基于LCWaveGAN的船舶航行噪声仿真生成方法
本发明涉及船舶航行噪声仿真生成方法。
背景技术:
在船舶航行水下辐射噪声信号中,连续谱的来源主要是空化噪声,旋转的机械构件产生的摩擦噪声等。连续谱的作用机理较为复杂,从原理上对连续谱噪声进行叠加或者是其他形式的仿真是不大现实的。故而,目前的方法主要是有,对连续谱进行各种方式的取样,通过样本设置滤波器参数。然后用高斯白噪声通过这些滤波器,得到连续谱的时域或者是频域信号。这些方法在一定程度上可以较好地还原船舶水下辐射噪声的连续谱信号,但是由于这些方法没有普适性,或者是步骤多,人工干预过程多,公式仿真和滤波器参数受采样精度的限制,仿真效果不佳;
综上,目前船舶航行噪声仿真生成方法存在以下两个问题:
第一,目前连续谱的生成方式,较为复杂,人为干预次数多,建立新的针对某一目标的水下辐射噪声仿真方法所需时间久;
第二,目前的船舶航行水下辐射噪声信号仿真多是针对静态目标仿真,没有针对航行中的声特性进行仿真;
导致获得的船舶航行水下辐射噪声信号准确率低,获得方式繁琐;
技术实现要素:
本发明的目的是为了解决现有船舶航行水下辐射噪声信号准确率低,获得方式繁琐的问题,而提出基于lcwavegan的船舶航行噪声仿真生成方法。
基于lcwavegan的船舶航行噪声仿真生成方法具体过程为:
步骤一、获取真实的船舶水下辐射噪声;
步骤二、对步骤一获取的真实船舶水下辐射噪声进行时频转换,将转换后的噪声信号进行平滑处理,得到连续谱;
步骤三、对连续谱进行时频转换,生成时域的连续谱噪声信号;
步骤四、将生成的时域连续谱噪声信号输入基于lcwavegan的连续谱信号生成模型中,训练lcwavegan中的判定器,生成仿真的船舶水下辐射噪声连续谱的时域信号;
步骤五、将生成的仿真船舶水下辐射噪声连续谱的时域信号进行累加,生成仿真的连续谱时域信号;
步骤六、提取步骤一中获取的真实船舶水下辐射噪声的调制参数;
步骤七、基于调制参数,合成调制信号;
步骤八、通过lofor谱模型提取步骤一中获取的真实的船舶水下辐射噪声的线谱;
步骤九、通过噪声发生器,将高斯白噪声输入到基于lcwavegan的连续谱信号生成模型中,生成连续谱;
步骤十、通过步骤七的调制信号、步骤八生成的线谱和步骤九生成的连续谱,叠加形成静止状态下的消声水池的目标仿真水下辐射噪声;
步骤十一、根据目标运动参数,对静止状态下的消声水池的目标仿真水下辐射噪声进行运动修正,得到仿真船舶航行水下辐射噪声。
本发明的有益效果为:
本发明采用获取真实的船舶水下辐射噪声;对获取的真实船舶水下辐射噪声进行时频转换,将转换后的噪声信号进行平滑处理,得到连续谱;对连续谱进行时频转换,生成时域的连续谱噪声信号;将生成的时域连续谱噪声信号输入基于lcwavegan的连续谱信号生成模型中,生成仿真的船舶水下辐射噪声连续谱的时域信号;将生成的仿真船舶水下辐射噪声连续谱的时域信号进行累加,生成仿真的连续谱时域信号;提取真实的船舶水下辐射噪声的调制参数;基于调制参数,合成调制信号;通过lofor谱模型提取步骤一中获取的真实的船舶水下辐射噪声的线谱;通过噪声发生器,将高斯白噪声输入到基于lcwavegan的连续谱信号生成模型中,生成连续谱;通过调制信号和生成的连续谱,叠加形成静止状态下的消声水池的目标仿真水下辐射噪声;根据目标运动参数,进行运动修正,得到仿真船舶航行水下辐射噪声。
本发明通过对对抗生成网络进行改进,建立自动抽样机制,使改进的lcwavegan模型,可以在保证生成噪声的质量的前提下,得到时间较长的仿真的航行中的船舶水下辐射噪声,具有普适性,人工干预次数少,自动化程度高。针对传统仿真方法对船舶航行噪声关注度较少的问题,采用时延滤波器方法,将船舶运动状态对噪声的影响考虑进去,设计出一种仿真船舶航行水下辐射噪声生成方法,提高了获取的船舶航行水下辐射噪声信号准确率,获得方式简便。
附图说明
图1为本发明基于lcwavegan的仿真连续谱信号生成方法;
图2a为船舶水下辐射噪声图;
图2b为人声示意图;
图3为1秒的噪声连续谱功率谱对比图;
图4为4秒的噪声连续谱功率谱对比图;
图5为运动修正前后频谱图对比图;
图6为仿真船舶航行水下辐射噪声生成示意图。
具体实施方式
具体实施方式一:本实施方式基于lcwavegan的船舶航行噪声仿真生成方法具体过程为:
步骤一、获取真实的船舶水下辐射噪声;
步骤二、对步骤一获取的真实船舶水下辐射噪声进行时频转换,将转换后的噪声信号进行平滑处理,得到连续谱;
步骤三、对连续谱进行时频转换,生成时域的连续谱噪声信号(快速傅立叶变换);
步骤四、将生成的时域连续谱噪声信号输入基于lcwavegan的连续谱信号生成模型中,训练lcwavegan中的判定器,通过模型内部的判定器,生成器,损失函数等逻辑处理,生成仿真的船舶水下辐射噪声连续谱的时域信号;
步骤五、将生成的仿真船舶水下辐射噪声连续谱的时域信号进行累加,生成仿真的连续谱时域信号;
步骤六、提取步骤一中获取的真实船舶水下辐射噪声的调制参数(demon方法);
步骤七、基于调制参数,合成调制信号;
步骤八、通过lofor谱等模型提取步骤一中获取的真实的船舶水下辐射噪声的线谱;
步骤九、通过噪声发生器,将高斯白噪声输入到基于lcwavegan的连续谱信号生成模型中,生成连续谱;
步骤十、通过步骤七的调制信号、步骤八生成的线谱和步骤九生成的连续谱,叠加形成未经过运动修正,也就是静止状态下的消声水池的目标仿真水下辐射噪声;
步骤十一、根据目标运动参数,对静止状态下的消声水池的目标仿真水下辐射噪声进行运动修正,得到仿真船舶航行水下辐射噪声。
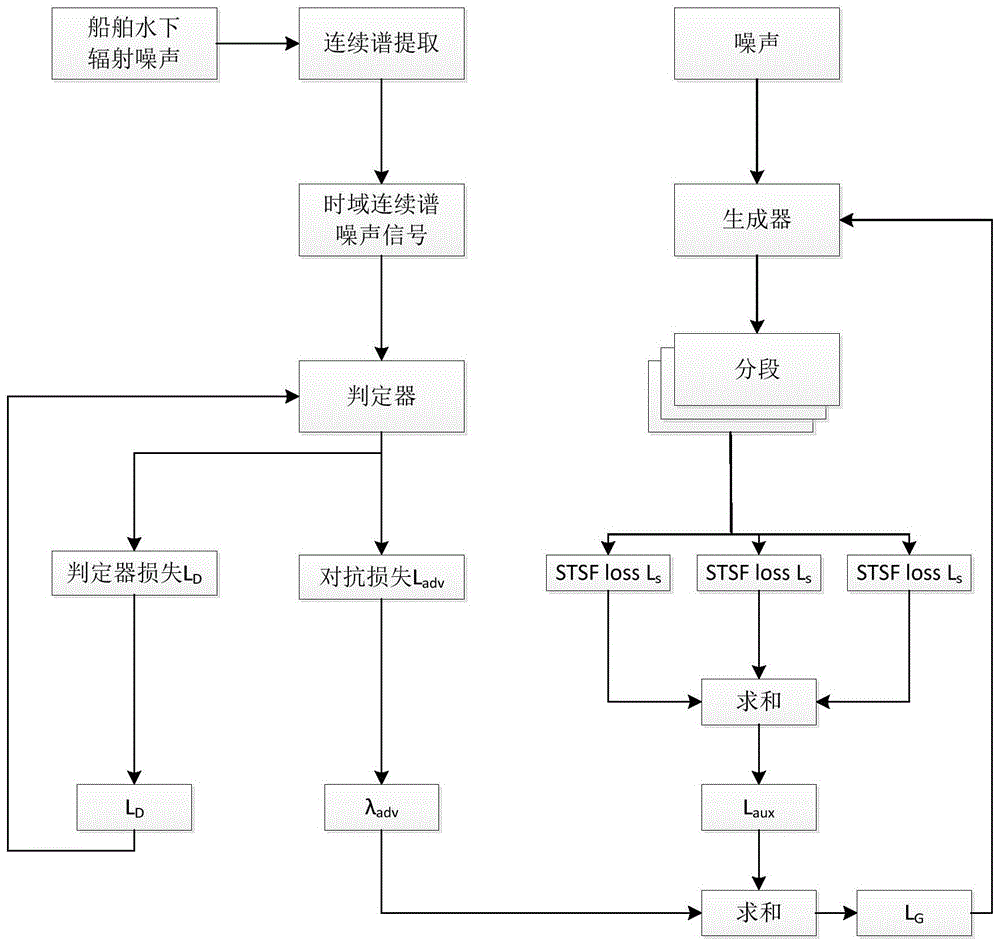
具体实施方式二:本实施方式与具体实施方式一不同的是,所述步骤四中将生成的时域连续谱噪声信号输入基于lcwavegan的连续谱信号生成模型中,训练lcwavegan中的判定器,通过模型内部的判定器,生成器,损失函数等逻辑处理,生成仿真的船舶水下辐射噪声连续谱的时域信号;具体过程为:
在生成器的改进中,本发明方法使用非因果卷积代替因果卷积。
基于lcwavegan的连续谱信号生成模型包括生成器和判定器;
随机噪声输入基于lcwavegan的连续谱信号生成模型,输入的随机噪声是高斯白噪声;
生成器通过使判定器分不清真伪,从而学习到真实的船舶水下辐射噪声连续谱信号,模型的训练是非自回归的,并且通过使用最小化对抗性损失来实现这个过程,基于lcwavegan的连续谱信号生成模型的对抗性损失为ladv(g,d);
将步骤一获取的真实船舶水下辐射噪声输入判定器进行判定,当生成的样本判定为真样本,输出船舶水下航行噪声的连续谱分量的噪声(执行公式3-6);当生成的样本判定为假样本,执行公式(1)-(4);
判定器将生成的样本判定为假样本的时候,使用由下式表示的优化准则;
ld(g,d)=ex~pdata[(1-d(x))2]+ez~n(0,i)[d(g(z))2](1)
其中,ex~pdata表示步骤三生成时域的连续谱噪声信号x的波形分布,ld(g,d)为判定器损失函数,d(x)表示判定器判断x产生的数据,x表示步骤三生成时域的连续谱噪声信号;
判定为假的说明还需要训练,需要用到公式1,判定为真的就输出了;
判定为假可以直接判定;
判定器的训练是通过真实水下辐射噪声训练的;
在生成对抗网络中,有很多未知的不稳定因素。在本方法设计前的论证实验中,很多生成对抗网络模型会出现生成器损失函数和判别器损失函数不下降,正确率卡在50%的情况。而且,随着要生成的数据越来越多,在同样的模型下,对硬件和计算时间的要求也越来越多。故而,为了解决此类问题,提高生成效率,并使模型稳定性提高,引入多分辨率短时傅里叶变换stft(short-timefouriertransform,短时傅里叶变换)辅助损失函数;
单一的短时傅里叶变换stft的损失函数为ls(g),ls(g)由下式所示:
ls(g)=ez~n(0,i),x~pdata[lsc(x,g(z))+lmag(x,g(z))](2)
其中,g(z)表示高斯白噪声通过生成器产生的仿真数据,lsc和lmag分别表示谱线收敛和对数stft幅度损失;
在该方法中,多分辨率stft辅助损失函数是不同的快速傅里叶变换窗口的大小,帧的移位等不同损失函数结果的和。
设m为短时傅里叶变换stft的损失,关于m用下式表示:
其中
在船舶水下航行噪声连续谱的基于短时傅里叶变换的信号时频表示中,时域上的分辨率和频域上的分辨率存在一定的竞争关系。例如,增加窗口的大小,可以增加频域上的分辨率,但是,在增加频域分辨率的同时,会使得时域分辨率下降。故而,在此方法中,通过多个不同stft损失和窗口大小等参数的设置,可以使模型在时频特性上的学习能力大大提高。并且,这种设置可以防止生成器在单一stft参数设置上过拟合,从而降低模型的学习能力。
综合以上,生成器的损失函数定义为多分辨率stft辅助损失函数,多分辨率stft辅助损失函数为lg(g,d),lg(g,d)如下式所示:
lg(g,d)=laux(g)+λadvladv(g,d)(4)
式中,λadv表示平衡g和d中损失函数的超参数,lg(g,d)为多分辨率stft辅助损失函数;
生成器生成在船舶水下航行噪声的连续谱分量的噪声;
将生成器生成的在船舶水下航行噪声的连续谱分量的噪声输入判定器进行判定,当生成的样本判定为真样本,输出生成器生成的在船舶水下航行噪声的连续谱分量的噪声;当生成的样本判定为假样本,执行公式(1)-(4),生成器生成在船舶水下航行噪声的连续谱分量的噪声,继续将生成器生成的在船舶水下航行噪声的连续谱分量的噪声输入判定器进行判定;直至生成的样本判定为真样本,输出生成器生成的在船舶水下航行噪声的连续谱分量的噪声;
在使用gan(对抗生成网络)对声音进行仿真生成的过程中,生成的声音和样本的声音在长度和分辨率上是一致的。在图2a、2b可以清楚的看到,相较于人读单词的声音在时域上是不“平滑”的,而船舶水下噪声在时域上是较为“连续”的,时间分布上也比较平均。故而,可以在生成器上做出如下改进,以适应船舶水下航行噪声的特点,生成更长时间的水下辐射噪声。
将生成器生成的连续谱分量的噪声随机抽取n段,n为输入高斯白噪声长度的倍数;将n段噪声送入判别器判别,全部为真,则输出真;若有大于等于一个为假,则输出假;注意,生成的长噪声应当随机抽取,否则生成的声音在听觉上有一定的顿挫感,类似于n个相似的音频拼接起来。
通过上述操作,可以在网络复杂度不变的前提下,生成时长更长的仿真的船舶水下辐射噪声连续谱的时域信号。
其它步骤及参数与具体实施方式一相同。
具体实施方式三:本实施方式与具体实施方式一或二不同的是,所述基于lcwavegan的连续谱信号生成模型的对抗性损失ladv(g,d)由下式表示:
ladv(g,d)=ez~n(0,i)[(1-d(g(z)))2](5)
其中,z为输入的高斯白噪声,ladv(g,d)为对抗损失,g为生成器,d为判定器,ez~n(0,i)代表z在服从0~i区间分布时的期望,n(0,i)为0~i区间,i表示高斯白噪声产生区间,g(z)表示高斯白噪声通过生成器产生的仿真数据,d(g(z))表示判定器判断g(z)产生的数据。
其它步骤及参数与具体实施方式一或二相同。
具体实施方式四:本实施方式与具体实施方式一至三之一不同的是,所述lsc如下式所示:
其中,‖‖f表示frobenius范数,stft()表示短时傅里叶变换的幅度。
其它步骤及参数与具体实施方式一至三之一相同。
具体实施方式五:本实施方式与具体实施方式一至四之一不同的是,所述lmag如下式所示:
其中,‖‖1表示l1范数,n表示幅度stft()中元素的数量。
其它步骤及参数与具体实施方式一至四之一相同。
具体实施方式六:本实施方式与具体实施方式一至五之一不同的是,所述步骤七中基于调制参数,合成调制信号;具体过程为:
由于船舶水下辐射噪声与螺旋桨的叶片与流体的摩擦有关,而螺旋桨的叶片在一定时域内是有周期性的,在谱分析中,可以把这种周期性的“节拍”表现成对连续谱信号的调制。叶频轴频和它们的谐频都以调制的形式存在。
由于螺旋桨的工作原理,潜艇或者船舶的水下辐射噪声具有明显的节拍现象,这就是调制谱;
基于调制参数,合成调制信号;调制信号在时域上用下式表示:
式中,m′为螺旋桨个数,ni为螺旋桨转速,单位是转每秒,理论上各个ni是一致的;
其它步骤及参数与具体实施方式一至五之一相同。
具体实施方式七:本实施方式与具体实施方式一至六之一不同的是,所述步骤八中通过lofor谱等模型提取步骤一中获取的真实的船舶水下辐射噪声的线谱;具体过程为:
根据信号处理中时域频域的关系,频域上的线谱在时域的表现形式在正常情况下是正弦信号。故而,船舶水下辐射噪声的线谱在时域中用下式表示:
式中,an是线谱的幅度,fn是线谱的频率,
其它步骤及参数与具体实施方式一至六之一相同。
具体实施方式八:本实施方式与具体实施方式一至七之一不同的是,所述步骤十一中根据目标运动参数,对静止状态下的消声水池的目标仿真水下辐射噪声进行运动修正,得到仿真船舶航行水下辐射噪声;具体过程为:
船舶水下航行噪声运动修正所需要的实时性不强,可以分帧对原始船舶水下航行噪声进行处理。首先,应确定水听器和船舶目标的相对运动方式,确定船舶水下辐射噪声从发出到水听器的时延δt;δt用下式表示:
其中,c代表仿真水域的声速,d代表船舶水下辐射噪声从发出到水听器的距离;
令时延δt用下式表示:
δt=(ceil(n)+n-ceil(n))/fs(11)
其中,ceil(n)代表δt*fs的整数部分,*代表乘号,n-ceil(n)代表δt*fs的小数部分,fs代表采样频率,n代表δt时间内有n个采样周期;δt*fs代表时延周期;
在时延周期δt*fs的整数部分,通过数据的缓存队列表示时延;
时延周期δt*fs的整数部分为sw1(t),sw1(t)代表缓存的船舶发出噪声的时域信号;
对于n-ceil(n)时间,由于小于采样周期,无法通过直接顺延的方式计算水听器收到声音的时间。故而可以采用,根据n-ceil(n)的取值,在纯小数实验滤波器组与缓存的输出队列信号进行卷积;
时延周期δt*fs的小数部分为sw2(t),sw2(t)是未计算传播损失的船舶发出噪声的时域信号;
得到了未计算传播损失的船舶发出噪声的时域信号之后,按照指定的时长分片,在本方法中使用仿真目标航行1米所需要的时长,具体时长分片可根据航速调整。
使用仿真目标航行1米所需要的时长分片,具体由下式表示:
sw(n:(δt+n))=ifft(δsl(fft(sw2(n:(δt+n)))))(12)
仿真目标的噪声是指高斯白噪声通过生成器生成的仿真噪声。仿真噪声的理论发生源是仿真目标。目标就是虚拟出我假定的目标的水下辐射噪声。
其中,sw(n:(δt+n))代表从n到δt+n时刻的计算过传播损失的船舶发出噪声的时域信号,ifft()代表快速傅里叶变换的逆变换,fft()代表快速傅里叶变换,sw2(n:(δt+n)代表从n到δt+n时刻的未计算过传播损失的船舶发出噪声的时域信号;δsl代表关于传播损失的公式,可根据具体需求选择适合的公式(比如tl=20lgd+a·d×10-3;d表示距离,a(f)=0.05f1.4,f表示频率,适用深海)。
最后,将各段sw(n:(δt+n))拼接起来,组成一段完整的计算过传播损失的船舶发出噪声的时域信号sw(t),即仿真船舶航行水下辐射噪声。
基于lcwavegan的连续谱信号仿真方法,如图1所示。船舶水下辐射噪声在进行连续谱提取后,再由时频转换生成时域的连续谱的噪声信号。再输入到基于lcwavegan的连续谱信号生成模型中,通过模型内部的判定器,生成器,损失函数等逻辑处理,生成出仿真的船舶水下辐射噪声连续谱的时域信号,之后,在经过信号的累加,生成仿真的连续谱的时域信号。
船舶航行噪声仿真生成方法如图6所示。消声水池的静止目标信号,经过包括多路水听器平均化处理之后,将声音切成1秒的片段,提取船舶水下辐射噪声的调制参数,使用调制参数,合成调制信号。通过lofor谱等模型提取消声水池目标信号的线谱。使用提取到的线谱参数,合成线谱信号。通过噪声发生器,输入到基于lcwavegan的仿真连续谱信号生成方法模型中,生成连续谱。之后,通过与之前生成的调制信号和线谱信号,叠加形成未经过运动修正,也就是静止状态下的消声水池的目标的仿真水下辐射噪声,再根据所需要的一定条件下的目标运动参数,形成修正后的消声水池的目标的仿真水下辐射噪声。
其它步骤及参数与具体实施方式一至七之一相同。
具体实施方式九:本实施方式与具体实施方式八不同的是,所述时延周期δt*fs的整数部分sw1(t)如下式所示:
sw1(t)=sm(t-ceil(n))(13)
其中,sw1(t)代表缓存的船舶发出噪声的时域信号,sm代表船舶发出噪声的实时时域信号。
其它步骤及参数与具体实施方式八相同。
具体实施方式十:本实施方式与具体实施方式九不同的是,所述
对于n-ceil(n)时间,由于小于采样周期,无法通过直接顺延的方式计算水听器收到声音的时间。故而可以采用,根据n-ceil(n)的取值,在纯小数实验滤波器组与缓存的输出队列信号进行卷积;
时延周期δt*fs的小数部分为sw2(t)如下式所示:
sw2(t)=conv(hk(n),sw1(t))(14)
其中,sw2(t)是未计算传播损失的船舶发出噪声的时域信号,conv()代表卷积操作,hk(n)代表时域滤波器组的权重。
其它步骤及参数与具体实施方式九相同。
采用以下实施例验证本发明的有益效果:
实施例一:
本实施例具体是按照以下步骤制备的:
实验采用消声水池数据集测试。消声水池数据集是在水声实验室的一个消声水池中产生的。由于消声水池面积的限制。实验数据的采集是在目标静止的情况下采集的。目标通过发动机功率大小来模拟出船舶运行状态。消声水池数据集共有8中噪声类型,每种噪声类型的总时长有360秒的噪声,每个片段的占用的空间是94,375,936字节,比特率是2097kbps,,采样率为65536hz,音频格式为wav格式。标注为“work0”、“work20”、“work50”、“work80”、“0power”、“20power”、“50power”、“80power”以上八种。实验环境如表1所示。
表1实验环境
由于目前的wavegan模型,只支持单gpu训练,故而生成器和判定器的规模不宜过大。判别器生成器的训练比为5:1。此网络结构的输入输出为分辨率为65536hz,时长为1秒的噪声数据。模型还可以输入时长是65536的有限度的整数倍的音频数据。相应的,需要再加入一定数量的网络层级和步长。
判别器的模型参数设计如下表2所示,在六个卷积层中,卷积核的大小为25。六个卷积层均使用tensorflow中的conv1d()函数。每一层中在conv1d()函数之后进行批次标准化,激活函数使用节中的辅助损失函数stft。
表2判别器模型参数
生成器的模型参数设计如下表3所示,输入是满足高斯分布的长度为100的一维随机数组,uconv层是由插值法上采样resize_nearest_neighbor,反卷积函数conv2d_transpose等构成,激活函数使用辅助损失函数stft、relu和tanh函数。
表3判别器模型参数
高斯分布的随机数组经过生成器,生成长度为65536的仿真的船舶水下辐射噪声。如果需要生成的噪声时长为2秒,4秒或者更长,可以在uconv_0层前加入一层或者多层uconv层,通过扩大卷积核数目,改变步长,生成更长的声音。但是,由于服务器算力和模型学习能力的限制,当学习生成的噪声的长度过长时,噪声的仿真质量将会下降。
图3对比的是时长为1秒的仿真与真实的船舶水下辐射噪声,图4对比的是时长为4秒的仿真与真实的船舶水下辐射噪声,仿真的基准都是“80power”数据的连续谱分量噪声。由图3、4中可以看出,同样在迭代26000次的情况下,时长越短的噪声,在功率谱对比上,仿真度越好。
由图3、4中还可以看出,仿真的连续谱分量的噪声,24000hz以内的仿真度较好,在更高频率的仿真度不如低频。但是由于目前对船舶水下辐射噪声的基于线谱等分类方法,大多针对噪声的低频段,而且由图3、4可知,水下辐射噪声在高频端的振幅极其微弱,故而高频端的失真对目前的船舶目标分类,识别或者检测工作影响不大。
在本发明方法中,可以实现65536hz,4s的相对真实的仿真的船舶水下辐射噪声。生成更长的音频时,会从高频开始失真,并且,由于生成长度加大,所以网络宽度变大,故而每一批的训练数量就会变小,时间也会更长。以生成一秒的声音为例,迭代26000次所需要的时间是30小时左右,而生成四秒,在批次数目不变的情况下,迭代26000次所需要的时间接近100小时。
船舶的运动状态在频率上的影响如图5所示,第一秒即[0,1)秒时间区间内的数据所绘制的频谱图,为了使观测更加明显,故而对频谱图做了平滑处理。由图5中可以明显的看出,在目标模拟向水听器方向运动500米之后,振幅明显增大,而且频率高的部分增大的较快,符合水声学原理。从数据上看,在目标从1000米运动到500米之后,30000hz的振幅增加量要比1000hz的多增加了3.9589db。
本发明还可有其它多种实施例,在不背离本发明精神及其实质的情况下,本领域技术人员当可根据本发明作出各种相应的改变和变形,但这些相应的改变和变形都应属于本发明所附的权利要求的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!