一种机器人自适应交互阻抗学习方法与流程
本发明属于机器人交互作用力控制领域,涉及一种机器人自适应交互阻抗学习方法。
背景技术:
阻抗控制作为机器人实现交互作用力控制的一种有效方法,往往须给出期望阻抗参数,进而设计阻抗控制器,控制机器人实现预期的交互作用力。然而,由于外界环境的未知性和不确定性,通常需要引入迭代学习策略,实现对环境中的阻尼和前馈力等非线性因素的自适应。当前绝大多数研究假设阻抗参数随时间呈现周期性变化,基于此设计阻抗学习控制器。然而,在精密装配、插拔接插件等典型交互任务中,机器人末端工具和环境的阻尼、表面粗糙度、弹性模量等物理参数与其相对位置有关,而非呈现时域内的周期性变化的特点,如果仍然采用这种基于时间周期性的阻抗学习机制,由于交互作用力变化导致的运动速度变化,将无法准确反映阻抗参数随空间位置变化的特点。
技术实现要素:
本发明解决的技术问题是:克服现有技术的不足,提出机器人自适应交互阻抗学习算法,准确反映了阻抗参数随空间位置变化的特点。
本发明解决技术的方案是:
一种机器人自适应交互阻抗学习方法,包括如下步骤:
步骤一、建立机器人自适应交互阻抗系统,包括机器人销和力学孔;力学孔为轴向水平放置的柱形通孔结构;力学孔的尺寸与机器人销对应;机器人销设置在力学孔中,且机器人销的外壁与力学孔内壁接触;机器人销沿力学孔的轴向实现移动。
一种机器人自适应交互阻抗学习方法,包括如下步骤:
步骤二、测量交互阻抗学习模型的各参数,包括机器人销的质量m、机器人销的驱动力fu、机器人销的环境运动阻力fe、机器人销沿轴向向力学孔孔底的移动距离x;
步骤三、建立机器人销与力学孔的装配力学公式:
式中,
步骤四、设定机器人销的跟踪参考轨迹的驱动力为fr,设定用于补偿环境和机器人之间其余交互力的自适应驱动力为fa;建立机器人销驱动力fu的计算方程;
步骤五、设定力学孔的孔深为l;将机器人销反复伸入力学孔底部n次;计算机器人销的累计移动距离l;
步骤六、设定机器人销每次伸入力学孔的速度跟踪误差为εi;其中,i为机器人销伸入力学孔的次数;1≤i≤n;则自适应驱动力fa为:
式中,ka为自适应力阻尼系数,即ka=kd;kd为未知阻尼系数,取决于销子和孔的材料、表面粗糙度及润滑条件等因素;
步骤七、设定位置跟踪误差为e,e=x-xr,其中,xr为参考轨迹;速度跟踪误差为
式中,α为比例系数,为正值;
β为微分反馈增益系数,为正值;
则机器人销的环境运动阻力fe为:
式中,kd为未知阻尼系数,取决于销子和孔的材料、表面粗糙度及润滑条件等因素;更新装配力学公式为:
步骤八、对公式(1)进行降阶处理,得到:
设定微分算子
由公式(2)的第二项获得空间域内的等效动力学模型为:
设置转换参量z,z=y,将转换参量z代入公式(3)中:
式中,a(x)为未知系数矢量,以x为周期且是有界的,
at(x)为未知系数矢量a(x)的转置;
ζ0(z)为已知矢量且对x、z连续可导,
b(x)是未知有界,且以x为周期的函数,函数值为正数,
ρ(z)为与z相关的自适应驱动力系数,
由于
式中,v(z,zr)为自定义状态转化函数;
步骤九、通过lyapunov-krasovskii函数推导出自适应力阻尼系数ka与轴向移动距离x间的关系如下:
式中,γ为反馈增益常数;
η(x)为反馈增益,η=ce;c为1×n常数向量,c=[c1,...,cn-1,1];e为广义速度跟踪误差,是n×1维常数向量;
设定μ(x)为扩展参数向量,
设定ζ0(z)为对x满足局部lipschitz条件的已知矢量,且对x、z连续可导;
ζ(x,e)为ζ0(z)的扩展向量;ζ(x,e)=[(ζ0)t,
设定c=[c1,...,cn-1,1]以保证p为渐近稳定的;
步骤十、为获得机器人销和力学孔间期望的速度和稳定交互,定义广义速度跟踪误差e为:
令公式(4)与公式(5)相减,得到闭环系统的误差动力学方程:
式中,q=[0,...,0,1]t;
则控制律方程:
式中,e为广义速度跟踪误差,e=[ε1,...,εn]t;
∈∈rp+2为扩展参数向量与扩展参数向量估计值的差值;
则:
式中,
引入微分算子
引入微分算子
进而:
式中,μ(x)为扩展参数向量,
a(x)和b(x)均为x的周期函数,设其周期为l,则:
μ(l)=μ(l-l)
当l≥l时,
即当l≥l时:
当0≤l≤l时,则:
进而:
此时:
而η=ce可知:
式中,
由式(9)可知η有界且关于l收敛,因此,e有界且关于l收敛,则闭环系统的误差动力学方程
在上述的一种机器人自适应交互阻抗学习方法,所述步骤三中,驱动力fu的计算方程为:
fu=fr+fa。
在上述的一种机器人自适应交互阻抗学习方法,所述步骤四中,累计移动距离l的计算方法为:
l=nl+x
式中,x为机器人销经过nl的学习后,最后一次机器人销沿轴向向力学孔孔底的移动距离x。
在上述的一种机器人自适应交互阻抗学习方法,所述步骤八中,扩展参数向量的估测值
式中,η(x)为反馈增益;
γ(l,l)为学习增益矩阵,且γ(l,l)>0,γ(l,l)的取值为:
其中,
对于l∈[0,l),λi(x)为严格递增函数,且满足λi(0)=0,λi(l)=ξi,ξi>0为常值。
本发明与现有技术相比的有益效果是:
(1)本发明采用了步骤五所述的自适应驱动力fa,提高了对未知环境的调整能力,实现了机器人在未知环境中,将销子按照期望的动力学特性插入孔内;
(2)本发明采用了步骤七,所述的微分算子
(3)本发明采用了步骤八,所述的自适应阻尼系数ka,通过多次迭代学习,提高了机器人对不确定性环境的交互作用力控制能力,实现了对未知环境的阻尼参数的准确学习。
附图说明
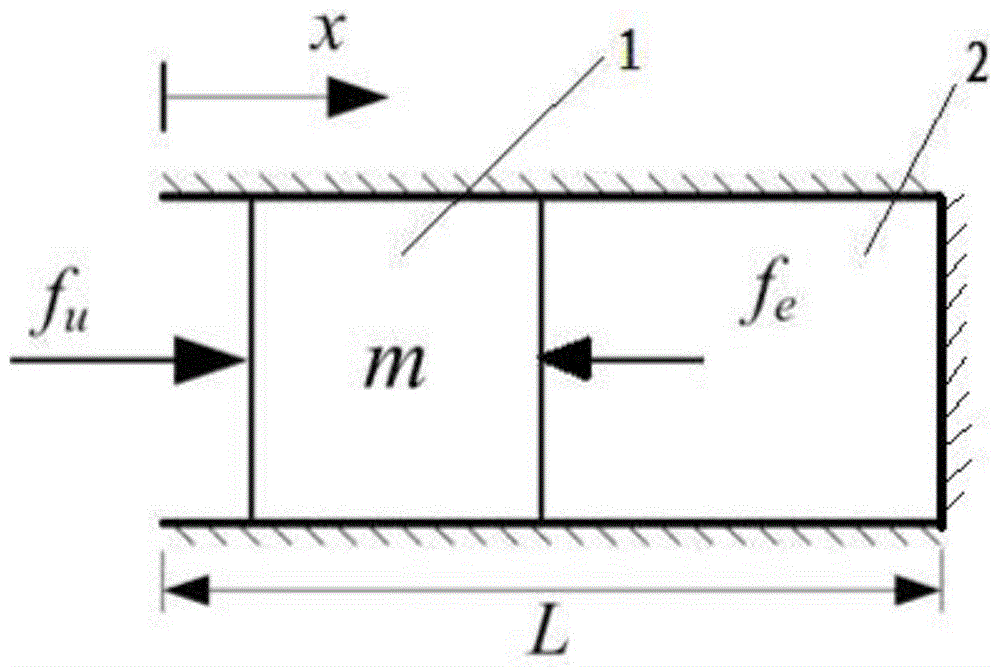
图1为本发明交互阻抗学习装置示意图。
具体实施方式
下面结合实施例对本发明作进一步阐述。
本发明提供一种机器人自适应交互阻抗学习方法,实现机器人销以恒定的速度插入力学孔内,即机器人学习到了环境的阻抗参数,通过调整自身的输出力,使机器人销和力学孔间实现了期望的交互动力学特性;本发明准确反映了阻抗参数随空间位置变化的特点。
机器人自适应交互阻抗学习方法,包括如下步骤:
步骤一、建立机器人自适应交互阻抗系统,包括机器人销1和力学孔2;如图1所示,力学孔2为轴向水平放置的柱形通孔结构;力学孔2的尺寸与机器人销1对应;机器人销1设置在力学孔2中,且机器人销1的外壁与力学孔2内壁接触;机器人销1沿力学孔2的轴向实现移动。
步骤二、测量交互阻抗学习模型的各参数,包括机器人销1的质量m、机器人销1的驱动力fu、机器人销1的环境运动阻力fe、机器人销1沿轴向向力学孔2孔底的移动距离x。
步骤三、建立机器人销1与力学孔2的装配力学公式:
式中,
步骤四、设定机器人销1的跟踪参考轨迹的驱动力为fr,设定用于补偿环境和机器人之间其余交互力的自适应驱动力为fa;建立机器人销1驱动力fu的计算方程:fu=fr+fa。
步骤五、设定力学孔2的孔深为l;将机器人销1反复伸入力学孔2底部n次;计算机器人销1的累计移动距离l;累计移动距离l的计算方法为:
l=nl+x
式中,x为机器人销1经过nl的学习后,最后一次机器人销1沿轴向向力学孔2孔底的移动距离x。
步骤六、设定机器人销1每次伸入力学孔2的速度跟踪误差为εi;其中,i为机器人销1伸入力学孔2的次数;1≤i≤n;则自适应驱动力fa为:
式中,ka为自适应力阻尼系数,即ka=kd;kd为未知阻尼系数,取决于销子和孔的材料、表面粗糙度及润滑条件等因素;
步骤七、设定位置跟踪误差为e,e=x-xr,其中,xr为参考轨迹;速度跟踪误差为
式中,α为比例系数,为正值;
β为微分反馈增益系数,为正值;
则机器人销1的环境运动阻力fe为:
式中,kd为未知阻尼系数,取决于销子和孔的材料、表面粗糙度及润滑条件等因素;更新装配力学公式为:
步骤八、对公式(1)进行降阶处理,得到:
设定微分算子
由公式(2)的第二项获得空间域内的等效动力学模型为:
设置转换参量z,z=y,将转换参量z代入公式(3)中:
式中,a(x)为未知系数矢量,以x为周期且是有界的,
at(x)为未知系数矢量a(x)的转置;
ζ0(z)为已知矢量且对x、z连续可导,
b(x)是未知有界,且以x为周期的函数,函数值为正数,
ρ(z)为与z相关的自适应驱动力系数,
由于
式中,v(z,zr)为自定义状态转化函数。
步骤九、通过lyapunov-krasovskii函数推导出自适应力阻尼系数ka与轴向移动距离x间的关系如下:
式中,γ为反馈增益常数;
η(x)为反馈增益,η=ce;c为1×n常数向量,c=[c1,...,cn-1,1];e为广义速度跟踪误差,是n×1维常数向量;
设定μ(x)为扩展参数向量,
设定ζ0(z)为对x满足局部lipschitz条件的已知矢量,且对x、z连续可导;
ζ(x,e)为ζ0(z)的扩展向量;ζ(x,e)=[(ζ0)t,
设定c=[c1,...,cn-1,1]以保证p为渐近稳定的。
步骤十、为获得机器人销1和力学孔2间期望的速度和稳定交互,定义广义速度跟踪误差e为:
令公式(4)与公式(5)相减,得到闭环系统的误差动力学方程:
式中,q=[0,...,0,1]t;
则控制律方程:
式中,e为广义速度跟踪误差,e=[ε1,...,εn]t;
∈∈rp+2为扩展参数向量与扩展参数向量估计值的差值;
则:
式中,
引入微分算子
引入微分算子
进而:
式中,μ(x)为扩展参数向量,
a(x)和b(x)均为x的周期函数,设其周期为l,则:
μ(l)=μ(l-l)
当l≥l时,
即当l≥l时:
当0≤l≤l时,则:
进而:
此时:
而η=ce可知:
式中,
由式(9)可知η有界且关于l收敛,因此,e有界且关于l收敛,则闭环系统的误差动力学方程
本发明虽然已以较佳实施例公开如上,但其并不是用来限定本发明,任何本领域技术人员在不脱离本发明的精神和范围内,都可以利用上述揭示的方法和技术内容对本发明技术方案做出可能的变动和修改,因此,凡是未脱离本发明技术方案的内容,依据本发明的技术实质对以上实施例所作的任何简单修改、等同变化及修饰,均属于本发明技术方案的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!