虚拟云环境中显卡故障的处理方法及装置与流程
本发明涉及显卡故障的处理技术领域,具体的涉及虚拟云环境中显卡故障的处理方法及装置。
背景技术:
在实际使用中,显卡故障现象会经常出现,正常使用中的显卡故障会导致服务不可用,运行在该显卡上的服务都不应该再继续提供服务,需要被调度走,而目前业内没有相关在虚拟云环境例如kubernetes环境中对于gpu显卡故障的处理方式。
之前物理机gpu集群上有自己的故障显卡屏蔽方案,在迁移到例如基于kubernetes和容器的虚拟化云环境中,因为虚拟化的特点之一就是应用和服务器解耦,由调度器分配,应用具体运行的宿主机也是不确定的,会经常受调度器的调度而迁移。对于客户端来说,能感知到的也就是一个入口地址,对于后面的运行环境完全不知。因此,在物理机环境下工作的故障显卡屏蔽方案无效,现有技术中不存在针对云端环境的显卡故障处理方法,需要针对云端环境重新设计。
另外,对于现有虚拟化后的架构来说,调度过程对于显卡故障不能进行屏蔽,导致新的这套架构不能稳定运行。
有鉴于此,特提出本发明。
技术实现要素:
本发明的目的在于:提供针对虚拟云环境进行故障显卡的屏蔽方案,保证虚拟框架的稳定运行。
为了实现上述发明目的,本发明提供了以下技术方案:
本发明提供一种虚拟云环境中显卡故障的处理方法,包括:
监听表征显卡故障的变动事件;
根据所述变动事件对存储的显卡资源信息进行数据同步处理,所述显卡资源信息包括所述虚拟云环境中的集群节点、显卡和服务之间的拓扑结构及显卡状态信息;
基于同步后的所述显卡资源信息,对虚拟云环境中的显卡故障进行后续处理,并同步更新所述显卡资源信息。
作为本发明的可选实施方式,采用邻接矩阵存储所述显卡资源信息;所述同步处理是对所述邻接矩阵进行数据同步处理。
作为本发明的可选实施方式,所述虚拟云环境为基于kubernetes的虚拟云环境;所述处理方法还包括:获取显卡故障信息,并在命名空间中创建配置文件来记录所述显卡故障信息;
所述监听表征显卡故障的变动事件,包括:监听所述命名空间下配置文件的变动事件;
可选地,通过和kubernetes的apiserver组件之间维持长连接,接收所述命名空间下的配置文件的变动事件。
作为本发明的可选实施方式,所述获取显卡故障信息,并在命名空间中创建配置文件来记录所述显卡故障信息,包括:
步骤s1001,在每个gpu机器上启动显卡检测程序;
步骤s1002,所述显卡检测程序周期性地获取所有显卡故障信息;
步骤s1003,如果获取到显卡故障信息,则在所述命名空间创建所述配置文件;
可选地,步骤s1001中通过启动kubernetes的daemonset,在每个gpu机器上启动显卡检测程序;
可选地,步骤s1002中,所述显卡检测程序通过显卡驱动的api接口周期性地获取所有显卡故障信息。
作为本发明的可选实施方式,所述根据所述变动事件对存储的所述显卡资源信息进行数据同步处理,包括下述中的一种或多种:
判断所述变动事件是否为故障新建事件,如果是故障新建事件,获取故障显卡的ip地址和显卡卡号列表,并将所述ip地址和所述显卡卡号存入所述显卡资源信息;
判断所述变动事件是否为显卡状态更改事件,如果是显卡状态更改事件,获取待修改显卡的ip地址和显卡卡号列表,基于待修改显卡的所述ip地址和显卡卡号列表修改所述显卡资源信息,更改显卡状态;
判断所述变动事件是否为故障删除事件,如果是故障删除事件,获取待删除故障对应的显卡的ip地址,基于所述ip地址删除所述显卡资源信息中对应的故障数据。
作为本发明的可选实施方式,所述对虚拟云环境中的显卡故障进行后续处理,包括:
为新创建的服务分配显卡时不再使用故障显卡;
驱逐所述故障显卡上已存在的服务。
作为本发明的可选实施方式,所述驱逐所述故障显卡上已存在的服务,包括:在kubernetes的虚拟云环境,通过订阅所述命名空间表征显卡故障的变动事件获取到显卡故障信息时,对所述故障显卡上已有服务进行删除,并同步服务变动信息到所述显卡资源信息;
可选地,将所述显卡资源信息存储在邻接矩阵时,所述驱逐所述故障显卡上已存在的服务包括:
订阅所述命名空间下配置文件变动事件,并判断所述变动事件的类型,所述配置文件为在获取到显卡故障信息时在所述命名空间所创建的记录所述显卡故障信息的文件;
当接收到的所述变动事件是配置文件新建事件或者配置文件修改事件时,获取所述变动事件涉及的故障显卡信息,并判断所述变动事件涉及gpu机器的总故障显卡是否超过设定值,若是,则遍历所述邻接矩阵,删除对应gpu机器所有显卡上的服务,并删除该gpu机器,以使kubernetes完成后续的故障显卡服务迁移重启操作;若否,则在所述邻接矩阵中找到所述变动事件涉及的故障显卡对应服务列表并删除,以使kubernetes完成后续的被删除服务的迁移重启操作。
作为本发明的可选实施方式,在kubernetes的虚拟云环境,且将所述显卡资源信息存储在邻接矩阵时,所述为新创建的服务分配显卡时不再使用所述故障显卡,包括:
新创建的服务启动显卡分配时,获取所述邻接矩阵,遍历gpu机器,获取可使用的显卡资源,所述可使用的显卡资源已过滤掉故障显卡;
判断所述可使用的显卡资源是否充足,选择可用显卡分配新创建的服务,并在所述邻接矩阵中查找该分配新创建的服务的显卡的对应gpu机器和显卡卡号,更新服务列表。
本发明实施例同时提供一种虚拟云环境中显卡故障的处理装置,包括:
数据处理模块,用于存储所述虚拟云环境中的显卡资源信息,并在监听到表征显卡故障的变动事件时,根据变动事件的类型对存储的所述显卡资源信息进行数据同步处理,所述显卡资源信息包括集群节点、显卡和服务之间的拓扑结构及显卡状态信息;
后续处理模块,用于基于同步后的所述显卡资源信息,对虚拟云环境中的显卡故障进行后续处理,并通过所述数据处理模块同步更新所述显卡资源信息。
作为本实施例的可选实施方式,所述虚拟云环境为基于kubernetes的虚拟云环境,所述处理装置还包括:探针模块,用于获取各gpu机器的显卡故障信息,并在命名空间中创建配置文件来记录所述显卡故障信息;
可选地,所述数据处理模块在监听到配置文件变动事件时:判断所述配置文件变动事件是否为配置文件新建事件,如果是,获取该新建事件包含的故障显卡的ip地址和显卡卡号列表,并根据所述ip地址和所述显卡卡号将故障显卡信息存入所述显卡资源信息;判断所述配置文件变动事件是否为显卡状态更改事件,如果是,获取显卡状态更改事件指向的ip地址和显卡卡号列表,基于所述ip地址和显卡卡号列表修改所述显卡资源信息,更改显卡状态;判断所述配置文件变动事件是否为配置文件删除事件,如果是,获取该配置文件删除事件指向的显卡的ip地址和显卡卡号,基于所述ip地址和显卡卡号删除所述显卡资源信息中对应的故障数据;
可选地,所述后续处理模块包括驱逐者模块,所述驱逐者模块用于在通过订阅所述命名空间的配置文件变动事件获取到显卡故障时,对故障显卡上已有服务进行删除,并同步服务变动信息到所述显卡资源信息;
可选地,所述后续处理模块包括调度模块,所述调度模块用于为新创建的服务进行显卡分配,所述调度模块在启动显卡分配时,根据所述显卡资源信息获取可使用的显卡资源,所述可使用的显卡资源已过滤掉故障显卡,并判断所述可使用的显卡资源是否充足,选择可用显卡分配新创建的服务,并在所述显卡资源信息中更新对应显卡的服务列表;
进一步可选地,所述数据处理模块采用邻接矩阵存储所述显卡资源信息;
进一步可选地,所述数据处理模块全局范围内启动单实例,注册命名空间并监听该命名空间下配置文件变动事件;并判断所述变动事件类型,根据所述变动事件的类型对邻接矩阵进行数据同步处理;可选地,所述数据处理模块通过和kubernetes系统的apiserver之间维持长连接,接收所述命名空间下的配置文件的变动事件;
进一步可选地,所述探针模块采用daemonset部署,主要流程为:
在每个gpu机器上启动对应的判断程序,循环判断每张显卡,调用驱动api接口判断显卡状态,若判断为显卡健康,则返回至循环判断步骤,若判断为显卡不健康,则在探针模块的命名空间创建/修改/删除包含节点ip和显卡的配置文件资源;
可选地,所述的驱逐者模块全局范围内启动单实例,与数据处理模块共享命名空间,订阅命名空间下的配置文件的变动事件,当接收到变动事件是新建事件或者修改事件时,判断本次新建事件或者修改事件的故障显卡数量是否超过设定值,若是,则遍历邻接矩阵,将对应gpu机器所有显卡对应服务列表删除,若否,则在邻接矩阵中找到显卡对应服务列表并删除;
可选地,所述调度模块全局范围内启动单实例,新创建的服务启动显卡分配时,获取所述邻接矩阵,遍历所述gpu机器,过滤掉故障显卡,判断显卡资源是否充足,选择可用显卡分配所述新创建的服务,然后在邻接矩阵中查找对应gpu机器和显卡,更新服务列表。
本发明同时还提供一种电子设备,包括处理器和存储器,所述存储器用于存储计算机可执行程序,当所述计算机程序被所述处理器执行时,所述处理器执行上述任一项所述的虚拟云环境中显卡故障的处理方法。
与现有技术相比,本发明的有益效果:
本发明的虚拟云环境中显卡故障的处理方法,对虚拟环境中的显卡资源信息例如集群节点、显卡及服务之间的拓扑结构及状态进行存储;监听表征显卡故障的变动事件,当监听到变动事件时,可根据该变动事件对存储的显卡资源信息进行数据同步处理,从而实现显卡资源信息的实时更新;然后基于同步后的所述显卡资源信息,对虚拟云环境中的显卡故障进行后续处理,可针对显卡故障的变动事件将故障显卡所对应的服务、或者集群节点进行处理,从而屏蔽故障显卡,保障虚拟框架的稳定运行;并同步更新所述显卡资源信息,确保显卡资源信息实时更新,针对虚拟云环境进行实时监测,针对虚拟云环境中的显卡故障进行实时监控、实时处理。
通过本发明的方案,还可提供相关功能给其他模块,用于ip、显卡卡号和服务数据查询和修改。
本发明针对虚拟环境中显卡出现故障的场景,可根据存储的虚拟云环境中的显卡资源信息,将该故障显卡上已存在的服务进行驱逐;控制新的服务不再使用故障显卡。
本发明可针对虚拟环境进行故障显卡的屏蔽,保证虚拟框架的稳定运行。
附图说明:
图1根据本发明一些实施例的虚拟云环境中显卡故障的处理方法的流程框图;
图2根据本发明一些实施例的虚拟云环境中显卡故障的处理方法中获取显卡故障信息并在命名空间中创建配置文件来记录所述显卡故障信息的流程框图;
图3根据本发明一些实施例的虚拟云环境中显卡故障的处理方法中根据所述变动事件对存储的显卡资源信息进行数据同步处理的流程框图;
图4根据本发明一些实施例的虚拟云环境中显卡故障的处理方法的全局处理流程示意图;
图5根据本发明一些实施例的一种数据处理模块的邻接矩阵的存储方式示意图;
图6根据本发明一些实施例的驱逐者模块对故障显卡上已有服务进行驱逐的流程框图;
图7根据本发明一些实施例的调度模块新建服务的流程框图;
图8根据本发明一些实施例的探针模块工作的流程框图。
具体实施方式
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合附图,对本发明实施例中的技术方案进行清楚、完整的描述。显然,所描述的实施例是本发明的一部分实施例,而不是全部的实施例。
因此,以下对本发明的实施例的详细描述并非旨在限制要求保护的本发明的范围,而是仅仅表示本发明的部分实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
需要说明的是,在不冲突的情况下,本发明中的实施例及实施例中的特征和技术方案可以任意组合。
应注意到:相似的标号和字母在下面的附图中表示类似项,因此,一旦某一项在一个附图中被定义,则在随后的附图中不需要对其进行进一步定义和解释。
在本发明的描述中,需要说明的是,术语“上”、“下”等指示的方位或位置关系为基于附图所示的方位或位置关系,或者是该发明产品使用时惯常摆放的方位或位置关系,或者是本领域技术人员惯常理解的方位或位置关系,这类术语仅是为了便于描述本发明和简化描述,而不是指示或暗示所指的装置或元件必须具有特定的方位、以特定的方位构造和操作,因此不能理解为对本发明的限制。此外,术语“第一”、“第二”等仅用于区分描述,而不能理解为指示或暗示相对重要性。
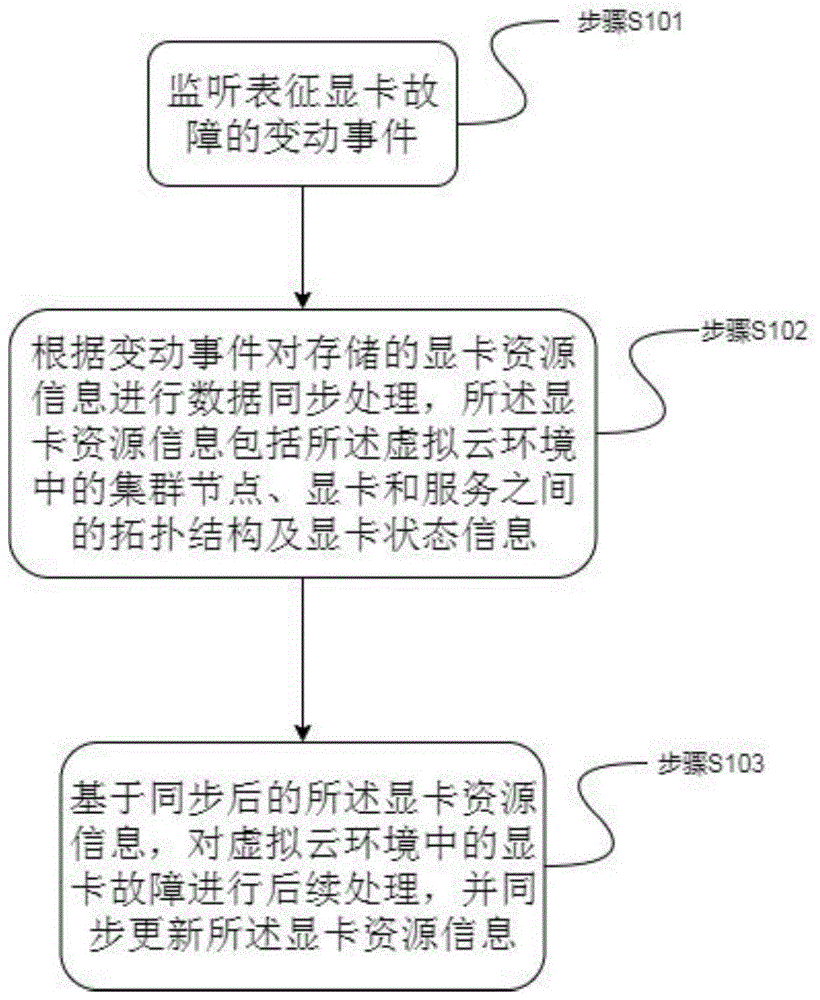
本实施例提供的虚拟云环境中显卡故障的处理方法,参见图1所示,该方法包括:
步骤101、监听表征显卡故障的变动事件。
本步骤监听虚拟云环境中的显卡是否发生了故障,并获取后续显卡故障处理所需要的显卡故障信息。所述监听的具体实现方式存在多种,因其对本方案的实现效果不产生影响,在此本实施例不做限定。一般本领域技术人员可依据具体情况进行设计。如,采用kubernetes系统实现的虚拟云环境中,可以通过和apiserver之间维持长连接,接收命名空间下的配置文件的变动事件;并预先在检测到显卡故障时在命名空间中创建config文件资源来提供实现基础。
步骤102、根据变动事件对存储的显卡资源信息进行数据同步处理,所述显卡资源信息包括所述虚拟云环境中的集群节点、显卡和服务之间的拓扑结构及显卡状态信息。
本实施例预先将虚拟云环境中的集群节点、显卡和服务之间的拓扑结构及显卡状态信息存储在所述显卡资源信息中。
监听到表征显卡故障的变动事件时,本步骤根据从变动事件获取显卡故障信息,对用于存储虚拟云环境中的显卡相关信息的显卡资源信息进行数据同步处理,经过该数据同步处理,可以及时地将显卡故障信息记录下来,以便后续进行显卡故障处理。
步骤103、基于同步后的所述显卡资源信息,对虚拟云环境中的显卡故障进行后续处理,并同步更新所述显卡资源信息。
本步骤根据同步后的显卡资源信息进行对虚拟云环境中的显卡故障进行后续处理,有必要的话同步更新所述显卡资源信息。此处对显卡故障进行后续处理主要可包括:为新创建的服务分配显卡时不再使用故障显卡;驱逐故障显卡上已存在的服务。故障显卡指表征显卡故障的变动事件中包含的发生故障的不能正常工作的显卡。
本实施例的虚拟云环境中显卡故障的处理方法,对虚拟环境中的显卡资源信息例如集群节点、显卡及服务之间的拓扑结构及状态进行存储;监听表征显卡故障的变动事件,当监听到变动事件时,可根据该变动事件对存储的显卡资源信息进行数据同步处理,从而实现显卡资源信息的实时更新;然后基于同步后的所述显卡资源信息,对虚拟云环境中的显卡故障进行后续处理,可针对显卡故障的变动事件将故障显卡所对应的服务、或者集群节点进行处理,从而屏蔽故障显卡,保障虚拟框架的稳定运行;并同步更新所述显卡资源信息,确保显卡资源信息实时更新,针对虚拟云环境中的显卡故障进行实时监控、实时处理。
作为本实施例的可选实施方式,本实施例可采用邻接矩阵存储所述显卡资源信息;所述同步处理是对所述邻接矩阵进行数据同步处理。
示例性地,参见图5所示,一种采用邻接矩阵存储所述显卡资源信息的示意图。本示例中的显卡资源信息包括显卡卡号、本显卡是否故障、本显卡的总显存、名称、使用显存、本显卡上运行的服务信息等。
在一些实施例中,本实施例所述虚拟云环境为基于kubernetes的虚拟云环境;所述处理方法还包括:
步骤s100、获取显卡故障信息,并在命名空间中创建配置文件来记录所述显卡故障信息;
步骤101所述监听表征显卡故障的变动事件,包括:监听所述命名空间下配置文件的变动事件。需要说明的是,基于不同的虚拟环境系统可以针对性的选择不同的文件作为载体,只要能够记录显卡故障检测的结果,用来共享显卡信息变动即可,并不限于本实施例所述的配置文件。
可选地,基于kubernetes的虚拟云环境下,可通过和kubernetes的apiserver组件之间维持长连接,接收所述命名空间下的配置文件的变动事件。
示例性地,参见图2所示,本实施例步骤s100获取显卡故障信息,并在命名空间中创建配置文件来记录所述显卡故障信息,可包括:
步骤s1001,在每个gpu机器上启动显卡检测程序;
步骤s1002,所述显卡检测程序周期性地获取所有显卡故障信息;
步骤s1003,如果获取到显卡故障信息,则在所述命名空间创建所述配置文件;
可选地,步骤s1001中可通过启动kubernetes的daemonset,在每个gpu机器上启动显卡检测程序。
可选地,步骤s1002中,所述显卡检测程序可通过显卡驱动的api接口周期性地获取所有显卡故障信息。具体检测周期本领域技术人员可以根据实际情况确定。或者,根据实验确定最优周期,在系统开销和功能实现上达到平衡。api接口,api是applicationprogramminginterface的缩写,是应用程序接口的意思。api接口能让编程人员所设计的软件,调用显卡内置的程序,从而让软件自动和硬件的驱动程序沟通,从而大幅度地提高了程序的设计效率。程序员只需要编写符合接口的程序代码,就可以充分发挥显卡的已有功能,不必再去了解硬件的具体性能和参数,大大简化了程序开发的效率。
进一步地,参见图3所示,本实施例步骤s102所述根据变动事件对存储的所述显卡资源信息进行数据同步处理,可包括下述中的一种或多种:
判断所述变动事件是否为故障新建事件,如果是故障新建事件,获取故障显卡的ip地址和显卡卡号列表,并将所述ip地址和所述显卡卡号存入所述显卡资源信息,更改显卡状态;
判断所述变动事件是否为显卡状态更改事件,如果是显卡状态更改事件,获取待修改显卡的ip地址和显卡卡号列表,基于待修改显卡的所述ip地址和显卡卡号列表修改所述显卡资源信息;
判断所述变动事件是否为故障删除事件,如果是故障删除事件,获取待删除故障对应的显卡的ip地址,基于所述ip地址删除所述显卡资源信息中对应的故障数据。
本实施例的虚拟云环境中显卡故障的处理方法,步骤s103所述的对虚拟云环境中的显卡故障进行后续处理,包括:为新创建的服务分配显卡时,不再使用所述故障显卡;驱逐所述故障显卡上已存在的服务。
进一步地,本实施例所述驱逐所述故障显卡上已存在的服务,可包括:在kubernetes的虚拟云环境,通过订阅所述命名空间表征显卡故障的变动事件,对故障显卡上已有服务进行删除,并同步服务变动信息到所述显卡资源信息。这样,在发现故障显卡时可及时针对故障显卡上已有服务进行驱逐,避免造成服务故障,数据丢失。
参见图6所示,将所述显卡资源信息存储在邻接矩阵时,该步骤包括:
订阅所述命名空间下配置文件变动事件,并判断所述变动事件的类型,所述配置文件为在获取到显卡故障信息时在所述命名空间所创建的记录所述显卡故障信息的文件。
本实施例通过配置文件记录显卡故障信息,配置文件在命名空间下可被共享,从而实现对显卡故障信息的共享调用及同步,本实施例的配置文件的内容是由开发人员根据具体的使用场景以及记录的对象确定的。例如,可在k8s环境下采用config文件作为配置文件,config文件是k8s提供的,我们要做的是利用这个功能,去更新维护机器、显卡以及工作在显卡上的服务这三者之间的关联关系,config文件配置的内容根据需求可由开发人员确定。
当接收到的所述变动事件是配置文件新建事件或者配置文件修改事件时,获取所述变动事件涉及的故障显卡信息,并判断所述变动事件涉及机器的总故障显卡是否超过设定值,若是,则遍历所述邻接矩阵,删除对应机器所有显卡上的服务,并删除该机器,以使kubernetes完成后续的故障显卡服务迁移重启操作;
若否,则在所述邻接矩阵中找到所述变动事件涉及的故障显卡对应服务列表并删除,以使kubernetes完成后续的被删除服务的迁移重启操作。
kubernetes环境下,当上述“删除对应机器所有显卡上的服务,并删除该机器”,kubernetes会自动完成后续的故障显卡服务迁移重启操作;当“找到所述变动事件涉及的故障显卡对应服务列表并删除”kubernetes会自动完成后续的被删除服务的迁移重启操作。本实施例利用了kubernetes原有功能完成节点删除和服务驱逐。
本实施例在发生配置文件新建事件或者配置文件修改事件时,针对与配置文件新建事件或者配置文件修改事件相关联的故障显卡上运行的服务进行迁移重启,确保服务的正常稳定运行。针对含有故障显卡数量过多的机器,还需要针对机器进行删除,提醒相关人员进行维修。
可选地,判断本次配置文件新建事件或者配置文件修改事件后该gpu机器的故障显卡数量是否超过一半,即上述设定值可以为该gpu机器的总显卡数量的一半。
参见图7,本实施例所述的虚拟云环境中显卡故障的处理方法,在kubernetes的虚拟云环境,且将所述显卡资源信息存储在邻接矩阵时,所述为新创建的服务分配显卡时,不再使用所述故障显卡,包括:
为新创建的服务启动显卡分配时,获取所述邻接矩阵,遍历gpu机器,获取可使用的显卡资源,所述可使用的显卡资源已过滤掉故障显卡;
判断所述可使用的显卡资源是否充足,选择可用显卡分配新创建的服务,并在所述邻接矩阵中查找该分配新创建的服务的显卡的对应机器和显卡号,更新服务列表。
本实施例的虚拟云环境中显卡故障的处理方法可针对新创建的服务提供健康显卡分配服务,确保新建服务的运行稳定,且能最大化的进行显卡资源配置,提高了系统的运行的稳定性及高效性。
参见图4所示,具体地,本实施例提供一种基于kubernetes(简称k8s)的虚拟环境中显卡故障的处理方法,包括数据处理模块、探针模块、调度模块和驱逐者模块。本实施采用在命名空间中创建配置文件(config文件)来记录收到的显卡故障信息,通过监听所述命名空间下配置文件的变动事件获取显卡故障信息,
所述的数据处理模块以邻接矩阵的方式存储了集群节点、显卡和服务拓扑结构。本实施例的数据处理模块可以为模型层,采用单实例部署方式。所述的数据处理模块全局范围内启动单实例,注册命名空间并监听该命名空间下config文件的变动事件;判断变动事件,并根据变动事件的类型对邻接矩阵进行数据同步处理。
本实施例针对变动事件进行了分类以及对应的处理流程可如下:
判断变动事件如果是新建事件(表示出现新的故障),通过split方法,解析config文件,从config文件中获取ip和显卡卡号列表,将ip和显卡卡号存入邻接矩阵。
优选地,按照ip分组,将故障显卡卡号数据存入邻接矩阵。
变动事件如果是更改事件,通过split方法,解析config文件,从config文件中获取ip和显卡卡号列表,遍历对比邻接矩阵,找到变更显卡,更新状态数据(记录故障或者恢复正常)
如果是删除事件:通过split方法,从config文件中获取ip,将本ip下的数据更新状态为恢复正常
优选地,数据处理模块可以按照ip分组,遍历分组与邻接矩阵对比,找到变更显卡,更新状态数据:记录显卡故障或者显卡恢复正常。
为了实现对数据处理模块的命名空间下的变动事件进行监听,本实施例所述的数据处理模块通过和kubernetes的apiserver之间维持长连接,接收命名空间下的config文件的变动事件。
本实施例的数据处理模块还可提供方法给其他模块,用于ip、显卡卡号和服务数据查询和修改:
1、提供查询功能:遍历邻接矩阵,通过ip或者ip+显卡卡号的方式,查询显卡信息列表和运行的服务列表。
2、提供删除服务功能:遍历邻接矩阵,通过ip或者ip+显卡卡号的方式,选择删除一个节点上所有显卡的服务列表或者删除指定显卡上的服务列表。
3、提供删除节点功能:遍历邻接矩阵,通过输入ip,删除一个节点上所有显卡服务列表,并删除本节点。
4、提供添加功能:遍历邻接矩阵,通过ip+显卡卡号+服务的方式,追加一个节点上指定显卡的服务列表。
参见图4所示,探针模块,部署方式为daemonset部署(daemonset为kubernetes的概念,在每个符合要求的服务器上启动守护进程)。
本实施例探针模块主要职责为:检查本节点显卡状态,组织数据传递给数据模块,数据结构如下:
config文件结构:
apiversion:v1
kind:configmap
metadata:
name:unhealthy-gpu-192.168.1.123
data:
gpus:"1,7"。
参见图8所示,本实施例探针模块的主要流程包括:
步骤s101,启动daemonset,在每个gpu机器上启动对应的检测程序;
步骤s102,循环判断每张显卡:程序通过显卡驱动的api循环获取所有显卡错误信息,正常则休眠等待下一次检测,重复步骤s102;不正常,则执行步骤s103。
步骤s103,在探针模块的命名空间创建包含节点ip和显卡的config文件资源。
优选地,所述的步骤s101检测程序可以定时启动,或者,间隔预定周期检测一次。
针对虚拟云环境中出现的故障显卡,当检测到显卡故障,需要将该故障显卡上已存在的服务进行驱逐,并且新创建的服务将不再分配到故障显卡。
参见图4所示,本实施例的驱逐者模块用于将已在故障显卡上运行的服务驱逐。
驱逐者模块可通过订阅config文件的变动事件,对故障显卡上已有服务进行删除,并同步服务变动信息到数据层(邻接矩阵)。本实施例驱逐者模块的部署方式为单实例部署。
所述的驱逐者模块全局范围内启动单实例,与数据处理模块共享命名空间,通过订阅命名空间下的config文件的变动事件,当接收到变动事件进行判断:当判断变动事件是新建事件或者修改事件时,判断本次新建事件或者修改事件的故障显卡数量是否超过设定值,若是,则遍历所述邻接矩阵,删除对应机器所有显卡上的服务,并删除该机器,以使kubernetes完成后续的故障显卡服务迁移重启操作;若否,则在所述邻接矩阵中找到所述变动事件涉及的故障显卡对应服务列表并删除,以使kubernetes完成后续的被删除服务的迁移重启操作。
优选地,判断本次故障新建事件或者显卡状态更改事件后,该gpu机器上故障显卡数量是否超过一半。
具体地,驱逐者模块针对变动事件的的处理流程如下:
对于新建事件:通过split方法,获取本次事件的显卡数量,判断该机器故障显卡数量是否超过设定值,若判断结果为是,则进行机器下线流程,若判断结果为否,则驱逐服务流程。
对于显卡状态更改事件:通过split方法,获取本次事件故障显卡列表,通过数据处理模块获取已经故障的显卡,将两组数据组合,判断故障显卡数量是否超过设定值,若判断结果为是,则进行机器下线流程,若判断结果为否,则进行驱逐服务流程。
所述的机器下线流程包括:调用数据处理模块删除节点的方法,删除该机器所有的服务,并从邻接矩阵中移除该节点(进一步的,kubernetes会完成被驱逐服务的迁移重启的操作),从kubernetes中删除该机器节点(kubernetes会将机器从集群中移除)。
进一步地,还可邮件通知管理人员进行机器返修。
所述的驱逐服务流程包括:将ip和故障显卡卡号作为参数调用数据处理模块删除服务的方法,删除故障显卡上运行的服务。进一步的,kubernetes会完成被删除服务的迁移重启操作。
针对虚拟环境中显卡出现故障的场景,需要处理的流程包含新的服务不再使用故障显卡流程。参见图4所示,调度模块,用于对新创建的服务进行显卡分配,部署方式为单实例部署。
参见图7所示,本实施例调度模块的主要流程包括:
步骤s201,全局范围内启动单实例,与数据处理模块共享命名空间;
步骤s202、为新创建的服务启动显卡分配,包括:
步骤s2021,获取邻接矩阵,遍历gpu机器,过滤故障显卡,判断显卡资源是否充足,选择可用显卡;
步骤s2022,绑定阶段,在邻接矩阵中查找对应机器和显卡,更新服务列表。
其中,调度模块与数据处理模块共享命名空间。
所述显卡分配时可通过预选、排序(通过打分排序,优选top1),选择最终可用的显卡。预选包括可通过数据处理模块提供的查询方法,获取邻接矩阵,遍历所有gpu节点,判断显卡资源(数量和显存)是否充足,以及判断卡是否故障(对于有故障的显卡,在这一步会被过滤掉),从而实现新服务不会调度到故障显卡上的效果。
所述步骤s2022中将ip,显卡卡号和服务信息当作参数调用数据处理模块提供的添加方法,该方法会遍历邻接矩阵,找到对应的ip和显卡,并将该服务追加到此显卡的服务列表。
本实施例以基于k8s的虚拟环境进行了详细阐述,对于不是k8s的虚拟云环境,本方案思路同样可用。不过需要修改的地方是,config这种在特定命名空间下以文件记录显卡信息的方式,是k8s环境下的具体实现。对于其它虚拟化实现的方式,比如mesos,需要针对性的改造,比如实现自定义的scheduler模块,用外部存储而不是监控文件的方式记录显卡信息等;对于本实施例中的数据模块和驱逐者模块,在其它形式的虚拟化环境,其功能可能会被整合进调度者模块里,这取决于具体实现方式。
本实施例的config文件只是记录显卡故障检测的结果,用来和其它例如调度者、驱逐者模块共享显卡信息变动的载体。显卡本身的工作状态,是通过显卡驱动提供的,对于k8s来说,显卡状态信息,最合适的方式就是以config文件形式注册在特定命名空间里,可以方便的被其它模块感知到。邻接矩阵的方式,也是我们认为比较合适的用于存储显卡以及工作在其上的服务关联关系的数据结构。其它可能的形式的话,例如还可以放在通用kv存储里,通过key-list的形式存储,这样的话可以被整个集群感知到。
参见图4所示,本实施例同时提供虚拟云环境中显卡故障的处理装置,包括:
数据处理模块,用于存储所述虚拟云环境中的显卡资源信息,并在监听到表征显卡故障的变动事件时,根据变动事件的类型对存储的所述显卡资源信息进行数据同步处理,所述显卡资源信息包括集群节点、显卡和服务之间的拓扑结构及显卡状态信息;
后续处理模块,基于同步后的所述显卡资源信息,对虚拟云环境中的显卡故障进行后续处理,所述数据处理模块并同步更新所述显卡资源信息。
作为本实施例的可选实施方式,所述虚拟云环境为基于kubernetes的虚拟云环境,
所述数据存储模块,以邻接矩阵的方式存储了所述集群节点、显卡和服务拓扑结构及显卡状态信息;
可选地,所述处理装置还包括探针模块,用于获取各gpu机器的显卡故障信息,并在命名空间中创建配置文件来记录所述显卡故障信息。
可在每个gpu机器上循环判断每张显卡是否故障,若判断为故障,则探针模块在其命名空间创建/修改/删除包含节点ip和对应显卡故障的文件资源。
可选地,所述后续处理模块包括驱逐者模块,通过订阅所述命名空间表征显卡故障的变动事件,对故障显卡上已有服务进行删除,并同步服务变动信息到所述显卡资源信息;
可选地,所述后续处理模块包括调度模块,新创建的服务启动显卡分配时,获取所述邻接矩阵,遍历gpu机器,获取显卡资源,所述显卡资源已过滤掉故障显卡;判断所述显卡资源是否充足,选择可用显卡分配新创建的服务,并在所述邻接矩阵中查找该分配新创建的服务的显卡的对应机器和显卡号,更新服务列表。
作为本实施例的可选实施方式,所述数据处理模块通过和kubernetes系统的apiserver之间维持长连接,接收命名空间下的配置文件的变动事件;所述的数据处理模块全局范围内启动单实例,注册命名空间并监听该命名空间下显卡故障的变动事件;判断变动事件,并根据变动事件的类型对邻接矩阵进行数据同步处理;
所述探针模块启动daemonset,在每个gpu机器上启动对应的判断程序,循环判断每张显卡,调用驱动api接口判断显卡状态,若判断为健康,则返回至循环判断步骤,若判断为不健康,则在探针模块的命名空间创建/修改/删除包含节点ip和显卡的config文件资源;
所述的驱逐者模块全局范围内启动单实例,与数据处理模块共享命名空间,订阅命名空间下的config文件的变动事件,当接收到变动事件是新建事件或者修改事件时,判断本次新建事件或者修改事件的故障显卡数量是否超过设定值,若是,则遍历邻接矩阵,对应机器所有显卡对应服务列表,删除,若否,则在邻接矩阵中找到显卡对应服务列表,删除;
所述调度模块全局范围内启动单实例,新创建的服务启动显卡分配,获取邻接矩阵,遍历gpu机器,过滤故障显卡,判断显卡资源是否充足,选择可用显卡,绑定阶段,在邻接矩阵中查找对应机器和显卡,更新服务列表。
本实施例的一种电子设备,包括处理器和存储器,所述存储器用于存储计算机可执行程序,当所述计算机程序被所述处理器执行时,所述处理器执行上述实施例中所述的任一项虚拟云环境中显卡故障的处理方法。
本实施例的一种计算机可读介质,存储有计算机可执行程序,所述计算机可执行程序被执行时,实现上述实施例中所述的任一项所述的虚拟云环境中显卡故障的处理方法。
以上实施例仅用以说明本发明而并非限制本发明所描述的技术方案,尽管本说明书参照上述的各个实施例对本发明已进行了详细的说明,但本发明不局限于上述具体实施方式,因此任何对本发明进行修改或等同替换;而一切不脱离发明的精神和范围的技术方案及其改进,其均涵盖在本发明的权利要求范围当中。
- 还没有人留言评论。精彩留言会获得点赞!