一种端到端文本检测和识别方法与流程
本发明涉及视觉识别的技术领域,尤其涉及一种端到端文本检测和识别方法。
背景技术:
文字在人们日常生活中扮演着举足轻重的角色,它们以交通指示牌、海报广告语和包装袋上产品描述等形式为人们传递信息和知识。随着手机、车载相机等带有摄像功能的设备的普及,越来越多的文字以图像形式采集、传播和存储,从图像中自动检测和识别文字在智能交通、图像检测以及场景理解等领域具有广阔的应用前景,因此,相关研究在计算机视觉领域一直备受关注。
近年来,基于深度学习的网络模型在声(语音识别)、图(计算机视觉)、文(自然语言处理)三大领域独占鳌头,成为各相关任务的主要解决方案,与此同时,文本检测和识别也进入了深度学习时代。现有的基于深度学习的文本检测算法主要有三种:基于语义分割的网络模型、基于目标检测的网络模型和混合模型。基于语义分割的网络模型对文本图像进行像素级预测,并根据预测结果推断出各像素所属文本框的位置、形状和角度。基于目标检测的网络模型把文本当作一种特定目标,通过对大量预置文本框进行分类和回归预测直接输出目标文本框信息。虽然上述两种模型在文本检测上取得了优异性能,但它们各有缺点,譬如,基于语义分割的网络模型不是端到端的文本检测模型,为了从预测结果推断出目标文本框的信息,这类模型往往需要大量复杂的后处理操作,而基于目标检测的文本检测模型容易漏检宽高比较大的文本区域。混合型文本检测模型取两者之长,避两者之短,同时对像素和预置文本框进行预测,故能有效提高检测率,然而,因为这类模型需要多个并行或串行分支进行多种类型目标值的预测,它们具有网络结构复杂、计算效率低的问题。
现有基于深度学习的文本识别模型可根据其序列预测模块的不同划分为基于注意力机制的识别模型和基于联结时序分类(ctc)的识别模型。这两种模型均使用卷积神经网络(cnn)和长短时记忆网络(lstm)对文本图像进行特征提取以及对特征片段进行编码,不同的是,基于注意力机制的识别模型使用attention-gru或attention-lstm对特征序列进行解码,得到字符串序列输出,而基于ctc的识别模型使用前向-后向算法ctc进行帧级预测结果到字符串序列的映射。然而,上述两种识别模型均面临以下问题:一是对弯曲文本识别效果不佳,需要额外的文本矫正模块,此外,因为lstm只接受一维特征向量作为输入,故二维特征图需要使用展平或池化操作映射到一维空间,这样会导致图像的空间和结构信息被破坏,进而影响识别性能;二是对低分辨文本图像鲁棒性差,由于自然场景文本图像分辨率差异较大,前处理阶段的尺度归一化操作会导致低分辨率图像放大后变模糊,进而影响识别性能。
技术实现要素:
为了解决上述问题,本发明提出一种端到端文本检测和识别方法,该方法先基于语义分割思想过滤掉大部分的背景像素,然后,针对保留的文本像素进行预置文本框的分类和回归预测,直接输出目标文本框的位置和形状等信息,最后,算法设计一种数据自增强的带有特征相似性约束的识别器进行文本识别。
本发明可通过以下技术方案实现:
一种端到端文本检测和识别方法,利用对输入文本图像的语义分割结果过滤掉背景像素,生成预置文本框集,再对其中的预置文本框边缘上的多个基准点进行分类和回归预测,检测出目标文本框,然后利用尺度变换和空间变换对输入文本图像进行特征提取,并使用特征相似性约束策略对识别器进行训练,最后利用训练好的识别器对目标文本框中的字符序列进行识别。
进一步,生成预置文本框集的方法包括:建立包括字符序列的图像库,对其中的各个文本图像进行归一化处理,再先后使用全卷积网络和上采样网络对输入文本图像进行不同缩放比例的多尺度特征图提取,以此作为输入,利用多个卷积层结合sigmoid函数生成语义分割图,同时,利用rpn网络对多尺度特征图上的所有像素位置进行区域提议生成,然后,根据语义分割图设置概率阈值,过滤掉小于所述概率阈值的像素点对应的区域提议,剩下的区域提议集合记为预置文本框集。
进一步,生成预置文本框集的方法包括以下步骤:
步骤1:收集并扩展自然场景的文本图像数据集作为训练样本集,对其中的文本图像i中的一个文本区域r进行标注,表示为gtr=[(x1,y1),(x2,y2),…,(xn,yn),txt],其中(xn,yn)为文本区域r边缘上的第n个基准点的坐标,n为预定义的基准点总数,txt为文本区域r中的字符串内容;
步骤2:基于全卷积网络和上采样网络的多尺度特征提取:对样本进行归一化处理后,先使用全卷积网络对输入文本图片进行特征提取,生成缩放比例为1/2t,1/2(t+1),1/2(t+2)…1/2(t+u)的u组特征图f1,f2,…fu,再使用上采样网络进行特征提取,生成相同缩放比例的另外u组特征图f’1,f’2,…,f’u;
步骤3:以特征图f’1,f’2,…,f’u作为输入,使用多个卷积层计算语义分割所需特征图,然后使用sigmoid函数计算各尺度上像素点为文本的概率,即生成语义分割图s1,s2,…,su;
步骤4:使用rpn网络针对多尺度特征图上所有像素位置进行区域提议生成,根据语义分割图s1,s2,…,su中的值设置概率阈值,过滤掉小于所述概率阈值的像素点对应的区域提议,剩下的区域提议集合为预置文本框集b。
进一步,检测出目标文本框的方法包括:先使用roialign方法对每个预置文本框进行特征提取,生成指定长度的特征向量,然后使用全连接层对每个预置文本框进行分类预测,对其上等距离采样得到的基准点[(x’1,y’1),(x’2,y’2),…,(x’n,y’n)]进行回归预测,生成针对每个预置文本框的文本得分sc和基准点偏移量(δx1,δy1,δx2,δy2,…,δxn,δyn),保留文本得分sc大于设定得分阈值的预置文本框,并根据公式xti=x’i+δxi和yti=y’i+δyi计算出预置文本框回归后得到的基准点的位置,将其连接在一起,生成目标文本区域即为目标文本框。
进一步,生成目标文本框的方法包括以下步骤:
步骤(1):对于预置文本框集b中的不同大小的预置文本框,先使用roialign方法生成指定长度的特征向量,然后使用全连接层对每个预置文本框进行分类预测,对其上等距离采样得到的基准点[(x’1,y’1),(x’2,y’2),…,(x’n,y’n)]进行回归预测,生成针对每个预置文本框的文本得分sc和基准点偏移量(δx1,δy1,δx2,δy2,…,δxn,δyn);
步骤(2):保留文本得分sc大于设定得分阈值的文本区域,并根据公式xti=x’i+δxi和yti=y’i+δyi计算出回归后得到的基准点的位置,将其连接在一起,生成目标文本区域即为目标文本框,最后,采用非最大值抑制算法消除冗余的目标文本框。
进一步,对识别器进行训练的方法包括:先对由gtr=[(x1,y1),(x2,y2),…,(xn,yn),txt]标注的高度为h的输入文本图像t进行三次尺度变换,得到变换图像t1,t2,t3,并根据标注的基准点使用薄板样条变换进行扭曲矫正,得到高度为h1的变换图像t4;再使用全卷积网络对变换图像t1,t2,t3,t4进行二维特征提取,并根据特征图大小,对不同尺度的特征图进行多倍下采样以将它们映射到同一尺度空间,然后通过展平操作将二维特征转换到一维空间,利用全连接层组进行一维特征向量提取,其对应的特征向量为v1,v2,v3,v4,以此作为输入,计算特征相似性约束损失,并使用带有自注意力机制的全连接层进行字符串序列预测,根据预测结果计算字符串预测损失。最后,整个网络结构使用总损失函数即语义分割损失、预置文本框分类和回归损失、特征相似性约束损失以及字符串预测损失的线性组合进行端到端训练,得到最优的网络模型参数。
进一步,对所述目标文本框进行一次尺寸变换得到变换图像t’,再使用全卷积网络对变换图像t’进行二维特征提取,并根据特征图大小,对特征图进行采样映射到特定尺度空间,然后通过展平操作将二维特征转换到一维空间,并利用训练好的全连接层组进行一维特征向量提取,其对应特征向量为v’,以此作为输入,利用训练好的带有注意力机制的全连接层对目标文本框中的字符序列进行识别。
进一步,利用如下方程式表示所述变化图像t1,t2,t3,
其中,f(t,hi)表示在保持宽高比的情况下将输入文本图像t尺寸归一化到高度为hi,d(.)表示2倍下采样,u(.)表示2倍上采样,h1,h2,h3,thred1,thred2,thred3为预定义值且h1=2*h2=3*h3;
当目标文本框的高度hp>thred1时,t’=f(tp,h1);当thred1
注意力计算如下:
其中,
所述总损失函数的方程式如下:
其中,
本发明有益的技术效果在于:
(1)利用图像分割模块的预测结果过滤掉大部分背景像素极大地减少了待预测预置文本框数量,有利于提升模型效率。
(2)对预置文本框边缘上的基准点进行回归预测,有利于检测任意方向和形状的文本区域。
(3)利用尺度变换和空间变换进行数据增强,并使用特征相似性约束策略从文本图像中提取表达能力强的特征,有利于提升模型对弯曲文本和低分辨率文本图像识别的鲁棒性。
附图说明
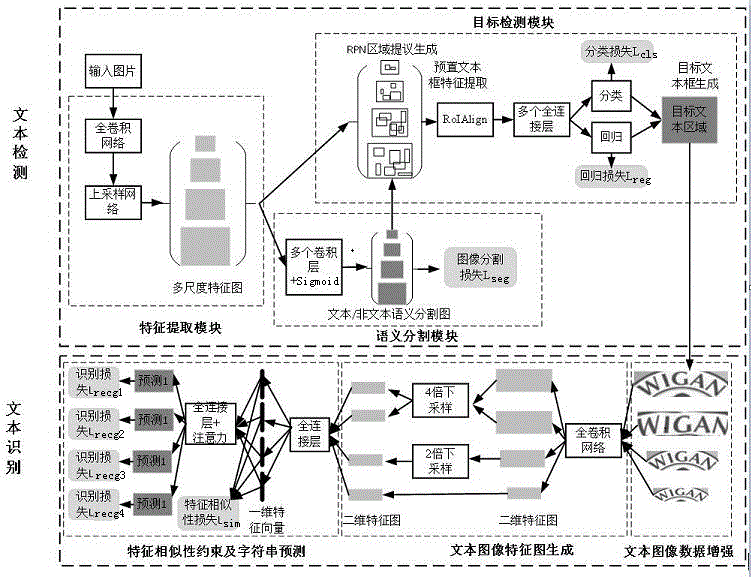
图1是本发明的检测和识别方法的实施框图;
图2是本发明的检测和识别方法的流程示意图。
具体实施方式
下面结合附图及较佳实施例详细说明本发明的具体实施方式。
如图1和2所示,本发明提供了一种端到端文本检测和识别方法,利用对输入文本图像的语义分割结果过滤掉背景像素,生成预置文本框集,再对其中的预置文本框边缘上的多个基准点进行分类和回归预测,检测出目标文本框,然后利用尺度变换和空间变换对输入文本图像进行特征提取,并使用特征相似性约束策略对识别器进行训练,最后利用训练好的识别器对目标文本框中的字符序列进行识别。具体包括如下步骤:
步骤1:收集并扩展自然场景文本图像数据集作为训练样本集;
收集公开数据库如icdar2015、icdar2017mlt、synthtext及totaltext等中的图像及其标注作为训练样本。然后,根据模型训练需求,对样本区域的标注进行扩展,即对文本区域边界进行基准点采样,作为文本区域新的标注方式。对于训练图像i中的一个文本区域r进行标注,可表示为gtr=[(x1,y1),(x2,y2),…,(xn,yn),txt],其中(xn,yn)为第n个基准点坐标,n为预定义的基准点总数,txt为文本区域的字符串内容。
步骤2:基于全卷积网络和上采样网络的多尺度特征提取;
训练阶段:对训练样本进行翻转、缩放、像素归一化等预处理,然后每批次随机裁剪8张大小为512*512的矩形区域作为网络输入进行模型训练;
测试阶段:在保持宽高比的前提下,将图片最长边归一化为1600或者2400,然后对图片进行像素归一化处理并以每批次1张作为网络输入。
为保证模型对文字大小的鲁棒性,网络首先使用全卷积网络如resnet-50对输入图片进行特征提取,生成缩放比例为1/2,1/4,1/8和1/16的四组特征图f1,f2,f3,f4。然后,为了融合高层特征和低层特征,网络使用上采样网络如fpn通过上采样的方式进行特征,生成相同缩放比例的另外四组特征图f’1,f’2,f’3,f’4。
步骤3:计算多尺度语义分割图;
以f’1,f’2,f’3,f’4作为输入,使用多个卷积层如2个3x3卷积层和1个1x1卷积层计算语义分割所需特征图,然后使用sigmoid函数计算各尺度上像素点为文本的概率,即生成语义分割图s1,s2,s3,s4,训练阶段,该步可计算得到语义分割损失lseg。
步骤4:使用rpn网络进行区域提议生成;
针对不同尺度特征图上各像素位置,rpn网络根据预定义的基尺寸、宽高比等超参,生成大量区域提议,即预置文本框。这些文本框的数量在百万级别,为减少待预测预置文本框数量,提升模型效率,本发明中的模型根据语义分割图s1,s2,s3,s4设置概率阈值,如0.3,先过滤掉一些背景像素点,如文本概率低于0.3的点,然后rpn网络只针对文本概率较高的像素点进行区域提议生成,得到预置文本框集b。或者利用rpn网络所有文本概率的像素点进行区域提议生成,设置概率阈值,过滤掉小于该概率阈值的像素点对应的区域提议,剩下的区域提议集合记为预置文本框集b。
步骤5:预置文本框分类和回归预测;
对于预置文本框集b中的不同大小的预置文本框,模型首先使用roialign生成特定长度的特征向量,然后使用全连接层进行分类和回归预测,生成针对每个预置文本框的文本得分sc和基准点偏移量(δx1,δy1,δx2,δy2,…,δxn,δyn)。现有算法一般只针对阈值文本框的中心点、宽、高或角点进行回归预测,因此回归后得到的目标文本框依然是矩形,对文本区域,特别是弯曲文本的形状不具有鲁棒性。本发明对阈值文本框上等距离采样得到的基准点[(x’1,y’1),(x’2,y’2),…,(x’n,y’n)]进行回归,可适用于任何文本形状。在训练阶段,根据训练图像上各文本框的基准点标注gtr=[(x1,y1),(x2,y2),…,(xn,yn),txt]和预测结果sc以及(δx1,δy1,δx2,δy2,…,δxn,δyn)可计算得到分类和回归损失lcls和lreg。
步骤6:目标文本框生成;
模型保留文本得分sc大于0.5的文本区域为目标文本区域,并根据公式xti=x’i+δxi和yti=y’i+δyi计算出该区域回归后得到的基准点的位置。然后,按顺序连接目标文本框上各基准点即可得到任意形状和方向的目标文本区域的位置。最后,非最大值抑制算法被用于消除冗余的目标文本框。
步骤7:识别器构建;
为了得到一个对文本扭曲、模糊和低分辨率鲁棒性较高的文本识别器,在训练阶段,我们对由gtr=[(x1,y1),(x2,y2),…,(xn,yn),txt]标注的高度为h的文本图像t进行三次尺度变换得到变换图像t1,t2,t3:
其中f(t,hi)表示在保持宽高比的情况下将图像t尺寸归一化到高度为hi,d(.)表示2倍下采样,u(.)表示2倍上采样,h1,h2,h3,thred1,thred2,thred3为预定义值且h1=2*h2=3*h3。此外,根据训练样本边缘上的基准点,使用薄板样条变换进行扭曲矫正,得到高度为h1的变换图像t4。训练阶段,t1,t2,t3和t4一起作为训练阶段识别器的输入,在测试阶段,由步骤6预测得到的本文图像tp只进行一次尺度变化得到t’,并将t’作为网络输入,其中当tp的高度hp>thred1时t’=f(tp,h1);当thred1
步骤8:文本图像的二维特征提取;
模型使用全卷积网络如resnet-32对t1,t2,t3,t4或者t’进行二维特征提取,并根据特征图大小,对不同大小的特征图进行4倍下采样或2倍下采样以将它们映射到同一尺度空间。
步骤9:利用全连接层组进行文本图像一维特征向量提取;
先通过展平操作将二维特征转换到一维空间,然后利用全连接层组进行文本图像一维特征向量提取。训练阶段t1,t2,t3,t4对应特征向量为v1,v2,v3,v4,测试阶段t’对应特征向量为v’。
步骤10:特征相似性约束计算;
该识别器旨在通过特征相似性约束,从扭曲、低分辨率和模糊图像t1,t2,t3中提取出与高分辨率、扭曲矫正后图像t4相似的特征。与现有识别器相比,该约束使本发明中提取到的一维特征更利于步骤11中的序列预测。因此,在得到对应特征向量v1,v2,v3,v4后,模型用如下公式计算特征相似性损失:
步骤11:字符序列输出预测;
该识别器使用带有注意力机制的全连接层从特征向量vi中推断出图片中的文本内容。该注意力用于强调与文本相关的特征,同时抑制背景对应特征,以提高识别器对文本图像中背景噪声的鲁棒性。注意力计算方式如下:
其中,
该总损失函数可以对文本检测模型和文本识别器进行端到端训练,得到最优模型参数。
技术人员应当理解,这些仅是举例说明,在不背离本发明的原理和实质的前提下,可以对这些实施方式做出多种变更或修改,因此,本发明的保护范围由所附权利要求书限定。
- 还没有人留言评论。精彩留言会获得点赞!