一种基于地学数据库的半监督学习矿产资源定量预测方法
本发明涉及矿产资源勘测领域,更具体地说,属于一种基于地学数据库的半监督学习矿产资源定量预测方法。
背景技术:
矿产资源勘查是发现矿床并查明其中的矿体分布、矿产种类、质量、数量、开采利用条件、技术经济评价及应用前景等,满足国家建设或矿山企业需要的全部地质勘查工作。矿产资源埋藏于地下,具有稀少、隐蔽、复杂等特点,其勘查过程常常需要采用地质填图、物探、化探、遥感地质等方法,应用钻探、坑探等技术手段,需要进行测量、编录、取样、化验、实验、储量计算、技术经济评价和可行性研究等工作,需要大量的人力、物力和资金投入。且一个矿产资源地从发现、查明到开发需要经过很长的周期。因而,矿产资源勘查是一项极具风险的工作。由此可见,在矿产资源勘查阶段就开始贯彻循环经济的原则十分重要。
目前,矿产资源勘查不准确,且矿产资源勘查效率低下,因此针对这些不足需要设计一款全新矿产资源勘查的方法。
技术实现要素:
针对现有应用及技术存在的不足,本发明提供了种基于地学数据库的半监督学习矿产资源定量预测方法。该方法能够很好地解决矿产资源勘查不准确,且矿产资源勘查效率低下。基于此方案,用户可以通过电脑软件输入程序,因此,用户可以放心的借助手机或电脑终端进行同步操作,对于矿产资源勘查的准确性和效率提升问题具有十分重要的意义。
为实现上述目的,本发明提供了如下技术方案:
一种基于地学数据库的半监督学习矿产资源定量预测方法,处理方法包括:本方法由三部分组成,第一部分为基础算法;第二部分为贝叶斯超参数优化算法;第三部分为用于评价预测方法效果和圈定找矿有利靶区的概率-面积/体积图法。
方法一:基础算法:以‘袋装法’为基础的正样本无标签学习算法;
其中,‘袋装法’该算法计算流程如下:
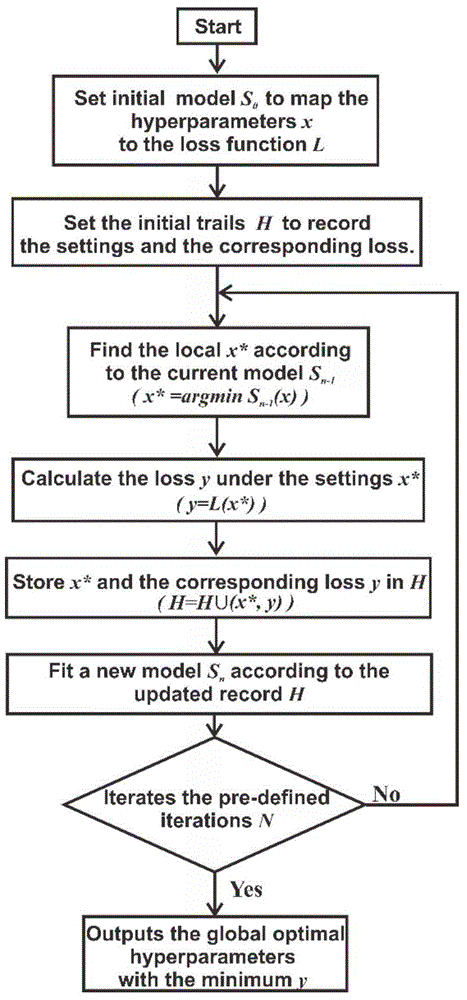
方法二:贝叶斯超参数优化算法,简要步骤总结如下:
步骤一:随机一些超参数x并训练得到模型,然后刻画这些模型的能力y,得到先验数据集合d=(x1,y1)、(x2,y2)、...、(xk,yk);
步骤二:通过先验数据d来拟合出高斯模型gm;
步骤三:通过采集函数找到在gm下的极大值,超参数x',并通过x'训练得到模型和刻画模型能力y',将(x',y')加入数据集d;
步骤四:重复2-3步,直至终止条件。
进一步的,方法三,用于评价预测方法效果和圈定找矿有利靶区的概率-面积/体积图法,简要概括如下:概率体积图包含两条线,一条为所预测的累计概率对应的块体面积/体积占矿体的百分比,另一条为所预测的累计概率对应的块体面积/体积占研究区的百分比,两条线交点即为靶区对应的概率阈值,该交点越高代表算法表现越好。
进一步的,对于基础算法,本方法提供了二维、三维矿产资源定量预测中常用的随机森林,梯度提升树,支持向量机等算法。
本发明的有益效果:
本发明通过基础算法、贝叶斯超参数优化算法和用于评价预测方法效果和圈定找矿有利靶区的概率-面积/体积图法三种方法组合成的一种组成一个总的方法,其中基础算法以‘袋装法’为基础的正样本无标签学习算法,贝叶斯超参数优化算法以四个步骤构成:步骤一:随机一些超参数x并训练得到模型,然后刻画这些模型的能力y,得到先验数据集合d=(x1,y1)、(x2,y2)、...、(xk,yk);步骤二:通过先验数据d来拟合出高斯模型gm;步骤三:通过采集函数找到在gm下的极大值,超参数x',并通过x'训练得到模型和刻画模型能力y',将(x',y')加入数据集d;步骤四:重复2-3步,直至终止条件,用于评价预测方法效果和圈定找矿有利靶区的概率-面积/体积图法,简要概括如下:概率体积图包含两条线,一条为所预测的累计概率对应的块体面积/体积占矿体的百分比,另一条为所预测的累计概率对应的块体面积/体积占研究区的百分比,两条线交点即为靶区对应的概率阈值,该交点越高代表算法表现越好,通过上述三种方法组成的基于地学数据库的半监督学习矿产资源定量预测方法,并通过电脑软件的输入上述的三类方法,最终能达到矿产资源勘查的准确性和效率提升。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为本发明贝叶斯超参数优化算法的同步英文流程图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
如附图1所示的一种基于地学数据库的半监督学习矿产资源定量预测方法,处理方法包括:本方法由三部分组成,第一部分为基础算法;第二部分为贝叶斯超参数优化算法;第三部分为用于评价预测方法效果和圈定找矿有利靶区的概率-面积/体积图法。
方法一:基础算法:以‘袋装法’为基础的正样本无标签学习算法;
其中,‘袋装法’该算法计算流程如下:
方法二:贝叶斯超参数优化算法,简要步骤总结如下:
步骤一:随机一些超参数x并训练得到模型,然后刻画这些模型的能力y,得到先验数据集合d=(x1,y1)、(x2,y2)、...、(xk,yk);
步骤二:通过先验数据d来拟合出高斯模型gm;
步骤三:通过采集函数找到在gm下的极大值,超参数x',并通过x'训练得到模型和刻画模型能力y',将(x',y')加入数据集d;
步骤四:重复2-3步,直至终止条件。
优选的,方法三,用于评价预测方法效果和圈定找矿有利靶区的概率-面积/体积图法,简要概括如下:概率体积图包含两条线,一条为所预测的累计概率对应的块体面积/体积占矿体的百分比,另一条为所预测的累计概率对应的块体面积/体积占研究区的百分比,两条线交点即为靶区对应的概率阈值,该交点越高代表算法表现越好。
优选的,对于基础算法,本方法提供了二维、三维矿产资源定量预测中常用的随机森林,梯度提升树,支持向量机等算法。
本发明通过电脑软件在anaconda3spyder4.1.4平台运行内部包含数据预处理、贝叶斯优化、基于‘袋装法’的正样本无标签学习及概率-面积/体积法等模块,其中两类正样本无标签学习的基础学习器包括目前在矿产资源定量预测与评价中应用最为广泛的randomforest(rf),gradientboostingdecisiontree(gbdt)和supportvectormachine(svm),上述三种基础学习器利用机器学习库scikit-learn构建与训练构建和训练。
首先spyder4.1.4,然后输入该软件的源数据(例)软件,要求分别输入:.csv格式,a.矿体地学信息数据库;b.无标签地学信息数据库;c.所有数据的x,y,z(即深度)坐标信息(按照先矿体后无标签的顺序)。此处注意矿体地学信息数据库和无标签地学信息数据库中的特征类别应该一致,上述数据均与软件放在同一运行目录下,运行‘袋装法’正样本无标签学习模块,运行p-vplot模块,最终得到数据结果,软件最终处理结果为:.csv格式的文件里面具有xyz和成矿概率,通过电脑软件的输入上述的三类方法,最终能达到矿产资源勘查的准确性和效率提升的目的。
在本发明创造的描述中,需要说明的是,除非另有明确的规定和限定,术语“安装”、“相连”、“连接”应做广义理解,例如,可以是固定连接,也可以是可拆卸连接,或一体地连接;可以是机械连接,也可以是电连接;可以是直接相连,也可以通过中间媒介间接相连,可以是两个元件内部的连通。对于本领域的普通技术人员而言,可以通过具体情况理解上述术语在本发明创造中的具体含义。
需要说明的是,在本文中,术语“上”、“下”、“内”、“外”“前端”、“后端”、“两端”、“一端”、“另一端”等指示的方位或位置关系为基于附图所示的方位或位置关系,仅是为了便于描述本发明和简化描述,而不是指示或暗示所指的装置或元件必须具有特定的方位、以特定的方位构造和操作,因此不能理解为对本发明的限制。
尽管已经示出和描述了本发明的实施例,对于本领域的普通技术人员而言,可以理解在不脱离本发明的原理和精神的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由所附权利要求及其等同物限定。
- 还没有人留言评论。精彩留言会获得点赞!