机床热误差自学习预测模型建模方法及基于数字孪生的机床热误差控制方法
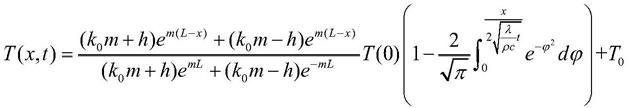
1.本发明属于机械误差分析技术领域,具体的为一种机床热误差自学习预测模型建模方法及基于数字孪生的机床热误差控制方法。
背景技术:
2.由于切削刀具与工件之间的相对空间位置随运行时间而变化,因此导致加工精度下降。热引起的误差是导致相对空间位置的关键因素。为了显着提高加工精度,需要减少或避免热致误差。电动主轴系统是精密机床的核心组成部分。但是,由于诸如热负荷的强度和位置、材料特性、环境温度和冷却系统等因素之间的复杂相互作用,致使热引起的误差非常大。控制和补偿系统的关键是具有强大鲁棒性和出色预测性能的热误差模型。热引起的误差显示出非线性,时变和非平稳的行为。因此,具有强鲁棒性和优异控制效果的热致误差控制变得极为困难。
3.当前,热致误差控制方法的研究是一个研究热点。研究方向主要集中在机床热致误差的减少和预测上。研究方法主要有理论和实验建模两种。其中,理论建模方法研究了机床的误差机理和热特性分析。虽然理论建模方法有效地揭示了误差机理,然而难以实现边界条件的准确表征,这使得热特性建模不准确。另外,现有的理论模型不能很好地应用于误差控制。实验建模和控制方法对于提高加工精度是有效且经济的,但对于热引起的误差模型的控制效果和鲁棒性仍不令人满意。
4.在海量数据和并行计算性能增长的背景下,具有自学习和自我调节能力的深度学习(dl)的预测性能接近甚至超越人类。与传统模型相比,深度神经网络适用于用层次化特征表征深层和复杂的非线性关系,并适用于处理具有多因素、不稳定和复杂行为的热误差数据。更重要的是,在没有考虑误差产生机理,建立了经验模型,从而导致误差数据与模型特征之间的匹配度降低。人工神经网络无法计算数据在时间轴上的传播,并且递归神经网络(rnn)的输出值受到先前输入的影响。在许多建模和预测问题中,预测的误差序列对历史数据具有长期依赖性,并且其长度可能会随时间变化,或者是隐藏且未知的。与其他线性预测模型相比,rnn模型对历史数据具有一定的记忆性能,可以学习任意复杂的函数和变量之间隐藏的非线性相互作用,并且在具有时序特性的误差建模和预测中具有最大优势。尽管rnn解决了时间依赖性的问题,但是在反向传播的链式导数计算中仍然存在梯度消失或爆炸的问题。lstm神经网络的内部状态仅通过线性相互作用而改变,这使得信息可以沿时间轴方向平滑地反向传播。从而增强了其对历史数据的记忆行为,lstm神经网络具有自学习能力。然后,lstm神经网络的优异的存储特性可以充分反映误差数据的长期记忆性能,与传统的建模方法相比具有极大的优势。
技术实现要素:
5.有鉴于此,本发明的目的在于提供一种机床热误差自学习预测模型建模方法及基
于数字孪生的机床热误差控制方法,具有出色预测性能和鲁棒性,能够反映热误差产生机理并具有自学习能力。
6.为达到上述目的,本发明提供如下技术方案:
7.本发明首先提出了一种机床热误差自学习预测模型建模方法,包括如下步骤:
8.1)输入机床热误差数据,初始化机床热误差数据并构建d
1:t
={(x1,y1),(x2,y2)
…
,(x
t
,y
t
)};其中,x
t
表示决定机床热误差的因素的向量,y
t
表示热误差,t为大于等于1的正整数;
9.2)构建概率分布模型:
[0010][0011]
y
t
=f(x
t
)+ε
t
[0012]
其中,ε
t
为观察误差;f为未知的目标函数;p(d
1:t
|f),p(f),p(d
1:t
)和p(f|d
1:t
)分别表示y的似然分布,y的先验概率分布,y的边际似然分布和y的后验概率分布;
[0013]
3)最大化ac函数以获得下一个评估点x
t+1
,并最小化目标函数和真实函数之间的总损失;所述ac函数为:
[0014][0015]
γ
t+1
=|y
*
‑
y
t+1
|
[0016]
其中,x
t+1
为下一个评估点;γ
t
为总损失;α
t
(x:d
1:t
)为ac函数;y
*
为当前的最优解;
[0017]
4)评估目标函数以获得y
t+1
;
[0018]
5)判断是否达到最大迭代次数:若是,则输出参数集;若否,则将(x
t+1
,y
t+1
)添加到概率分布模型内以更新概率分布模型,返回步骤3);重复上述步骤,直至获得最优解;
[0019]
6)将通过boa算法获得的最佳超参数用于bayesian
‑
lstm神经网络模型,并使用bayesian
‑
lstm神经网络模型训练自学习误差预测模型,输出预测的热误差。
[0020]
进一步,所述概率分布模型采用gp模型。
[0021]
进一步,所述步骤6)中,目标函数的输入包括lstm神经网络的历元大小、批处理大小和节点数,目标函数的输出为rsme;选择使rsme最小的超参数,然后调用boa算法优化lstm神经网络的历元大小,批处理大小和节点数,得到最佳超参数。
[0022]
进一步,所述bayesian
‑
lstm神经网络模型包括lstm层和dense层,所述dense层为完全连接层并用于将lstm层的输出转换为所需的输出。
[0023]
本发明还提出了一种基于数字孪生的机床热误差控制方法,包括如下步骤:
[0024]
1)获取物理世界数据:包括工件原始数据、机床原始数据和切削刀具及误差获取系统数据;
[0025]
2)建立热误差仿真模型:根据机床热误差机理,建立热误差分析模型,结合获取的物理世界数据对机床的热行为进行虚拟仿真;
[0026]
3)在线测量热误差,将在线测量得到的机床热误差数据用于bayesian
‑
lstm神经网络模型的建模和训练,得到如上所述方法创建得到的机床热误差自学习预测模型;
[0027]
4)采用机床热误差自学习预测模型预测热误差,若预测的热误差大于工件的预设加工误差,则控制机床进行误差补偿,误差补偿的大小与预测的热误差大小相等、但方向相
反;
[0028]
5)循环步骤3)和步骤4),直至机床加工过程完成。
[0029]
进一步,所述工件原始数据包括工件的几何尺寸、材料属性和预设的加工精度;所述机床原始数据包括机床的进给速度,主轴转速和切削深度等;所述切削刀具及误差获取系统的原始数据包括刀具长度,刀具直径,螺旋角度和采样频率等。
[0030]
进一步,所述步骤4)中,控制机床进行误差补偿的控制策略如下:
[0031]
令由热误差引起的位置偏差矢量表示为:
[0032]
oo'=[δo
x
,δo
y
,δo
z
]
[0033]
则控制向量表示为
[0034]
δh
s
=
‑
oo'
[0035]
设机床主轴的初始位置为po,在热误差的作用下伸长并倾斜到最终位置po'.则获得不同方向的控制值
[0036]
δo
x
=(d
0x
+d+δd)sinγ
x
[0037]
δo
y
=(d
0y
+d)γ
y
[0038]
δo
z
=δd
‑
δo
d
=δd
‑
(d
0x
+d+δd)(1
‑
cosγ
x
)
[0039]
其中,δo
x
、δo
y
、δo
z
分别表示x方向、y方向和z方向的控制值;d表示工具的长度;δd表示轴向热伸长率;d
0x
和d
0y
分别表示偏转中心与主轴法兰之间的距离;γ
x
和γ
y
分别表示由热误差引起的位置偏差矢量在x方向和y方向上的偏差角度。
[0040]
进一步,根据所述控制策略得到加工工件上任一点w的坐标为:
[0041][0042]
其中,p
x
、p
y
和p
z
分别表示工件上任一点w的预设坐标;p
x
'、p
y
'、p
z
'分别表示工件上任一点w经误差补偿控制后的坐标。
[0043]
本发明的有益效果在于:
[0044]
本发明的机床热误差自学习预测模型建模方法,采用bayesian
‑
lstm神经网络模型训练自学习误差预测模型并输出预测的热误差,具有以下优点:
[0045]
1)lstm神经网络可以避免将将典型温度作为模型输入,避免了以典型温度变量为输入导致的多重共线性,同时避免了由多重共线性引起的预测性能降低及鲁棒性恶化等问题;另外,也避免了现有预测模型难以实现边界条件的准确表征的问题,这使得热特性建模更加准确,模型鲁棒性更强;
[0046]
2)lstm神经网络其内部状态仅通过线性相互作用而改变,这使得信息可以沿时间轴方向平滑地反向传播,从而增强了历史数据的记忆行为;
[0047]
3)lstm神经网络的应用可以充分反映误差数据的存储特性,与传统的建模方法相比具有极大的优势;
[0048]
4)lstm神经网络的预测性能和鲁棒性与其超参数密切相关,通过采用贝叶斯优化算法(boa)来优化lstm的历元大小,批处理大小和节点数等超参数,可基于传入的误差数据实时更新概率分布模型,利用boa和lstm神经网络的组合建立了具有出色预测性能和鲁棒性的自学习误差预测模型。
[0049]
本发明的基于数字孪生的机床热误差控制方法,通过数字孪生技术,根据机床热误差机理建立热误差分析模型,并结合物理世界数据对机床的热行为进行虚拟仿真,实现了物理世界和信息世界之间产生互动和融合,为物理实体增加或扩展新功能;通过虚拟仿真在线测量热误差用于bayesian
‑
lstm神经网络模型的建模和训练,从而得到机床热误差自学习预测模型,利用机床热误差自学习预测模型对热误差进行预测,从而可通过实时反向控制热误差以提高机床加工精度和质量。
附图说明
[0050]
为了使本发明的目的、技术方案和有益效果更加清楚,本发明提供如下附图进行说明:
[0051]
图1为单一热负荷作用下的轴系统的结构示意图;
[0052]
图2为图1中轴系统的简化热力学模型;
[0053]
图3为轴的温度响应示意图;
[0054]
图4为热变形与温度响应之间的关系示意图;
[0055]
图5为本发明机床热误差自学习预测模型的构架图;
[0056]
图6为lstm神经网络的结构的结构图;
[0057]
图7为转速随时间的变化图,其中,图7a为工作条件#1,图7b为工作条件#2;
[0058]
图8为轴在工作条件#1作用下的热伸长率随时间的变化曲线图;
[0059]
图9为bayesian
‑
lstm模型的结构和参数图;
[0060]
图10为轴在工作条件#1作用下的热伸长拟合曲线图;
[0061]
图11为轴在工作条件#2作用下的热伸长率随时间的变化曲线图;
[0062]
图12为轴在工作条件#2作用下的热伸长预测曲线图;
[0063]
图13为基于数字孪生的机床热误差控制系统的框架图;
[0064]
图14为轴的热误差控制矢量建模几何原理图;
[0065]
图15为误差控制验证图;图15a为工作条件#3中转速随时间的变化图,图15b为控制结构比较图;
[0066]
图16为实际加工验证图;图16a为测试样品的加工图;图16b为测试样品的二维图。
具体实施方式
[0067]
下面结合附图和具体实施例对本发明作进一步说明,以使本领域的技术人员可以更好地理解本发明并能予以实施,但所举实施例不作为对本发明的限定。
[0068]
本实施例以机床主轴为例,对机床热误差的机理进行说明。机床主轴可以看作是一端固定、另一端旋转支撑的轴系统,热通量从主轴的固定端作为一个单独的热源输入,如图1所示。
[0069]
在单一热负荷作用下,具有相同横截面的轴的轴芯温度可表示为:
[0070]
[0071]
式中,k0、h和t(0)分别为热导率、对流系数及热源温度,且λ为轴的轴芯热膨胀系数;l为轴的长度;d0为轴的直径;t0为轴的初始温度;ρ为轴的密度;c为轴的比热容;t为时间;x为主轴上的位置。
[0072]
主轴轴芯热伸长表示为:
[0073][0074]
轴芯热膨胀的精确模型取决于轴对热负荷的温度响应。热膨胀系数α是温度的函数,因此,轴芯温度场和热变形在时空范围内具有时变、非线性和非稳态特性,很难获得准确的轴温升高。为了模拟轴系统的实际加工过程,定义了热通量hf,该热通量作为余弦函数,以时间为自变量。
[0075]
hf=20cos(2πt)+20
[0076]
将热通量hf输入到轴系统的一端,如图1所示,计算轴的热膨胀。为了反映热误差的长期记忆行为,使用solid186元素在ansys workbench中建立了一个主轴系统的简化热力学模型,该模型不占用大量计算资源,如图2所示。一个具有20个节点的高阶三维实体结构元素,每个节点在xyz方向上具有3个角度以进行方向平移。热边界条件包括热源负荷和对流系数,结构边界条件包括固定支撑和无摩擦支撑。将以上边界条件加载到有限元模型中,在仿真中,一个步骤是一秒钟,总共分析了100个步骤,获得了轴的瞬态温度和热伸长率以及支撑端的端面的温度和热伸长率,如图3所示。可以看出,相对于温度响应,热膨胀存在明显的时间延迟。即,热膨胀的时间变化相对于温度上升具有时间滞后。如图4所示,获得了主轴热特性的迟滞效应。结果表明,温度和热变形之间存在明显的迟滞。建立热误差模型时,应考虑历史长期热效应信息对当前热误差的影响。以上对误差机理的分析表明,热误差具有长期记忆的能力,传统的热误差模型不能胜任。
[0077]
下面对本实施例的机床热误差自学习预测模型建模方法的具体实施方式进行详细说明。
[0078]
如图5所示,为本发明机床热误差自学习预测模型的构架图。本实施例的机床热误差自学习预测模型建模方法,包括如下步骤:
[0079]
1)输入机床热误差数据,初始化机床热误差数据并构建d
1:t
={(x1,y1),(x2,y2)
…
,(x
t
,y
t
)};其中,x
t
表示决定机床热误差的因素的向量,y
t
表示热误差,t为大于等于1的正整数。
[0080]
2)构建概率分布模型:
[0081][0082]
y
t
=f(x
t
)+ε
t
[0083]
其中,ε
t
为观察误差;f为未知的目标函数;p(d
1:t
|f),p(f),p(d
1:t
)和p(f|d
1:t
)分
别表示y的似然分布、y的先验概率分布、y的边际似然分布和y的后验概率分布;本实施例的概率分布模型采用gp模型。
[0084]
3)最大化ac函数以获得下一个评估点x
t+1
,并最小化目标函数和真实函数之间的总损失;所述ac函数为:
[0085][0086]
γ
t+1
=|y
*
‑
y
t+1
|
[0087]
其中,x
t+1
为下一个评估点;γ
t
为总损失;α
t
(x:d
1:t
)为ac函数;y
*
为当前的最优解;
[0088]
4)评估目标函数以获得y
t+1
;
[0089]
5)判断是否达到最大迭代次数:若是,则输出参数集;若否,则将(x
t+1
,y
t+1
)添加到概率分布模型内以更新概率分布模型,返回步骤3);重复上述步骤,直至获得最优解;
[0090]
6)将通过boa算法获得的最佳超参数用于bayesian
‑
lstm神经网络模型,并使用bayesian
‑
lstm神经网络模型训练自学习误差预测模型,输出预测的热误差。具体的,目标函数的输入包括lstm神经网络的历元大小、批处理大小和节点数,目标函数的输出为rsme;选择使rsme最小的超参数,然后调用boa算法(bayesian optimization algorithm)优化lstm神经网络的历元大小,批处理大小和节点数,得到最佳超参数。本实施例的bayesian
‑
lstm神经网络模型包括lstm层和dense层,所述dense层为完全连接层并用于将lstm层的输出转换为所需的输出。
[0091]
需要指出的是,通过手动计算很难准确确定lstm神经网络的最佳设置。当有多个超参数需要调整时,计算规模太大,网格搜索的计算速度较慢,对于非凸问题很容易获得局部最优。boa仅需要较少的功能评估,因为boa根据描述先前迭代中的适应性评分的分布来学习并选择最佳的超参数集。因而可使用boa算法来优化lstm神经网络的超参数。
[0092]
由于具有完全的数学和概率结构,boa的性能要好得多。在boa中使用先验分布来定义后验分布上的功能空间。使用信息先验分布的方法可以描述目标函数的某些特性,并且在诸如平滑度或最大可能位置等特性的未知估计函数的条件下可以采用函数本身的形式。boa算法假设变量之间的黑盒函数是独立的,并且变量服从正态分布。该假设的局限性较小,并且具有很强的实际应用性,这使得boa在黑匣子函数全局优化中的具有适用性。boa有两个关键点,一个是概率分布模型,另一个是ac函数。概率分布模型的功能是替换未知的目标函数,通过逐步迭代校正先验概率分布,使其越来越接近目标函数f。当前的研究通常使用高斯过程(gp)模型作为概率分布模型,并将其用于超参数的优化。ac函数的作用是平衡勘探和开发能力,最后优化迭代过程中的搜索方向。探索的目的是防止模型陷入局部最优值,而探索的目的是提高发现全局最优值的速度。然后选择下一个评估点以使总损失最小。
[0093]
lstm神经网络是一种特殊的rnn。通过精心设计“门”结构,可以避免传统rnn中产生的梯度消失和梯度爆炸问题。lstm神经网络通过三个门来保存和控制存储单元中的信息。每个单元由四个主要元素组成,即输入门、遗忘门、输出门和单元状态。信息的存储和控制是通过激活函数的点乘法实现的。梯度下降训练一系列参数以控制每个门的状态。lstm神经网络结构图如图6所示。因此,具有记忆功能的lstm模型在时间序列数据的预测和分类中表现出色。lstm神经网络由多个同类单元组成,这些单元可以通过更新内部状态来实现
信息的长期存储。
[0094]
lstm神经网络建模的关键是单元状态,因为它可以随时存储单元状态。遗忘门的作用是让细胞记住或忘记先前的状态。输入门的作用是允许或阻止进入的信号来更新设备状态。输出门的功能是控制单元状态的输出并转移到下一个单元。此外,通过图6的遗忘门和输入门实现细胞状态的调节。lstm神经网络单元的内部结构由多个感知器组成。
[0095]
boa可以在参数空间中快速找到相对最佳的超参数。如图5所示。对于未知的目标函数,将一些已知的先验知识用作目标函数,然后将一系列观察样本代入模型,以使训练后的模型服从函数。然后可以找到一组超参数以最大化自学习效果。boa可以通过少量计算任务来获得最佳模型超参数。
[0096]
下面以电动主轴系统为例,对本实施例创建得到的机床热误差自学习预测模型的性能进行说明。
[0097]
电动主轴系统用于进行热特性实验,通过五点法获得热伸长率。使用美国lion precision制造的动态旋转误差分析仪sea来测试和分析热误差。高精度标准滚珠的夹紧是通过主轴前端的bt40柄实现的。在x,y和z的三个相互垂直的方向上布置了五个电容位移传感器。通过主轴动态旋转误差分析仪sea采集标准球的径向和轴向位移。对x和y径向数据进行处理和分析以获得主轴的倾斜角度。获得z方向数据作为轴向热伸长率。
[0098]
高精度c8
‑
2.0位移用于测量热引起的误差。该采集仪是一个多通道和双灵敏度电容式位移传感器驱动器,即lion elite cpl290,具有六个通道,用于高和低精度双量程模式的电容式位移传感器。在制造过程中产生的高精度标准球的圆度误差为60nm,与热误差相比,几何圆度误差可忽略不计。加速和减速过程在切削过程中很常见,工作条件#1和#2的热误差数据分别用于建模和预测,其中,工作条件#1用于模拟加工中的加速和减速过程,工作条件#2用于模拟加工过程中的随机转速,如图7所示。
[0099]
以轴向热伸长为例,轴向热伸长随时间变化,如图8所示,为工作条件#1下的热伸长率。热引起的误差的动态变化是非线性且非平稳的,这意味着采用bayesian
‑
lstm神经网络训练自学习误差预测模型是有效的。
[0100]
为了使模型具有良好的预测性能,boa用于优化超参数,例如历元大小,批处理大小和lstm神经网络的节点数。为了减少人为因素对模型的影响,根据误差数据的具体情况,如下设置超参数的范围:历元大小在[1,100]的范围内,批处理大小在[16,48]的范围内,lstm神经网络的单位数在[128,396]的范围内。表1中列出了boa算法的参数,根据指南进行选择,以加快收敛速度并提高boa的优化性能。置信上限的可调参数kappa的功能是调整开发和勘探。kappa的增加导致不确定性重要性(未开发的空间)的增加,从而激励了勘探工作。kappa值表示高于置信上限的零的标准偏差,并将其设置为2.576。
[0101]
表1boa参数
[0102][0103]
通过优化boa,可以获得lstm神经网络模型的体系结构和参数,如图9所示。lstm神经网络模型分为两层,包括一层lstm神经网络和一层密集神经网络,以实现误差数据的更深层表达。单元格表示每层神经元的数量,输入和输出表示网络数据的向量维。第一个数字表示样本数,第二个数字表示时间窗口大小,第三个数字表示特征。损失函数是均方误差。
利用adam算法对热误差模型的训练过程进行了优化,并用它代替了随机梯度下降法,从而减少了内存使用量,提高了计算效率,将adam优化算法的学习率设置为α=0.001。网络模型是在keras框架下构建的。训练误差模型的次数设置为40,并通过boa进行优化。通过boa优化,可以获得bayesian
‑
lstm神经网络的设置参数,如表2所示。
[0104]
表2.lstm神经网络模型的设置
[0105][0106]
同时对bp网络模型和mlra模型进行设置,以比较以上三个模型的拟合性能,如图10所示。在整个运行过程中,误差数据发生了显着变化,并且整个过程中存在着急剧而快速的变化,因此,处理急剧变化的误差数据的能力非常重要。结果表明,三种模型在误差数据的以下特性方面存在一些差异。以下性能说明了误差模型的拟合能力。因此,bayesian
‑
lstm网络模型的拟合能力最好,其次是bp神经网络模型,而mlra模型的拟合能力最差。
[0107]
四个模型预测性能的评估结果如表4所示。bayesian
‑
lstm模型、bp模型和mlra模型的拟合能力η分别为98.44%,98.03%和95.88%。可以看出,bayesian
‑
lstm模型的拟合精度高于其他两个模型。bp模型的拟合能力η高于mlra模型,因为mlra模型不能完全反映热误差的长期记忆关系。此外,bayesian
‑
lstm神经网络模型没有引入任何临界温度,并有效地反映了长期记忆行为,避免了温度变量之间的共线性,并反映了热误差机理。因此,bayesian
‑
lstm模型的拟合能力是最好的。
[0108]
表4.拟合能力评估
[0109][0110]
图11示出了在工作条件#2下的热引起的误差,并且其特性与在工作条件#1下的特性类似,其是非线性的,随时间变化的并且是非平稳的。在整个运行过程中,热误差会动态且急剧变化。热误差的快速变化对误差模型的鲁棒性和泛化能力提出了很高的要求。图11所示的热伸长率与图8所示的热伸长率显着不同,这表明工作条件对热误差的影响。
[0111]
通过bayesian
‑
lstm模型,bp模型和mlra模型预测热误差,如图12所示。bayesian
‑
lstm模型、bp模型和mlra模型的预测性能依次降低。更重要的是,bayesian
‑
lstm模型的预测性能和鲁棒性远胜于bp模型和mlra模型,而mlra模型的预测性能和鲁棒性强于bp模型。bp模型无法实现与贝叶斯lstm神经网络模型和mlra模型相同的预测。主要原因是bayesian
‑
lstm神经网络层实现了热误差数据的非线性,时变和非平稳行为的更深表达,
bayesian
‑
lstm神经网络充分表征了热误差的长期记忆行为,且bayesian
‑
lstm网络模型具有很强的自学能力。boa提高了误差数据与模型行为之间的匹配度。如果没有合理的参数调整过程,bp神经网络通常会出现过拟合现象。因此,bayesian
‑
lstm模型的预测性能远优于bp模型。mlra模型不能完全反映非线性、时变和非平稳特性。因此,bayesian
‑
lstm神经网络的预测性能远优于mlra模型。bp神经网络在训练过程中易于过度拟合,拟合性能好但泛化能力不足,而mlra模型没有过度拟合的问题,因此,mlra模型的预测性能优于bp模型。bayesian
‑
lstm预测模型的预测性能在以上三个模型中最好。
[0112]
如表5所示,通过预测能力来评估热误差模型的预测性能。bayesian
‑
lstm神经网络模型的预测能力最好,其次是mlra模型,而bp模型的预测能力最差。结果表明,bayesian
‑
lstm模型可以准确地预测热误差,并且用boa优化lstm神经网络的超参数是有效的。
[0113]
表5.预测能力评估
[0114][0115]
下面对本实施例基于数字孪生的机床热误差控制方法的具体实施方式进行详细说明。
[0116]
如图13所示,为本发明基于数字孪生的机床热误差控制方法的框架图。本实施例的基于数字孪生的机床热误差控制方法,包括如下步骤:
[0117]
1)获取物理世界数据:包括工件原始数据、机床原始数据和切削刀具及误差获取系统的原始数据;具体的,所述工件原始数据包括工件的几何尺寸、材料属性和预设的加工精度;所述机床原始数据包括机床的进给速度,主轴转速和切削深度等;所述切削刀具及误差获取系统的原始数据包括刀具长度,刀具直径,螺旋角度和采样频率等。
[0118]
2)建立热误差仿真模型:根据机床热误差机理,建立热误差分析模型,结合获取的物理世界数据对机床的热行为进行虚拟仿真;
[0119]
3)在线测量热误差,将在线测量得到的机床热误差数据用于bayesian
‑
lstm神经网络模型的建模和训练,得到如上所述方法创建得到的机床热误差自学习预测模型;
[0120]
4)采用机床热误差自学习预测模型预测热误差,若预测的热误差大于工件的预设加工误差,则控制机床进行误差补偿,误差补偿的大小与预测的热误差大小相等、但方向相反;
[0121]
5)循环步骤3)和步骤4),直至机床加工过程完成。
[0122]
具体的,步骤4)中,控制机床进行误差补偿的控制策略如下:
[0123]
如图14所示,令由热误差引起的位置偏差矢量表示为:
[0124]
oo'=[δo
x
,δo
y
,δo
z
]
[0125]
则控制向量表示为
[0126]
δh
s
=
‑
oo'
[0127]
设机床主轴的初始位置为po,在热误差的作用下展开并倾斜到最终位置po'.则获得不同方向的控制值
[0128]
δo
x
=(d
0x
+d+δd)sinγ
x
[0129]
δo
y
=(d
0y
+d)γ
y
[0130]
δo
z
=δd
‑
δo
d
=δd
‑
(d
0x
+d+δd)(1
‑
cosγ
x
)
[0131]
其中,δo
x
、δo
y
、δo
z
分别表示x方向、y方向和z方向的控制值;d表示工具的长度;δd表示轴向热伸长率;d
0x
和d
0y
分别表示偏转中心与主轴法兰之间的距离;γ
x
和γ
y
分别表示由热误差引起的位置偏差矢量在x方向和y方向上的偏差角度。
[0132]
根据所述控制策略得到加工工件上任一点w的坐标为:
[0133][0134]
其中,p
x
、p
y
和p
z
分别表示工件上任一点w的预设坐标;p
x
'、p
y
'、p
z
'分别表示工件上任一点w经误差补偿控制后的坐标。
[0135]
借助数字孪生,可以通过实时输入数据在线实现热误差的预测和控制,并且可以基于误差模型的反馈信息和热误差的控制策略来同步调整机床参数。本实施例已验证了机床热误差自学习预测模型的有效性,然后将其嵌入到数字孪生系统中,使用实时误差数据执行机床热误差自学习预测模型的建模、预测和控制。
[0136]
如图13所示,由数字孪生驱动的具有自我学习能力的热误差控制方法由物理控制过程、虚拟误差控制过程和孪生数据组成。物理控制过程是用于控制和提高加工精度的客观活动和实体的集合,包括机床、切削工具、工件、切削液、加工过程、加工执行、过程参数、通信协议、通信接口和控件执行等。虚拟误差控制过程是物理过程的真实映射,它实现了对实际加工过程中的热误差的监视、预测、管理和控制。数字孪生数据包括与物理和虚拟误差控制过程相关的数据集,并支持虚拟和实际数据的深度融合和交互。通过物理和虚拟误差控制过程的双向映射和交互,由数字孪生驱动的机床的误差补偿和控制可以实现物理和虚拟误差控制过程的集成和融合,最后实现物理现实和虚拟模型之间的迭代,完成机床运行状态的操作和调整。并且支持控制过程的智能优化和决策,实现机床的精确执行和优化控制。
[0137]
误差模型是输入数据的体现,根据误差数据自动在线调整自学习误差模型,静态和动态数据都被使用。静态数据包括与几何尺寸、材料特性、预设加工精度、cnc系统、rs23、plc、刀具长度、刀具直径、切削刀具的螺旋角度以及采样有关的数据错误获取系统的频率。动态数据包括与控制轴、进给速度、主轴转速和切削深度有关的数据。这些静态和动态数据构成决定机床误差的因素的向量,并将该向量用于数字世界中的实时误差预测、补偿和控制。此外,根据步骤4)计算控制分量,并根据cnc系统的通信协议将调整后的g代码反馈到物理世界,以实现基于数字孪生的热误差的自学习控制。
[0138]
支持自学习的机床热误差控制系统由物理和数字子系统组成。物理子系统由工件、机床、切削工具、误差获取系统和pc组成。数字子系统实现了虚拟仿真和实时预测,以揭示热误差的长期记忆行为,可以通过bayesian
‑
lstm神经网络模型准确预测热误差。可以通过添加大小相等且方向相反的反向误差来实现自学习控制和热误差补偿。以上三个模型被嵌入到数字孪生系统中以实时预测热误差,并且这些模型可以随着误差数据的增加而自动更新其参数。如果预测误差大于预设的加工误差,则启动控制策略,并将三个方向上的控制分量发送到plc。然后,将三个方向上的控制分量与零件程序叠加在一起以更新g代码。最
后,根据误差方向确定控制轴,控制控制轴的进给速度,以保证加工误差在预设范围内。并实现了基于自学习的误差控制。如果预测的热误差小于预设的加工误差,则加工过程将正常运行。通过动态交互和融合各种加工信息,包括工件数据、机床数据、切削刀具数据和误差采集系统,解决了上述动态复杂误差的控制难题。
[0139]
如图15(a)所示,在工作条件#3下进行了具有自学习能力的热误差控制实验。比较了三个具有自学习能力的错误控制系统的控制效果,如图15(b)所示。在工作条件#3下的热引起的误差很大。结果表明,上述三个自学习支持的错误控制系统有效地减小了误差。此外,以bayesian
‑
lstm神经网络模型为实时误差预测模型的自学习型误差控制系统的控制效果是上述三种控制模型中最好的,其次是mlra模型,以bp神经网络模型作为实时误差预测模型的自学习型误差控制系统的控制效果最差。
[0140]
然后评估了以上三个具有自学习能力的误差控制系统的控制性能,如表6所示,对于以bayesian
‑
lstm神经网络模型为实时误差预测模型的自学习型误差控制系统,采用误差控制的热伸长率的mae和绝对最大残差分别约为0.40μm和1.24μm。对于以mlra模型作为实时误差预测模型的自学习误差控制系统,热伸长率的mae和绝对最大残差分别约为1.55μm和5.26μm。对于以bp神经网络模型作为实时误差预测模型的具有自学习能力的误差控制系统,热伸长的平均残留量和最大残留量分别约为2.30μm和9.57μm。可以看出,在上述三种模型中,具有bayesian
‑
lstm神经网络模型的自学习型误差控制系统的控制效果是最好的。然后验证了以bayesian
‑
lstm神经网络模型作为实时误差预测模型的具有自学习能力的误差控制系统的有效性,该系统足够准确,可以在后续的加工过程中进行误差控制和补偿。
[0141]
表6控制能力评估
[0142][0143]
对iso 10791
‑
7中的测试样品进行加工,如图16所示。在实验中,转速、进给速度和切削深度为根据加工质量的要求,分别为7000r/min,40mm/min和50μm。然后在热引起的误差控制之前和之后分别测量孔与正方形的边之间的距离,如表7所示。初始条件是机床接通电源十分钟,热状态是机床加热两个小时的状态,然后实施热误差控制。结果表明,由于热效应,在没有误差控制的情况下,热状态下孔距的误差在[15μm,21μm]范围内。此外,当使用bayesian
‑
lstm神经网络模型作为热状态下的实时误差预测模型实现自学习误差控制系统时,孔距的加工误差在[1μm,5μm]范围内。在热状态下,当以mlra模型作为实时误差预测模型实现自学习误差控制系统时,孔距的加工误差在[7μm,11μm]范围内,并且加工误差当使用bp神经网络模型作为实时误差预测模型来实现自学习误差控制系统时,孔距的误差在[12μm,16μm]范围内。
[0144]
表7.有和没有热误差控制的加工误差(μm)
[0145][0146]
以上所述实施例仅是为充分说明本发明而所举的较佳的实施例,本发明的保护范围不限于此。本技术领域的技术人员在本发明基础上所作的等同替代或变换,均在本发明的保护范围之内。本发明的保护范围以权利要求书为准。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1