一种工艺参数驱动的天然气水露点在线预测方法
1.本发明涉及天然气集输领域,具体涉及一种工艺参数驱动的天然气水露点在线预测方法。
背景技术:
2.天然气水露点是天然气气质的一项重要技术指标。游离水的积聚会导致管线容量降低和腐蚀加剧,以及因水露点偏高而形成的水合物会导致管线、阀门堵塞。因此脱去天然气中的游离水是实际生产的重要任务之一。在实际生产中,通常使用天然气水露点仪监测天然气水露点。由于在实际监测中检测仪存在堵塞、传感器损坏等局限性,常规的使用天然气露点仪监测天然气水露点的方法无法准确有效的监测脱水性能。使用数据驱动方法预测天然气水露点避免了检测仪的缺陷,传统方法使用天然气接触器温度、三甘醇浓度和天然气压力等参数预测天然气水露点。在实际的脱水系统中,不仅是接触器温度和三甘醇浓度对天然气水露点有影响,各监测参数与天然气水露点也存在相互间的影响关系。针对现有检测技术和传统数据驱动方法的局限性,本发明通过梯度提升决策树(gradient boosting decision tree,gbdt)算法评估天然气原始特征集参数对天然气水露点敏感性,减少冗余或无关参数对露点预测的影响,实现关键参数的选择。通过参数选择后的训练样本对神经过程(nerual process,np)模型进行训练优化。优化后的np预测模型可以通过脱水装置的工艺监测参数实时的在线预测天然气水露点,实现脱水装置脱水性能的评估。
技术实现要素:
3.针对常规天然气水露点检测仪易损坏,检测成本高及传统数据驱动方法不能有效反应实际脱水系统天然气水露点与各监测参数间的影响关系的缺点,本发明公开了一种工艺参数驱动的天然气水露点在线预测方法,通过评估和选择对天然气水露点的关键参数,结合具有灵活执行非线性预测的np模型,实现一种脱水装置工艺参数的天然气水露点在线预测。
4.本发明通过下述技术方案实现:
5.一种工艺参数驱动的天然气水露点在线预测方法,包括以下步骤:
6.步骤s1:对于具有n个工艺监测参数的脱水系统,将各参数依次编号为参数1至参数n,n个工艺参数和天然气水露点的历史监测数据组成预测模型原始训练数据集,数据集共有p个样本,将各样本依次编号为样本1至样本p,该数据集以n个工艺参数为变量,天然气水露点为标签或目标值;
7.步骤s2:建立用于选择关键参数的梯度提升决策树(gradient boosting decision tree,gbdt)模型。所述gbdt模型是由回归树组成的加法模型。最新的决策树根据以已建立好的决策树模型建立,即构建当前的第t棵回归树时以前t
‑
1棵决策树的负梯度将作为回归树拟合的每个样本的新目标值,直至模型收敛时模型训练完成,当模型训练完成时计算n个工艺参数在各棵树中的平均重要程度来评估并选择重要参数,所述工艺参数j的
平均重要程度依据计算,所述m是gbdt建立的决策树的数量,l是二叉树的深度,假设每棵树都是二叉树,所述是节点t分裂前后的之后的平方损失依据l
t
=n
root
imp
root
‑
n
l
imp
l
‑
n
r
imp
r
计算,所述其中n
root
是节点分裂前的样本数量,n
l
是分裂后左节点的样本数量,n
r
是分裂后右节点的样本数量。imp
root
是节点分裂前的均方误差,imp
l
是分裂后左节点的均方误差,imp
r
是分裂后右节点的均方误差,确定所述gbdt模型的训练参数,损失函数,决策树的数量、决策树最大深度、学习率,所述损失函数决定决策树节点的分裂,所述决策树的数量、决策树最大深度和学习率是为了防止模型过拟合,利用训练集所有样本目标值的均值初始化模型f0(x);
8.步骤s3:训练模型第t棵回归树,所述1≤t≤m,计算第t
‑
1棵树分裂完成后的模型f
t
‑1(x)的负梯度,将负梯度作为每个样本的新目标值,所述回归树训练是节点分裂的过程,当达到树的最大深度或节点只有一个样本时停止分裂,当所有节点停止分裂时该回归树训练完成,所述回归树的分裂过程通过最小平方误差函数选择最优分裂特征和值,其最优分裂属性计算过程为:依次遍历该节点所有参数特征h=1,2,...,n
g
和第h个参数在该节点的样本值,即将第h个参数特征作为分裂变量,及将该参数特征的某个样本值s作为分裂条件值,依据值,依据选择最优分裂特征和分裂值,所述y
i
为样本目标值,γ1为r1所有样本目标值的均值和γ2为r2所有样本目标值的均值,计算当前回归树各叶节点均值a
ti
,通过线性搜索确定模型权重更新模型f
t
(x)=f
t
‑1(x)+γ
t
a
t
,所述f
t
(x)为第t棵树分裂完成后的模型a
t
为第t棵回归树各叶节点a
ti
组成的向量,第t棵回归树训练完成;
9.步骤s4:重复步骤s3,直到所有回归树训练完成,得到工艺参数特征选择的gbdt模型;
10.步骤s5:分别计算原始数据集n个工艺参数在gbdt各棵树中的平均重要程度并排序,得到各工艺参数对天然气水露点的重要程度,设定阈值选择关键工艺参数,得到特征选择后的n
′
个工艺参数,将选择的n
′
个参数依次编号为参数1至参数n
′
,n
′
个工艺参数为变量数据和天然气水露点监测数据为标签值或目标值组成特征选择后的数据集;
11.步骤s6:将特征选择后的训练数据集,按7∶3的比例划分训练上下文集和训练目标集,建立天然气水露点预测的神经过程(nerual process,np)模型,所述np模型结合了神经网络和高斯过程的优点,np模型由编码器和解码器组成,模型通过编码器生成高维随机隐变量z,将高斯过程的目标分布的预测转化为对隐变量z的计算,所述高维随机隐变量z服从多维高斯分布,所述编码器通过多层感知器(multilayer perceptron,mlp)生成中间变量并利用中间变量参数化高维随机隐变量z,该分布由中间变量通过mlp得到分布的均值向量和方差向量建立,所述中间变量利用n
′
个工艺参数数据和天然气水露点组成的点集通过mlp生成的数组取均值得到,所述生成中间变量的神经网络,输入层神经元个数由输入数据决定,共包含三个隐藏层,每个隐藏层128个神经元,输出层由128个神经元组成,对中间变量的神经网络的输出值取均值,并经一个128神经元的隐藏层和两个128神经元的输出层分
别生成高维随机隐变量z的均值向量μ和方差向量σ,对高维随机隐变量z采样,由于z由中间变量的神经网络的输出值取均值建立,对于一次输入,所有数据点具有相同的采样,将采样复制n
′
次,所述输入n
′
为n
′
个工艺参数数据和天然气水露点组成的点集的大小,采样扩展得到解码器的高维随机隐变量z的采样输入z
c
、z
t
,所述解码器分为模型优化和模型预测两部分,所述解码器由mlp建立,所述模型优化通过输入训练上下文集生成的采样z
c
、训练目标集生成的采样z
t
和训练目标集对模型进行优化,所述模型优化通过证据下界优化模型各参数,所述解码器神经网络,输入层神经元个数由输入数据决定,共包含两个隐藏层,每个隐藏层128个神经元,输出层由2个神经元组成,分别输出预测值和预测值的预测方差,所述模型预测将训练数据集作为上下文集,将新生成的监测数据作为目标集,所述目标集不包含目标值,通过上文集生成的采样z
c
和目标集自变量数据输入解码器神经网络实现目标预测,所述所有解码器和编码器中的数据输入,当包含多个输入时将多个输入以向量前后相连的形式组成一个新的单一的输入;
12.步骤s7:训练np模型,从训练上文集随机采样k个样本,该样本数量不低于训练上文集数量的30%,从训练目标集随机采样q个样本,该样本数量不低于训练目标集数量的30%,组成np模型的一次训练样本,将选取的训练样本送入np模型,通过np模型优化中的证据下界得到模型损失,所述模型损失即为单次训练损失;
13.步骤s8:重复步骤s7直至训练过程收敛,得到天然气水露点预测模型;
14.步骤s9:进行天然气水露点在线预测,对于脱水系统实时工艺参测数据,将训练数据集作为上下文集,将新的监测数据作为步骤6中的目标集,将该上文集和目标集输入np模型,通过解码器的目标预测实现天然气水露点在线预测。
15.本发明的原理为,通过gbdt算法评估和选择原始数据集中的重要参数,减少冗余或无关特征对预测结果的影响.以提高天然气水露点的预测精度;将训练数据集分为训练上文集和训练目标集,从训练上文集和训练目标集采样组成多维样本序列,作为np模型的训练样本,以工艺监测参数建立天然气水露点预测模型可以充分利用生产系统中各相关参数与露点的影响关系;np模型通过高维随机变量参数化目标函数,通过神经网络模拟实现了高斯过程,且可以自适应的学习高斯过程的核函数,可以充分学习生产系统中各相关参数与露点的影响关系;通过训练优化的np模型,对于新的工艺监测参数,可以实时在线预测天然气水露点。
16.进一步地,步骤s6中编码器阶段增加训练目标集与训练上下文集的注意力机制,所述注意力机制充分利用了训练上下文集的信息,并为重要的上下文点赋予了该模型更多的权重,将重要的上下文点赋予更多的权重以提高学习效率和预测效果,所述注意力机制通过训练上下文集的自变量、训练目标集的自变量和训练上下文集生成,训练上下文集通过mlp生成中间表表达式r,所述r神经网络由三个隐藏层,每个隐藏层128个神经元,输出层由128个神经元组成,同时将训练上下文集的自变量、训练目标集的自变量通过一个128个神经元的隐藏层和128个神经元组成的输出层的mlp生成训练上下文集的自变量的中间表述k和训练目标集的自变量的中间表述q,通过laplace(q,k,r):=wr,计算注意力机制,在模型预测时,上下文集和目标集的注意力机制计算过程与训练时训练上下文集的自变量和训练目标集的自变量的计算过程相同,注意力机制在编码阶段生成,在解码阶段解码器增加注意力机制输入,并在解码阶段模型优化和预测都使用注意力机制。
17.本发明具有较高的预测精度,是实现天然气水露点在线预测的有效方法,常规检测仪受到检测仪堵塞、传感器损坏等因素的影响,导致天然气水露点检测成本高,准确度差;及传统数据驱动方法仅使用少数相关状态参数不能有效反应脱水系统各监测参数与天然气水露点的关系,导致天然气水露点准确度差,本发明通过选取关键参数组成高维数据集结合np可自适应学习复杂数据集函数关系的特性,一种工艺监测数据本身学习各参数间的耦合关系,可以较高精度实现脱水系统天然气水露点的在线预测。
附图说明
18.此处所说明的附图用来提供对本发明实施例的进一步理解,构成本申请的一部分,并不构成对本发明实施例的限定。在附图中:
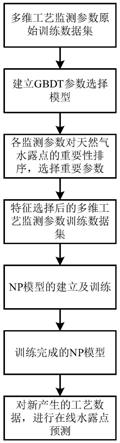
19.图1为本发明一种工艺参数驱动的天然气水露点在线预测方法实现流程图;
20.图2为gbdt模型示意图。
21.图3为np模型示意图。
具体实施方式
22.为使本发明的目的、技术方案和优点更加清楚明白,下面结合实施例和附图,对本发明作进一步的详细说明,本发明的示意性实施方式及其说明仅用于解释本发明,并不作为对本发明的限定。
23.实施例一:
24.本发明一种工艺参数驱动的天然气水露点在线预测方法实现流程图如图1所示,包括以下步骤:
25.步骤s1:对于具有n个工艺监测参数的脱水系统,将各参数依次编号为参数1至参数n,n个工艺参数和天然气水露点的历史监测数据组成预测模型原始训练数据集,数据集共有p个样本,将各样本依次编号为样本1至样本p,该数据集以n个工艺参数为变量,天然气水露点为标签或目标值;
26.如针对某天然气三甘醇脱水装置,监测参数包括各子部件的吸收塔压力、三甘醇循环量、闪蒸罐液位、压力控制阀开度、瞬时处理量、重沸器温度、精馏柱温度等33个工艺监测参数,以及天然气水露点日检测数据,共有495个样本,以所有历史数据作为原始训练数据集。
27.步骤s2:建立用于选择关键参数的梯度提升决策树(gradient boosting decision tree,gbdt)模型。所述gbdt模型是由回归树组成的加法模型。最新的决策树根据以已建立好的决策树模型建立,即构建当前的第t棵回归树时以前t
‑
1棵决策树的负梯度将作为回归树拟合的每个样本的新目标值,直至模型收敛时模型训练完成,当模型训练完成时计算n个工艺参数在各棵树中的平均重要程度来评估并选择重要参数,所述工艺参数j的平均重要程度依据计算,所述m是gbdt建立的决策树的数量,l是二叉树的深度,假设每棵树都是二叉树,所述是节点t分裂前后的之后的平方损失依据l
t
=n
root
imp
root
‑
n
l
imp
l
‑
n
r
imp
r
计算,所述其中n
root
是节点分裂前的样本数量,n
l
是分裂后左节点的样本数量,n
r
是分裂后右节点的样本数量。imp
root
是节点分裂前的均方误差,imp
l
是
分裂后左节点的均方误差,imp
r
是分裂后右节点的均方误差,确定所述gbdt模型的训练参数,损失函数,决策树的数量、决策树最大深度、学习率,所述损失函数决定决策树节点的分裂,所述决策树的数量、决策树最大深度和学习率是为了防止模型过拟合,利用训练集所有样本目标值的均值初始化模型f0(x);
28.针对该三甘醇脱水装置原始训练数据集,以所有工艺监测数据组成高维自变量,以天然气水露点为因变量,以平方误差函数为损失函数,决策树的数量100、决策树最大深度3、学习率0.1,建立初始模型。
29.步骤s3:训练模型第t棵回归树,所述1≤t≤m,计算第t
‑
1棵树分裂完成后的模型f
t
‑1(x)的负梯度,将负梯度作为每个样本的新目标值,所述回归树训练是节点分裂的过程,当达到树的最大深度或节点只有一个样本时停止分裂,当所有节点停止分裂时该回归树训练完成,所述回归树的分裂过程通过最小平方误差函数选择最优分裂特征和值,其最优分裂属性计算过程为:依次遍历该节点所有参数特征h=1,2,...,n
g
和第h个参数在该节点的样本值,即将第h个参数特征作为分裂变量,及将该参数特征的某个样本值s作为分裂条件值,依据值,依据选择最优分裂特征和分裂值,所述y
i
为样本目标值,γ1为r1所有样本目标值的均值和γ2为r2所有样本目标值的均值,计算当前回归树各叶节点均值a
ti
,通过线性搜索确定模型权重更新模型f
t
(x)=f
t
‑1(x)+γ
t
a
t
,所述f
t
(x)为第t棵树分裂完成后的模型a
t
为第t棵回归树各叶节点a
ti
组成的向量,第t棵回归树训练完成;
30.gbdt模型通过串行各树计算残差的梯度方向来使模型达到最优,为模型添加新树,不断增加新树以计算当前模型残差的梯度方向,以提高模型的准确度。
31.步骤s4:重复步骤s3,直到所有回归树训练完成,得到工艺参数特征选择的gbdt模型;
32.当训练损失收敛后结束训练,模型训练完成。
33.步骤s5:分别计算原始数据集n个工艺参数在gbdt各棵树中的平均重要程度并排序,得到各工艺参数对天然气水露点的重要程度,设定阈值选择关键工艺参数,得到特征选择后的n
′
个工艺参数,将选择的n
′
个参数依次编号为参数1至参数n
′
,n
′
个工艺参数为变量数据和天然气水露点监测数据为标签值或目标值组成特征选择后的数据集;
34.进行关键参数选择时,通过计算天然气三甘醇脱水装置各工艺监测参数在gbdt模型中各树中的程度得到。将所有参数的重要性排名后,设定阈值选择重要参数。对于该脱水装置选择了出吸收塔富甘醇温度、吸收塔差压、计量温度、吸收塔磁浮子液位、三甘醇入泵前温度等15个关键参数。将关键参数和天然气水露点组成新的训练数据集,关键参数为自变量,天然气水露点为标签或目标值。
35.步骤s6:将特征选择后的训练数据集,按7∶3的比例划分训练上下文集和训练目标集,建立天然气水露点预测的神经过程(nerual process,np)模型,所述np模型结合了神经网络和高斯过程的优点,np模型由编码器和解码器组成,模型通过编码器生成高维随机隐变量z,将高斯过程的目标分布的预测转化为对隐变量z的计算,所述高维随机隐变量z服从
多维高斯分布,所述编码器通过多层感知器(multilayer perceptron,mlp)生成中间变量并利用中间变量参数化高维随机隐变量z,该分布由中间变量通过mlp得到分布的均值向量和方差向量建立,所述中间变量利用n
′
个工艺参数数据和天然气水露点组成的点集通过mlp生成的数组取均值得到,所述生成中间变量的神经网络,输入层神经元个数由输入数据决定,共包含三个隐藏层,每个隐藏层128个神经元,输出层由128个神经元组成,对中间变量的神经网络的输出值取均值,并经一个128神经元的隐藏层和两个128神经元的输出层分别生成高维随机隐变量z的均值向量μ和方差向量σ,对高维随机隐变量z采样,由于z由中间变量的神经网络的输出值取均值建立,对于一次输入,所有数据点具有相同的采样,将采样复制n
′
次,所述输入n
′
为n
′
个工艺参数数据和天然气水露点组成的点集的大小,采样扩展得到解码器的高维随机隐变量z的采样输入z
c
、z
t
,所述解码器分为模型优化和模型预测两部分,所述解码器由mlp建立,所述模型优化通过输入训练上下文集生成的采样z
c
、训练目标集生成的采样z
t
和训练目标集对模型进行优化,所述模型优化通过证据下界优化模型各参数,所述解码器神经网络,输入层神经元个数由输入数据决定,共包含两个隐藏层,每个隐藏层128个神经元,输出层由2个神经元组成,分别输出预测值和预测值的预测方差,所述模型预测将训练数据集作为上下文集,将新生成的监测数据作为目标集,所述目标集不包含目标值,通过上文集生成的采样z
c
和目标集自变量数据输入解码器神经网络实现目标预测,所述所有解码器和编码器中的数据输入,当包含多个输入时将多个输入以向量前后相连的形式组成一个新的单一的输入;
36.高斯过程预测值是概率的,可以自适应进行拟合和回归。脱水装置或其他工业设备多维监测数据的分布复杂,难以准确的选择核函数。np模型通过引入高维随机变量,将高斯过程建模过程转化为对高维随机变量的计算,所属高维随机变量通过神经网络建立。从而摆脱了核函数的限制,可以自适应的学习脱水装置复杂多维工艺监测数据的分布规律,实现准确的回归计算。
37.步骤s7:训练np模型,从训练上文集随机采样k个样本,该样本数量不低于训练上文集数量的30%,从训练目标集随机采样q个样本,该样本数量不低于训练目标集数量的30%,组成np模型的一次训练样本,将选取的训练样本送入np模型,通过np模型优化中的证据下界得到模型损失,所述模型损失即为单次训练损失;
38.将脱水装置训练数据集,按照7:3的比例分为训练上下文集和训练目标集,每次训练时从训练上下文集随机采样105个数据点和训练目标集随机采样45个数据点组成一次训练样本,通过采样的方式可以降低时间复杂度。然后通过证据下界计算目标集预测值和目标集实际值的损失。
39.步骤s8:重复步骤s7直至训练过程收敛,得到天然气水露点预测模型;
40.当训练损失收敛后结束训练,np模型训练完成。
41.步骤s9:进行天然气水露点在线预测,对于脱水系统实时工艺参测数据,将训练数据集作为上下文集,将新的监测数据作为步骤6中的目标集,将该上文集和目标集输入np模型,通过解码器的目标预测实现天然气水露点在线预测。
42.进行天然气水露点在线预测,将脱水装置新产生的实时工艺监测参数数据作为目标集,以训练集数据作为上下文集,组成在线预测数据样本,通过训练好的np预测模型实现天然气水露点在线预测。
43.进一步地,步骤s6中编码器阶段增加训练目标集与训练上下文集的注意力机制,所述注意力机制充分利用了训练上下文集的信息,并为重要的上下文点赋予了该模型更多的权重,将重要的上下文点赋予更多的权重以提高学习效率和预测效果,所述注意力机制通过训练上下文集的自变量、训练目标集的自变量和训练上下文集生成,训练上下文集通过mlp生成中间表表达式r,所述r神经网络由三个隐藏层,每个隐藏层128个神经元,输出层由128个神经元组成,同时将训练上下文集的自变量、训练目标集的自变量通过一个128个神经元的隐藏层和128个神经元组成的输出层的mlp生成训练上下文集的自变量的中间表述k和训练目标集的自变量的中间表述q,通过计算注意力机制,在模型预测时,上下文集和目标集的注意力机制计算过程与训练时训练上下文集的自变量和训练目标集的自变量的计算过程相同,注意力机制在编码阶段生成,在解码阶段解码器增加注意力机制输入,并在解码阶段模型优化和预测都使用注意力机制。
44.对于目标集中数据点接近某个上下文集点时,该目标点预测值应接近该上下文点的天然气水露点值。通过计算目标点和上下文点之间的注意力机制,为重要的上下文点赋予更多的权重,以提高训练和预测效果。
45.以上所述的具体实施方式,对本发明的目的、技术方案和有益效果进行了进一步详细说明,所应理解的是,以上所述仅为本发明的具体实施方式而已,并不用于限定本发明的保护范围,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1