基于文本超分辨的甲骨文识别
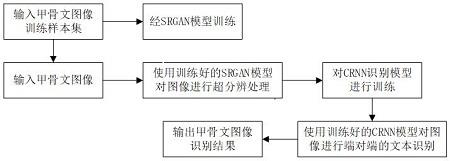
1.本发明涉及文本图像超分辨及图像文字识别领域,具体涉及基于文本超分辨的甲骨文识别。
背景技术:
2.中国古代的甲骨文是世界上最著名的古代文字系统之一,甲骨文的识别与破译是甲骨文研究的重要课题之一。有些甲骨文字已经有了一定程度的解释。然而,这些结果是由专家手工完成的,这种手工方法需要高水平的专业知识,使得这样的研究非常昂贵,并且进一步阻碍了甲骨文识别和破译的进展。因此,一种高效、有效的甲骨文研究技术是当前和未来甲骨文研究的迫切需要。
3.目前,基于深度学习的甲骨文字识别都是监督方式的。常见的甲骨单字图像有甲骨字模图像和拓片文字图像两种,真正意义的甲骨文字识别工作需要在拓片文字数据集上进行,甲骨磨损、拓印噪声和甲骨纹理干扰对识别结果影响很大,从公开报道结果来看,整体识别率都不理想,最高的仅为70%左右。基于文本超分辨的甲骨文识别主要包含文本图像超分辨和文本图像识别两个部分。
技术实现要素:
4.本发明提供了甲骨文字拓片图像的识别方法,降低了低分辨率导致的识别困难,提高了识别的准确率。
5.本发明技术方案为基于文本超分辨的甲骨文识别,所述方案包括以下步骤:
6.s0:输入待测的甲骨文拓片图像;
7.s1:采用hr图像和lr图像对srgan网络进行训练;
8.s2:使用srgan技术对图像进行超分辨预处理,以提高甲骨文字图像分辨率,降低噪声;
9.s3:对预处理之后的甲骨文图像集合输入到训练好的端到端crnn识别模型中。
10.所述步骤s0的操作过程如下:
11.s00:在互联网上下载获取拓片甲骨文字的图像数据集;
12.s01:图像数据集的75%作为训练集,25%作为测试集供后续训练与验证。
13.所述步骤s1的操作过程如下:
14.s10:srgan是一种用于图像超分辨率(sr)的生成对抗网络(gan),利用感知损失(perceptual loss)和对抗损失(adversarial loss)来提升恢复出的图片的真实感,能够在公共基准测试中从严重下采样的图像中恢复照片般逼真的纹理,从其低分辨率 (lr)对应物估计高分辨率(hr)图像;
15.s11:将真实的高分辨率图像和虚假的高分辨率图像传入判别模型中,分别将判别结果与1和0做对比,利用对比得到的loss进行训练;
16.s12:将低分辨率图像传入生成模型,得到高分辨率图像,利用该高分辨率图像获
得判别结果与1进行对比。将真实的高分辨率图像和虚假的高分辨率图像传入vgg 网络,获得两个图像的特征并比较获得loss;
17.s13:训练过程中,固定一方,更新另一方的网络权重,交替迭代,在这个过程中,形成竞争对抗,直到双方达到一个动态的平衡,公式如下:
[0018][0019]
其中,x表示真实的图像,z表示输入的g网络噪声,g(z)表示g网络生成的图像。d(x)表示真实输入的概率,d(g(z))表示d网络判断g生成的图像是否真实的概率。
[0020]
所述步骤s2的操作过程如下:
[0021]
s20:输入甲骨文字图像数据集到训练好的srgan网络模型中;
[0022]
s21:输入低分辨率图像经过一个卷积+relu函数然后经过b个残差网络结构,每个残差网络内部包含两个卷积+标准化+relu,还有一个残差边,用于特征提取;
[0023]
s22:通过上采样,将长宽进行放大,两次上采样后,变为原来的4倍,实现提高分辨率。
[0024]
所述步骤s3的操作过程如下:
[0025]
s30:将预处理后的obc306拓片甲骨文字图像数据集按3:1比例分为训练集和测试集;
[0026]
s31:用该数据集对crnn识别模型进行训练;
[0027]
s32:crnn识别模型是cnn+rnn+ctc的结构,通过cnn将图片的特征提取出来后采用rnn对序列进行预测,最后通过一个ctc的翻译层得到最终结果,网络架构由三部分组成,包括卷积层,循环层和转录层,从底向上;
[0028]
s33:通过crnn网络提取特征向量序列,并最终得到待识别文字图像中的文字识别结果。
[0029]
与现有技术相比,本发明提供的技术方案的有益效果是:
[0030]
1.将超分辨与文本检测识别相结合,提高识别精确率;
[0031]
2.将crnn模型应用于甲骨文字数据集,实现了端到端的识别;
[0032]
3.将超分辨应用于甲骨文检测识别领域,扩展超分辨的应用领域;
附图说明
[0033]
图1为基于文本超分辨的甲骨文识别系统实现流程图;
[0034]
图2为待识别甲骨文拓片原始图;
[0035]
图3为预处理后的甲骨文拓片示意图;
[0036]
图4为识别后的示意图。
具体实施方式
[0037]
如图1所示:
[0038]
为使本发明的目的、技术方案和优点更加清楚,下面对本发明实施方式作进一步地详细描述。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
[0039]
实施本发明技术方案为基于文本超分辨的甲骨文识别,所述方案包括以下步骤:
[0040]
s0:输入待测的甲骨文拓片图像;
[0041]
s1:采用hr图像和lr图像对srgan网络进行训练;
[0042]
s2:使用srgan技术对图像进行超分辨预处理,以提高甲骨文字图像分辨率,降低噪声;
[0043]
s3:对预处理之后的甲骨文图像集合输入到训练好的端到端crnn识别模型中。
[0044]
所述步骤s0的操作过程如下:
[0045]
s00:在互联网上下载获取拓片甲骨文字的图像数据集;
[0046]
s01:图像数据集的75%作为训练集,25%作为测试集供后续训练与验证,原始图如图2所示。
[0047]
所述步骤s1的操作过程如下:
[0048]
s10:srgan是一种用于图像超分辨率(sr)的生成对抗网络(gan),利用感知损失(perceptual loss)和对抗损失(adversarial loss)来提升恢复出的图片的真实感,能够在公共基准测试中从严重下采样的图像中恢复照片般逼真的纹理,从其低分辨率 (lr)对应物估计高分辨率(hr)图像;
[0049]
s11:将真实的高分辨率图像和虚假的高分辨率图像传入判别模型中,分别将判别结果与1和0做对比,利用对比得到的loss进行训练;
[0050]
s12:将低分辨率图像传入生成模型,得到高分辨率图像,利用该高分辨率图像获得判别结果与1进行对比。将真实的高分辨率图像和虚假的高分辨率图像传入vgg 网络,获得两个图像的特征并比较获得loss;
[0051]
s13:训练过程中,固定一方,更新另一方的网络权重,交替迭代,在这个过程中,形成竞争对抗,直到双方达到一个动态的平衡,公式如下:
[0052][0053]
其中,x表示真实的图像,z表示输入的g网络噪声,g(z)表示g网络生成的图像。d(x)表示真实输入的概率,d(g(z))表示d网络判断g生成的图像是否真实的概率。
[0054]
所述步骤s2的操作过程如下:
[0055]
s20:输入甲骨文字图像数据集到训练好的srgan网络模型中;
[0056]
s21:输入低分辨率图像经过一个卷积+relu函数然后经过b个残差网络结构,每个残差网络内部包含两个卷积+标准化+relu,还有一个残差边,用于特征提取;
[0057]
s22:通过上采样,将长宽进行放大,两次上采样后,变为原来的4倍,实现提高分辨率,得到的高分辨率图像如图3所示。
[0058]
所述步骤s3的操作过程如下:
[0059]
s30:将预处理后的obc306拓片甲骨文字图像数据集按3:1比例分为训练集和测试集;
[0060]
s31:用该数据集对crnn识别模型进行训练;
[0061]
s32:crnn识别模型是cnn+rnn+ctc的结构,通过cnn将图片的特征提取出来后采用rnn对序列进行预测,最后通过一个ctc的翻译层得到最终结果,网络架构由三部分组成,包括卷积层,循环层和转录层,从底向上;
[0062]
s33:通过crnn网络提取特征向量序列,并最终得到待识别文字图像中的文字识别结果,如图4所示。
[0063]
综上所述,本实施例的基于文本超分辨的甲骨文识别,采用文本图像sr算法与 crnn文本识别算法相结合,对甲骨文字拓片图像进行识别,降低了低分辨率导致的识别困难,提高了识别的准确率。
[0064]
以上所述仅为本发明的实施例,并非因此限制本发明的专利范围,凡是利用本发明说明书及附图内容所作的等效结构或等效流程变换,或直接或间接运用在其他相关的技术领域,均同理包括在本发明的专利保护范围内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1