一种基于跨度表示的端到端的菜谱信息抽取方法及系统
1.本发明涉及知识图谱领域,具体涉及一种基于跨度表示的端到端的菜谱信息抽取方法及系统。
背景技术:
2.食品安全风险防控一直是大型赛事保障工作的重点,加强食品安全风险识别与防控对维护重大赛事的顺利举行,具有极其重要的意义。安全风险相关数据存在分布散乱,关联性不强等问题,具有多源头,多渠道,多环节的特点。知识图谱提供了一种更好管理、组织和理解海量信息的方法,其以如(鱼香肉丝,原料,肉丝)这样的三元组的形式描述客观世界中的概念、实体及其关系,具有强大的语义关联能力。菜谱知识图谱的构建,将菜谱相关的知识进行整合,关联成一个“语义网络”,并以可视化的形式呈现,为食品风险按防控工作提供底层数据支撑。
3.信息抽取包括命名实体识别和关系抽取,即从原始文本中识别出实体以及实体所属的类型同时判断出命名实体识别所识别出的实体之间的关系。信息抽取是构建知识图谱的关键一步同时也对下游自然语言处理任务,比如,问答、语义检索等任务起到支持作用。抽取质量直接影响整个知识图谱的质量。流水线式的方法是信息抽取中一种传统的方法,即先用一个模型进行命名实体识别,然后通过另一个模型进行关系抽取。鉴于这种流水线式的方法容易造成错误累积,端到端的信息抽取技术成为主流。如果一个实体对中的两个实体分别为鱼香肉丝和肉丝,这样的实体为重叠实体。在菜谱语料中存在大量像鱼香肉丝和肉丝这样的重叠实体,传统的端到端的方法对于解决重提实体问题效果并不突出。
技术实现要素:
4.为了解决上述技术问题,本发明提供一种基于跨度表示的端到端的菜谱信息抽取方法及系统。
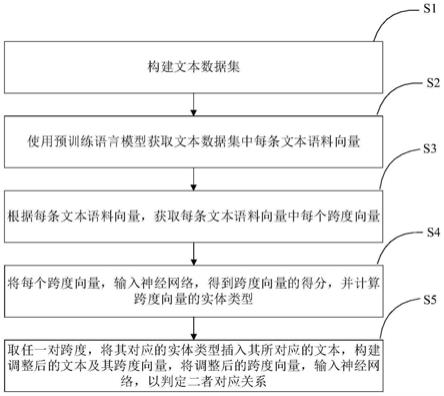
5.本发明技术解决方案为:一种基于跨度表示的端到端的菜谱信息抽取方法,包括:
6.步骤s1:构建文本数据集;
7.步骤s2:使用预训练语言模型获取所述文本数据集中每条文本语料向量;
8.步骤s3:根据每条所述文本语料向量,获取每条所述文本语料向量中每个跨度向量;
9.步骤s4:将所述每个跨度向量,输入神经网络,得到所述跨度向量的得分,并计算所述跨度向量的实体类型;
10.步骤s5:取任一对所述跨度,将其对应的实体类型插入其所对应的所述文本,构建调整后的文本及其跨度向量,将所述调整后的跨度向量,输入神经网络,以判定二者对应关系。
11.本发明与现有技术相比,具有以下优点:
12.本发明提供的方法通过一种端到端的模型,从文本数据中联合抽取菜谱中的实体
以及实体之间的对应关系,将命名实体识别和关系分类转化为分类任务,能通过简单的前馈神经网络解决复杂的信息抽取任务。当一个实体包含于另一个实体中时,两个不同的实体属于不同的跨度,有不同的向量表示,能有效解决重叠实体问题,极大的提高菜谱文本数据的信息抽取的准确率。
附图说明
13.图1为本发明实施例中一种基于跨度表示的端到端的菜谱信息抽取方法的流程图;
14.图2为本发明实施例中一种基于跨度表示的端到端的菜谱信息抽取方法中步骤s3:根据每条文本语料向量,获取每条文本语料向量中每个跨度向量的流程图;
15.图3为本发明实施例中一种基于跨度表示的端到端的菜谱信息抽取方法中步骤s4:将跨度向量,输入神经网络,得到跨度向量的得分,并计算跨度向量的实体类型的流程图;
16.图4为本发明实施例中一种基于跨度表示的端到端的菜谱信息抽取方法中步骤s5:取任一对跨度,将其对应的实体类型插入其所对应的文本进行调整,构建调整后的文本及其跨度向量,将调整后的跨度向量,输入神经网络,以判定二者对应关系的流程图;
17.图5为本发明实施例中基于跨度表示的端到端的菜谱信息抽取模型示意图;
18.图6本发明实施例中一种基于跨度表示的端到端的菜谱信息抽取系统的结构框图。
具体实施方式
19.本发明提供了一种基于跨度表示的端到端的菜谱信息抽取方法,有效解决菜谱中重叠实体问题,极大的提高菜谱文本数据的信息抽取的准确率。
20.为了使本发明的目的、技术方案及优点更加清楚,以下通过具体实施,并结合附图,对本发明进一步详细说明。
21.实施例一
22.如图1所示,本发明实施例提供的一种基于跨度表示的端到端的菜谱信息抽取方法,包括下述步骤:
23.步骤s1:构建文本数据集;
24.步骤s2:使用预训练语言模型获取文本数据集中每条文本语料向量;
25.步骤s3:根据每条文本语料向量,获取每条文本语料向量中每个跨度向量;
26.步骤s4:将每个跨度向量,输入神经网络,得到跨度向量的得分,并计算跨度向量的实体类型;
27.步骤s5:取任一对跨度,将其对应的实体类型插入其所对应的文本,构建调整后的文本及其跨度向量,将调整后的跨度向量,输入神经网络,以判定二者对应关系。
28.在一个实施例中,上述步骤s1:构建文本数据集,具体包括:
29.利用爬虫技术,获取百度百科、美食杰以及其他网站上的非结构化和半结构化的食谱信息,形成文本数据集。通过人工标注,标出每条文本数据中的实体以及实体之间对应的关系。
30.在一个实施例中,上述步骤s2:使用预训练语言模型获取文本数据集中每条文本语料向量,具体包括:
31.使用现有的预训练语言模型对文本数据集中每条文本进行处理。本发明实施例采用 bert预训练语言模型,获取文本数据集中的每条文本语料向量;其中,处理前的文本表示为x={x1,...,x
n
},处理后的文本语料向量表示为x={x1,...,x
n
};
32.其中,x
i
是该条文本数据中第i个汉字的向量。
33.如图2所示,在一个实施例中,上述步骤s3:根据每条文本语料向量,获取每条文本语料向量中每个跨度向量,具体包括:
34.步骤s31:获得文本语料向量中所有跨度向量;其中,跨度为每条文本语料中所有可能的汉字组合;跨度表示为s={s1,...,s
m
},其中,s
i
为该文本语料的第i个跨度,n 为文本长度,
35.步骤s32:构建跨度s
i
的向量其中,x
start(i)
表示s
i
的起始位置向量,x
end(i)
示跨度s
i
的结束位置向量,表示s
i
中所有向量的加权和,φ(i)是表示s
i
大小的向量。
[0036][0037]
如图3所示,在一个实施例中,上述步骤s4:将跨度向量,输入神经网络,得到跨度向量的得分,并计算得到跨度向量的实体类型,具体包括:
[0038]
步骤s41:将每个跨度向量g
i
,构建输入g={g1,...,g
m
},输入神经网络,得到跨度向量得分;
[0039]
以每个上述跨度向量g
i
构建得到的g={g1,...,g
m
}作为输入,通过带有激活函数的两层前馈神经网络ffnn,如下述公式(1),平行计算每个跨度向量得分;
[0040][0041]
步骤s42:根据跨度向量得分,计算得到跨度向量的实体类型e
i
。
[0042]
本发明实施例采用如下述公式(2)的softmax函数,判断跨度向量所属实体类型。
[0043][0044]
本发明实施例预先定义菜谱的实体类型为:菜名、菜系、工艺、原材料、人群以及营养元素。根据值,将其划分至对应的实体类型e
i
。如果用来表示识别出来的跨度向量不属于上述任何预先定义好的实体类型,该跨度向量不是一个实体,将其归为空实体。
[0045]
如图4所示,在一个实施例中,上述步骤s5:取任一对跨度,将其对应的实体类型插入其所对应的文本进行调整,构建调整后的文本及其跨度向量,将调整后的跨度向量,输入神经网络,以判定二者对应关系,具体包括:
[0046]
步骤s51:取任一对跨度s
i
和s
j
,将其对应的实体类型e
i
和e
j
插入文本中进行调整,则调整后的文本表示为: x
*
= {...,<s:e
i
>,x
start(i)
,...,x
end(i)
,</s:e
i
>,...,< o:e
j
>,x
start(j)
,...,x
end(j)
,</o:e
j
>,...};s
i*
和s
j*
分别表示调整后的跨度,其对应的跨度向量表示分别为和和其中表示< s:e
i
>通过预训练语言模型后的输出向量,表示</s:e
i
>通过预训练语言模型后的输出向量,
表示s
i*
大小的向量;的表示方法相同;
[0047]
为了提高效率,本发明实施例取任意一对实体类型为非空的跨度s
i
和s
j
,进行文本的调整以及构建调整后的跨度向量。
[0048]
步骤s52:将调整后的跨度向量和构建输入并输入神经网络,以判定二者对应关系。
[0049]
以构建的作为带有激活函数的前馈神经网络ffnn的输入,利用下述公式(3)计算二者关系类型得分,并在该得分上利用softmax函数,如下述公式(4) 判定二者所属关系类型。
[0050][0051][0052]
本发明定义了菜谱的关系类型:属于、采用、原料是、适合,不适合、相生、相克以及富含。如果得到关系类型为空关系,则表明二者之间没有对应关系。
[0053]
如图5所示,展示了本发明的基于跨度表示的端到端的菜谱信息抽取模型示意图,先获取文本的跨度向量所对应的实体分类,再基于该实体分类,构建调整后的文本语料向量,最终确定实体之间的关系分类。
[0054]
本发明提供的方法通过一种端到端的模型从文本数据中联合抽取菜谱中的实体以及实体之间的对应关系,通过解决重叠实体问题,极大的提高菜谱文本数据的信息抽取的准确率。
[0055]
实施例二
[0056]
如图6所示,本发明实施例提供了一种基于跨度表示的端到端的菜谱信息抽取系统,包括下述模块:
[0057]
构建文本数据集模块61,用于构建文本数据集;
[0058]
构建文本语料向量模块62,用于使用预训练语言模型获取文本数据集中每条文本语料向量;
[0059]
构建跨度向量模块63,用于根据每条文本语料向量,获取每条文本语料中每个跨度的向量;
[0060]
获取实体类型模块64,用于将每个跨度向量,输入神经网络,得到跨度向量的得分,并计算跨度向量的实体类型;
[0061]
判定跨度向量关系模块65,用于取任一对跨度,将其对应的实体类型插入其所对应的所述文本,构建调整后的文本及其跨度向量,将调整后的跨度向量,输入神经网络,以判定二者对应关系。
[0062]
提供以上实施例仅仅是为了描述本发明的目的,而并非要限制本发明的范围。本发明的范围由所附权利要求限定。不脱离本发明的精神和原理而做出的各种等同替换和修改,均应涵盖在本发明的范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1