一种基于多向语义的知识图谱复杂关系推理方法与流程
1.本发明涉及人工智能中知识图谱技术领域,具体地,涉及一种利用人工智能表示学习方法对知识图谱中复杂关系进行推理的方法。
背景技术:
2.随着人工智能技术的发展,知识图谱越来越得到学术界和工业界的关注,知识图谱在未来人工智能发展中起着举足轻重的作用。知识图谱是以头实体、尾实体及其之间存在的关系组成的三元组为基本单元,其中实体可以是现实世界中的实体,比如具体人名、地名、机构等,也可以代表属性的属性值或概念,比如某颜色等,关系可以是两个实体和实体之间的现实关系,比如夫妻关系、从属关系,也可以是实体和属性值之间的关系,比如年龄等。但随着互联网发展,每时每刻都在产生大量的数据,其中就产生大量的三元组知识,以至于每个实体会与其他实体之间存在复杂的关系。随着构建知识图谱规模的不断扩大,知识图谱内复杂的关系无法采取人工的方式进行补全。所以针对知识图谱关系推理补全问题出现了的大量相关研究。其中出现了一些将实体和关系映射为低维向量,再利用向量关系进行推理的研究,常称为表示学习方法,比如transe、transh和transr等关系推理方法。虽然这些模型在某些方面表现出其优势和创新,但是这些模型在利用语义信息进行复杂关系推理时,只考虑关系推实体的语义影响,没有考虑实体对实体的语义影响以及实体对关系的语义影响。比如(人类,吃,蔬菜)学习语义表示向量时,“人类”的语义信息应该受到“蔬菜”和“吃”的语义影响,同理“蔬菜”的语义信息同样应该受到“人类”和“吃”的影响,这样致使学习到的语义向量表示实体或关系语义信息不充分,最终影响对复杂关系的推理效果。
技术实现要素:
3.本发明针对现有技术中存在的上述不足,提供了一种基于多向语义的知识图谱复杂关系推理方法。
4.本发明是通过以下技术方案实现的。
5.一种基于多向语义的知识图谱复杂关系推理方法,包括:将知识图谱的训练样本数据集中的实体映射为两组低维空间向量表示;将知识图谱的训练样本数据集中的关系映射为两组低维空间向量和一维参数表示;随机选择知识图谱的训练样本数据集中的实体,替换训练样本正三元组的实体,生成训练负样本数据;根据训练样本正三元组和生成的训练负样本,定义训练过程中的目标函数为:式中,,其中表示正三元
组的距离函数,表示正三元组的对应负样本的距离函数;其中:或或式中,表示头实体对应于本身固有属性对应的语义信息表示,不因本身的性质影响尾实体或关系的语义信息表示;表示关系本身固有属性对应的语义信息表示,头实体或尾实体的固有属性对应的语义信息不因其而变化;表示尾实体对应于本身固有属性对应的语义信息表示,不因本身的性质影响头实体或关系的语义信息表示,关系或尾实体的固有属性对应的语义信息不因其而变化;表示头实体由于在三元组内对三元组内的关系和尾实体产生的语义影响,当关系和尾实体固定时,对关系和尾实体的影响随着头实体变化而变化;表示关系在三元组内对三元组内的头实体和尾实体产生的语义影响,头实体和尾实体固定时,对头尾实体的影响随着关系变化而变化;表示尾实体由于在三元组内对三元组内的关系和头实体产生的语义影响,当关系和头实体固定时,对关系和头实体的影响随着尾实体变化而变化;表示作为关系的动作本身受到头实体使动和尾实体被动信息的影响,同时应受到自身固有属性的影响,用来区分表示实体和关系;表示非线性变换,对应于注意力机制;表示一个m维的单位向量;为距离公式;将训练样本数据集中的实体映射结果和关系映射结果分别带入目标函数,优化得到知识图谱中每个实体或关系对应的向量表示;利用优化得到的向量表示,计算知识图谱三元组中实体和关系之间的距离值,并根据距离值进行关系推理。
6.优选地,所述将知识图谱的训练样本数据集中的实体映射为两组低维空间向量两组向量,包括:设知识图谱的训练样本数据集中的实体集合中共有n个实体,其中每一个实体映射为一个m维的向量和一个m维的向量。
7.优选地,对于知识图谱中的训练样本数据集中的实体集合中的每一个实体映射为向量和向量分别随机初始化为一个m维的向量,并限制其模长为1。
8.优选地,所述将知识图谱的训练样本数据集中的关系映射为两组低维空间向量和一维参数表示,包括:
设知识图谱的训练样本数据集中的关系集合中共有t个关系,其中每一个关系映射为一个m维度的向量、一个m维的向量和一个一维参数。
9.优选地,对于知识图谱中的训练样本数据集中的关系集合中的每一个关系映射为向量和向量分别随机初始化为一个m维的向量,并限制其模长为1,同时随机初始化一个一维参数。
10.优选地,所述生成训练负样本数据的方法,包括:对于训练样本中的正三元组s(h,r,t),随机从实体集合中选择一个实体,并随机替换三元组中的头实体h或尾实体t,生成负样本数据集;其中,其中,为设知识图谱的训练样本数据集中的关系集合。
11.优选地,将训练样本数据集中的实体映射结果和关系映射结果分别带入目标函数,对知识图谱中的实体与关系进行训练;经过训练后,最终得到每个实体或关系对应的映射向量,利用映射向量获得实体之间是否满足某种关系的可能性。
12.优选地,所述利用优化得到的向量表示,计算知识图谱三元组中实体和关系之间的距离值,包括:得到每组向量后,利用距离函数计算头实体h、关系r和尾实体t之间的距离大小;当距离值趋向于0时,判断知识图谱三元组为正三元组,获得其中所示关系;当距离值趋向于无穷大时,推荐候选实体进行知识图谱关系补全,并重新计算头实体h、关系r和尾实体t之间的距离大小。
13.根据本发明的另一个方面,提供了一种终端,包括存储器、处理器及存储在存储器上并能够在处理器上运行的计算机程序,所述处理器执行所述计算机程序时能够用于执行上述任一项所述的方法。
14.根据本发明的第三个方面,提供了一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时可用于执行上述任一项所述的方法。
15.由于采用了上述技术方案,与现在技术相比,本发明具有如下有益效果:本发明提供的基于多向语义的知识图谱复杂关系推理方法,在学习每个实体或关系对应的语义向量时,充分考虑实体在三元组内受到的多向语义影响,同时关系语义向量受到实体的语义影响,从而习得的向量更能表示每个实体或关系对应的语义信息。本发明提供的基于多向语义的知识图谱复杂关系推理方法,能够更好的模拟不同实体或关系在不同三元组“环境”下的语义信息,提高对复杂关系的推理效果。
附图说明
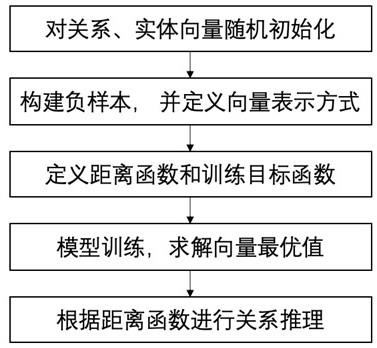
16.通过阅读参照以下附图对非限制性实施例所作的详细描述,本发明的其它特征、目的和优点将会变得更明显:图1为本发明一优选实施例中基于多向语义的知识图谱复杂关系推理方法流程
图。
具体实施方式
17.下面对本发明的实施例作详细说明:本实施例在以本发明技术方案为前提下进行实施,给出了详细的实施方式和具体的操作过程。应当指出的是,对本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。
18.本发明一实施例提供了一种基于多向语义的知识图谱复杂关系推理方法,该方法学习语义向量时,充分利用多向语义信息,更好的表示实体或关系对应的语义信息,进而提高对知识图谱中复杂关系的推理效果。
19.本实施例提供的基于多向语义的知识图谱复杂关系推理方法,可以包括如下步骤步骤1,将知识图谱的训练样本数据集中的实体映射为两组低维空间向量(低维空间向量在本领域用于表达有限长度的向量,比如200维的向量)表示;将知识图谱的训练样本数据集中的关系映射为两组低维空间向量和一维参数表示;步骤2,随机选择知识图谱训练样本数据集中的实体,替换训练样本正三元组的实体,生成训练负样本数据;步骤3,根据训练样本正三元组和生成的训练负样本,定义训练过程中的目标函数为:式中,,表示正三元组的距离函数,表示正三元组的对应负样本的距离函数;其中:或或式中,表示头实体对应于本身固有属性对应的语义信息表示,不因本身的性质影响尾实体或关系的语义信息表示,(如(“老虎”) 固有属性是食肉动物,关系(如“吃”)或尾实体(如“肉”)的固有属性对应的语义信息不因其而变化);表示该关系本身固有属性对应的语义信息表示,头实体(如“老虎”)或尾实体(如“肉”)的固有属性对应的语义信息不因其(如“吃”表示的关系属性)而变化;表示尾实体对应于本身固有属性对应的语义信息表示,不因本身的性质影响头实体或关系的语义信息表示,关系(如“吃”)或尾实体(如
“
肉”)的固有属性对应的语义信息不因其而变化);表示头实体由于在三元组内对三元组内的关系和尾实体产生的语义影响,当关系和尾实体固定时,对关系和尾实体的影响随着头实体变化而变化;表示关系在三元组内对三元组内的头实体和尾实体产生的语义影响,头实体和尾实体固定时,对头尾实体的影响随着关系变化而变化;表示尾实体由于在三元组内对三元组内的关系和头实体产生的语义影响,当关系和头实体固定时,对关系和头实体的影响随着尾实体变化而变化;表示由于关系是一个动作,动作本身受到头实体使动和尾实体被动信息的影响,同时应受到自身固有属性的影响,用来区分表示实体和关系(如老师可以是实体,三元组(老师,教,学生),也可以是关系,三元组(王二,老师,张三));表示非线性变换,对应于注意力机制;表示一个m维的单位向量;表示距离公式,minkowski distance;步骤4,将训练样本数据集中的实体映射结果和关系映射结果分别带入目标函数,优化得到知识图谱中每个实体或关系对应的向量表示;步骤5,利用优化得到的向量表示,计算知识图谱三元组中实体和关系之间的距离值,并根据距离值进行关系推理。
20.作为一优选实施例,将知识图谱的训练样本数据集中的实体映射为两组低维空间向量两组向量,包括:设知识图谱的训练样本数据集中的实体集合中共有n个实体,其中每一个实体映射为一个m维度的向量和一个m维的向量。
21.作为一优选实施例,对于知识图谱中的训练样本数据集中的实体集合中的每一个实体映射为向量和向量分别随机初始化为一个m维的向量,并限制其模长为1。
22.在此步骤中,此时只是随机映射,对应向量无法表示其对应的实体的语义信息,需要训练后得到准确的向量值。
23.作为一优选实施例,将知识图谱的训练样本数据集中的关系映射为两组低维空间向量和一维参数表示,包括:设知识图谱的训练样本数据集中的关系集合中共有t个关系,其中每一个关系映射为一个m维度的向量、一个m维的向量和一个一维参数。
24.作为一优选实施例,对于知识图谱中的训练样本数据集中的关系集合中的每一个关系映射为向量和向量分别随机初始化为一个m维的向量,并限制其模长为1,同时随机初始化一个一维参数。
25.在此步骤中,此时只是随机映射,对应向量无法表示其对应的实体的语义信息,需要训练后得到准确的向量值。
26.作为一优选实施例,生成训练负样本数据的方法,包括:
对于训练样本中正确的三元组s(h,r,t),随机从实体集合中选择一个实体,并随机替换三元组中的头实体h或尾实体t,生成负样本数据集;其中,其中,为设知识图谱的训练样本数据集中的关系集合。
27.在此步骤中,训练集为已知内容,利用该步骤训练得到对应的向量,使其满足对应的关系,从而判断是否三元组成立。
28.作为一优选实施例,将训练样本数据集中的实体映射结果和关系映射结果分别带入目标函数,对知识图谱中的实体与关系进行训练;经过训练后,最终得到每个实体或关系对应的映射向量,利用映射向量获得实体之间是否满足某种关系的可能性。
29.作为一优选实施例,利用优化得到的向量表示,计算知识图谱三元组中实体和关系之间的距离值,包括:得到每组向量后,利用距离函数计算头实体h、关系r和尾实体t之间的距离大小;当距离值趋向于0时,判断知识图谱三元组为正三元组,获得其中所示关系;当距离值趋向于无穷大时,推荐候选实体进行知识图谱关系补全,并重新计算头实体h、关系r和尾实体t之间的距离大小。
30.在本发明部分实施例中:头实体受尾实体和关系的多向语义影响,最终头实体h对应的表示向量为:为:尾实体受头实体和关系的多向语义影响,最终尾实体t对应的表示向量为:为:头实体受尾实体和关系的多向语义影响,最终头实体h对应的表示向量为:为:其中,表示为一个人工智能常用的非线性激活函数,如tanh、relu或softmax等非线性激活函数;表示哈达玛积(hadamard product)。
31.最终得到距离函数为:其中,表示欧氏距离或曼哈顿距离。
32.当实体h和实体t满足关系r时,期望三者对应的向量计算得到的距离趋向
于0,当实体h和实体t不满足关系r时,期望三者对应的向量计算得到的距离趋向于无穷大。
33.下面结合附图,对本实施例所提供的技术方案进一步描述如下。
34.如图1所示,本实施例所提供的方法,包括如下步骤:(1)实体和关系向量初试化:知识图谱的训练样本数据集中的实体映射为低维空间向量两组向量,即实体集合中共有n个实体,每个实体映射为一个m维度的向量和一个m维的向量;步骤(2)中,知识图谱的训练样本数据集中的关系映射为低维空间向量两组向量和一维参数表示,即关系集合中共有t个关系,每个实体映射为一个m维度的向量、一个m维的向量和一个一维参数。
35.例如:对于知识图谱中的实体集合中的每个实体映射为向量和向量分别随机初始化为一个m维的向量,并限制其模长为1;对于知识图谱中的关系集合中的每个关系映射为向量和向量分别随机初始化为一个m维的向量,并限制其模长为1,同时随机初始化一个一维参数。
36.(2)构建负样本,并定义向量表示方式对于训练样本中正确的三原组(h,r,t),随机从实体集合中随机选择一个实体,并随机替换头实体h或尾实体t,生成负样本数据集。
37.(3)语义向量表示最终计算:头实体受尾实体和关系的多向语义影响,最终头实体h对应的表示向量为:为:尾实体受头实体和关系的多向语义影响,最终尾实体t对应的表示向量为:为:头实体受尾实体和关系的多向语义影响,最终头实体h对应的表示向量为:为:其中表示为一个人工智能常用的非线性激活函数,如tanh、relu或softmax
等非线性激活函数;表示哈达玛积(hadamard product)。
38.定义距离函数和目标函数: 其中表示欧氏距离或曼哈顿距离。当实体h和实体t满足关系r时,我们期望三者对应的向量计算得到的距离趋向于0,当实体h和实体t不满足关系r时,我们期望三者对应的向量计算得到的距离趋向于无穷大。
39.训练的目标函数:式中,其中表示正三元组的距离值,表示正三元组对应负样本的距离值。
40.式中:或或
41.(4)模型训练、求解向量最优值及(5)进行关系推理利用最优算法对目标值函数进行优化,得到每个实体或关系对应的表示向量, 利用实体集内所有的实体替换尾实体或头实体,或利用关系集中所有的关系替换关系,根据距离函数计算替换后的三元组距离值,值越小表示对应三元组为正例的可能性越大。从而得到对应的推荐关系。
42.本发明另一实施例提供了一种终端,包括存储器、处理器及存储在存储器上并能够在处理器上运行的计算机程序,处理器执行计算机程序时能够用于执行上述实施例中任一项的方法。
43.可选地,存储器,用于存储程序;存储器,可以包括易失性存储器(英文:volatile memory),例如随机存取存储器(英文:random
‑
access memory,缩写:ram),如静态随机存取存储器(英文:static random
‑
access memory,缩写:sram),双倍数据率同步动态随机存取存储器(英文:double data rate synchronous dynamic random access memory,缩写:ddr sdram)等;存储器也可以包括非易失性存储器(英文:non
‑
volatile memory),例如快闪存储器(英文:flash memory)。存储器用于存储计算机程序(如实现上述方法的应用程序、功能模块等)、计算机指令等,上述的计算机程序、计算机指令等可以分区存储在一个或多个存储器中。并且上述的计算机程序、计算机指令、数据等可以被处理器调用。
44.上述的计算机程序、计算机指令等可以分区存储在一个或多个存储器中。并且上述的计算机程序、计算机指令、数据等可以被处理器调用。
45.处理器,用于执行存储器存储的计算机程序,以实现上述实施例涉及的方法中的各个步骤。具体可以参见前面方法实施例中的相关描述。
46.处理器和存储器可以是独立结构,也可以是集成在一起的集成结构。当处理器和存储器是独立结构时,存储器、处理器可以通过总线耦合连接。
47.本发明第三个实施例提供了一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时可用于执行本发明上述实施例中任一项所述的方法。
48.本发明上述实施例提供的基于多向语义的知识图谱复杂关系推理方法,将知识图谱三元组分别映射到低维空间中的两组向量;其中一组向量用于表示对应的固有信息,称为固有向量(),另一种向量表示为三元组内语义信息的交叉信息,称之为交叉向量();利用交叉向量分别产生对应的注意力机制权重向量();利用产生的权重向量对固有向量加权(对应具体实施中步骤3),产生不同实体或关系在不同三元组环境下的向量表示(,,);再利用头实体、a关系和尾实体满足头实体向量加关系向量与尾实体向量的哈夫曼距离计算();最终学习得到对应向量表示(对应具体实施中步骤1),利用哈夫曼距离进行知识图谱关系推理。本发明上述实施例所提供的基于多向语义的知识图谱复杂关系推理方法,结合了不同三元组环境下对应的语义信息差异(如:相同头实体h和关系r,不同尾实体t,得到不同的向量表示(,,)),与现实三元组语义信息更好的贴合,在知识图谱复杂关系推理任务上具有更高的准确性。
49.以上对本发明的具体实施例进行了描述。需要理解的是,本发明并不局限于上述特定实施方式,本领域技术人员可以在权利要求的范围内做出各种变形或修改,这并不影响本发明的实质内容。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1