一种基于多因子聚合模型的景区畅游度预测范式方法与流程
本发明涉及互联网大数据旅游服务领域,具体来说,涉及一种基于多因子聚合模型的景区畅游度预测范式方法。
背景技术:
随着社会生活水平的日益改善,人们的生活方式也不仅仅限于普通的衣、食、住、行。在物质方面得到提升的同时精神方面也追求一个质的飞跃,因此近些年旅游业也井喷式的发展,与此同时各景区的服务质量也需要同步的提升,提高有客户的旅游体验,特别是节假日的时间段,各个地区的景区游客常常出现较严重的拥堵跟滞留现象等问题。
因此为解决上述的问题现提出景区畅游度模型,该模型的目的是通过满足游客和管理两方面的需求,来改善游客旅游体验、转变景区服务观念,加快旅游智慧化建设。游客方面,游客通过获取景区畅游度信息,选择最恰当的出行时间和最合适的景点出游,从而获得较高满意度;景区管理方面,通过畅游度信息的发布,及时的向游客推荐最佳路线,避免游客集中部分景点,来提升景区服务水平和知名度。
技术实现要素:
本发明的目的是克服上述背景中的不足之处,提出一种基于多因子聚合模型的景区畅游度预测范式方法。
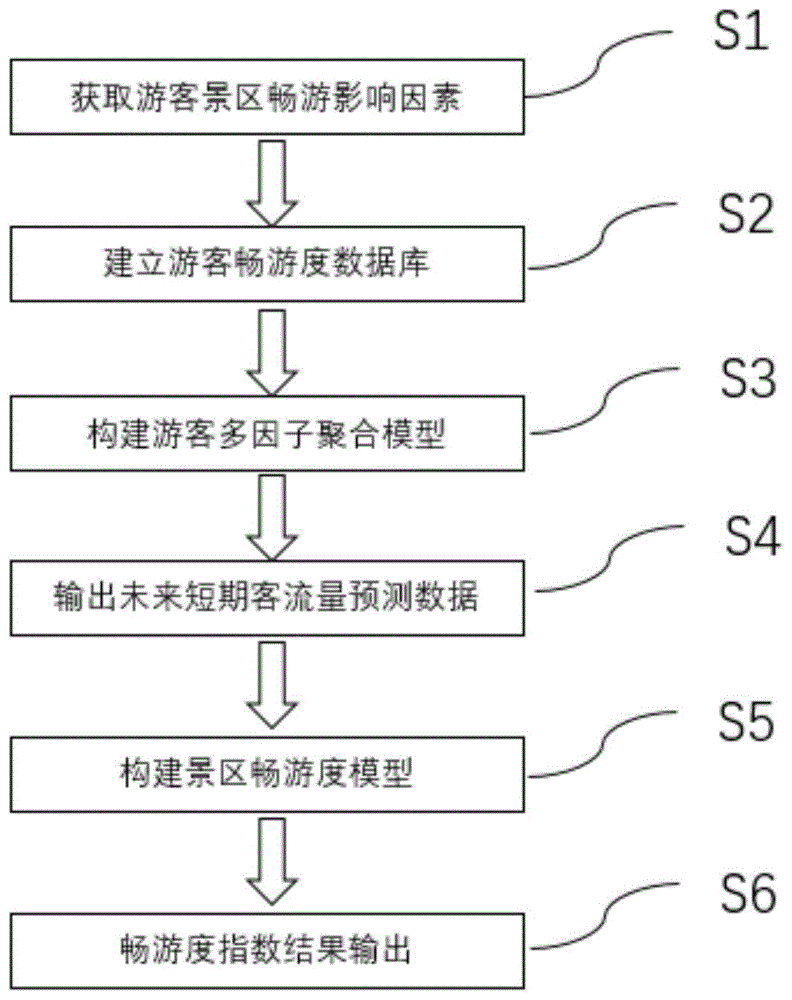
该方法包括如下步骤:
步骤s1:获取游客畅游景区影响因素;
步骤s2:建立游客畅游度数据集;
步骤s3:构建游客多因子聚合模型;
步骤s4:输出未来短期客流量预测数据;
步骤s5:构建景区畅游度模型;
步骤s6:畅游度指数结果输出。
优选地,所述步骤s1中游客畅游景区影响因素包括景区开放性、游客舒适度、道路通畅度和设施完善度。
优选地,所述步骤s2中游客畅游度数据集包括省内重点景区动态信息、天气预报信息、空气质量指数信息、pm2.5实时浓度信息、景区类型、景区游客量、道路拥挤度、高速卡口车流量、景区停车场停车余位、景区厕所密度和景区饭店密度信息。
所述步骤s3中构建游客多因子聚合模型主要包括如下步骤:
步骤s31:统计收集样本景区每小时客流量历史数据;
步骤s32:出游状态信息结果输出;
步骤s33:计算斯皮尔曼(spearman)相关系数ρ;
步骤s34:采用arima(p,d,q)模型预测未来一周每小时的客流量值。
优选地,所述多因子聚合模型步骤s31中样本景区每小时客流量历史数据的时间周期为t-t0,其中t代表当前时刻,t0代表1周前的此时刻。
优选地,所述多因子聚合模型步骤s32中出游状态信息结合了天气预报信息、空气质量指数信息、pm2.5实时浓度信息、气象预警和出游景点匹配性,具体结果包括适宜、较适宜、一般、较不宜、不适宜,并分别赋值为1、0.75、0.5、0.25、0。
优选地,所述多因子聚合模型步骤s33中斯皮尔曼(spearman)相关系数ρ包括各景点的历史客流量和出游状态值,相关系数ρ的计算方式为:
其中n数值为84,i代表其中的一个景点,xi代表景点i客流量,
所述多因子聚合模型步骤s34中arima(p,d,q)模型具体为:
其中,l是滞后算子,d为整数且大于0,i代表景点数,p代表自回归项数,φ代表自回归系数多项式,q代表滑动平均项数,θ代表滑动平均系数多项式,εt代表零均值白噪声序列。
首先,对历史客流量的时间序列进行平稳性分析,若为非平稳数据则需进行d阶差分,化为平稳非白噪声序列。其次,计算自相关系数acf(autocorrelationfunction)和偏自相关系数pacf(partialautocorrelationfunction),判断最佳阶层p和阶数q;最后,回归分析并验证结果;经过回归分析,计算客流量预测值;同时观察arima(autoregressiveintegratedmovingaveragemode)模型下的残差是否服从正态分布,并检验残差是否(自)相关。
优选地,所述多因子聚合模型步骤s34中预测的结果为:未来一周每小时客流量ξ1=未来一周每小时的客流量预测值*(1+ρ),其中,调整系数ρ是根据客流量与出游状态值两者相关系数进行确定。
预测景区未来一小时客流状态ξ2=1-未来一周每小时的客流量/日承载最大客流量,
其中,ξ≦0.2对应报警状态,0.2<ξ≦0.4对应拥挤状态,0.4<ξ≦0.6对应适中状态,0.6<ξ≦1对应舒适状态。
所述步骤s5中景区畅游度模型评价指标包括游客舒适度、道路通畅度和设施完善度;其中景区闭园情况下的畅游度定义为0,景区开园情况下的畅游度模型构建包括如下步骤:
步骤s51:采用ahp方法构建游客舒适度、道路畅通度和设施完善度各维度指数分项指标;
步骤s52:对分项指标进行min-max归一化处理;
步骤s53:采用主成分分析法(pca)确认各分项指标权重;
步骤s54:综合评估畅游度指数。
优选地,所述步骤s52中分项指标min-max归一化处理方法如下:
x*=(xi-xmin)/(xmax-xmin)
其中,xi表示实际值,xmin和xmax为对应的极小值和极大值,x*取值范围介于0至1之间。
优选地,所述步骤s53中主成分分析法(pca)具体定义如下:
假设存在p个景区观察点r=(x1,x2,…,xp)t,每个样本景点涵盖i个特征xp=(x1,x2,…,xi),xi对应是特定观察点的分项指标;
对样本矩阵r进行变换,求出相关系数矩阵,变换方法为标准化:
标准化
根据矩阵特征方程|r-λip|=0,解出特征值λ和特征向量ip,得到主成分:
倘若方差贡献率不满足条件,指标间相关性较弱,那么需通过熵值法重新计算各维度权重大小。
根据标准化后的指标数据计算出信息熵:
最终,综合评价结果如下:
景区畅游度指数=游客舒适度*w1+道路通畅度*w2+设施完善度*w3
优选地,所述步骤s6中畅游度指数结果输出主要包括如下结果:
a、客流量预测:
未来一周每小时客流量=未来一周每小时的客流量预测值*(1+ρ)
b、畅游度指数:
景区畅游度指数=游客舒适度*w1+道路通畅度*w2+设施完善度*w3。
本发明的有益效果在于:
(1)从游客方面来说,游客通过获取景区畅游度信息,选择最恰当的出行时间和最合适的景点出游,从而获得较高满意度。
(2)从景区管理方面来说,通过畅游度信息的发布,及时的向游客推荐最佳路线,避免游客集中部分景点,来提升景区服务水平和知名度。
(3)该发明通过建立多种模型来综合考虑景区畅游度,此方法灵活简洁具有十分广泛的实用性。
附图说明
图1是本发明景区畅游度预测范式方法构建流程图;
图2是本发明游客多因子聚合模型构建流程图;
图3是本发明景区开园情况下的畅游度模型构建流程图。
具体实施方式
下面将结合附图和实例对本发明作进一步的详细说明。
结合图1可知,该发明所述方法具体分为6个步骤,其中步骤s1获取游客畅游景区影响因素,其中影响因素包括了景区开放性、游客舒适度、道路通畅度和设施完善度。步骤s2建立游客畅游度数据集,其中数据包括省内重点景区动态信息、天气预报信息、空气质量指数信息、pm2.5实时浓度信息、景区类型、景区游客量、道路拥挤度、高速卡口车流量、景区停车场停车余位、景区厕所密度和景区饭店密度等信息。步骤s3中通过收集的数据构建游客多因子聚合模型,该聚合模型最终可以预测出未来一周每小时的客流量值,在步骤s4中输出未来短期客流量预测数据。步骤s5中景区畅游度模型评价指标包括游客舒适度、道路通畅度和设施完善度;其中景区闭园情况下的畅游度定义为0,景区开园情况下的畅游度模型构建。最后步骤s6中畅游度指数结果输出主要包括如下结果:
a、客流量预测:
未来一周每小时客流量=未来一周每小时的客流量预测值*(1+ρ)
b、畅游度指数:
景区畅游度指数=游客舒适度*w1+道路通畅度*w2+设施完善度*w3。
结合图2,步骤s3构建游客多因子聚合模型时,具体的又分为4个步骤,其中s31中样本景区每小时客流量历史数据的时间周期为t-t0,其中t代表当前时刻,t0代表1周前的此时刻。步骤s32中出游状态信息结合了天气预报信息、空气质量指数信息、pm2.5实时浓度信息、气象预警和出游景点匹配性,具体结果包括适宜、较适宜、一般、较不宜、不适宜,并分别赋值为1、0.75、0.5、0.25、0。步骤s33中斯皮尔曼(spearman)相关系数ρ包括各景点的历史客流量和出游状态值,相关系数ρ的计算方式为:
其中n数值为84,i代表其中的一个景点,xi代表景点i客流量,
其中,l是滞后算子,d为整数且大于0,i代表景点数,p代表自回归项数,φ代表自回归系数多项式,q代表滑动平均项数,θ代表滑动平均系数多项式,εt代表零均值白噪声序列
首先,对历史客流量的时间序列进行平稳性分析,若为非平稳数据则需进行d阶差分,化为平稳非白噪声序列。其次,计算自相关系数acf和偏自相关系数pacf,判断最佳阶层p和阶数q;最后,回归分析并验证结果;经过回归分析,计算客流量预测值;同时观察arima模型下的残差是否服从正态分布,并检验残差是否(自)相关。步骤s34中预测的结果为:未来一周每小时客流量ξ1=未来一周每小时的客流量预测值*(1+ρ),其中,调整系数ρ是根据客流量与出游状态值两者相关系数进行确定。
预测景区未来一小时客流状态ξ2=1-未来一周每小时的客流量/日承载最大客流量,
其中,ξ≦0.2对应报警状态,0.2<ξ≦0.4对应拥挤状态,0.4<ξ≦0.6对应适中状态,0.6<ξ≦1对应舒适状态。
结合图3,景区开园情况下的畅游度模型构建包括如下5个步骤,其中步骤s51采用ahp方法构建游客舒适度、道路畅通度和设施完善度各维度指数分项指标。步骤s52中分项指标min-max归一化处理方法如下:
x*=(xi-xmin)/(xmax-xmin)
其中,xi表示实际值,xmin和xmax为对应的极小值和极大值,x*取值范围介于0至1之间。
步骤s53中:假设存在p个景区观察点r=(x1,x2,…,xp)t,每个样本景点涵盖i个特征xp=(x1,x2,…,xi),xi对应是特定观察点的分项指标;
对样本矩阵r进行变换,求出相关系数矩阵,变换方法为标准化:
标准化
根据矩阵特征方程|r-λip|=0,解出特征值λ和特征向量ip,得到主成分:
根据标准化后的指标数据计算出信息熵:
最终,综合评价结果如下:
景区畅游度指数=游客舒适度*w1+道路通畅度*w2+设施完善度*w3
以上所述仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!