一种基于计算广告背景下的相似人群拓展方法以及装置与流程
1.本发明涉及信息处理技术领域,尤其涉及一种基于计算广告背景下的相似人群拓展方法以及装置。
背景技术:
2.在互联网商业应用中,许多广告主在“搜寻潜客”时,都会遇到如难以识别高潜人群、难于平衡成本与规模等问题,在这一背景下则产生了lookalike(相似人群拓展)人群定向技术,该技术可以利用广告主第一方数据,基于少量的种子用户,通过大数据分析和机器学习拓展出和种子相似的用户人群,而这些拓展出的相似人群最终也很有可能成为广告主的目标客户,从而提升广告效果。
3.lookalike技术主流方法:方法一,显示定位,广告主根据标签进行人群选择。这种方法简单,直观,广告主通过用户画像标签,筛选性别、年龄、偏好等标签,从而直接筛选目标人群。但是该方法需要广告主大量人工参与试错,且该方法具有一定的局限性,人工打出的标签不能完全概括目标人群的所有属性,比如不一定男性就不关心护肤品等。显示定位的方法期长、成本高,而且很难通用。
4.方法二,隐式定位,通过机器学习的方法,对种子用户进行建模。隐式定位的方法几乎不需要广告主参与,只需要广告主提供目标人群(即种子用户)的特征,通过机器学习的方法,根据种子数据自动发现相似人群,有效规避了自定义标签面临的问题。
5.lookalike技术难点,难点一:高潜力用户难寻、精准与规模之间难取平衡点是广告主所面临的两个主要难题,核心在于对大规模潜在用户的有效触及。效果和规模之间达成“帕累托最优”(最理想状态)显得相对棘手,具体为,广告主想要尽量触达潜在的目标客户,则会需要对大规模潜在用户都进行触达,人群的聚焦性也必然逐步降低,致使非目标人群的比例也随着流量的增加而增加,增加广告成本,但是如果广告主缩小触达规模,则会导致一部分目标人群未被触达,影响广告效果。
6.难点二:降低种子用户的敏感性:种子用户是拓展的前提和基础,种子用户的质量往往也是lookalike效果好坏的关键。但广告主很难提供数据量足够大且足够宽泛的种子包。这个时候就需要考虑如何在少量种子包且种子不一定能覆盖全局特征的情况下,进行有效的数据预处理和模型学习。
技术实现要素:
7.本发明所要解决的技术问题是针对现有技术的不足,提供一种基于计算广告背景下的相似人群拓展方法以及装置。
8.本发明解决上述技术问题的技术方案如下:一种基于计算广告背景下的相似人群拓展方法,其包括:
9.获取由种子人群组成的正样本、由非种子人群组成的负样本、预设负样本采样条件、广告前端监测数据、第三方标签数据以及预设规则标签;
10.根据所述预设负样本采样条件对所述负样本进行分层采样处理,得到采样后的负样本;
11.分别对所述广告前端监测数据以及所述第三方标签数据进行特征处理,并分别构建模型,对应得到第一模型以及第二模型;
12.在第一模型以及第二模型中,分别调整正样本的权重参数,对应得到第三模型以及第四模型;
13.对所述第三模型以及第四模型进行融合打分,得到人群打分信息;
14.选出所述人群打分信息中的模糊打分区域;
15.对所述模糊打分区域进一步构建模型进行过滤筛选,得到第一相似人群;
16.根据预设规则标签以及所述广告前端监测数据对所述第一相似人群进行筛选过滤,得到相似人群。
17.进一步地,所述分别对所述广告前端监测数据以及所述第三方标签数据进行特征处理,并分别构建模型,对应得到第一模型以及第二模型的步骤,包括:
18.对所述广告前端监测数据进行数值化编码处理,得到数值化编码的广告前端监测数据;
19.对所述数值化编码的广告前端监测数据进行数值分箱处理,得到客户关系管理类特征;
20.对所述客户关系管理类特征构建模型,得到第一模型。
21.进一步地,所述分别对所述广告前端监测数据以及所述第三方标签数据进行特征处理,并分别构建模型,对应得到第一模型以及第二模型的步骤,包括:
22.对所述第三方标签数据进行词嵌入处理,得到嵌入式第三方标签数据;
23.对所述嵌入式第三方标签数据构建模型,得到第二模型。
24.进一步地,所述选出所述人群打分信息中的模糊打分区域的步骤,包括:
25.将所述人群打分信息中分值为0.5至0.7之间的区域设置为模糊打分区域。
26.进一步地,所述分别调整正样本的权重参数为分别按照时间衰减系数分配以及调整正样本的权重。
27.本发明的有益效果是:通过机器学习及规则包过滤的方法,从而保证尽可能触达目标人群的基础上,缩小触达人群规模,提高目标人群筛选的精准性。
28.此外,本发明还提供了一种基于计算广告背景下的相似人群拓展装置,其包括:
29.获取设备,用于获取由种子人群组成的正样本、由非种子人群组成的负样本、预设负样本采样条件、广告前端监测数据、第三方标签数据以及预设规则标签;
30.处理设备,用于根据所述预设负样本采样条件对所述负样本进行分层采样处理,得到采样后的负样本;
31.所述处理设备,还用于分别对所述广告前端监测数据以及所述第三方标签数据进行特征处理,并分别构建模型,对应得到第一模型以及第二模型;
32.所述处理设备,还用于在第一模型以及第二模型中,分别调整正样本的权重参数,对应得到第三模型以及第四模型;
33.所述处理设备,还用于对所述第三模型以及第四模型进行融合打分,得到人群打分信息;
34.所述处理设备,还用于选出所述人群打分信息中的模糊打分区域;
35.所述处理设备,还用于对所述模糊打分区域进一步构建模型进行过滤筛选,得到第一相似人群;
36.所述处理设备,还用于根据预设规则标签以及所述广告前端监测数据对所述第一相似人群进行筛选过滤,得到相似人群。
37.进一步地,所述处理设备,还用于对所述广告前端监测数据进行数值化编码处理,得到数值化编码的广告前端监测数据;
38.所述处理设备,还用于对所述数值化编码的广告前端监测数据进行数值分箱处理,得到客户关系管理类特征;
39.所述处理设备,还用于对所述客户关系管理类特征构建模型,得到第一模型。
40.进一步地,所述处理设备,还用于对所述第三方标签数据进行词嵌入处理,得到嵌入式第三方标签数据;
41.所述处理设备,还用于对所述嵌入式第三方标签数据构建模型,得到第二模型。
42.进一步地,所述处理设备,还用于将所述人群打分信息中分值为0.5至0.7之间的区域设置为模糊打分区域。
43.进一步地,所述分别调整正样本的权重参数为分别按照时间衰减系数分配以及调整正样本的权重。
44.本发明的有益效果是:通过机器学习及规则包过滤的方法,从而保证尽可能触达目标人群的基础上,缩小触达人群规模,提高目标人群筛选的精准性。
45.本发明附加的方面的优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本发明实践了解到。
附图说明
46.图1为本发明实施例提供的基于计算广告背景下的相似人群拓展方法的示意性流程图之一。
47.图2为本发明实施例提供的基于计算广告背景下的相似人群拓展方法的示意性流程图之二。
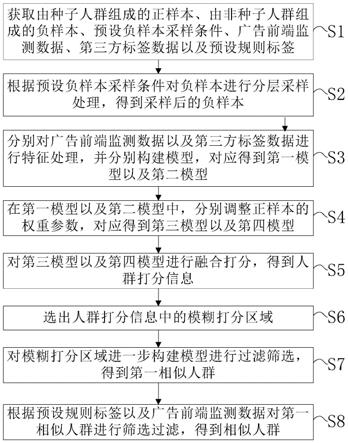
48.图3为本发明实施例提供的基于计算广告背景下的相似人群拓展装置的示意性结构框图。
具体实施方式
49.以下结合附图对本发明的原理和特征进行描述,所举实例只用于解释本发明,并非用于限定本发明的范围。
50.如图1和图2所示,本发明实施例提供了一种基于计算广告背景下的相似人群拓展方法,其包括:
51.s1、获取由种子人群组成的正样本、由非种子人群组成的负样本、预设负样本采样条件、广告前端监测数据、第三方标签数据以及预设规则标签;
52.s2、根据所述预设负样本采样条件对所述负样本进行分层采样处理,得到采样后的负样本;
53.s3、分别对所述广告前端监测数据以及所述第三方标签数据进行特征处理,并分别构建模型,对应得到第一模型以及第二模型;
54.s4、在第一模型以及第二模型中,分别调整正样本的权重参数,对应得到第三模型以及第四模型;
55.s5、对所述第三模型以及第四模型进行融合打分,得到人群打分信息;
56.s6、选出所述人群打分信息中的模糊打分区域;
57.s7、对所述模糊打分区域进一步构建模型进行过滤筛选,得到第一相似人群;
58.s8、根据预设规则标签以及所述广告前端监测数据对所述第一相似人群进行筛选过滤,得到相似人群。
59.lookalike,即相似人群扩展,是基于种子用户,通过一定的算法评估模型,找到更多拥有潜在关联性的相似人群的技术。
60.种子人群,即目标人群。
61.logistics regression(逻辑回归),即一种有监督的统计学习方法,主要用于对样本进行分类。
62.gbdt(gradient boosting decision tree),是一种迭代的决策树算法,该算法由多棵决策树组成,所有树的结论累加起来做最终答案。
63.本发明实施例使用规则标签进行统一过滤,具体为:步骤11,选取正负样本,对负样本进行采样;步骤12,分别对广告前端监测数据和一三方标签数据进行特征处理,构建模型;步骤13,调整正样本的权重参数,按时间衰减系数分配权重;步骤14,模型融合打分;步骤15,针对模糊打分区域进一步构建模型进行过滤筛选;步骤16,使用规则标签进行统一过滤,并筛选出近几个月活跃人群,最终圈出高潜人群。
64.其中,1、正样本选取种子人群,负样本分层采样,比如在拓展留资用户的场景中,负样本可以从到站未留资,未到站的样本中进行分层采样,然后采用pu
‑
learning(positive
‑
unlabeled learning,只有正样本的半监督的二分类器)思想多次训练模型去除负样本中的高分样本,筛选出最终的负样本,并且由于大部分的目标人群都包含于近期活跃的人群中,所以对正负样本都取近期活跃的人群。
65.2、由于前端广告监测的数据维度较高难以采取树模型,所以分别对前端广告监测数据进行数值化编码,数值分箱,构建rfm(recency
‑
frequency
‑
monetary,客户关系管理)类特征,特征拉平后使用logistics regression(逻辑回归)方法构建模型,对一三方标签数据使用word2vec(独热编码)方法进行word embedding(词嵌入),然后再使用gbdt(gradient boosting decision tree,梯度提升树)方法构建模型。
66.3、由于近期的用户行为对于挖掘高潜人群(相似人群)的价值更大,所以在模型中按时间衰减系数分配正样本的权重,近期的正样本的权重大于早期的正样本的权重。
67.4、使用stacking(商品堆码)方法对lr模型(logistic regression,逻辑回归)和gbdt(gradient boosting decision tree,梯度提升树)模型进行模型融合,最终输出泉灵人群打分。
68.5、对人群打分进行分组评级,发现模型将大规模人群都分为高潜人群,且很大量级集中在分值为0.5
‑
0.7之间,将其定义为模糊打分区域,针对该部分样本进一步构建模型进行过滤筛选。
69.6、最后使用常用的规则标签并结合近几个月广告前端监测数据监测到的活跃人群,针对全体高潜人群进行统一筛选过滤,最终圈出高潜人群。
70.本发明的主要改进点在于:1、对负样本进行分层采样,并采取pu
‑
learning(positive
‑
unlabeled learning,只有正样本的半监督的二分类器)的方法过滤可能是正样本的负样本,且采取近期活跃。2、分别对广告前端监测数据和一三方标签数据进行特征处理,并分别采用lr(logistic regression,逻辑回归),gbdt(gradient boosting decision tree,梯度提升树)方法构建模型,最后使用stacking方法进行模型融合打分。3、在模型中按时间衰减系数分配正样本的权重。4、对第一层模型圈出的高潜人群的低分人群进一步构建模型进行过滤筛选。5、为缩小广告触达的人群规模,结合规则标签和近几个月活跃人群,对模型圈出的高潜用户进行最终过滤。
71.进一步地,所述分别对所述广告前端监测数据以及所述第三方标签数据进行特征处理,并分别构建模型,对应得到第一模型以及第二模型的步骤,包括:
72.对所述广告前端监测数据进行数值化编码处理,得到数值化编码的广告前端监测数据;
73.对所述数值化编码的广告前端监测数据进行数值分箱处理,得到客户关系管理类特征;
74.对所述客户关系管理类特征构建模型,得到第一模型。
75.进一步地,所述分别对所述广告前端监测数据以及所述第三方标签数据进行特征处理,并分别构建模型,对应得到第一模型以及第二模型的步骤,包括:
76.对所述第三方标签数据进行词嵌入处理,得到嵌入式第三方标签数据;
77.对所述嵌入式第三方标签数据构建模型,得到第二模型。
78.进一步地,所述选出所述人群打分信息中的模糊打分区域的步骤,包括:
79.将所述人群打分信息中分值为0.5至0.7之间的区域设置为模糊打分区域。
80.进一步地,所述分别调整正样本的权重参数为分别按照时间衰减系数分配以及调整正样本的权重。
81.本发明的有益效果是:通过机器学习及规则包过滤的方法,从而保证尽可能触达目标人群的基础上,缩小触达人群规模,提高目标人群筛选的精准性。
82.如图3所示,此外,本发明还提供了一种基于计算广告背景下的相似人群拓展装置,其包括:
83.获取设备,用于获取由种子人群组成的正样本、由非种子人群组成的负样本、预设负样本采样条件、广告前端监测数据、第三方标签数据以及预设规则标签;
84.处理设备,用于根据所述预设负样本采样条件对所述负样本进行分层采样处理,得到采样后的负样本;
85.所述处理设备,还用于分别对所述广告前端监测数据以及所述第三方标签数据进行特征处理,并分别构建模型,对应得到第一模型以及第二模型;
86.所述处理设备,还用于在第一模型以及第二模型中,分别调整正样本的权重参数,对应得到第三模型以及第四模型;
87.所述处理设备,还用于对所述第三模型以及第四模型进行融合打分,得到人群打分信息;
88.所述处理设备,还用于选出所述人群打分信息中的模糊打分区域;
89.所述处理设备,还用于对所述模糊打分区域进一步构建模型进行过滤筛选,得到第一相似人群;
90.所述处理设备,还用于根据预设规则标签以及所述广告前端监测数据对所述第一相似人群进行筛选过滤,得到相似人群。
91.进一步地,所述处理设备,还用于对所述广告前端监测数据进行数值化编码处理,得到数值化编码的广告前端监测数据;
92.所述处理设备,还用于对所述数值化编码的广告前端监测数据进行数值分箱处理,得到客户关系管理类特征;
93.所述处理设备,还用于对所述客户关系管理类特征构建模型,得到第一模型。
94.进一步地,所述处理设备,还用于对所述第三方标签数据进行词嵌入处理,得到嵌入式第三方标签数据;
95.所述处理设备,还用于对所述嵌入式第三方标签数据构建模型,得到第二模型。
96.进一步地,所述处理设备,还用于将所述人群打分信息中分值为0.5至0.7之间的区域设置为模糊打分区域。
97.进一步地,所述分别调整正样本的权重参数为分别按照时间衰减系数分配以及调整正样本的权重。
98.本发明的有益效果是:通过机器学习及规则包过滤的方法,从而保证尽可能触达目标人群的基础上,缩小触达人群规模,提高目标人群筛选的精准性。
99.最后应说明的是:以上各实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述各实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分或者全部技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1