一种基于编程上下文信息的代码重构方法
本发明涉及代码重构方法,尤其涉及一种基于编程上下文信息的代码重构方法。
背景技术:
针对标识符重构,主要体现在以下两个方面,一是基于命名约定的重命名,二是基于不一致性的重命名。
基于命名约定的重命名:命名约定是程序员用来指导他们命名软件实体的一套规则,尤其是形成标识符的规则(包括单词的选择,也包括“语法”规则)。根据统一的命名惯例命名软件实体提高了软件应用程序的可读性和可维护性。命名惯例是与上下文相关的。不同的编程语言和组织定义了自己的命名约定。例如,java语言建议按照camelcase约定命名实体,而c程序员通常使用下划线作为分隔符来连接单词。
基于命名约定寻找重命名机会不同于命名约定本身的选择或质量。暗示问题的不是命名惯例本身,而是它的违反。理论上,基于命名约定的重命名必须首先找到软件采用的上下文约定,其次识别违反重命名机会等约定的标识符。
基于不一致性的重命名:检查软件中不一致的标识符是识别重命名机会的另一项关键技术。标识符传达对程序理解有用的领域概念。它们捕捉程序员在编写代码时所拥有的特定于应用程序的知识。适当的标识符不仅应该简明地反映其实体的作用,而且应该在整个程序中一致地表示概念。然而,大多数程序都存在标识符不一致的问题。
基于不一致性的重命名现有方法基于标识符之间的不一致性以及实体名称和实体实现之间的不一致性来识别重命名机会。此外,标识符之间的不一致性分为基于同义词的方法、基于克隆的方法和基于相似性的方法。
现有的研究工作把主要精力放在了重命名机会的识别上,却忽略了确定哪一部分标识符是需要被重命名之后的操作,即标识符重命名的来源是什么,以及采用何种方式将更好的标识符推荐给开发者,这一部分与重命名机会的识别同样重要,甚至决定了与开发者的交互程度以及开发者对于推荐的新标识符的接受程度,影响了标识符重构的有效性和意义。
现阶段,尚未有研究系统性地总结标识符重构的有效推荐来源是什么以及有效的推荐方式是什么。针对这一部分的研究目前比较匮乏,迫切需要进一步展开更加深入的研究。
技术实现要素:
发明目的:本发明的目的是提供一种个性化构建新的重构标识符、提高软件质量的基于编程上下文信息的代码。
技术方案:一种基于编程上下文信息的代码重构方法,根据编程项目的上下文信息,对编程项目的需求文档、设计文档、缺陷报告和代码结构进行分析,包括步骤如下:
(1)将代码上下文、注释、需求文档和设计文档进行切分序列化,形成文本向量;
(2)通过机器学习方法,将文本向量转换为数值向量,并进行数值向量的嵌入,形成向量空间;
(3)对于形成的多个向量空间,选用聚类方法将向量空间进行聚类,将最后形成的相同编程上下文模型归类到一起;
(4)对于给定的标识符通过编程上下文模型,形成重构备选排序列表,推荐给开发者。
进一步,所述步骤(1)中,在进行切分序列化之前,首先将代码上下文转化为抽象语法树;所述代码上下文、注释、需求文档和设计文档均要先被标记为文本向量;所有的代码上下文都通过抽象语法树来解析,并通过深度优先搜索算法来遍历生成的抽象语法树,以获得两种标记:一种是节点类型,另一种是该节点的标识符;为下一步的向量嵌入做准备。
进一步,所述步骤(2)中,将切分序列化中生成的文本向量转化为数值向量,并进行向量嵌入,形成向量空间,包括步骤如下:
步骤21,描述性文本嵌入
通过步骤(1)的文本向量模式,提供文本标记序列:
nvname←epv(tn)
其中,epv是段落向量嵌入函数,将序列标记的训练集tn作为输入;输出是名称映射函数nvname:tn→vn,其中vn是嵌入的向量空间;
步骤22,代码上下文嵌入
选用两层神经网络,模型构建如下:
tvb←ew(tb)
其中,ew是以标记序列tb的训练集为输入的标记嵌入函数;输出是一个标记映射函数tvb:twb→vbw,其中twb是标记的词汇表,vbw是在twb中嵌入记号的向量空间;
在序列嵌入之后,代码上下文最终被表示为二维向量;设定给定的代码上下文b由tb=(t1,t2,t3...tk)标记序列表示,其中ti∈twb,i=1,2,3,....,k;vb是对应于tb的二维数值向量,则vb推断如下:
vb←∫(tb,tvb)
其中,∫是基于标记映射函数tvb将代码上下文的标记序列转化为二维向量的函数,因此vb=(v1,v2,v3...vk)∈vb;其中vi←tvb(ti),vb是一组二维向量;
步骤23,生成向量空间
对于代码上下文,输入是步骤(22)中生成的二维向量,输出是对应一个整体的向量空间,则映射函数通过以下公式获得:
vvbody←ebv(vb)
其中,ebv是一个嵌入函数,将代码上下文vb的二维向量作为训练数据,并产生一个映射函数vvbody,其定义如下:
vvbody:vb→vb′
其中,vb′是代码上下文的嵌入向量空间。
进一步,所述步骤(3)中,通过k均值聚类将步骤(2)生成的向量空间划分成不同的子集,划分聚类将数据对象划分成不重叠的子集,使得每个数据对象恰在一个子集中;采用k均值发现用户指定个数k的簇,将生成的向量空间看成是高维空间内的点,完成聚类的任务;k均值聚类操作如下:
首先,选择k个初始质心,其中k是用户指定的参数;每个点指派到最近的质心,而指派到一个质心的点集为一个簇;
然后,根据指派的簇的点,更新每个簇的质心;重复指派和更新步骤,直到簇不发生变化,或等价地直到质心不发生变化;
采用邻近性度量来量化数据,对于空间内的点使用欧几里得距离,将点指派到最近的质心;
对欧几里得距离的数据,采用误差的平方和sse作为度量聚类质量的目标函数:
其中,dist是欧几里得空间中两个对象之间的标准欧几里得距离;ci是第i个簇,k是簇的个数,x是对象。
进一步,所述步骤(4)中,对于需要重构的标识符,将其输入到聚类后的编程上下文模型中,获得分类输出,输出此标识符对应的编程上下文模型的分类簇标签,并识别出与此标识符相同编程上下文分类簇标签的所有标识符,再通过计算所有标识符之间的向量相似度,得到此标识符属于的上下文环境;同时还附有与此标识符上下文环境相似的其他上下文环境对应的标识符,将所述对应的标识符构成重构备选排序列表。
本发明与现有技术相比,其显著效果如下:1、利用代码编程上下文信息,构建编程上下文模型,更加有效、个性化地构建新的重构标识符,提高软件质量,避免程序缺陷与腐化,帮助开发人员去进行程序开发;2、将需要重构的标识符输入编程上下文模型,输出分类标签,作为隐藏的重构来源,向开发者更好地进行重命名推荐;3、提出了重命名推荐的概念,提供了一种基于编程上下文信息的代码重构方法。
附图说明
图1为本发明的总流程示意图;
图2为本发明代码片段的通用和精确的抽象语法树示意图。
具体实施方式
下面结合说明书附图和具体实施方式对本发明做进一步详细描述。
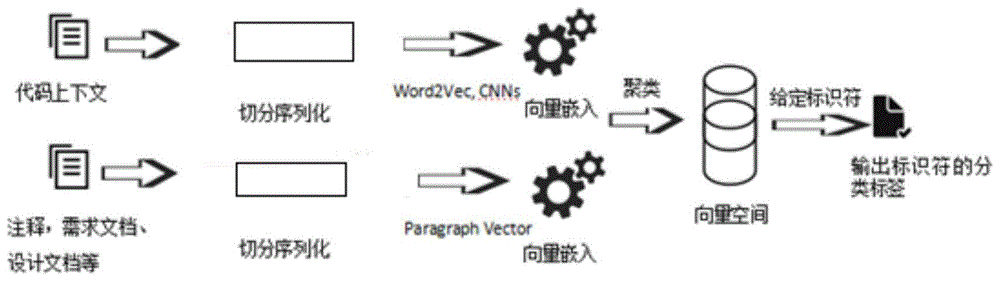
编程上下文数据是标识符进行校正的重要信息来源。现有的标识符所在的编程上下文数据,尚未被有效利用,主要包括三类,分别为编程人员信息、编程项目信息和编程环境信息,其中编程人员和编程项目又分为历史信息和现场信息。这些信息具有多样性、海量性、高速性和可变性等特点。针对这些特点,本发明研究上下文信息的结构、内涵和特征提取分类技术。在三类上下文信息中,编程项目的上下文信息种类繁多,是本发明重点分析的内容。针对编程项目上下文信息,对项目的需求文档、设计文档、缺陷报告和代码结构等制品进行分析,构建标识符与软件制品之间的关联关系,形成编程上下文模型。对于给定的标识符,能从编程上下文模型中找出与其编程上下文环境一致的标识符,并将与其编程上下文环境一致的标识符列为此标识符的重构来源,构建出更加符合语义以及更具个性化的重构来源列表,更好地给开发者进行重命名推荐,本发明的整个流程如图1所示。
本发明的实现包括步骤如下:
(1)切分序列化:将代码上下文(如果标识符是方法名,对于代码上下文则是该方法的方法体)、注释、需求文档和设计文档等进行切分序列化,形成文本向量。
(2)向量嵌入:通过机器学习方法,如paragraphvector和cnns(convolutionalneuralnetworks,卷积神经网络)等,将文本向量转换为数值向量,并进行数值向量的嵌入,形成向量空间。
(3)聚类输出:对于形成的多个向量空间,选用聚类方法(例如计算两个向量的相似度,即考察向量空间内两个向量之间的欧几里得距离)将这些向量空间进行聚类,即将最后形成的相同的编程上下文模型归类到一起。
(4)将标识符输入编程上下文模型中:对于给定的标识符,输入到编程上下文模型中,输出此标识符对应的编程上下文模型的分类簇标签,并识别出与此标识符相同编程上下文模型的所有标识符,再通过计算所有标识符之间的向量相似度,形成重构备选排序列表,推荐给开发者。
本发明的详细实现过程如下:
步骤一,切分序列化
在进行切分序列化之前,首先对于代码上下文进行预处理,即将代码上下文转化为抽象语法树(ast:abstractsyntaxtree)。在生成的传统抽象语法树中,叶节点中一些标记为simplename的标记会干扰代码片段的特征学习。例如,在图2treea中变量节点list被表示为(simplename,list),而方法节点toarray被表示为(simplename,toarray)。所以在通用抽象语法树的叶节点处,区分这两个节点可能就很有挑战性。为此,本发明将不用的节点细化为不同的节点类型,对语法书进行改进,将改进的语法树称作精确抽象语法树。
图2为一个返回语句的通用和精确的抽象语法树。首先,精确的语法树呈现了一个简化的架构。第二,与一般的语法树节点相比,用精确抽象语法树来区分一些不同的节点变得更容易。string[]类型的节点标记为(arraytype,string[]),变量节点list简化为(variable,list),toarray方法简化为(method,toarray),因此,用精确抽象语法树更容易区分两个节点,也降低了生成的文本向量相似性。
在本发明中,代码上下文、注释、需求文档和设计文档等都要先被标记为文本向量。所有的代码上下文都通过精确抽象语法树来解析,并通过深度优先搜索算法(dfs:depthfirstsearch)来遍历生成的精确抽象语法树,以获得两种标记:一种是ast节点类型,另一种是该节点的标识符。例如代码“doubleprofit”被标记为四个标记的文本向量(primitivetype,double,variable,profit),以此类推,就可以将所有的代码上下文转换为四个标记的文本向量。代码上下文可以很好的被精确抽象语法树解析来获取特征,而对于注释、需求文档和设计文档而言,在本发明的方法中,设计了如下的文本向量模式(objecttype,function,paratype,output),其中objecttype是指描述对象的类型,比如一句注释描述的是一个方法的功能,则此时objecttype即为methodtype,以此类推;function顾名思义是指所描述要完成的功能,比如文档上要求一处代码要完成两个数互换的操作,则此时function即为swop;paratype即为描述对象的参数类型,如一句话描述的是两个整型的加法,则此时paratype即为int;output即是描述对象的输出,如无输出,则为null。通过以上设计的文本向量模式,能很好地将注释、需求文档和设计文档等转化为文本向量。至此,所有的编程上下文都转化为了文本向量,完成了切分序列化的操作,为后面的向量嵌入做了准备。
步骤二,向量嵌入
将切分序列化中生成的文本向量转化为数值向量,并进行向量嵌入,形成向量空间。对于注释、需求文档和设计文档等描述性的语句,通过paragraphvector算法将它们嵌入到向量中。而对于代码上下文,首先通过word2vec技术将文本标记嵌入到向量中,然后这些嵌入向量被送到卷积神经网络中,从而将整个代码上下文嵌入到向量空间中。详细步骤如下:
步骤21,描述性文本嵌入
paragraphvector是一种无监督的算法,它能从可变长度的文本片段中学习固定长度的特征表示,例如句子和段落。因此,对于注释、需求文档和设计文档等描述性的语句能很好地继续向量嵌入。具体来说,通过步骤一中提出的新的文本向量模式,提供文本标记序列。
nvname←epv(tn)(1)
公式(1)中,epv是段落向量嵌入函数,将序列标记的训练集tn作为输入;输出是名称映射函数nvname:tn→vn,其中vn是嵌入的向量空间。paragraphvector算法能把整个文本序列嵌入到向量中。
步骤22,代码上下文嵌入
word2vec是一个两层神经网络,其主要功能是嵌入单词,将每个单词转化为数值向量。其模型构建如下:
tvb←ew(tb)(2)
公式(2)中,ew是以标记序列tb的训练集为输入的标记嵌入函数;输出是一个标记映射函数tvb:twb→vbw,其中twb是标记的词汇表,vbw是在twb中嵌入记号的向量空间。
在序列嵌入之后,代码上下文最终被表示为二维向量。设定给定的代码上下文b由tb=(t1,t2,t3...tk)标记序列表示;其中ti∈twb,i=1,2,3,....,k;vb是对应于tb的二维向量,那么vb推断如下:
vb←∫(tb,tvb)(3)
公式(3)中,∫是基于标记映射函数tvb将代码上下文的标记序列转化为二维向量的函数,因此vb=(v1,v2,v3...vk)∈vb;其中vi←tvb(ti),vb是一组二维向量。
步骤23,生成向量空间
描述性文本是单词的集合,paragraphvector算法能将不同长度的段落生成相同长度的数值向量,集合成空间,所以以代码上下文(如方法体)的向量空间生成为例。
对于代码上下文,需要另外的映射函数,其中输入是步骤22中生成的二维向量,输出是对应一个整体的向量空间。
该映射函数通过以下公式获得:
vvbody←ebv(vb)(4)
公式(4)中,ebv是一个嵌入函数(cnns),将代码上下文vb的二维向量作为训练数据,并产生一个映射函数vvbody,其定义如下:
vvbody:vb→vb′(5)
公式(5)中,vb′是代码上下文的嵌入向量空间。
至此,将切分序列化中生成的文本向量转化为了数值向量,并进行向量嵌入,形成了向量空间。
步骤三,聚类输出
聚类分析仅根据在数据中发现的描述对象及其关系的信息,将数据对象分组。其目标是,数据内的对象是相似的(相关的),而不同组中的对象是不同的(不相关的)。需要通过聚类技术将上述生成的向量空间划分成不同的子集(簇)。划分聚类可以将数据对象划分成不重叠的子集(簇),使得每个数据对象恰在一个子集中。k均值聚类是基于原型的、划分的聚类技术,试图发现用户指定个数(k)的簇。在本发明中,将生成的向量空间看成是高维空间内的点,然后采用k均值聚类来完成聚类的任务。下面具体介绍k均值聚类的相关操作。
首先,选择k个初始质心,其中k是用户指定的参数,即所期望的簇的个数。每个点指派到最近的质心,而指派到一个质心的点集为一个簇。然后,根据指派的簇的点,更新每个簇的质心。重复指派和更新步骤,直到簇不发生变化,或等价地直到质心不发生变化。
为了将点指派到最近的质心,需要邻近性度量来量化所考虑的数据的“最近”概念,对于空间内的点使用欧几里得距离。
因为质心可能随数据邻近性度量和聚类目标不同而改变。聚类的目标通常用一个目标函数表示,该目标函数依赖于点之间,或点到簇的质心的邻近性,考虑邻近性度量为欧几里得距离的数据,采用误差的平方和sse作为度量聚类质量的目标函数:
公式(6)中,dist是欧几里得空间中两个对象之间的标准欧几里得距离,ci是第i个簇,k是簇的个数,x是对象。
步骤四,将标识符输入编程上下文模型中
通过计算向量之间的相似度,将生成的向量空间聚类之后,就形成了多个不相似向量子空间,不同的子空间对应相似的上下文环境。对于需要重构的标识符,将其输入到聚类后的编程上下文模型中,获得分类输出,得到的不仅仅是此标识符属于的上下文环境;同时还附有与此标识符上下文环境相似的其他上下文环境对应的标识符,将对应的标识符构成重构备选排序表。
计算向量相似度的方法还可以计算两个向量之间的相似度,计算重构备选的标识符与需要重构标识符之间的相似度,形成重构排序列表,推荐给开发者。如此可以更好地提供给开发者更具个性化、更符合标识符的语义以及所处环境的标识符重命名。
- 还没有人留言评论。精彩留言会获得点赞!