一种基于领域知识图谱的水务数据智能发现方法
1.本发明属于知识图谱构建及应用领域,涉及一种基于领域知识图谱的水务数据智能发现方法。
背景技术:
2.随着水利信息的发展,通过先进的采集设备和技术,我们采集到了大量的水环境实时数据。同时,网络上由用户产生的数据以及一些开放链接数据都在不断产生。但是,专业人员和用户想要获取自己需要的数据时,通过关键词的搜索并不能得到想要的结果。知识图谱是一种大规模的语义网络。2012年谷歌提出知识图谱的概念是为了提高其搜索质量。对于现在知识图谱的构建,已经出现了许多通用知识图谱和领域知识图谱,典型的有百度的“知心”、搜狗的“知立方”、scikg、likedmdb等。领域知识图谱的深度还有待进一步深入。对于知识图谱相关的应用,2016年李威蓉等人构建了地理空间数据来源本体来提高地理空间数据的检索质量。2015年冯钧等以《水利公文主题词表》构建的本体为基础对水利信息进行检索。但是,该研究中构建的知识库信息缺乏,并不能很好的涵盖这个领域,进而达到很好的检索效果。
技术实现要素:
3.有鉴于上述现有的不足,本发明的目的在于提供一种基于领域知识图谱的水务数据智能发现方法构建方法。本方法首先构建水务知识图谱,然后利用知识图谱对领域数据做标注,最后基于知识图谱对用户输入的关键词进行解析进而得到排序后的数据,提高了数据的发现质量。
4.为了解决上述问题,本发明采用如下的技术方案:一种基于领域知识图谱的水务数据智能发现方法包括一下步骤:
5.步骤1:利用现有百科非结构化数据,数据库中的结构化数据和文本中的结构化数据构建知识图谱。
6.步骤2:采集水务相关数据,并利用知识图谱对数据做标注。
7.步骤3:对数据进行检索。首先对用户数据的关键词进行识别,然后利用jena解析知识图谱发现其关联信息进而得到用户想要的数据,最后对数据进行排序。
8.进一步的,本发明步骤1所述的构建知识图谱的方法,其步骤具体包括:
9.步骤1
‑
1:利用tfidf算法从专业文献中抽取领域的重要术语,基于这些术语利用参照法(标杆对照、业务适配、增补裁剪)梳理出水务知识图谱的实体类型。
10.步骤1
‑
2:利用参照法梳理出水务知识图谱的实体关系类型。
11.步骤1
‑
3:利用现有的数据库中的结构化数据库中的数据填充知识图谱的实例信息。如果出现新的实体类型,则返回步骤1,添加新的实体类型。
12.步骤1
‑
4:抽取现有知识库cn
‑
dbpedia中的实体信息来丰富水务知识图谱中的属性信息。
13.步骤1
‑
5:利用深度学习的方法来抽取水务实体之间的关系,丰富知识图谱的关系类型。如果有出现新的实体关系类型,则回到步骤2,添加新的实体关系类型。
14.进一步的,本发明步骤2所述的数据标注方法,其步骤具体包括:
15.步骤2
‑
1:在网上或者专业数据库中收集水务领域的数据集,记录它的元数据。同时,要分析这些数据集的特征,时间特征、空间特征和来源特征等。
16.步骤2
‑
2:利用构建的水务知识图谱中的概念或者实例去标注步骤2
‑
1中收集的水务数据的特征。
17.进一步的,本发明步骤3所述的数据检索方法,其步骤具体包括:
18.步骤3
‑
1:首先对检索条件进行预处理,首先对查询关键词进行分词得到语义项,然后利用同义词典映射的方法将这些语义项映射到知识图谱的该概念或者实体。
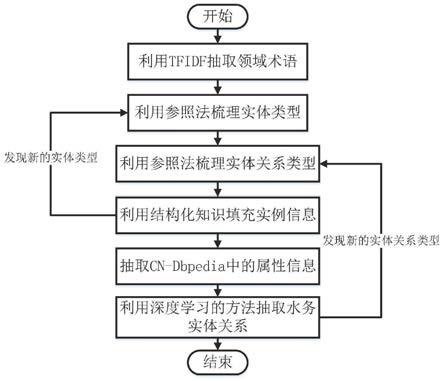
19.步骤3
‑
2:利用jena自带的推理规则和自定义的推理规则推理出水务知识图谱中原来没有的三元组信息。
20.步骤3
‑
3:利用jena解析知识图谱,查找与被检索语义项相关联的实体信息,进而查找到相关数据集。
21.步骤3
‑
4:利用定义好的排序规则,对检索出的数据集进行排序。这里的排序规则指的是:数据集的权重是由与数据集相关联的语义项的权重决定的。这些权重由人为经验决定,比如:定义“相同”实体关系类型的权重为1,“包含”的权重0.8,“相离”的权重为0.7。数据集按权重从高到低排序。
22.步骤3
‑
5:评估检索的效果。
23.进一步的步骤3
‑
5的评测指标:使用信息检索常用的三项指标:查准率p、查全率r、以及综合评价指标f来评价数据发现的效果。计算公式分别如下:
24.查全率:
25.查准率:
26.综合评价指标:
27.其中tp指的是查询到的相关数据总数,fp指的是系统中相关数据总数,fn指的是系统返回的数据总数。
28.本发明是一种基于领域知识图谱的水务数据智能发现方法。
29.有益效果:
30.1.在知识图谱构建阶段,本发明面对没有领域专家的情况,能够在短时间内总结出知识图谱的框架,即知识图谱的实体关系类型和知识图谱的实体关系类型,为下一步打下了坚实的基础。
31.2.在知识图谱构建的实体关系抽取阶段,本发明可以在知识图谱的对象缺乏关系时,从文本中提取水务实体和实体之间的关系,从而为下一步利用知识图谱对领域数据检索打下了坚实的基础。
32.3.利用领域知识图谱提高了水务数据检索的质量,可以帮助专业技术人员更好地发现自己想要的数据。
附图说明
33.图1为本发明水务知识图谱的构建流程图。
34.图2为水务知识图谱的部分实体类型。
35.图3为水务知识图谱的部分实体关系类型。
36.图4水务语义类型图。
37.图5水务关系类型。
38.图6数据发现流程图。
39.图7基于知识图谱的水务数据发现流程图。
具体实施方式
40.本发明提供了一种基于领域知识图谱的水务数据智能发现方法,为使本发明的目的、技术方案及效果更加清楚、明确,以下对本发明进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
41.请参阅图1。图1为本发明中构建水务知识图谱的流程图,图中首先用参照法构建了知识图谱的实体类型和关系类型。这里参照的对对象就是umls。umls的实体关系类型如图2所示。它的关系类型如图3所示。统一医学语言系统(unified medical language system,umls)是美国国立医学图书馆持续开发了20多年的巨型医学术语系统,涵盖了临床、基础、药学、生物学、医学管理等医学及与医学相关学科,收录了约200万个医学概念,医学词汇更是空前,达到了500多万个。
42.umls规定了语义的类型分为两个大类,实体和事件。实体分为概念实体和物理实体。事件分为现象或过程和活动。语义类型分为相关关系和功能上的关系。我们在构建水务知识图谱的时候可以参照umls的结构来对水务的实体和关系类型进行划分,没有的进行添加,多余的进行裁剪。最终构建出的知识图谱的部分结构如图4和图5所示。
43.请参照图6,为水务数据的发现流程图。首先对用户要搜索的关键字进行预处理,这里的预处理包括分词、同义词典的映射等。然后利用推理过后的水务知识图谱对资源进行检索,最后利用排序算法对数据进行排序。
44.图7为基于知识图谱的水务数据发现流程图。
45.应当理解的是,本发明的应用不限于上述的举例,对本领域普通技术人员来说,可以根据上述说明加以改进或变换,所有这些改进和变换都应属于本发明所附权利要求的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1