一种基于深度学习的交通事故智能检测方法
本发明涉及深度学习的图像与视频分析技术领域,尤其涉及一种基于深度学习的交通事故智能检测方法。
背景技术:
随着深度学习的不断发展,人们对图像识别领域的研究也更加深入。而全球道路交通事故死亡逐渐被认为是主要的公共卫生问题之一,将基于深度学习的图像与视频分析技术应用于交通事故视频监控系统上,可以无需人力,自主检测交通事故,并及时告知相关人员已经发生交通事故,这样就可及早为事故受害者提供抢救服务,还可规避二次事故发生,大大减少甚至避免人员伤亡和财务损失。
现在应用在检测交通事故领域的方法很多:有基于高斯混合模型(gmm)从视频镜头中提取前景和背景,以检测车辆,再基于均值偏移算法跟踪检测到的车辆,通过收集车辆位置、加速度和行驶车辆方向这些参数并分析其变化,作为事故决策依据;也有基于支持向量机实现、基于随机森林实现、基于轨迹聚类技术实现或者在车上安装硬件传感器进行监控等方法实现。但是交通事故形态多样、特征复杂,而且影响交通事故判断的外界因素也有很多,比如天气变化、道路环境、视频监控角度、设备状态等,所以在现有的检测算法里,尤其是基于传统目标检测方法实现的算法,都存在着一些缺陷:易受天气变化、道路环境变化的影响,导致检测精度不高;部分算法只能检测出发生了交通事故,却无法检测出属于哪一类事故场景;算法运算时间长,内存消耗大。
技术实现要素:
为解决现有技术所存在的技术问题,本发明提供一种基于深度学习的交通事故智能检测方法,通过采用表征能力强的resnet-50网络结构检测交通事故,来降低天气变化、道路环境变化对算法的影响,采取了检测速度快的yolov3算法来实现具体交通事故场景的检测,并且优化了网络结构,解决了算法运算时间长,检测细粒度低的问题,并实现检测精度的提高。
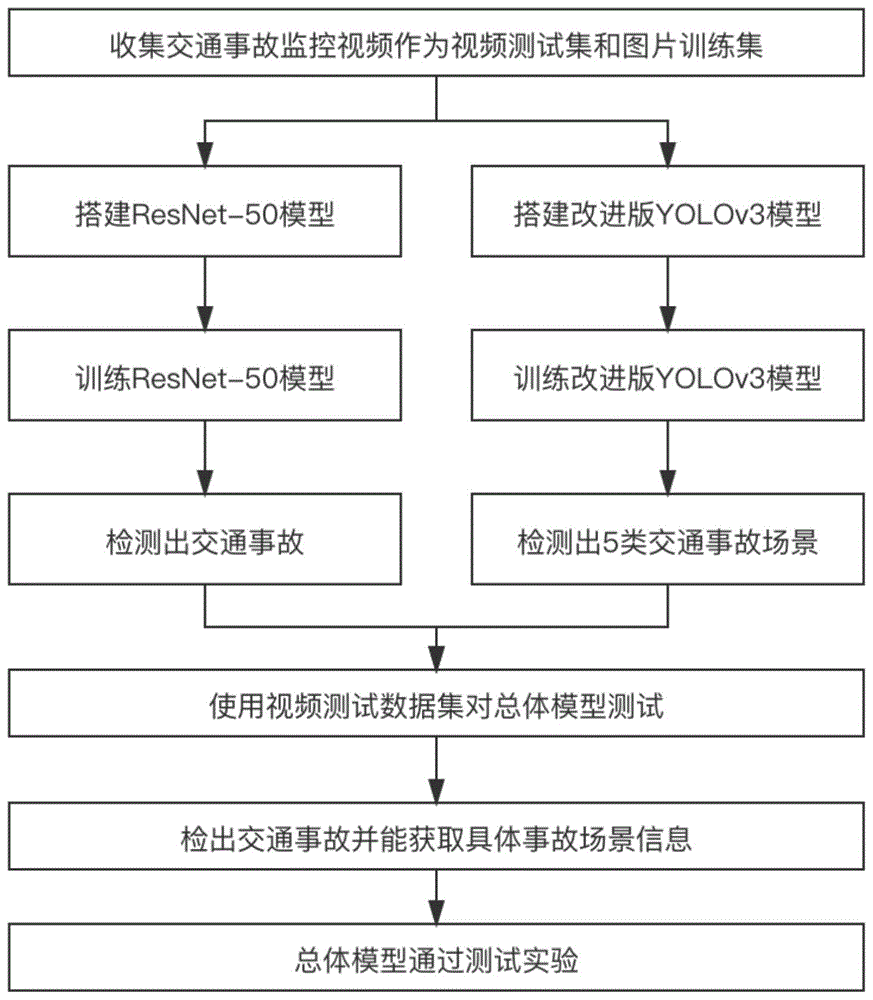
本发明采用以下技术方案来实现:一种基于深度学习的交通事故智能检测方法,主要包括以下步骤:
s1、收集交通事故监控视频作为视频测试集和图片训练集,处理出resnet-50图片数据集和yolov3图片数据集;
s2、搭建resnet-50深度卷积神经网络模型;
s3、使用resnet-50图片数据集训练resnet-50深度卷积神经网络模型;
s4、构建改进版yolov3模型,利用空间金字塔池网络结构spp-net与k均值聚类算法k-means进行优化;
s5、利用yolov3图片数据集训练改进版yolov3模型,检测车辆损坏、翻车、非机动车翻车、人员伤亡、失火5类交通事故场景;
s6、利用视频测试数据集进行总体模型测试,检出交通事故并获取具体事故场景信息;
s7、总体模型通过测试实验。
本发明与现有技术相比,具有如下优点和有益效果:
1、本发明通过采用表征能力强的resnet-50网络结构检测交通事故,来降低天气变化、道路环境变化对算法的影响,采取了检测速度快的yolov3算法来实现具体交通事故场景的检测,并且优化了网络结构,解决了算法运算时间长,检测细粒度低的问题,并利用空间金字塔池网络结构spp-net与k均值聚类算法k-means进行优化,实现检测精度的提高。
2、本发明方法能及时告知相关人员已发生交通事故,就可及早为事故受害者提供抢救服务,还可规避二次事故发生,大大减少甚至避免人员伤亡和财务损失。
附图说明
图1是本发明方法的流程图;
图2是本发明resnet-50神经网络架构图;
图3是本发明改进版yolov3神经网络架构图;
图4是本发明resnet-50模型实验仿真图;
图5是本发明resnet-50算法检测交通事故结果展示图;
图6是本发明改进版yolov3算法检测具体交通事故结果展示图。
具体实施方式
下面结合实施例及附图对本发明作进一步详细的描述,但本发明的实施方式不限于此。
实施例
如图1所示,本实施例一种基于深度学习的交通事故智能检测方法,包括以下步骤:
s1、收集交通事故监控视频作为视频测试集和图片训练集,利用视频处理库opencv将视频处理成帧序列,提取交通事故帧图片与非交通事故帧图片,分为accidents与no-accidents两类,对应于交通事故类和非交通事故类;使用labelimg对accidents类图片标注类别标签,其中,标签分为5类:damage、cardump、twowheeldump、persondump、fire,对应车辆损坏、翻车、非机动车翻车、人员伤亡、失火5类交通事故场景。
在本实施例中,收集交通事故监控视频具体过程如下:
s111、搜集监控视频200个,视频长度在0-3分钟之间,每个视频内容包含事故发生前、事故发生中、和事故发生后的场景;
s112、取20%监控视频作为视频测试输入,剩余80%进行视频转帧序列处理,并过滤出667张accidents类图片与646张no-accidents类图片,组成resnet-50图片数据集,用于训练与测试resnet-50模型;
s113、增加5类具体交通事故场景图片搜集,总共4421张图片,并做好标签处理,组成yolov3图片数据集,用于训练与测试改进版yolov3模型。
s2、如图2所示,搭建resnet-50深度卷积神经网络模型,具体过程如下:
s21、构建残差结构,来解决深度神经网络退化问题,残差结构设计算子一般为以下两种形式:
y=f(x,{wi})+x(1)
y=f(x,{wi})+wsx(2)
其中,y表示残差结构的输出特征,x表示残差结构的输入特征,f(x,{wi})表示输入特征x经过一个或多个权值为wi的卷积结构处理,ws为处理输入特征卷积结构的权值;本实施例的残差结构中包含3个卷积结构,卷积结构由卷积层、批归一化层(batchnormalization)和激活函数组成;
s22、基于残差结构和卷积结构,搭建resnet-50卷积神经网络,网络结构如图2所示;
s23、处理前向传播过程,构建损失函数,采取交叉熵作为损失函数,先使用softmax激活函数将每个类别所对应的输出分量归一化:
其中,si表示类别i对应的归一化预测输出分量,yi表示类别i对应的原始输出分量,yj表示类别j对应的原始输出分量,共有n个类别;
再计算交叉熵,计算公式为:
其中,ep(s′i,si)表示为交叉熵,s′i表示为类别i对应的归一化真实输出分量;
s24、构建adma优化器,整合模型,创建模型运行会话。
s3、使用resnet-50图片数据集训练resnet-50深度卷积神经网络模型,具体过程如下:
s31、基于python编写训练脚本;
s32、配置训练超参,学习率lr、分批处理个数batc_size、一阶估计衰减因子beta1、二阶估计衰减因子beta2;执行训练脚本并携带必要参数,数据集文件路径、迭代次数;开始训练resnet-50模型,过程中自动微调权重参数,最终得出resnet-50深度卷积神经网络模型回归,仿真精度曲线如图4所示,可见,在本实施例中,训练集精度与测试集精度皆达到了98%,说明resnet-50深度卷积神经网络网络用于检测交通事故,效果显著;
s33、另行准备交通事故与非交通事故图片各50张,计算该回归模型的检出率dr与误检率fdr,这两个检验指标公式如下:
其中,dn表示为检测出来的交通事故数量,atn表示为数据集中交通事故总图片数量,fdn表示为检测结果错误数量,tn表示为数据集总数;
并对比论文《computervision-basedaccidentdetectionintrafficsurveillance》,该论文提出了应用maskr-cnn算法检测车辆目标,再是基于有效质心的监控镜头目标跟踪算法,根据与其他车辆重叠后车辆中的速度和轨迹异常作为依据来得出是否发生交通事故发生事故的概率,表1为本发明resnet-50深度卷积神经网络模型与对比论文的回归模型的检出率dr、回归模型的误检率fdr指标对比结果,其中,对比论文的结果来自该论文:
表1dr、fdr指标对比结果
从s32与s33中的指标结果可以分析得出结论,应用resnet-50深度神经网络模型去检测交通事故,本发明提出的算法相比对比论文算法精度更高,误检率更低。
s4、构建改进版yolov3模型,在原darknet53网络结构增加三处空间金字塔池网络结构(spp-net),解决输入尺寸不固定问题,利用k均值聚类算法(k-means)为yolov3数据集聚类,得出先验框初始值,配置在改进版yolov3网络结构配置文件中,具体过程如下:
s41、采用k-means算法,计算改进版yolov3图片数据集对应的初始先验框值,首先定义iou计算函数:
intse=(yi2-yi1)×(xi2-xi1)(8)
union=box_pre+box_rela-intse(9)
其中,iou表示为预测边框与真实边框的交集面积与并集面积的比例,intse表示为预测边框与真实边框的交集面积,union表示为预测边框与真实边框的并集面积,xi1、yi1分别表示为类别i预测边框左上角坐标取的最大值与类别i真实边框左上角坐标取的最大值,yi2、yi2分别表示为类别i预测边框右下角角坐标取的最大值与类别i真实边框右下角坐标取的最大值,box_pre、box_rela分别表示为预测边框面积和真实边框面积;
定义k-means的目标函数f)iou)如下:
f(iou)=1-iou(10)
通过编码实现数据集聚类,获取9对先验框初始值,并从小到大排列,赋值于yolov3网络结构配置文件中;
s42、搭建yolov3网络模型,并新增spp-net于yolo预测网络中,最终的网络结构如图3所示。
s43、处理前向传播过程,构建交叉熵损失函数;
s44、构建sgd优化器,整合模型,创建模型运行会话。
s5、利用步骤s1中准备好的yolov3图片数据集训练改进版yolov3模型,具体过程如下:
s51、将yolov3数据集分配成80%为训练图片、20%测试验证图片,并生成相应图片路径的文本文件,并建立一个类别名称文件,文件包含5类名称,分别为:damage、cardump、twowheeldump、persondump、fire,对应于车辆损坏、翻车、非机动车翻车、人员伤亡、失火5类具体场景;
s52、在yolov3模型项目中建立数据集相关配置文本文件,配置项包含:检测类别总数、训练数据集路径、验证数据集路径、类别标签名称文件;
s53、将yolov3数据集voc格式标签标注转为yolo格式标注;
s54、设置超参初始值,配置改进版yolov3网络配置文件,将使用k-means算法得到的先验框初始值配置进去;
s55、使用imagenet数据集训改进版yolov3网络,得到预训练权重文件;
s56、执行训练脚本并传入必要参数,数据集相关配置文本文件路径、改进版yolov3网络配置文件路径、迭代次数、预训练权重文件路径,开始训练改进版yolov3模型。
s6、利用步骤s1中准备好的视频测试数据集进行总体模型测试,检出交通事故并获取具体事故场景信息,具体过程如下:
s61、采用步骤s1中预留的20%的监控视频作为测试视频;
s62、将测试视频作为resnet-50深度卷积神经网络模型的输入,执行测试脚本,其中需求传入必要参数包括输入视频路径、训练得到的resnet-50权重文件路径、类别名称;
s63、获取经过resnet-50深度卷积神经网络模型分类后的视频输出,则视频每帧都标记有对应所属类别及其概率,结果展示图如图5所示,从结果图中可以看到,对应交通事故和非交通事故的两类图片的检测结果,与图片实际情况相符,说明本发明具备良好的检测交通事故的能力。
s64、将步骤s63中的视频输出作为改进版yolov3模型的输入,执行测试脚本,其中需要传入必要参数包括输入视频路径、训练得到的改进版yolov3权重文件路径、类别名称、改进版yolov3网络配置文件;
s65、获取经过改进版yolov3模型检测后的视频输出,则视频用标签和边框标注出了检测到的车辆损坏、翻车、非机动车翻车、人员伤亡、失火这5类交通事故场景,检测结果如图6所示,可见改进版yolov3模型能很好的检测出5类具体交通事故场景,相比只能检测出是否发生交通事故的算法,本发明细粒度更高。
s7、总体模型通过测试实验,能够实现交通事故智能检测与具体交通事故类型检测。
上述实施例为本发明较佳的实施方式,但本发明的实施方式并不受上述实施例的限制,其他的任何未背离本发明的精神实质与原理下所作的改变、修饰、替代、组合、简化,均应为等效的置换方式,都包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!