单篇文档分析方法和装置
本发明涉及计算机技术领域,尤其涉及一种单篇文档分析方法和装置。
背景技术:
随着信息化社会的发展,人们面对的数据量呈现出井喷式增长,在大数据时代,如何快捷有效地获取数据信息,已经成为人们面对的一个迫切需要解决的问题。如何快速从锁定的文档中了解其核心内容,从而确定该文档是否是自己所需的文档,在人们面对有限时间时获取更充分有效的信息问题时显得尤为重要。
现有技术中主要是通过确定待分析文档的业务类型,并依据实体在文档中出现的位置一家实体与实体之间的语法结构,获取实体与实体之间的关系,并以实体为节点,实体之间的关系为边,构建知识图谱与分档之间的映射关系。
其中,分析主要是依据文本本身为依据,不能对文档未披露的信息进行补充,使得用户在看到所进行的文档分析后,可能仍然不知道该文档的主要内容,或者不明白文档内容的逻辑关系等,即不能使用户准确而全面地理解文档中的内容。
技术实现要素:
本发明提供一种单篇文档分析方法和装置,用以解决现有技术中用户不能全面准确而全面理解文档的缺陷,实现帮助用户对文档进行语义级别的快速查阅和分析,并帮助用户快速定位自己的感兴趣的文档。
第一方面,本发明实施例提供一种单篇文档分析方法,包括:
获取待进行分析的文档;
对所述文档进行分类;
对所述文档进行实体链接,得到实体链接结果;
对所述文档进行分句处理得到多个句子,并对得到的句子进行分词处理和词性标注处理;
对分词和词性标注处理后的结果分别进行关键词抽取、命名实体识别和实体开放关系抽取,得到关键词抽取结果、命名实体识别结果和开放关系抽取结果;
将实体链接结果、关键词抽取结果和命名实体识别结果进行处理,得到实体合并结果;
基于关键词抽取结果和命名实体识别结果进行语义要素抽取,得到语义要素结果;
基于实体链接结果进行关系扩展,得到关系扩展结果;
根据分句得到的句子和实体合并结果进行共现关系计算,得到共现关系确定结果;
基于关系扩展结果、开放关系抽取结果和共现关系确定结果,得到单篇文档的分析结果。
进一步地,根据本发明提供的一种单篇文档分析方法,其中,对得到的句子进行分词处理,包括:
采用规则分词、统计分词、规则和统计混合分词三种方法中的一种或多种对得到的句子进行分词处理。
进一步地,根据本发明提供的一种单篇文档分析方法,其中,所述规则分词是指通过维护字典,在切分语句时,将语句的每个字符串与词表中的词进行逐一匹配,如果匹配成功,则切分,否则不切分;其中,匹配方法包括正向最大匹配法、逆向最大匹配法以及双向最大匹配法;
所述统计分词是指统计预设文本,如果相连接的字在不同的文本中出现次数越多,则说明这些相连接的字为一个词;统计分词方法包括两步,第一步是建立统计语言模型,第二步是对文本进行词语划分;其中,统计分词包括有基于隐含马尔科夫hmm、条件随机场crf方法;
所述规则和统计混合分词是指先基于词典的方法进行分词,然后再用统计分词的方法进行辅助。
进一步地,根据本发明提供的一种单篇文档分析方法,其中,所述对所述文档进行实体链接,包括:
建立词和实体的联合表示模型;
基于所述词和实体的联合表示模型,采用概率实体模型,建立所述文档中的连续字符与知识库中的实体的链接关系。
进一步地,根据本发明提供的一种单篇文档分析方法,其中,所述对分词和词性标注处理后的结果进行关键词抽取,包括:
采用词频-逆文档频次算法tf-idf、textrank、基于文法规则、潜在语义分析lsa、潜在语义检索lsi方法,得到关键词词表和每个词在原文中的位置及重要性。
进一步地,根据本发明提供的一种单篇文档分析方法,其中,所述对分词和词性标注处理后的结果进行命名实体识别,包括:
采用基于规则的方法、基于特征的方法和基于神经网络的方法中的一种或多种对分词和词性标注处理后的结果进行命名实体识别。
进一步地,根据本发明提供的一种单篇文档分析方法,其中,将实体链接结果、关键词抽取结果和命名实体识别结果进行处理,得到实体合并结果,包括:
确定实体链接结果、关键词抽取结果和命名实体识别结果的并集作为实体合并结果;
确定实体链接结果、关键词抽取结果和命名实体识别结果的交集作为实体合并结果。
进一步地,根据本发明提供的一种单篇文档分析方法,其中,基于关键词抽取结果和命名实体识别结果进行语义要素抽取,得到语义要素结果,包括:
基于关键词抽取结果确定语义要素中的what要素;
基于命名实体识别结果确定语义要素中的who要素、where要素和when要素。
进一步地,根据本发明提供的一种单篇文档分析方法,其中,基于实体链接结果进行关系扩展,得到关系扩展结果,包括:
基于实体链接结果所链接到的背景知识对所述文档中的实体进行关系扩展,得到关系扩展结果。
第二方面,本发明提供一种单篇文档分析装置,包括:
第一处理模块,用于获取待进行分析的文档;
第二处理模块,用于对所述文档进行分类;
第三处理模块,用于对所述文档进行实体链接,得到实体链接结果;
第四处理模块,用于对所述文档进行分句处理得到多个句子,并对得到的句子进行分词处理和词性标注处理;
第五处理模块,用于对分词和词性标注处理后的结果分别进行关键词抽取、命名实体识别以及实体开放关系抽取,得到关键词抽取结果、命名实体识别结果以及开放关系抽取结果;
第六处理模块,用于将实体链接结果、关键词抽取结果和命名实体识别结果进行处理,得到实体合并结果;
第七处理模块,用于基于关键词抽取结果和命名实体识别结果进行语义要素抽取,得到语义要素结果;
第八处理模块,用于基于实体链接结果进行关系扩展,得到关系扩展结果;
第九处理模块,用于根据分句得到的句子和实体合并结果进行共现关系计算,得到共现关系确定结果;
第十处理模块,用于基于关系扩展结果、开放关系抽取结果和共现关系确定结果,得到单篇文档的分析结果。
本发明提供的一种单篇文档的分析方法和装置,通过对获取的文档进行分句处理,并对分句后的句子进行分词和词性标注处理。另外,对获取的文档进行分类,并对获取的文档进行实体链接。然后对分词和词性标注处理后的结果进行关键词抽取和命名实体识别,继而,结合实体链接的词汇,对得到词汇结果进行合并。同时基于关键词抽取结果和命名实体识别结果进行语义要素抽取,得到语义要素结果。此外,对实体链接结果进行关系扩展,基于分词和词性标注后的结果进行开放关系抽取,得到开放关系抽取结果;根据分句得到的句子和实体合并结果进行共现关系确定;基于关系扩展结果、开放关系抽取结果和共现关系确定结果,得到单篇文档的分析结果。因此,本发明帮助用户对文档进行语义级别的快速查阅和分析,并帮助用户快速定位自己的感兴趣的新闻。
附图说明
为了更清楚地说明本发明或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作一简单地介绍,显而易见地,下面描述中的附图是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1是本发明提供的单篇文档的分析方法的流程示意图之一;
图2是本发明提供的单篇文档分析方法的流程示意图之二;
图3是本发明提供的单篇文档分析装置的结构示意图;
图4是本发明提供的电子设备的结构示意图。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚,下面将结合本发明中的附图,对本发明中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
下面结合图1-图2描述本发明的一种单篇文档的分析方法,包括:
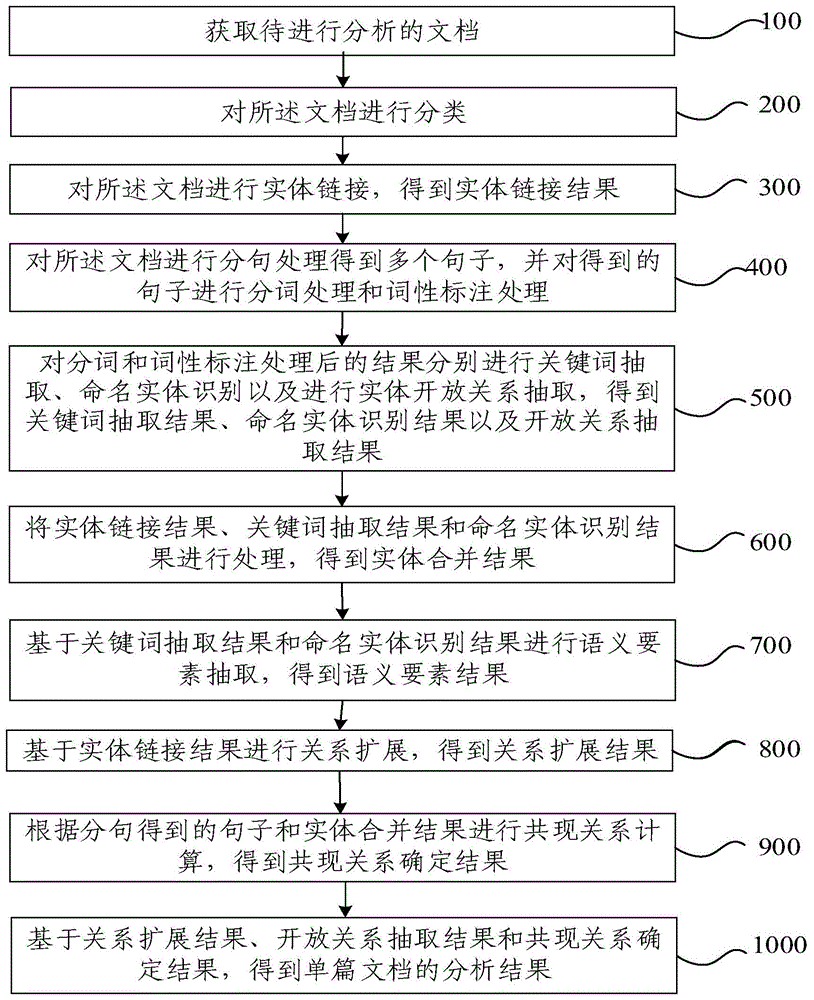
步骤100:获取待进行分析的文档。
步骤200:对所述文档进行分类。
步骤300:对所述文档进行实体链接,得到实体链接结果。
步骤400:对所述文档进行分句处理得到多个句子,并对得到的句子进行分词处理和词性标注处理。
步骤500:对分词和词性标注处理后的结果分别进行关键词抽取、命名实体识别以及实体开放关系抽取,得到关键词抽取结果、命名实体识别结果以及开放关系抽取结果。
步骤600:将实体链接结果、关键词抽取结果和命名实体识别结果进行处理,得到实体合并结果。
步骤700:基于关键词抽取结果和命名实体识别结果进行语义要素抽取,得到语义要素结果。
步骤800:基于实体链接结果进行关系扩展,得到关系扩展结果。
步骤900:根据分句得到的句子和实体合并结果进行共现关系计算,得到共现关系确定结果。
步骤1000:基于关系扩展结果、开放关系抽取结果和共现关系确定结果,得到单篇文档的分析结果。
具体地,步骤100中,获取待分析文档,通过数据挖掘技术获取各个新闻网站的新闻页面信息,此处的新闻网站可以是专门提供新闻信息的网站,可以包括国家大型新闻门户(如新华网、人民网等)、商业门户(新浪新闻、网易新闻等)、地方新闻门户(长江网等)、以及行业门户网站;还可以包括一些社交平台(新浪微博等)。也包括国外的主流媒体,例如“bbc、cnn”等,但不限于这些网站。本发明中不对获取文档的格式进行限定,不对获取文档的主题进行限定等等。
步骤200中对步骤100中获取的文档进行分类处理,如果针对多篇文章,则对文本按着篇章级别进行分类。分类可以采用决策树分类、最近邻分类、朴素贝叶斯分类、神经网络、支持向量机、基于深度学习的分类等方法,每篇新闻都可以得到一个分类。本发明通过使用基于bert的深度学习模型对文本进行预训练,得到分类模型,并使用分类模型对所有新闻篇章进行分类。按着“体育”、“财经”、“科技”、“军事”、“娱乐”、“健康”、“文化”、“社会”、“教育”、“其他”共10个分类,获取得到的新闻中标题为“中超-新援双响于汉超首球曹赟定直红申花3-1当代“为”体育“类别中的一篇。
步骤300中对获取的文档进行实体链接,其中实体链接是指给定文档和知识库,实体链接旨在识别出文本中的所有实体提及,并在知识库中找到每个实体提及对应的实体,如果知识库并未收录实体提及指代的实体,则需将映射到空实体。这里的知识库,又称为知识图谱,用来描述实体与实体之间的关系,将知识组织为有向图,表示知识图谱的所有节点,每个节点代表一个实体,实体拥有丰富的信息描述,例如实体类别、信息框、文本描述等,表示两个节点之间的关系集合。知识图谱还可被表示为三元组集合。而实体提及表示文本中提及实体的文本片段,其可能是一个词,也可能是几个连续的词。例如,篮球运动员“迈克尔·乔丹”在不同文档中可能出现不同的实体提及,“乔丹”或者“空中飞人”等。比如对前文提到的新闻标题为“中超-新援双响于汉超首球曹赟定直红申花3-1当代”对全文进行实体链接可以得到其中的重点词汇,同样对上文文本中的某句话“第28分钟元敏诚在禁区弧顶放倒毕津浩,博拉尼奥斯离门19米任意球直接射门得分,打进个人加盟申花后的首球。上半场上海申花1比0领先。“该句话进行实体链接,可以得到“禁区“、“毕津浩“、“博拉尼奥斯“、“申花“等实体链接结果。我们通过实体链接的功能,对每篇新闻都可以得到一个词表和每个词在原文中的位置,以及其对应的详细的背景介绍资料。实体链接后,也可以通过对相应背景资料的分析,得到和对应实体有一跳关系的实体及其关系。
步骤400中对步骤100中获取的文档进行分句处理,其中分句处理是按照语法规则对文档中构成一个完整句子的语句分出。比如在中文中将带有“。”、“?”、“;”和“……”等带有表示句子终结的符号的句子分解出来。在英文中将“.”、“?”等带有表示句子终结的符合的句子作为一个完整的句子分解出来。举例来说,来自“新浪”网站,标题为“中超-新援双响于汉超首球曹赟定直红申花3-1当代”新闻中“北京时间10月27日晚19点35分,2020年中超联赛第二阶段第二轮首回合(总第17轮)上海申花和重庆当代的比赛,在昆山体育中心开始。第15分钟莫雷诺抢球时受伤被迫退场,钱杰给替补上。第28分钟元敏诚在禁区弧顶放倒毕津浩,博拉尼奥斯离门19米任意球直接射门得分,打进个人加盟申花后的首球。”分句后结果为“北京时间10月27日晚19点35分,2020年中超联赛第二阶段第二轮首回合(总第17轮)上海申花和重庆当代的比赛,在昆山体育中心开始。”、“第15分钟莫雷诺抢球时受伤被迫退场,钱杰给替补上。”、“第28分钟元敏诚在禁区弧顶放倒毕津浩,博拉尼奥斯离门19米任意球直接射门得分,打进个人加盟申花后的首球。”共3句。
继而,对依据步骤400中的分句处理获得句子进行分词和词性标注。其中分词是指采用一定的方法将一个完整的句子按照语法规则或者语义进行拆分或肢解,得到独立的符合文档语境的词语、短语、字(包括单个汉字、单个英文字母等)和标点符号等。其中词性是词汇基本的语法属性,词性标注是在给定句子中判定每个词的语法范畴,确定其词性并加以标注的过程即对采用分词方法得到的分词结果按照语法规则对各个结果标注词性。距离来说,“最终,10人应战的申花队3比1战胜重庆当代。”,可以得到为精确分词结果为“最终/,/10/人/应战/的/申花队/3/比/1/战胜/重庆当代/。”,词性标注结果为“最终d/,wp/10m/人n/应战v/的u/申花队ni/3m/比v/1m/战胜v/重庆当代ni/。wp”。其中d代表副词,wp代表标点符号,m代表数词,n代表名字,v代表动词,u代表助词,ni代表机构团队。
其中“重庆当代”是由两个名词构成的复合名词,因此在进分词时可能出现“重庆”、“当代”以及“重庆当代”三种情形,故而,需要在分词时采用一定的方法使分词的结果符合上下文语境。
步骤500中,对分词和词性标注后的结果进行关键词抽取和命名实体识别以及实体开放关系抽取。而关键词抽取是指将文档中对于理解文档的核心信息具有重要意义的词汇提取出来,用来帮助用户理解文本的主要信息。比如,对上述标题为“中超-新援双响于汉超首球曹赟定直红申花3-1当代“的新闻提取关键词可以得到有”申花3-1当代”、“博拉尼奥斯梅开二度”、“足球”等。
另外,实体识别是指将文档中的所有实体提取出来,其中实体是表示现实世界中的具体事物,或者是抽象的概念。如人、机构、地点,或者“机器学习”、“人工智能”等。区别与大多数研究中的区别于大多数研究中的“命名实体”,本文中指的实体包括命名实体(主要指人物、组织机构、地点)、普通实体(如电影、书籍、歌曲、文化习俗、食物、材料等)和抽象概念(产生于人类抽象思维的无实物形态的概念)。在知识库中,一个实体可能对应多个概念,如,迈克尔·乔丹在维基百科中既属于类别"篮球运动员",又属于类别“总统自由勋章获得者”。其中的实体识别是指识别文本中具有特定意义的实体,主要包括人名、地名、机构名、专有名词等。举例说明,对上述标题为“中超-新援双响于汉超首球曹赟定直红申花3-1当代”的新闻进行实体识别可以得到组织机构有“上海申花”、“重庆当代”等,人名有“博拉尼奥斯”、“曹赟定”等,地点有“昆山体育中心”、“禁区”等。
同时,基于分词和词性标注后的结果进行开放关系抽取,得到开放关系抽取结果。开放关系抽取是指不需要预先定义关系,而是使用实体对上下文中的一些词语来描述实体之间的关系。例如“姚明出生于上海”中,开放关系抽取系统的抽取结果就是(姚明,出生于,上海),其中“姚明”和“上海”是存在关系的实体对,“出生于”代表关系。
步骤600中对步骤300中实体链接得到的词汇与步骤400中关键词抽取和命名实体识别得到结果进行实体合并处理。
步骤700中对步骤500中得到的关键词抽取结果和命名实体识别结果进行语义要素抽取。其中,要素抽取时识别出新闻文档中描述的与新闻事件相关的要素信息(包括when(何时)、where(何地)、what(何事)、who(何人)、why(为何)、how(如何))。同样,以上文中的标题为“中超-新援双响于汉超首球曹赟定直红申花3-1当代”的新闻进行命名实体识别的结果中可以得到who可以从人名和组织机构名得到“上海申花”、“重庆当代”、“博拉尼奥斯”、“曹赟定”等;where可以从地点等得到“昆山体育中心”、“禁区”等;when是从原始文本中抽取到“10月27日晚19点35分”、“2020年”、“第15分钟”等,从关键词提取的结果中可以得到what有“博拉尼奥斯梅开二度”等。
继而,在步骤800中,对实体链接结果进行关系扩展,具体说来,通过关系扩展,将实体链接中的背景知识带入实体之中,使得以前只能在文本之中的实体之间构建关系的范围得以扩展到相应的背景知识之中,因此,够给用户提供更加全面和精确信息。举例说明,美国篮球巨星“詹姆斯”,在该实体的背景知识中“勒布朗·詹姆斯(lebronjames),全名勒布朗·雷蒙·詹姆斯(lebronraymonejames),1984年12月30日出生于美国俄亥俄州阿克伦,美国职业篮球运动员,司职小前锋,绰号“小皇帝”,效力于nba洛杉矶湖人队。詹姆斯在2003年nba选秀中于首轮第1顺位被克利夫兰骑士队选中,在2009年与2010年蝉联nba常规赛最有价值球员(mvp)。2010年,詹姆斯转会至迈阿密热火队。2011年,依靠在国际体坛上的知名度,詹姆斯与芬威体育集团达成合作协议,他成了利物浦足球俱乐部的全球独家高级形象代表,而报酬则是利物浦的若干股权。2012年,詹姆斯得到nba个人生涯的第3座常规赛mvp,第1个总冠军和总决赛mvp,并代表美国男篮获得了伦敦国际顶级赛事的金牌,追平了迈克尔·乔丹在1992年所创的纪录。2013年,詹姆斯夺得第4个常规赛mvp、第2个nba总冠军和第2个总决赛mvp,实现两连冠。2014年,詹姆斯回归骑士。2016年,詹姆斯带领骑士逆转战胜卫冕冠军勇士夺得队史首个总冠军和个人第3个总决赛mvp。2018年7月10日,詹姆斯正式与湖人签下4年1.53亿美元的合同。2019-20赛季,詹姆斯当选nba助攻王,夺得第4次总冠军以及个人第4个总决赛mvp。詹姆斯篮球智商极高、突破犀利,拥有出色的视野和传球技术,被认为是nba有史以来最为全能的球员之一。2019年福布斯100名人榜,詹姆斯排名第17位。2020年12月27日,詹姆斯当选2020美联社最佳男运动员。”由上可知,通过实体链接将实体“詹姆斯”的关系扩展到与实体“利物浦”、“迈克尔〃乔丹”、“洛杉矶湖人”“克利夫兰骑士队”等实体之间的关系,这些关系不一定是实体“詹姆斯”所处的文档中能够体现出来的关系,因此通过实体链接将背景知识与实体“詹姆斯”结合在一起,实现对实体关系的扩展。
步骤900中,根据分句得到的句子和实体合并结果进行共现关系处理。共现关系是指两个实体处于一个句子或者实体合并后的结果之中,两个实体呈现出共同出现的状态。比如,上述新闻“中超-新援双响于汉超首球曹赟定直红申花3-1当代”中“第82分钟马尔西尼奥打算对秦升人球分过,结果秦升把马尔西尼奥撞翻吃到黄牌。”该句中有“马尔西尼奥”和“秦升”等实体,该两个实体在一句话之中,既可以得到两者为共现关系。另外,按照步骤700的开放关系抽取方法,对该句进行开放关系抽取可以得到(马尔西尼奥,撞翻,秦升),其中“马尔西尼奥”和“秦升”是存在关系的实体对,“撞翻”代表关系。
步骤1000中,基于关系扩展结果、开放关系抽取结果和共现关系结果确定单篇文档的分析结果。即通过将上述关系扩展结果、开放关系抽取结果、以及共线关系结果三者进行实体关系计算,得到该片文档的全面而概括的内容,本发明抽取的实体之间关系,包括以下三大类:第一类是语料(篇章)级关系抽取;第二类是句子级别关系,即为从一个句子中判别两个实体间是何种语义关系;第三类是从链接到的背景知识给出的关系。
其中,对事件文本进行语料级的实体关系抽取,是指从文本的上下文中抽取相应的两个实体之间的关系,比如事件“2020年10月12日新闻‘湖人总冠军!湖人时隔十年夺队史第17冠,詹皇获得总决赛fmvp’”从中可以得出实体“詹姆斯”与实体“湖人”之间的关系是“‘詹姆斯’效力于‘湖人’”。
其中对事件文本进行句子级的实体关系抽取,是指对事件文本中呈现语法状态的句子中表现的两个实体之间的关系,即从一个句子中判断两个实体间是何种关系。举例来说,句子“詹姆斯效力于洛杉矶湖人队”可以得到的两个实体为“詹姆斯”以及“洛杉矶湖人”而这两个实体之间的关系为“詹姆斯”“效力于”“洛杉矶湖人队”。
而对多个事件从实体链接得到的实体链接结果进行实体关系抽取,即实体之间的关系并不能从事件文本或句子中获取,但是在实体的背景知识中存在两个实体之间的关系的信息,比如“詹姆斯”这一实体的背景知识中“2011年,依靠在国际体坛上的知名度,詹姆斯与芬威体育集团达成合作协议,他成了利物浦足球俱乐部的全球独家高级形象代表,而报酬则是利物浦的若干股权。”可以获知,实体“詹姆斯”与实体“利物浦”之间的关系是“詹姆斯”是“利物浦”的一个股东。
通过采用这三种判断实体之间关系的方式,可以充分而全面地表现不同实体之间的关系,使读者能够获得更加全面的信息。
本发明提供的一种单篇文档的分析方法和装置,通过对获取的文档进行分句处理,并对分句后的句子进行分词和词性标注处理。然后对分词和词性标注处理后的结果进行实体链接、关键词抽取和命名实体识别,继而,对得到词汇结果进行合并。同时基于关键词抽取结果和命名实体识别结果进行语义要素抽取,得到语义要素结果。此外,对实体链接结果进行关系扩展,基于文档的实体对、文中的词语以及要素结果进行开放关系抽取;根据分句得到的句子和实体合并结果进行共现关系确定;基于关系扩展结果、开放关系抽取结果和共现关系确定结果,得到单篇文档的分析结果。因此,本发明帮助用户对文档行语义级别的快速查阅和分析,并帮助用户快速定位自己的感兴趣的新闻。
进一步地,在本发明的一个实施例中,对得到的句子进行分词处理,包括:
采用规则分词、统计分词、规则和统计混合分词三种方法中的一种或多种对得到的句子进行分词处理。
进一步地,所述规则分词是指通过维护字典,在切分语句时,将语句的每个字符串与词表中的词进行逐一匹配,如果匹配成功,则切分,否则不切分;其中,匹配方法包括正向最大匹配法、逆向最大匹配法以及双向最大匹配法。
所述统计分词是指统计预设文本,如果相连接的字在不同的文本中出现次数越多,则说明这些相连接的字为一个词;统计分词方法包括两步,第一步是建立统计语言模型,第二步是对文本进行词语划分;其中,统计分词包括有基于隐含马尔科夫hmm、条件随机场crf方法。
所述规则和统计混合分词是指先基于词典的方法进行分词,然后再用统计分词的方法进行辅助。
进一步地,根据本发明提供的一种单篇文档分析方法,其中,对获取的文档进行实体链接,包括:
建立词和实体的联合表示模型。
基于所述词和实体的联合表示模型,采用概率实体模型,建立所述文档中的连续字符与知识库中的实体的链接关系。
所述词和实体的联合表示模型包括skip-gram模型、知识库模型和锚文本上下文模型的组合;相应地,建立词和实体的联合表示模型,包括:
建立skip-gram模型,通过预测词的相邻词学习给定文本语料中词的表示;
建立知识库模型,通过预测目标实体相邻的实体来学习实体的表示;
建立锚文本上下文模型,将锚文本替换为相应的实体,预测该实体周围下文的词,将词和实体映射到同一个语义空间中;
在对所述词和实体的联合表示模型进行训练时,所述词和实体的联合表示模型的总目标为最大化三个模型目标函数的线性组合。
进一步地,基于所述词和实体的联合表示模型,采用概率实体模型,建立所述文档中的连续字符与知识库中的实体的链接关系,包括:
给定一个实体提及mi,根据实体从知识库中找出相关实体e;
根据实体e,生成出实体提及mi的上下文;
生成实体提及mi中的其他实体;
其中,给定输入文档d和实体提及mi,找出知识库中mi的对应实体的问题被确定为下述的形式:
其中,每个实体提及对应的生成过程是相互独立的,其中
p(e)是实体的先验分布,将实体的先验分布定义为在整个数据集上的先验分布;为了控制在不同领域先验不同而带来的影响,引入了影响因子α:
其中,ae,*是指向实体e的锚文本集合,a*,*是知识库kb中所有锚文本的集合;α=0表示实体先验为1,取值对后验概率p(e|m)没有影响,α=1表示先验概率不受任何控制;
其中,
将词向量对应的词汇表提前建立一个aho-corasick索引,直接使用aho-corasick算法匹配实体提及上下文中的词而不需要进行分词操作;
p(n|e)是给定实体e的上下文实体的概率分布;
其中,计算实体一致性的方法包括:找到当前处理的文档中初始的无歧义的实体,加入初始化的无歧义实体集合n,确定先验概率p^(e|m)>θ的实体为无歧义实体,其中,p^(e|m)=|ae,m|/|a*,m|;
按照从左向右或者从简单到复杂的顺序处理发现实体的提及{m1,m2,,m|m|},每次处理得到一个已消歧的实体后,加入集合n,集合n的向量表示为其中所有实体向量的平均:
其中,en表示无歧义的实体。
具体地,实体链接,给定文档和知识库,实体链接旨在识别出文本中的所有实体提及,并在知识库中找到每个实体提及对应的实体,如果知识库并未收录实体提及指代的实体,则需将映射到空实体。实体链接任务一般分为三个步骤:实体发现、候选实体生成和候选实体消歧。实体发现旨在识别出文档中的所有实体提及,候选实体生成则为每个实体提及找到其可能指代的知识库实体,称为候选实体集。候选实体消歧则是确定实体提及所指代的知识库实体。
本发明使用一种词和实体的联合表示模型。该模型主要基于skip-gram模型。skip-gram最先被提出来学习词的嵌入式表示,其中心思想是用目标词预测其上下文的词。本发明使用的词和实体的联合表示模型基于skip-gram模型有三个部分:1)常规的skip-gram模型,通过预测词的相邻词学习给定文本语料中词的表示;2)知识库模型,通过预测目标实体相邻的实体来学习实体的表示;3)锚文本上下文模型,将锚文本替换为相应的实体,预测该实体周围下文的词,将词和实体映射到同一个语义空间中。该联合表示模型在训练时,模型的总目标为最大化三个模型目标函数的线性组合。
同时,本发明可以将实体链接的过程看做是一个生成式的过程。给定一个实体提及mi,首先,根据实体的从知识库kb中找出一个相关实体e,然后,根据实体e,生成出实体提及mi的上下文,最后,生成实体提及mi中的其他实体。因此,给定输入文档d和实体提及mi,找出知识库中mi的对应实体的问题可以被推断为如式1的形式:
本发明假设每个实体提及对应的生成过程是相互独立的,其中
给定输入文档d和实体提及mi,最终的知识库中对应的实体是最大化后验概率p(ei|mi,d)的实体,因此,可以形式化为2:
p(e)是实体的先验分布。本发明将实体的先验分布定义为在整个数据集上的先验分布,即本发明是在电力客服领域的先验分布。在大规模的语料库中,一个实体被提及的次数越多,那么这个实体可能越被人们所熟知。然而,在不同的领域中,实体的先验概率可能是不同的,如在电力客服领域中,词语"系统内部过电压"指代电力客服领域“电力系统内容过电压”的概率就比在开放领域中更大。因此,为了控制在不同领域先验不同而带来的影响,本发明引入了一个影响因子α,如式3。
其中,ae,*是指向实体e的锚文本集合,a*,*是kb中所有锚文本的集合。α=0表示实体先验为1,即其取值对后验概率p(e|m)没有任何影响,α=1表示先验概率不受任何控制。
其中,
p(n|e)是给定实体e的上下文实体的概率分布。在有关联的上下文中,如一篇新闻,实体通常属于相同的话题,而且这些实体通常在语义空间中比较接近。因此,这个分布也可以看做是实体的话题一致性的分布。本发明设计了一个两步的计算实体一致性的方法。首先,本发明找到当前处理的文档中初始的无歧义的实体,加入初始化的无歧义实体集合n,本发明定义先验概率p^(e|m)>θ的实体为无歧义实体,其中,p^(e|m)=|ae,m|/|a*,m|,在系统中,本发明选取了θ=0.95;然后,本发明按照从左向右(lefttoright,l2r)或者从简单到复杂(simpletocomplex,s2c)的顺序处理发现到的实体的提及{m1,m2,,m|m|},每次处理得到一个已消歧的实体后,加入集合n,集合n的向量表示为其中所有实体向量的平均,即式5:
其中,en表示无歧义的实体。p(n|e)通过集合n的向量和候选实体的向量的余弦相似度计算。本发明发现s2c和l2r的处理顺序带来的结果之差并不明显,考虑到s2c的顺序还要进行一次排序,因此在具体实现时本发明采用了l2r的顺序。
在本实施例中,需要说明的是,实体链接,给定文档和知识库,实体链接旨在识别出文本中的所有实体提及,并在知识库中找到每个实体提及对应的实体,如果知识库并未收录实体提及指代的实体,则需将映射到空实体。
在本实施例中,实体链接这一部分,对于实体发现的结果{m1,m2,...,m|m|}和其对应的候选实体集合c1,c2,...,c|m|,实体链接为每个mi在其对应的候选实体集合ci中找到一对应的实体ei*。这部分主要包括两个工作:1)词和实体的联合表示学习;2)基于词和实体的联合表示,使用一个概率消歧模型进行实体链接。
下面对词和实体的联合表示进行解释和说明。本实施例使用一种词和实体的联合表示模型。该模型主要基于skip-gram模型。skip-gram最先被提出来学习词的嵌入式表示,其中心思想是用目标词预测其上下文的词。本发明使用的词和实体的联合表示模型基于skip-gram模型有三个部分:1)常规的skip-gram模型,通过预测词的相邻词学习给定文本语料中词的表示;2)知识库模型,通过预测目标实体相邻的实体来学习实体的表示;3)锚文本上下文模型,将锚文本替换为相应的实体,预测该实体周围下文的词,将词和实体映射到同一个语义空间中。
(1)词表示学习
给定一个包含t个词的词序列w1,w2,...,wt,skip-gram模型的目标是最大化下式中的目标函数:
其中,c是上下文窗口的大小,wt表示目标词,wt+j表示上下文的词。条件概率p(wt+j|wt)根据softmax进行计算,如下式所示:
其中,w是包含所有词的集合,vw和uw表示词w在矩阵v和矩阵u中的向量。
(2)知识库模型
在电力客服知识库中,每一个实体都有链接到其它实体的链接,本发明称之为“外链”。本发明使用实体之间的外链关系来学习实体之间的相关度。另一个度量实体之间相关度的方法是维基链接度量法(wikipedialink-basedmeasure,wlm),该方法被应用作为实体链接的特征。wlm按照下式计算:
其中,e是知识库kb中的实体,ce是有链接指向实体e的集合。wlm方法的假设是,拥有的链接集合的交集越多的实体越相关。受wlm方法的启发,基于skip-gram模型,可以将实体和实体的连接关系看做是词之间的上下文关系,因此,将知识库模型形式化为下式:
类似的,条件概率p(eo|ei)也可以利用softmax计算。
(3)锚文本上下文模型
如果只是将词的skip-gram模型和知识库模型拼接起来,词和实体并不在一个向量空间中,因此,可以利用锚文本,将锚文本替换为其表示的实体,基于skip-gram模型,用该实体预测其上下文中的词,该模型的目标函数为下式:
其中,a是锚文本集合,q是锚文本周围的上下文的词的集合。在训练时,模型的总目标为最大化三个模型目标函数的线性组合,如下式所示:
l=lw+le+la
下面对于概率实体模型进行详细介绍,可以将实体链接的过程看作是一个生成式的过程。给定一个实体提及mi,首先,根据实体的从知识库kb中找出一个相关实体e,然后,根据实体e,生成出实体提及mi的上下文,最后,生成实体提及mi中的其他实体。因此,给定输入文档d和实体提及mi,找出知识库中mi的对应实体的问题可以被推断为如下式的形式:
本实施例假设每个实体提及对应的生成过程是相互独立的,其中
在本实施例中,给定输入文档d和实体提及mi,最终的知识库中对应的实体是最大化后验概率p(ei|mi,d)的实体,因此,可以形式化为下式:
p(e)是实体的先验分布。本实施例将实体的先验分布定义为在整个数据集上的先验分布,例如可以是在电力客服领域的先验分布。在大规模的语料库中,一个实体被提及的次数越多,那么这个实体可能越被人们所熟知。然而,在不同的领域中,实体的先验概率可能是不同的,如在电力客服领域中,词语"系统内部过电压"指代电力客服领域“电力系统内容过电压”的概率就比在开放领域中更大。因此,为了控制在不同领域先验不同而带来的影响,本实施例引入了一个影响因子α,如下式:
其中,ae,*是指向实体e的锚文本集合,a*,*是kb中所有锚文本的集合。α=0表示实体先验为1,即其取值对后验概率p(e|m)没有任何影响,α=1表示先验概率不受任何控制。
其中,
p(n|e)是给定实体e的上下文实体的概率分布。在有关联的上下文中,如一篇新闻,实体通常属于相同的话题,而且这些实体通常在语义空间中比较接近。因此,这个分布也可以看做是实体的话题一致性的分布。本实施例设计了一个两步的计算实体一致性的方法。首先,本发明找到当前处理的文档中初始的无歧义的实体,加入初始化的无歧义实体集合n,本实施例定义先验概率p^(e|m)>θ的实体为无歧义实体,其中,p^(e|m)=|ae,m|/|a*,m|,在系统中,本实施例选取了θ=0.95;然后,本实施例按照从左向右(lefttoright,l2r)或者从简单到复杂(simpletocomplex,s2c)的顺序处理实体e的实体提及{m1,m2,,m|m|},每次处理得到一个已消歧的实体后,加入集合n,集合n的向量表示为其中所有实体向量的平均,即下式:
其中,en表示无歧义的实体。p(n|e)通过集合n的向量和候选实体的向量的余弦相似度计算。本实施例发现s2c和l2r的处理顺序带来的结果之差并不明显,考虑到s2c的顺序还要进行一次排序,因此在具体实现时本发明采用了l2r的顺序。
此外,下面对关于结果修剪的部分进行解释和说明。在经过实体发现和实体链接的过程之后,对于每个文档d本发明可以得到一个结果序列r={r1,r2,...,r|m|},ri=(mi,ei*,scorei),其中,scorei是实体链接结果中p(e|m)的值,本发明将其看做是实体链接的置信度。由于基于百科构建的词典数目庞大,因此在实体发现中将所有实体都保留下来的话难免会留下些许噪音实体。因此,本发明设计了一个简单的过滤算法进行最后结果的过滤,将r按照ri.scorei从高到底排序,保留前k%的结果为
在本实施例中,关于实体识别和实体链接数据的举例情况可以参照下表1和表2。
表1实体识别情况
表2实体链接情况
下面分别举个中文和英文的例子,知识库采用在维基百科和百度百科中,锚文本的数量庞大,的统计数据显示,英文维基页面中的锚文本约有近一千万条,百度百科中的锚文本约有三百多万条。丰富的锚文本为实体发现和实体链接提供了充足的数据支撑。通过分别抽取百度百科和英文维基中的锚文本,构建了锚文本词典。词典中的每个键可以看做是一个实体的提及,对应的值可以看做是知识库中对应该提及的实体。
表3部分锚文本词典展示
另外,由于英文维基中还包括消歧页面,即对于一个实体名字,给出了其可能指代的所有实体,将这一部分数据也加入了英文的锚文本词典中。最后,得到的锚文本词典的总量为:英文维基的锚文本词典共有4,843,616条实体提及-实体匹配对,百度百科共有2,895,610条实体提及-实体匹配对。
本发明在所有的锚文本中,应用以下过滤规则进行过滤:其中length取为1,prob取为0.01,count取为2。(取数范围可以放大)
1)去掉length(m)≤1的锚文本;
2)去掉link_prob(m)≤0.01的锚文本;
3)去掉count(m)≤2的锚文本。
下面举例进行说明,例如对于例子m1为“南京市长江大桥”,m2为“长江大桥”此时length(m1)和length(m2)分别为7和4,则存在length(m1)>length(m2),则保留m1。对于例子m1为“电采暖分时电价”,m2为“电采暖阶梯电价”此时length(m1)和length(m2)都是7,则length(m1)=length(m2),但是link_prob(m1)<link_prob(m2),本该情况下保留m2。
对于结果修剪部分,将∈取值为0.0008。(可以将范围放大)“将r按照ri.scorei从高到底排序,保留前k%的结果为
根据上面的技术方案可知,本实施例设计了一个无监督的基于词和实体联合表示的生成式概率模型,来解决实体的歧义性。
进一步地,本发明提供的一个实施例中,对分词和词性标注处理后的结果进行关键词抽取,包括:
本发明可以采用词频-逆文档频次算法(tf-idf,termfrequency-inversedocumentfrequency)、textrank、基于文法规则、潜在语义分析(latentsemanticanalysis,lsa)、潜在语义检索(latentsenmanticindex,lsi)等方法,可以得到一个关键词词表,和每个词在原文中的位置及重要性。
进一步地,本发明提供的一个实施例中,对分词和词性标注处理后的结果进行命名实体识别,包括:
采用基于规则的方法、基于特征的方法和基于神经网络的方法中的一种或多种对分词和词性标注处理后的结果进行命名实体识别。
进一步地,本发明提供的一个实施例中,将实体链接结果、关键词抽取结果和命名实体识别结果进行处理,得到实体合并结果,包括:
确定实体链接结果、关键词抽取结果和命名实体识别结果的并集作为实体合并结果;
确定实体链接结果、关键词抽取结果和命名实体识别结果的交集作为实体合并结果。
具体地,针对实体链接、关键词抽取和命名实体识别抽取出来的词汇交叉情况,所有得到的实体进行合并,我们针对词内的重叠以规则进行处理。例如原始句子为“abcdefghij”,其中每个字母代表一个字,例如其中实体链接链接到的词为“defg”,关键词或者命名实体识别提取为cd,则将结果修正为cdefg,关键词或者命名实体识别为cdefg,则将结果修正为cdefg,关键词或者命名实体识别为cdefgh,则将结果修正为cdefgh,关键词或者命名实体识别为de,则将结果修正为defg,关键词或者命名实体识别为defg,则将结果为defg。即表现为确定实体链接、关键词抽取和命名实体识别得到的词汇结果的并集作为实体合并结果。
若关键词或者命名实体识别为defgh,则将结果为defg,关键词或者命名实体识别为ef,则将结果修正为ef,关键词或者命名实体识别为efg,则将结果修正为efg。举例说来,使用实体链接结果得到有“中超联赛”,根据之前设置的规则,我们保留为“中超联赛”,我们对关键词抽取得到的结果进行修正且补充知识,文本中的“中超联赛”由实体链接中考虑上下文内容可以得到是足球领域的“中国足球超级联赛”,而关键词可能只能得到是“中超”,而“中超”可能指的是“中国排球超级联赛”、“中国羽毛球超级联赛“等赛事,则关键词则变为“中国足球超级联赛”,实体链接功能对关键词提取功能提供了消歧。其下级联赛分别是中国足球协会甲级联赛、中国足球协会乙级联赛及中国足球协会会员协会冠军联赛。”背景知识。即通过实体链接将中实体中的“中超联赛”是指“中国足球超级联赛”,而关键词中的“中超”可能指的是“中国排球超级联赛”、“中国羽毛球超级联赛“等赛事,即呈现多个子集,但是在本文档中,最终确定的“中超”指的是“中国足球超级联赛”,表现为对实体链接、关键词抽取和命名实体识别得到的词汇结果的交集作为实体合并结果。
进一步地,本发明提供的一个实施例中,基于关键词抽取结果和命名实体识别结果进行语义要素抽取,得到语义要素结果,包括:
基于关键词抽取结果确定语义要素中的what要素。
基于命名实体识别结果确定语义要素中的who要素、where要素和when要素。
具体地,对于对上述标题为“中超-新援双响于汉超首球曹赟定直红申花3-1当代“的新闻提取关键词可以得到有“申花3-1当代”、“博拉尼奥斯梅开二度”、“足球”等。对上述新闻进行实体识别可以得到组织机构有“上海申花”、“重庆当代”等,人名有“博拉尼奥斯”、“曹赟定”等,地点有“昆山体育中心”、“禁区”等。从原始文本中抽取到“10月27日晚19点35分”、“2020年”、“第15分钟”等。由上可知,从关键词提取中得到的三个关键词属于what的内容。而实体识别中的上海申花”、“重庆当代”等,人名有“博拉尼奥斯”、“曹赟定”等则是who,而“昆山体育中心”则属于where。同时,“10月27日晚19点35分”、“2020年”、“第15分钟”则是属于when的内容。
进一步地,本发明提供的实施例中,基于实体链接结果进行关系扩展,得到关系扩展结果,包括:
基于实体链接结果所链接到的背景知识对所述文档中的实体进行关系扩展,得到关系扩展结果。
举例说明,在“申花”的实体链接为“上海绿地申花足球俱乐部“的背景介绍,可以看到“莫雷诺”和“申花”的关系为“效力于”。在比如上文中“詹姆斯”的实体链接中“2011年,依靠在国际体坛上的知名度,詹姆斯与芬威体育集团达成合作协议,他成了利物浦足球俱乐部的全球独家高级形象代表,而报酬则是利物浦的若干股权。”可以获知,实体“詹姆斯”与实体“利物浦”之间的关系是“詹姆斯”是“利物浦”的一个股东。
具体地,对于上述各个实施例中的方法,举例说明如下:
首先,数据采集,我们采集2020年10月27日0点-24点的“新浪”、“搜狐”、“网易”、“凤凰网”、“cnn”“bcc”等新闻媒体的新闻文本。然后,对文本进行分句处理,例如来自“新浪”标题为“中超-新援双响于汉超首球曹赟定直红申花3-1当代”新闻中“北京时间10月27日晚19点35分,2020年中超联赛第二阶段第二轮首回合(总第17轮)上海申花和重庆当代的比赛,在昆山体育中心开始。第15分钟莫雷诺抢球时受伤被迫退场,钱杰给替补上。第28分钟元敏诚在禁区弧顶放倒毕津浩,博拉尼奥斯离门19米任意球直接射门得分,打进个人加盟申花后的首球。”分句后结果为“北京时间10月27日晚19点35分,2020年中超联赛第二阶段第二轮首回合(总第17轮)上海申花和重庆当代的比赛,在昆山体育中心开始。”、“第15分钟莫雷诺抢球时受伤被迫退场,钱杰给替补上。”、“第28分钟元敏诚在禁区弧顶放倒毕津浩,博拉尼奥斯离门19米任意球直接射门得分,打进个人加盟申花后的首球。”共3句。然后,分词及词性标注,分别对所有新闻中的文本使用基于字典和hmm(隐马尔科夫模型)相结合的方法,例如“最终,10人应战的申花队3比1战胜重庆当代。”,可以得到为精确分词结果为“最终/,/10/人/应战/的/申花队/3/比/1/战胜/重庆当代/。”,词性标注结果为“最终d/,wp/10m/人n/应战v/的u/申花队ni/3m/比v/1m/战胜v/重庆当代ni/。wp”。其中d代表副词,wp代表标点符号,m代表数词,n代表名字,v代表动词,u代表助词,ni代表机构团队。
然后,使用基于bert的深度学习模型对文本进行预训练,得到分类模型,并使用分类模型对所有新闻篇章进行分类。按着“体育”、“财经”、“科技”、“军事”、“娱乐”、“健康”、“文化”、“社会”、“教育”、“其他”共10个分类,获取得到的新闻中标题为“中超-新援双响于汉超首球曹赟定直红申花3-1当代“为”体育“类别中的一篇。
然后对全文进行实体链接可以得到其中的重点词汇,同样对上段文本中的某句话“第28分钟元敏诚在禁区弧顶放倒毕津浩,博拉尼奥斯离门19米任意球直接射门得分,打进个人加盟申花后的首球。上半场上海申花1比0领先。“该句话进行实体链接,可以得到“禁区”、“毕津浩”、“博拉尼奥斯”、“申花”等实体链接结果。
然后,我们对文本通过类tf-idf结合文法规则的方法进行关键词提取,对所有新闻文本进行关键词提取,其中对上述标题为“中超-新援双响于汉超首球曹赟定直红申花3-1当代“的新闻提取关键词可以得到有“申花3-1当代”、“博拉尼奥斯梅开二度”、“足球”等。
然后,我们对文本采用基于规则的方法进行实体识别,其中对上述标题为“中超-新援双响于汉超首球曹赟定直红申花3-1当代“的新闻实体识别可以得到组织机构有“上海申花”、“重庆当代”等,人名有“博拉尼奥斯”、“曹赟定”等,地点有“昆山体育中心”、“禁区”等。
再然后,使用实体链接结果得到有“中超联赛”,根据之前设置的规则,我们保留为“中超联赛”,我们对关键词抽取得到的结果进行修正且补充知识,文本中的“中超联赛”由实体链接中考虑上下文内容可以得到是足球领域的“中国足球超级联赛”,而关键词可能只能得到是“中超”,而“中超”可能指的是“中国排球超级联赛”、“中国羽毛球超级联赛”、等赛事,则关键词则变为“中国足球超级联赛”,实体链接功能对关键词提取功能提供了消歧。“背景知识。在“申花”的实体链接为“上海绿地申花足球俱乐部“的背景介绍,可以看到“莫雷诺”和“申花”的关系为“效力于”。
最后进行要素抽取的操作,从命名实体识别的结果中可以得到,who可以从人名和组织机构名得到“上海申花”、“重庆当代”、“博拉尼奥斯”、“曹赟定”等;where可以从地点等得到“昆山体育中心”、“禁区”等;when是从原始文本中抽取到“10月27日晚19点35分”、“2020年”、“第15分钟”等,从关键词提取的结果中可以得到what有“博拉尼奥斯梅开二度”等。
针对文本中“第82分钟马尔西尼奥打算对秦升人球分过,结果秦升把马尔西尼奥撞翻吃到黄牌。”该句中有“马尔西尼奥”和“秦升”等实体,该两个实体在一句话之中,既可以得到两者为共现关系。对该句进行开放关系抽取可以得到(马尔西尼奥,撞翻,秦升),其中“马尔西尼奥”和“秦升”是存在关系的实体对,“撞翻”代表关系。
下面对本发明提供的单篇文档分析装置进行描述,下文描述的单篇文档分析装置与上文描述的单篇文档分析方法可相互对应参照。
结合图3说明,本发明实施例中提供一种单篇文档分析装置,包括:
第一处理模块30,用于获取待进行分析的文档。
第二处理模块31,用于对所述文档进行分类。
第三处理模块32,用于对所述文档进行实体链接,得到实体链接结果。
第四处理模块33,用于对所述文档进行分句处理得到多个句子,并对得到的句子进行分词处理和词性标注处理。
第五处理模块34,用于对分词和词性标注处理后的结果分别进行关键词抽取、命名实体识别以及实体开放关系抽取,得到关键词抽取结果、命名实体识别结果以及开放关系抽取结果。
第六处理模块35,用于对实体链接结果、关键词抽取结果和命名实体识别结果进行处理,得到实体合并结果。
第七处理模块36,用于基于关键词抽取结果和命名实体识别结果进行语义要素抽取,得到语义要素结果。
第八处理模块37,用于基于实体链接结果进行关系扩展,得到关系扩展结果。
第九处理模块38,用于根据分句得到的句子和实体合并结果进行共现关系计算,得到共现关系确定结果。
第十处理模块39,用于基于关系扩展结果、开放关系抽取结果和共现关系确定结果,得到单篇文档的分析结果。
由于本发明实施例提供的装置,可以用于执行上述实施例所述的方法,其工作原理和有益效果类似,故此处不再详述,具体内容可参见上述实施例的介绍。
图4示例了一种电子设备的实体结构示意图,如图4所示,该电子设备可以包括:处理器(processor)410、通信接口(communicationsinterface)420、存储器(memory)830和通信总线440,其中,处理器410,通信接口420,存储器430通过通信总线440完成相互间的通信。处理器410可以调用存储器430中的逻辑指令,以执行上述各实施例提供的单篇文档分析方法。
此外,上述的存储器430中的逻辑指令可以通过软件功能单元的形式实现并作为独立的产品销售或使用时,可以存储在一个计算机可读取存储介质中。基于这样的理解,本发明的技术方案本质上或者说对现有技术做出贡献的部分或者该技术方案的部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质中,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)执行本发明各个实施例所述方法的全部或部分步骤。而前述的存储介质包括:u盘、移动硬盘、只读存储器(rom,read-onlymemory)、随机存取存储器(ram,randomaccessmemory)、磁碟或者光盘等各种可以存储程序代码的介质。
又一方面,本发明还提供一种非暂态计算机可读存储介质,其上存储有计算机程序,该计算机程序被处理器执行时实现以执行上述各实施例提供的单篇文档分析方法。
最后应说明的是:以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围。
- 还没有人留言评论。精彩留言会获得点赞!