基于DOM树和行列分割的Web内容信息提取方法
本发明涉及数据挖掘领域,具体涉及一种基于dom树和行列分割的web内容信息提取方法。
背景技术:
随着internet和web技术的飞速发展,网页已成为信息发布的主要载体。网页是由信息块和非信息块组成,信息块是由网页的主要内容块组成,只有这些才包含想要的信息。非信息块诸如导航菜单、底部的联系人信息、广告以及一些与网页主题无关的装饰组件,都是噪声信息。要想提高信息提取的性能,必须要去除这些噪声信息,并快速准确地对网页进行分割,从而获得组成块并对其进行准确的提取。因此如何更好的去除这些噪声并且准确提取这些信息块成为当前研究的热点。
现有的网页信息抽取的方法可以分为四类:基于包装器和启发式规则的信息提取方法,基于文本特征的信息提取方法,基于视觉分块的信息提取方法,基于统计和机器学习的信息提取方法。
(1)基于包装器和启发式规则的信息提取方法。该方法是一种早期且流行的方法,后续的web模板提取技术也属于这一类。其原则是通过构造包装器或web模板规则从web信息源中提取符合规则的信息。
(2)基于文本特征的信息提取方法。该方法通过网页结构和文本特征将网页划分为文本块和链接块。通过使用连续出现的噪声块的结果来完成文本部分的位置,得到网页信息。
(3)基于视觉分块的信息提取方法。该算法受人眼视觉启发,对人视觉处理信息进行模拟,并结合dom树对网页进行文本分块,最后从文本块中定位到正文块,达到提取信息的目的。
(4)基于统计和机器学习的信息提取方法。该算法通过对样本网页的文本分布和节点特征进行统计分析,建立模型规则,并通过不断学习对模型参数进行改进,从而在一定程度上实现自适应。
技术实现要素:
本发明的目的在于提供一种基于dom树和行列分割的web内容信息提取方法;该方法将网页解析成dom树,使用视觉特征和正则表达式过滤的方法去除噪声信息,通过重复行列拆分过程对网页进行分区得到组成块,最终使用两个启发式规则从这些组成块中进行提取,获得信息块。
本发明实现发明目的采用如下技术方案:
一种基于dom树和行列分割的web内容信息提取方法,其特征在于:所述包括如下步骤:
1)视觉特征去噪;
经过查看网页发现,大量的网页都是由head、foot、left、right、center五部分或者其中某几部分组成,其中大多数的网页均含有head、foot区域,right、left区域选择性拥有,通过视觉特征,去除上下左右部分;
2)正则表达式去噪;
在初步获取的正文文本中,可能仍包含利用视觉特征未去除的噪声信息,这些区域中的元素作为正文包含其中,需要通过正则表达式过滤的方式再次去除网页噪声信息;
表1噪声信息
3)生成一个新的网页视觉树;
本发明将网页拆分成列,对于每列,分别进行进一步的拆分为行或列,在此基础上,重复进行上述操作。
网页预处理之后,将网页转换成dom树结构,在此基础上,自下向上遍历中生成一个新的网页视觉树,在遍历过程中,为了提高处理效率,利用视觉特征和正则表达式去除那些噪声节点,对通常不含正文文本内容的标签做剪枝处理,得到一个简洁的dom树,并为新的视觉树中每个提取的节点分配一个判断符:即为每个节点标记两个布尔型变量,代表其子树中是否存在列拆分;
4)识别组成块;
本发明从视觉树对应的根节点展开新的可视化树,首先需要判断是否进行了列拆分,如果当前节点的子节点有子树,即进行列拆分,则增加一个粒度,继续扩展当前节点的子节点;如果当前子树只有行拆分,则不进行扩展,如此重复进行上述操作,当整个树不再进行扩展时,所有的叶节点都是预期的组成块,本发明是基于列拆分,初始分区粒度值从1开始,通过上述过程,就可以获得网页的所有组成块;
5)提取信息块;
本发明使用两个启发式规则通过加权平均来获得信息块的分数,分数最大的组成块即信息块,启发式规则如下:
r1、信息块通过上述过程后是标记数最多的块;
r2、信息块是所有块中面积最大的块;
作为优选,本发明提供的基于dom树和行列分割的web内容信息提取方法.,其特征在于:所属视觉特征去噪设计步骤如下:
1)将网页转化成dom结构,并得到页面的大小;
2)根据页面大小获得上下左右四部分阈值,记为w1,w2,w3.w4;
3)对页面内除body标记外元素取得其绝对坐标及实际大小和由阈值所划分出的区域进行比较,若任意元素e,(a,b)为其所占区域上的左上角原点绝对坐标,(width,height)记为此元素所占区域大小;
如果e.b+e.height<=w1,则e属于head区域;
如果e.b>=w2,则e属于foot区域;
如果e.a+e.width<=w3,则e属于left区域;
如果e.a>=w4,则e属于right区域;
所有不属于head,foot,left,right的区域作为结果返回;
作为优选,本发明提供的基于dom树和行列分割的web内容信息提取方法.,其特征在于:所述正则表达式如下:
<script[^>]*?>[\s\s]*?</script>
<style[^>]*?>[\s\s]*?</style>
<head[^>]*?>[\s\s]*?</head>
<!—[^-]*-->
<!--[\s\s]*?-->
作为优选,本发明提供的基于dom树和行列分割的web内容信息提取方法,其特征在于:在所述计算组成块分数的步骤中,根据以下公式1来计算:公式1:
score(bi)=α×areai+(1-α)|bi|
其中,|bi|为块bi中标记数目,area为块bi的面积,得分最高的块是信息块。
附图说明
下面结合附图对本发明作进一步的说明。
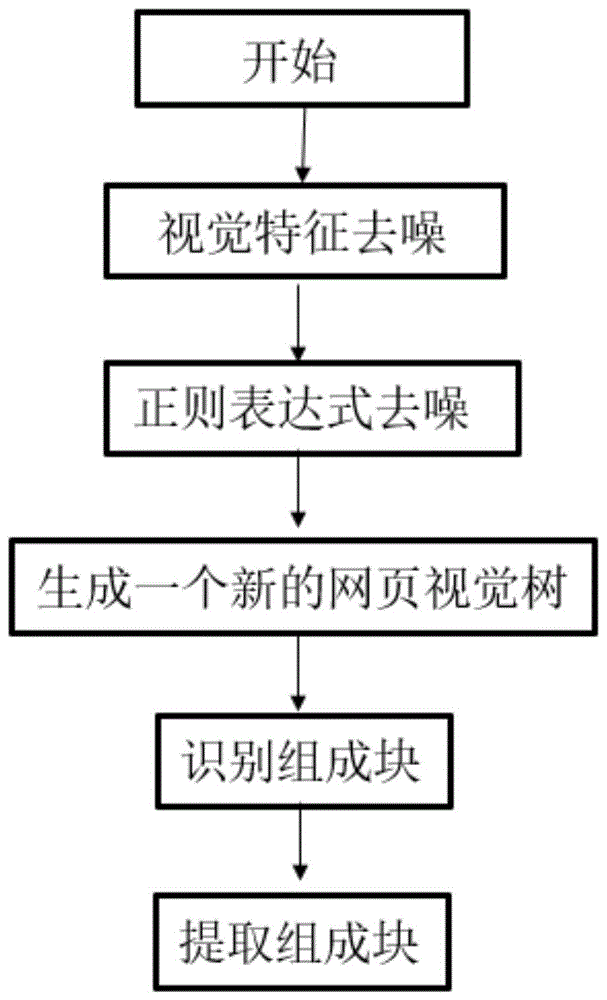
图1是本发明一种基于dom树和行列分割的web内容信息提取方法实施步骤的流程图;
图2是本发明网页拆分图;
图3是本发明在5个数据集上的结果示意图;
图4是本发明与其他两种算法的对比示意图。
具体实施方式
以下通过结合附图对本发明做进一步解释说明。
图1为根据本发明一种基于dom树和行列分割的web内容信息提取方法实施步骤的流程图,如图所示,该方法包括以下步骤:
1)视觉特征去噪;
经过查看网页发现,大量的网页都是由head、foot、left、right、center五部分或者其中某几部分组成,其中大多数的网页均含有head、foot区域,right、left区域选择性拥有,通过视觉特征,去除上下左右部分;
2)正则表达式去噪;
在初步获取的正文文本中,可能仍包含利用视觉特征未去除的噪声信息,这些区域中的元素作为正文包含其中,需要通过正则表达式过滤的方式再次去除网页噪声信息;
表1噪声信息
3)生成一个新的网页视觉树;
如图2所示,本发明将网页拆分成列,对于每列,分别进行进一步的拆分为行或列,在此基础上,重复进行上述操作。
网页预处理之后,将网页转换成dom树结构,在此基础上,自下向上遍历中生成一个新的网页视觉树,在遍历过程中,为了提高处理效率,利用视觉特征和正则表达式去除那些噪声节点,对通常不含正文文本内容的标签做剪枝处理,得到一个简洁的dom树,并为新的视觉树中每个提取的节点分配一个判断符:即为每个节点标记两个布尔型变量,代表其子树中是否存在列拆分;
4)识别组成块;
本发明从视觉树对应的根节点展开新的可视化树,首先需要判断是否进行了列拆分,如果当前节点的子节点有子树,即进行列拆分,则增加一个粒度,继续扩展当前节点的子节点;如果当前子树只有行拆分,则不进行扩展,如此重复进行上述操作,当整个树不再进行扩展时,所有的叶节点都是预期的组成块,本发明是基于列拆分,初始分区粒度值从1开始,通过上述过程,就可以获得网页的所有组成块;
5)提取信息块;
本发明使用两个启发式规则通过加权平均来获得信息块的分数,分数最大的组成块即信息块,启发式规则如下:
r1、信息块通过上述过程后是标记数最多的块;
r2、信息块是所有块中面积最大的块;
图3是本发明在5个数据集上结果示意图,其中横坐标代表数据集,纵坐标代表本发明在每个数据集的结果。
图4是本发明与其他两种算法的对比示意图。可以发现,本发明的准确率结果优于其他两种算法。
以上显示和描述了本发明的基本原理、主要特征和本发明的优点。本行业的技术人员应该了解,本发明不受上述实施例的限制,上述实施例和说明书中描述的只是说明本发明的原理,在不脱离本发明精神和范围的前提下,本发明还会有各种变化和改进,这些变化和改进都落入要求保护的本发明范围内。
- 还没有人留言评论。精彩留言会获得点赞!