一种基于大数据迁移学习的动力电池预测方法与流程
1.本发明属于动力电池属性计算、管理技术领域,具体涉及一种基于大数据迁移学习的动力电池预测方法。
背景技术:
2.新能源汽车的动力电池在运行过程中会产生大量的监控数据,使用这些数据可以建立机器学习预测模型,对动力电池的各种属性进行预测。例如使用动力电池的历史监控数据预测动力电池将来一段时间的最高温度,并根据温度的高低改变车辆的控制策略,可以将温度控制在安全范围内,降低动力电池发生热失控的风险。
3.使用监控数据建立机器学习尤其是深度学习预测模型的过程,包括准备大量数据集、创建模型结构、使用数据集训练模型、根据训练结果进一步调参,不断重复训练、调参过程直至最终得到令人满意的预测效果。
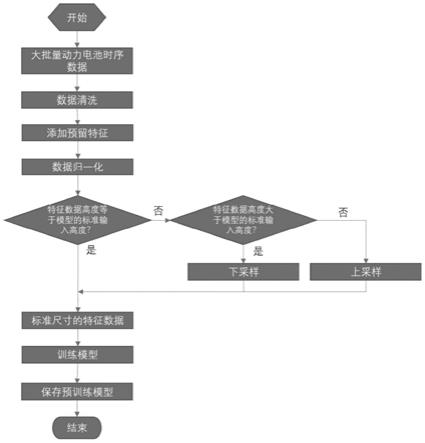
4.如附图1所示,常规模型开发流程为:1)动力电池时序数据这里使用的时序数据是从一大段完整动力电池数据中,采用滑动窗口法截取的时序片段,通常截取1小时的片段数据,如数据采样频率比较高,则可以使用较短的片段数据,但为了保证预测效果,数据长度不应该低于30分钟。
5.2)数据清洗数据清洗的目的是清洗数据中的缺失值或异常数值:缺失值:对于轻微数据缺失(比如95个电压值中有少数几个电压值缺失)则使用均值、中位值或邻近值进行填充,对于严重数据缺失(比如95个电压值大部分缺失)则直接删除本条数据;异常值:使用统计判断或领域知识判断数据是否在正常范围内,对于非正常范围内的数据做替换处理,具体处理方式与缺失值填充类似,使用均值、中位值或邻近值替换。
6.3)数据归一化为消除不同特征间的量纲差异,使用min
‑
max归一化方法对数据做归一化处理。
7.4)数据尺寸标准化为了便于cnn方法处理数据,对数据尺寸做标准化处理,但因为动力电池数据相邻特征间不存在时间和空间上的邻域关系,还因为数据宽度方向上本来就已经保持了统一的尺寸,故而无需对数据在宽度方向进行缩放处理。在高度方向上,因为数据存在时间上的邻域关系,所以可以在数据高度方向上进行缩放,以使得不同的输入数据保持统一的标准尺寸。
8.5)训练模型使用大批量数据长时间重复训练模型,并在训练过程中检测模型在验证集上的预测效果,当模型收敛后保存得到训练好的模型。
9.新能源汽车是个快速发展的行业,新产品推出速度快,行蓬勃发展给创建机器学
习模型带来了很多机遇,同时也带来了很多挑战,表现为产品类型多、监控数据格式不统一(例如不同车型中单体电压数量可能不同)、新产品数据积累少等等,这都增加了模型开发的难度,如按照常规的模型开发模式,不得不花费大量人力针对不同的产品类型、数据格式分别训练出大量不同的模型,费时费力的同时还无法保证模型的预测效果。
技术实现要素:
10.本发明的目的是提供一种能够降低模型开发难度,提高模型开发效率的基于大数据迁移学习的动力电池预测方法。
11.为达到上述目的,本发明采用的技术方案是:一种基于大数据迁移学习的动力电池预测方法,该方法为:预先基于动力电池的大数据建立并训练用于预测动力电池的带有若干项预留特征的迁移学习预训练模型;当需要对新类型动力电池进行预测时,利用所述新类型动力电池的部分时序数据微调训练所述迁移学习预训练模型,将所述新类型动力电池的部分时序数据中的部分特征对应应用到所述预留特征中,得到适用于所述新类型动力电池的新预测模型;在对属于所述新类型动力电池的待预测的动力电池进行预测时,利用所述新预测模型对所述待预测的动力电池进行预测并得到预测结果。
12.所述迁移学习预训练模型中的所述预留特征默认值为0。
13.所述迁移学习预训练模型使用卷积神经网络结构或循环神经网络结构。
14.当所述迁移学习预训练模型使用卷积神经网络结构时,所述迁移学习预训练模型采用vgg系列、googlenet系列、resnet系列或densenet系列模型。
15.当所述迁移学习预训练模型使用循环神经网络结构时,所述迁移学习预训练模型采用lstm或gru模型。
16.所述迁移学习预训练模型为回归模型或分类模型。
17.由于上述技术方案运用,本发明与现有技术相比具有下列优点:本发明能够加快模型开发速度、解决新动力电池产品数据偏少时的模型开发问题,解决了不同动力电池产品数据特征不统一的问题,能够降低模型开发难度,提高模型开发效率。
附图说明
18.附图1为现有的常规模型开发流程图。
19.附图2为本发明的基于大数据迁移学习的动力电池预测方法中迁移学习预训练模型开发流程图。
20.附图3为本发明的基于大数据迁移学习的动力电池预测方法中新预测模型开发流程图。
具体实施方式
21.下面结合附图所示的实施例对本发明作进一步描述。
22.实施例一:一种基于大数据迁移学习的动力电池预测方法,该方法为:预先基于动力电池的大数据建立并训练用于预测动力电池的带有若干项预留特征的迁移学习预训练
模型;当需要对新类型动力电池进行预测时,利用新类型动力电池的部分时序数据微调训练迁移学习预训练模型,将新类型动力电池的部分时序数据中的部分特征对应应用到预留特征中,得到适用于新类型动力电池的新预测模型;在对属于所述新类型动力电池的待预测的动力电池进行预测时,利用新预测模型对待预测的动力电池进行预测并得到预测结果。简而言之,本申请的基于大数据迁移学习的动力电池预测方法包括两部分,分别为创建迁移学习预训练模型和使用迁移学习预训练模型创建新预测模型。
23.1、迁移学习预训练模型的开发流程1)开发流程迁移学习预训练模型的开发过程,与常规模型开发流程基本相同,如附图2所示,不同之处在于确定模型的输入特征时,添加了若干项预留特征。因为新能源汽车企业众多且每家企业又有很多的车型,尽管有国标格式的规范,因为众多车型配置得不同,动力电池数据在特征上难免存在较大差异。为了应对这一问题,本方案通过增加预留特征的方法,使用足够充分的特征数量来保证数据特征上的一致性。比如,动力电池单体电池的特征数量通常在100个左右,可以增加预留特征使单体电池特征总数达到120个,迁移学习预训练模型中的预留特征默认值为0。
24.预留特征主要包括3种类型:单体电池预留特征、电池包温度预留特征、其它特征预留特征。
25.2)模型网络结构迁移学习预训练模型使用卷积神经网络(cnn)结构或循环神经网络(rnn)结构。当迁移学习预训练模型使用卷积神经网络结构时,迁移学习预训练模型采用vgg系列、googlenet系列、resnet系列或densenet系列模型。当迁移学习预训练模型使用循环神经网络结构时,迁移学习预训练模型采用lstm或gru模型。
26.相比之下,cnn方法模型在微调训练时的灵活度会更高些,故本实施例中迁移学习预训练模型使用标准的卷积神经网络结构,比如vgg系列、googlenet系列、resnet系列、densenet系列等,得到各种不同的网络结构的迁移学习预训练模型,以满足不同业务场景在预测精度、速度等方面的要求。
27.因为标准卷积神经网络是针对视觉领域创建的,为了可以在动力电池数据上使用,需要对标准卷积神经网络结构进行调整,主要包括:a)将第一层卷积核输入通道数in_channels由3改为1;b)修改fc层输出数量:如果是回归模型则将输出维度改成目标维度值并去掉softmax层;如果是分类模型,则将fc输出维度改成分类的类别数量,同时保留softmax层。
28.3)预训练模型的类型迁移学习预训练模型选择可以反映整体状况的属性做回归模型或分类模型(比如用最高温度做回归模型或者使用过压报警做分类模型),使用大数据集充分训练、调参、再训练,使得模型可以从大数据集中学习到有效的数据模式,最后保存训练好的模型作为迁移学习预训练模型。
29.2、基于迁移学习预训练模型的新预测模型开发流程当有新类型动力电池产品,即新类型的待预测动力电池需求时,根据对运算速度、预测精度的要求选择合适的预训练模型,再根据预测数据维度修改模型输出的数量,然后
使用微调的方式训练便可以快速获得适用于新类型动力电池的新预测模型。
30.基于迁移学习的新模型开发流程与常规模型开发流程在整体上大体类似,如附图3所示,但却又有根本上的差异,不同之处包括:1)小批量时序数据迁移学习借助于预训练模型中的通用有效模式,使用小批量数据微调训练就可以获得常规模型开发方法中大批量数据才能达到的效果,降低了模型开发对数据量的要求。
31.2)特征对齐使用预训练模型时,要根据预训练模型的特征(包含预留特征)排列新模型数据的特征顺序:电压对齐:将新模型数据电压特征填充到预训练模型的电压特征位置,没有使用到的位置使用默认值0;温度对齐:同电压对齐,将新模度数据温度特征填充到预训练模型的温度特征位置,没有使用到的位置使用默认值0;其它特征的对齐:将其它特征按照预训练模型中对应特征位置填充,如果有使用不到的预训练特征,则填充默认值0,如果有多出预训练模型中不存在的特征,则填充到预留其它特征位置,没有使用到的其它预留特征同样使用默认值0填充。
32.3)微调预训练模型迁移学习与常规模型在训练上完全不同,不需要大量数据的长时间训练,只需要使用新类型动力电池的小批量数据对预训练模型微调,就可以快速得到达到期望预测效果的新预测模型。
33.本方案使用深度学习中的迁移学习思路,使用预留属性的方式解决数据格式不统一问题,在大数据集上训练模型以学习到数据中的通用表达模式,进而将这种通用模式使用少量数据微调迁移到其它产品上使用,解决了产品类型多、数据量不足导致的模型开发问题。本方案重点改进在于下面3个方面:1)解决了新产品数据量偏少时的模块开发问题开发新产品模型时,往往会存在数据积累不足导致的数据量偏少问题,导致模型无法从少量数据中学习到有效的表达模式,使模型效果无法达到所期望的预测性能。而本专利使用迁移学习方式,将预训练模型中从大量数据集中学习到的有效数据模式直接迁移过来使用,减少了开发新产品模型时对数据量的要求。
34.2)解决了不同产品数据的特征不统一问题使用预留特征,解决了不同产品的动力电池数据特征差异问题,不同动力电池数据可以统一到同一个模型,增加了模型的通用性,减少了模型开发的规模。
35.3)加快模型开发速度使用大数据集预训练模型,从中学习到动力电池数据中通用的有效模式,当开发新产品模型时,只需要通过微调训练的方式,就可以使用预训练模型获得预测性能达到期望的模型,而不需要一切都从零开始,既加快了开发速度又保证了预测性能。
36.本方案的优势在于:常规的深度学习模型开发,需要使用大量数据、长时间训练以及大量调参,才可以获得预测能力满足需求的模型,这在实际操作中往往会存在很多技术复杂度、时间投入、数
据集上的种种限制。
37.电动汽车领域,新产品推出速度快,在数据集问题上就会表现为没有足够的数据积累,以至于只能使用较少的数据训练模型,无法获得预测性能足够好的模型。本专利采用迁移学习方法,发挥大数据优势,在大数据集上充分训练模型,使模型学习到动力电池数据中的有效模式,再将这些预训练模型用于各种新模型的开发,使得这些新模型可以迁移使用预训练模型中的有效模式,降低了开发难度,并且只需要较少的数据以及短时间的微调训练就可以获得所期望的模型效果。
38.不同车辆产品配置的多样性往往还意味着数据特征上的不同,使得不同产品的数据无法通用,以至于不得不为每一种产品单独开发模型,对模型开发和模型部署都造成了沉重的负担。本专利通过预留特征的方式,为不同车型提供了统一的数据格式,这些预留特征在没有使用时,对应权重近乎于0,从而不发挥作用。一旦需要用到这些预留特征时,只需要通过微调训练新模型,便可以快速更新预留特征对应的权重,使这些预留特征发挥作用,最终解决了不同车型特征不统一的问题。
39.上述实施例只为说明本发明的技术构思及特点,其目的在于让熟悉此项技术的人士能够了解本发明的内容并据以实施,并不能以此限制本发明的保护范围。凡根据本发明精神实质所作的等效变化或修饰,都应涵盖在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1