业务流程剩余时间预测方法、系统、存储介质及计算设备
本发明涉及业务流程管理的
技术领域:
,尤其是指一种基于过程挖掘的业务流程剩余时间预测方法、系统、存储介质及计算设备。
背景技术:
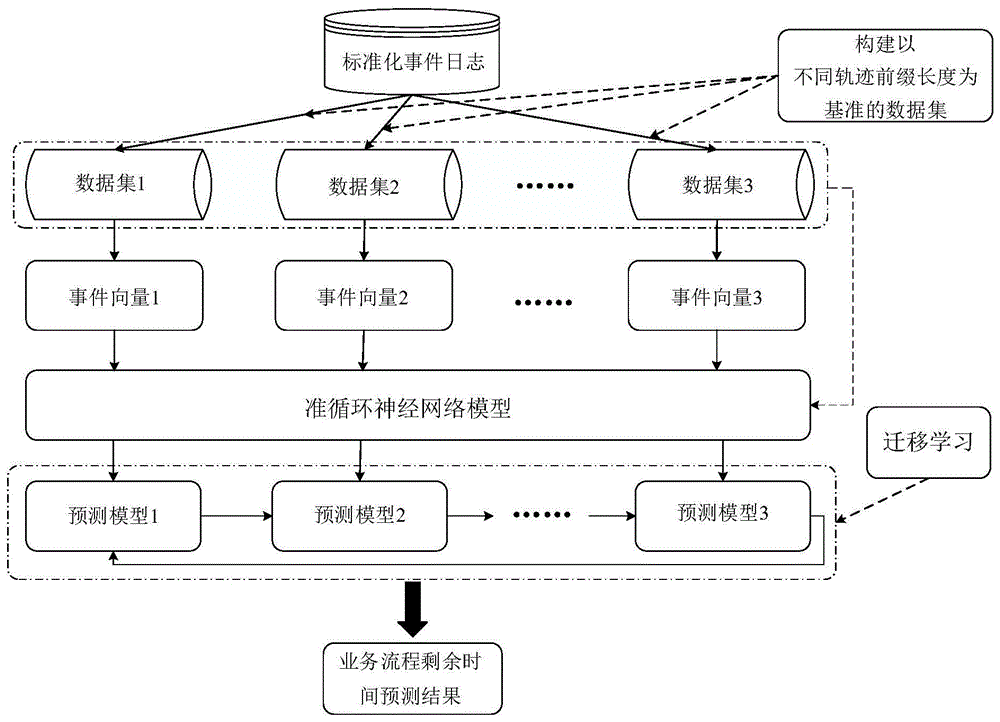
:近年来,预测型流程监控成为了业务流程管理领域中重要的研究方向,其主要是对正在执行的业务流程实例进行预测型分析,进一步准确预测出当前实例在未来的一段时间内可能出现的执行状态,例如某个实例的演变、下一个将要执行的活动、实例剩余时间等。业务流程剩余时间预测是预测型流程监控一项主要的预测任务,其主要目标是对正在执行的业务流程实例剩余的执行时间进行预测。随着机器学习技术和深度学习技术的广泛使用,研究者将机器学习技术和深度学习技术应用到剩余时间预测任务之中,并取得了较好的预测效果,特别是基于长短期记忆网络(longshort-termmemory,lstm),其在剩余时间预测任务上的准确度超过了机器学习方法和流程模型方法。目前,在现有的研究中,基本上都是通过使用传统lstm以及gru循环神经网络训练剩余时间预测模型,虽然lstm和gru可以较好地解决序列问题,但是该模型在处理大规模的序列数据时存在着训练速度缓慢的问题,因此如何在提升流程实例剩余时间预测效果的同时,提高流程实例剩余时间预测模型训练的速度,是一项亟需解决的问题。技术实现要素:本发明的第一目的在于克服现有技术的缺点与不足,提供了一种基于过程挖掘的业务流程剩余时间预测方法,可实现对业务流程剩余时间进行精准预测,取得了准确的剩余时间,为后续业务流程优化奠定基础。本发明的第二目的在于提供一种业务流程剩余时间预测系统。本发明的第三目的在于提供一种存储介质。本发明的第四目的在于提供一种计算设备。本发明的第一目的通过下述技术方案实现:业务流程剩余时间预测方法,包括以下步骤:1)获取标准化事件日志,该标准化事件日志中记载了相关的业务流程,包含事件和事件时间戳;2)根据步骤1)中获得的标准化事件日志构建以不同轨迹前缀长度为基准的数据集,并将数据集划分为训练集和测试集;3)将步骤2)中获得的训练集输入到准循环神经网络模型中,进行迭代训练,并对网络模型参数进行调整,在达到设定迭代次数后,获得最终的网络模型参数文件;4)将步骤3)获得的最终的网络模型参数文件加载到准循环神经网络模型中,通过基于word2vec的cbow模型和迁移学习来提升业务流程剩余时间的预测效果,并获得最优的准循环神经网络模型,最终将测试集输入到最优的准循环神经网络模型中进行验证,获得准确的业务流程剩余时间预测结果。在步骤1)中,将事件日志中多余的属性删除,只保留事件和事件的时间戳,从而构成标准化事件日志;所有事件日志均通过4tu平台来获取。在步骤2)中,根据步骤1)获得的标准化事件日志构建以不同轨迹前缀长度为基准的数据集,其具体步骤如下:2.1)在标准化事件日志中,对轨迹前缀长度的范围进行设定;2.2)遍历标准化事件日志中的每一条轨迹,并在步骤2.1)设定好的范围内进行截取,得到长度不同的轨迹前缀及其对应的业务流程剩余时间;2.3)将步骤2.2)得到的所有长度不同轨迹前缀及其对应的业务流程剩余时间作为数据集,并以70%比例当作训练集,余下的30%当作测试集。在步骤3)中,所述准循环神经网络模型由卷积层和池化层组成,将训练集输入到准循环神经网络模型之后,首先会经过一层卷积层,该卷积层利用数量为m的滤波器对训练集进行卷积运算,目的在于提取输入训练集的特征信息,并得到输出序列x(x1,x2,……,xn),其中xn代表第n个输出序列;然后,输出序列x(x1,x2,……,xn)会再经过一层池化层,池化层作用就是减少卷积层的输出序列x(x1,x2,……,xn)特征数目,得到新的输出序列z(z1,z2,……,zn),其中zn代表第n个新的输出序列,而该输出序列z(z1,z2,……,zn)就是业务流程以不同轨迹前缀长度为基准的剩余时间预测结果;其中,预测结果包含预测的业务流程剩余时间和平均绝对误差;最后,根据得到的平均绝对误差结果对网络模型参数进行调整,并再次进行迭代训练,在完成设定的迭代次数后,获得最终的网络模型参数文件。所述步骤4)包括以下步骤:4.1)对数据集中的事件时间戳进行离散化处理,离散化后事件e的执行时间为:式中,t(e)代表事件e的连续执行时间,tmax(starttime-endtime)(e,a)和tmin(starttime-endtime)(e,a)代表活动a在事件日志中出现的最长与最短执行时间,n的是离散化后事件e执行时间所划分数量;4.2)将全部活动a与步骤4.1)离散化后的执行时间进行拼接,得到事件向量其中t代表活动a的执行时间,代表m阶矩阵;4.3)根据步骤4.2)得到的事件向量θ<a,t>,利用基于word2vec的cbow模型对事件向量θ<a,t>进行预训练,具体步骤如下:4.3.1)事件向量θ<a,t>与基于word2vec的cbow模型中输入层的权重矩阵w{1,2,3,……,m}进行点乘运算,得到矩阵向量v{1,2,3,……,k},其中权重矩阵中的m、k代表是第m个和第k个权重矩阵;4.3.2)将步骤4.3.1)中得到的矩阵向量v{1,2,3,……,k}进行加权求平均操作,并得到矩阵向量p;4.3.3)将步骤4.3.2)中得到的矩阵向量p与基于word2vec的cbow模型中输出层的权重矩阵z进行点乘运算,并经过softmax归一化后,得到预训练事件向量结果q;4.3.4)根据步骤4.3.3)得到的事件向量q,将其输入到已加载网络模型参数文件的准循环神经网络模型中进行迭代训练,再将迭代后的网络模型以迁移学习的方式进行训练,得到最优的准循环神经网络模型;4.3.5)将测试集输入到步骤4.3.4)得到的最优的准循环神经网络模型中进行验证,从而获得准确的业务流程剩余时间预测结果;其中,上述word2vec是一个用来产生词向量的方法,而cbow模型是word2vec中一种常用的模型,该模型主要是将事件向量中同一轨迹且经常出现的事件进行相似性向量表示,并通过上下文事件来预测当前事件;上述迁移学习则是将训练好的模型参数迁移到新的模型中来,进一步帮助新模型进行训练,而利用迁移学习的主要目的在于:由于构建的以不同轨迹前缀长度为基准的数据集中,短轨迹前缀的数量要多于长轨迹的数量,倘若不对轨迹前缀进行区分,并输入到准循环神经网络模型中进行训练会造成业务流程剩余时间预测不准确的情况,因此,需要先对数量多的短轨迹前缀进行训练,然后利用迁移学习,将短轨迹前缀训练好的网络模型参数作为长轨迹前缀训练的初始值,从而达到提升业务流程剩余时间预测结果的目的。本发明的第二目的通过下述技术方案实现:基于过程挖掘的业务流程剩余时间预测系统,包括:数据预处理模块,用于将事件日志中多余的属性删除,只保留事件和事件的时间戳,从而构成标准化事件日志,该标准化事件日志记载了相关的业务流程;数据生成模块,用于将数据预处理模块获得的标准化事件日志构建以不同轨迹前缀长度为基准的数据集,并将数据集划分为训练集和测试集;获取网络参数模块,用于将数据生成模块中获得的训练集输入到准循环神经网络模型中,进行迭代训练,在达到设定迭代次数后,获得最终的网络模型参数文件;预测结果提升输出模块,用于将获取网络参数模块获得的最终的网络模型参数文件加载到准循环神经网络模型中,通过基于word2vec的cbow模型和迁移学习来提升业务流程剩余时间的预测效果,并获得最优的准循环神经网络模型,最终将测试集输入到最优的准循环神经网络模型中进行验证,从而获得准确的业务流程剩余时间预测结果,并对结果进行输出。本发明的第三目的通过下述技术方案实现:一种存储介质,存储有程序,所述程序被处理器执行时,实现上述的业务流程剩余时间预测方法。本发明的第四目的通过下述技术方案实现:一种计算设备,包括处理器以及用于存储处理器可执行程序的存储器,所述处理器执行存储器存储的程序时,实现上述的业务流程剩余时间预测方法。本发明与现有技术相比,具有如下优点与有益效果:1、本发明通过使用迁移学习的方法加强了不同长度轨迹前缀内在关联性,并且克服了长轨迹前缀数量少的问题,从而获得了准确的业务流程剩余时间预测结果。2、本发明通过使用基于word2vec的cbow模型,充分的反映出事件向量的语义信息,从而提高了剩余时间预测模型的性能。3、本发明相较于传统剩余时间预测方法,在预测准确性上得到了明显的提升,从而为必要的人工干预提供更有利的决策依据。4、本发明在训练时间上优于传统的预测方法,从而一定程度上缩短了程序的执行时间。5、本发明方法在预测型流程监控任务中具有广泛的使用空间,操作简单、适应性强,在业务流程剩余时间预测方面有广阔前景。附图说明图1为本发明方法逻辑流程图。图2为准循环神经网络模型结构图。图3为网络模型参数文件示意图。图4为基于word2vec的cbow模型结构图。图5为基于word2vec的cbow模型预训练事件向量结果图。图6为效果对比图。图7为基于word2vec的cbow模型效果分析图。图8为训练时间性能对比分析图;图9为本发明系统框架图。具体实施方式下面结合实施例及附图对本发明作进一步详细的描述,但本发明的实施方式不限于此。实施例1如图1所示,本实施例公开了一种基于过程挖掘的业务流程剩余时间预测方法,首先获取标准化事件日志,利用得到的事件日志构建以不同轨迹前缀长度为基准的数据集,并将数据集划分为训练集和测试集。其次,将训练集输入到准循环神经网络模型中进行迭代训练。为了提升业务流程剩余时间预测结果,利用word2vec的cbow模型对数据集进行预训练,得到事件向量,并将事件向量输入到准循环神经网络模型中,得到最优的准循环神经网络模型。最后,利用迁移学习对最优的准循环神经网络模型进行训练,并通过测试集进行验证。最后得到准确的业务流程剩余时间预测结果。其包括以下步骤:1)通过4tu平台获取事件日志,将事件日志中多余的属性删除,只保留事件和事件的时间戳,从而构成标准化事件日志,在此标准化事件日志中记载了相关的业务流程;其中选取了5个事件日志,分别是bpic_2012_a/w/o:某财政机构贷款申请审批日志、helpdesk:某票务管理系统后台日志、hospital_billing:某医院epr系统中出院结算流程日志。所有事件日志均可通过4tu平台来获取。选取的5个公开事件日志详细信息如表1所示。表1事件日志基本信息统计数据集轨迹数量事件数量活动数量轨迹最大长度轨迹最小长度bpic_2012_a130877302210103bpic_2012_o5015417287394bpic_2012_w965814745061531helpdesk3804137109141hospital_billing1000004513591821712)根据步骤1)中获得的标准化事件日志构建以不同轨迹前缀长度为基准的数据集,并将数据集划分为训练集和测试集,其具体步骤如下:2.1)在标准化事件日志中,对轨迹前缀长度的范围进行设定;2.2)遍历标准化事件日志中的每一条轨迹,并在步骤2.1)设定好的范围内进行截取,得到长度不同的轨迹前缀及其对应的业务流程剩余时间;2.3)将步骤2.2)得到的所有长度不同轨迹前缀及其对应的业务流程剩余时间作为数据集,并以70%比例当作训练集,余下的30%当作测试集。3)将步骤2)中获得的训练集输入到准循环神经网络模型(模型结构见图2所示)中,依照设定好的训练次数进行迭代训练,并对网络模型参数进行调整,在完成迭代训练之后,获得最终的网络模型参数文件,具体情况如下:所述准循环神经网络模型由卷积层和池化层组成,将训练集输入到准循环神经网络模型之后,首先会经过一层卷积层,该卷积层利用数量为m的滤波器对训练集进行卷积运算,目的在于提取输入训练集的特征信息,并得到输出序列x(x1,x2,……,xn),其中xn代表第n个输出序列;然后,输出序列x(x1,x2,……,xn)会再经过一层池化层,池化层作用就是减少卷积层的输出序列x(x1,x2,……,xn)特征数目,得到新的输出序列z(z1,z2,……,zn),其中zn代表第n个新的输出序列,而该输出序列z(z1,z2,……,zn)就是业务流程以不同轨迹前缀长度为基准的剩余时间预测结果。其中,预测结果包含预测的业务流程剩余时间和平均绝对误差;根据得到的平均绝对误差结果对网络模型参数进行调整,并再次进行迭代训练,在完成设定的迭代次数后获得最终的网络模型参数文件,见图3所示。在参数文件中包含迭代次数(epoch)、训练起始位置(startpos)、学习率(learnrate)、平均绝对误差值(mae)。4)将步骤3)获得的最终的网络模型参数文件加载到准循环神经网络模型中,通过基于word2vec的cbow模型(模型结构见图4所示)和迁移学习来提升业务流程剩余时间的预测效果,并获得最优的准循环神经网络模型,最终将测试集输入到最优的准循环神经网络模型中进行验证,获得准确的业务流程剩余时间预测结果,包括以下步骤:4.1)对数据集中的事件时间戳进行离散化处理,离散化后事件e的执行时间为:式中,t(e)代表事件e的连续执行时间,tmax(starttime-endtime)(e,a)和tmin(starttime-endtime)(e,a)代表活动a在事件日志中出现的最长与最短执行时间,n的是离散化后事件e执行时间所划分数量;4.2)将全部活动a与步骤4.1)离散化后的执行时间进行拼接,得到事件向量其中t代表活动a的执行时间,代表m阶矩阵;4.3)根据步骤4.2)得到的事件向量θ<a,t>,利用基于word2vec的cbow模型对事件向量θ<a,t>进行预训练,具体步骤如下:4.3.1)事件向量θ<a,t>与基于word2vec的cbow模型中输入层的权重矩阵w{1,2,3,……,m}进行点乘运算,得到矩阵向量v{1,2,3,……,k},其中权重矩阵中的m、k代表是第m个和第k个权重矩阵;4.3.2)将步骤4.3.1)中得到的矩阵向量v{1,2,3,……,k}进行加权求平均操作,并得到矩阵向量p;4.3.3)将步骤4.3.2)中得到的矩阵向量p与基于word2vec的cbow模型中输出层的权重矩阵z进行点乘运算,并对运算后的结果进行softmax归一化,得到预训练事件向量结果q,见图5所示;其中,图5第一行数字55代表有55个事件,3代表每一个事件都会由三个不同的浮点数进行表示;4.3.4)根据步骤4.3.3)得到的事件向量q,将其输入到已加载网络模型参数文件的准循环神经网络模型中进行迭代训练,再将迭代后的网络模型以迁移学习的方式进行训练,得到最优的准循环神经网络模型;4.3.5)将测试集输入到步骤4.3.4)得到的最优的准循环神经网络模型中进行验证,从而获得准确的业务流程剩余时间预测结果。其中,上述word2vec是一个用来产生词向量的方法,而cbow模型是word2vec中一种常用的模型,该模型主要是将事件向量中同一轨迹且经常出现的事件进行相似性向量表示,并通过上下文事件来预测当前事件;上述迁移学习则是将训练好的模型参数迁移到新的模型中来,进一步帮助新模型进行训练,而利用迁移学习的主要目的在于:由于构建的以不同轨迹前缀长度为基准的数据集中,短轨迹前缀的数量要多于长轨迹的数量,倘若不对轨迹前缀进行区分,并输入到准循环神经网络模型中进行训练会造成业务流程剩余时间预测不准确的情况,因此,需要先对数量多的短轨迹前缀进行训练,然后利用迁移学习,将短轨迹前缀训练好的网络模型参数作为长轨迹前缀训练的初始值,从而达到提升业务流程剩余时间预测结果的目的。下面为了进一步验证本实施例上述基于过程挖掘的业务流程剩余时间预测方法在业务流程预测任务上的有效性与优越性,将与其它神经网络模型进行比较,具体情况如下:实验使用平均绝对误差(meanabsoluteerror,mae)作为每一个神经网络模型的评价指标,同时采用5折交叉验证的方式对业务流程剩余时间神经网络模型进行有效地评估,具体过程如下:a、使用平均绝对误差(meanabsoluteerror,mae)作为每一个神经网络模型的评价指标:其主要通过计算业务流程每一个轨迹前缀的剩余时间真实值和预测值之间差值的绝对值来评判剩余时间预测的准确度。倘若mae值较低,则说明预测的剩余时间较为准确。式中,σ(k)代表的是轨迹前缀,f(σ(k))是轨迹前缀的剩余时间真实值,remaintime(σ,k)是轨迹前缀的剩余时间预测值。b、采用5折交叉验证的方式对业务流程剩余时间神经网络模型进行有效地评估,即将构建好的数据集随机划分为5等份,每一次选择4份数据作为训练集,1份作为测试集,并重复5次实验,最后把5次交叉验证mae值的平均值作为最终评估结果。为了得到业务流程剩余时间预测任务中最优神经网络模型,因此将长短期记忆网络(longshort-termmemory,lstm)以及门控循环单元(gatedrecurrentunit,gru)作为对比方法。将要对比的神经网络模型具体如下:a、gru(门控循环单元神经网络模型)b、lstm(长短期记忆神经网络模型)c、qrnn(准循环神经网络模型)d、bi-gru(含有双向机制门控循环单元神经网络模型)e、bi-lstm(含有双向机制长短期记忆神经网络模型)f、bi-qrnn(含有双向机制准循环神经网络模型)g、att-bi-gru(含有双向机制、注意力机制门控循环单元神经网络模型)h、att-bi-lstm(含有双向机制、注意力机制长短期记忆神经网络模型)i、att-bi-qrnn(含有双向机制、注意力机制准循环神经网络模型)j、trans-att-bi-gru(含有双向机制、注意力机制、迁移学习门控循环单元神经网络模型)k、trans-att-bi-lstm(含有双向机制、注意力机制、迁移学习长短期记忆神经网络模型)l、trans-att-bi-qrnn(含有双向机制、注意力机制、迁移学习准循环神经网络模型)对不同神经网络模型进行基本调参,调整参数如下:a、输入事件向量的维度:{3,5,7,10}b、神经元隐向量的维度:{3,5,7,10}c、学习率:{0.01,0.1}d、迭代次数:150e、优化算法:adam经过调参之后,表2展示了本方法与对比方法在5个不同数据集上的mae值并且得到以下三个结论:表2不同方法的对比实验结果方法bpic_2012_abpic_2012_obpic_2012_whelpdeskhospital_billingts-set7.5057.3928.4296.28351.456ts-multiset7.4887.2038.6916.16751.507ts-sequence7.4889.6128.6196.19251.504spn8.8806.3858.5166.33778.018lstm3.5887.9938.0213.54242.050bi-lstm4.6008.4077.2212.95241.515att-bi-lstm3.8957.3246.1532.67736.691trans-att-bi-lstm3.4895.8585.8263.35733.201gru4.8887.3947.7533.42547.400bi-gru4.4618.1447.3343.22237.157att-bi-gru3.5127.3066.3383.30333.201trans-att-bi-gru3.4385.8635.8213.29932.187qrnn3.5436.7797.5163.19936.611bi-qrnn3.9926.7577.1282.88435.248att-bi-qrnn3.2006.2766.0072.62633.101trans-att-bi-qrnn2.3735.1585.2752.42331.436由表2可以看出,利用深度学习方法进行剩余时间预测的效果要比基于变迁系统和随机petri网方法的效果好,进一步印证了深度学习方法在剩余时间预测任务上的优势。而产生此现象的关键原因在于循环神经网络具备较强的序列建模能力以及鲁棒性较强,可以很好地处理高噪声、海量的事件日志,进而可以获得良好地预测效果。对比qrnn、lstm和gru三种循环神经网络(qrnnvslstmvsgru、bi-qrnnvsbi-lstmvsbi-gru、att-bi-qrnnvsatt-bi-lstmvsatt-bi-gru、trans-att-bi-qrnnvstrans-att-bi-lstmvstrans-att-bi-gru),qrnn在整体上的预测效果要优于lstm以及gru,因此可以认为qrnn比lstm、gru更加适合业务流程剩余时间预测任务。以qrnn作为基础神经网络模型,引入迁移学习、双向机制、注意力机制以及基于word2vec的cbow模型后,在5个不同的数据集中都获得了较好的预测效果。相较于以lstm和gru为神经单元的基于迁移学习的循环神经网络预测方法,本发明方法的mae值平均下降了14%,从而证明了本发明方法的优越性。为了验证基于过程挖掘的业务流程剩余时间预测方法中使用的准循环神经网络模型在业务流程剩余时间预测任务上的优越性,在去除基于迁移学习剩余时间预测模型和基于word2vec的cbow模型的前提下,对各个神经网络模型在业务流程剩余时间预测任务上的效果进行对比,具体步骤如下:a、移除迁移学习和基于word2vec的cbow模型,使用传统的方式为全部的轨迹前缀构建统一的训练模型;b、在训练的过程当中分别移除双向机制和注意力机制,并以qrnn、lstm以及gru为基准作为循环神经网络的具体实现;表3展示了各个神经网络模型效果对比的方法。并根据图6中的(a)、(b)、(c)、(d)、(e)全部方法在5个数据集中的mae值得到以下四个结论:表3效果对比方法方法是否有双向机制是否有注意力机制模型训练方式lstm否否统一bi-lstm是否统一att-bi-lstm是是统一trans-att-bi-lstm是是迁移学习gru否否统一bi-gru是否统一att-bi-gru是是统一trans-att-bi-gru是是迁移学习qrnn否否统一bi-qrnn是否统一att-bi-qrnn是是统一trans-att-bi-qrnn是是迁移学习在不含有注意力机制、双向机制以及迁移学习情况下,qrnn相较于lstm以及gru在5个数据集中都取得了较低的mae值;在引入双向机制后,bi-qrnn相较于bi-lstm以及bi-gru在5个数据集中取得了较好地mae值,同时相比于qrnn,bi-qrnn在4个数据集中取得了更低地mae值;在引入注意力机制之后,att-bi-qrnn的预测效果还是略优于att-bi-lstm、att-bi-gru以及bi-qrnn;在引入迁移学习后,trans-att-bi-qrnn在5个数据集上的预测效果要优于att-bi-qrnn,并且mae值也低于trans-att-bi-lstm以及trans-att-bi-gru。由此,可以总结得到引入双向机制、注意力机制以及迁移学习都可提高业务流程剩余时间的精确度。此外,qrnn在业务流程剩余时间预测任务上要比传统的lstm以及gru更加的适合,这就说明将qrnn应用于剩余时间预测是一项有益的尝试。为了验证基于word2vec的cbow模型对业务流程剩余时间预测效果的影响,本发明将基于word2vec的cbow模型得到的事件向量(表示为trans-att-bi-qrnn-vector)以及传统one-hot编码(表示为trans-att-bi-qrnn-novector)得到的向量作为准循环神经网络模型的输入,进而测试基于word2vec的cbow模型对剩余时间预测效果的影响。图7展示了两种不同方法的mae值,由图7可以看出,trans-att-bi-qrnn-vector在5个数据集上的mae值要比trans-att-bi-qrnn-novector的mae值低3%,因此可以认为基于word2vec的cbow模型对提升业务流程剩余时间预测效果有重要的作用。为了进一步验证基于过程挖掘的业务流程剩余时间预测方法中使用的准循环神经网络模型在时间性能上的优势,在同参数的情况下将准循环神经网络的训练时间与其它神经网络模型训练时间进行对比,测试的方法如下:a、无基于word2vec的cbow模型和迁移学习,并在特定的轨迹前缀下对各个神经网络模型的训练时间进行测试。b、有基于word2vec的cbow模型,无迁移学习,并在特定的轨迹前缀下对各个神经网络模型的训练时间进行测试。c、有基于word2vec的cbow模型和迁移学习,并在不同长度的轨迹前缀下对各个神经网络模型的训练时间进行测试。在实验过程中,各个神经网络模型在不同方法下采用了相同的参数设置,实验结果如图8中(a)、(b)、(c)、(d)、(e)所示。由图8中(a)可以发现,数据集bpic_2012_a在不使用基于word2vec的cbow模型和迁移学习的情况下,以qrnn为基准的神经网络模型训练时间要比以lstm为基准和以gru为基准的神经网络模型训练时间快了约9%~15%;在使用基于word2vec的cbow模型和不使用迁移学习的情况下,以qrnn为基准的神经网络模型训练时间要比以lstm为基准和以gru为基准的神经网络模型训练时间快了约11%~19%;在使用基于word2vec的cbow模型和迁移学习的情况下,以qrnn为基准的神经网络模型训练时间要比以lstm为基准和以gru为基准的神经网络模型训练时间快了约14%~22%。由图8中(b)可以发现,数据集bpic_2012_o在不使用基于word2vec的cbow模型和迁移学习的情况下,以qrnn为基准的神经网络模型训练时间要比以lstm为基准和以gru为基准的神经网络模型训练时间快了约22%~30%;在使用基于word2vec的cbow模型和不使用迁移学习的情况下,以qrnn为基准的神经网络模型训练时间要比以lstm为基准和以gru为基准的神经网络模型训练时间快了约22%~37%;在使用在使用基于word2vec的cbow模型和迁移学习的情况下,以qrnn为基准的神经网络模型训练时间要比以lstm为基准和以gru为基准的神经网络模型训练时间快了约14%~22%。由图8中(c)可以发现,数据集bpic_2012_w在不使用基于word2vec的cbow模型和迁移学习的情况下,以qrnn为基准的神经网络模型训练时间要比以lstm为基准和以gru为基准的神经网络模型训练时间快了约18%~32%;在使用基于word2vec的cbow模型和不使用迁移学习的情况下,以qrnn为基准的神经网络模型训练时间要比以lstm为基准和以gru为基准的神经网络模型训练时间快了约35%~45%;在使用基于word2vec的cbow模型和迁移学习的情况下,以qrnn为基准的神经网络模型训练时间要比以lstm为基准和以gru为基准的神经网络模型训练时间快了约8%~28%。由图8中(d)可以发现,数据集helpdesk在不使用基于word2vec的cbow模型和迁移学习的情况下,以qrnn为基准的神经网络模型训练时间要比以lstm为基准和以gru为基准的神经网络模型训练时间快了约15%~21%;在使用基于word2vec的cbow模型和不使用迁移学习的情况下,以qrnn为基准的神经网络模型训练时间要比以lstm为基准和以gru为基准的神经网络模型训练时间快了约12%~19%;在使用基于word2vec的cbow模型和迁移学习的情况下,以qrnn为基准的神经网络模型训练时间要比以lstm为基准和以gru为基准的神经网络模型训练时间快了约12%~20%。由图8中(e)可以发现,数据集hospital_billing在不使用基于word2vec的cbow模型和迁移学习的情况下,以qrnn为基准的神经网络模型训练时间要比以lstm为基准和以gru为基准的神经网络模型训练时间快了约20%~30%;在使用基于word2vec的cbow模型和不使用迁移学习的情况下,以qrnn为基准的神经网络模型训练时间要比以lstm为基准和以gru为基准的神经网络模型训练时间快了约13%~26%;在使用基于word2vec的cbow模型和迁移学习的情况下,以qrnn为基准的神经网络模型训练时间要比以lstm为基准和以gru为基准的神经网络模型训练时间快了约12%~24%。实施例2本实施例公开了一种基于过程挖掘的业务流程剩余时间预测系统,如图9所示,包括数据预处理模块、数据生成模块、获取网络参数模块和预测结果提升输出模块。数据预处理模块,用于将事件日志中多余的属性删除,只保留事件和事件的时间戳,从而构成标准化事件日志,该标准化事件日志记载了相关的业务流程;数据生成模块,用于将数据预处理模块获得的标准化事件日志构建以不同轨迹前缀长度为基准的数据集,并将数据集划分为训练集和测试集;获取网络参数模块,用于将数据生成模块中获得的训练集输入到准循环神经网络模型中,进行迭代训练,在达到设定迭代次数后,获得最终的网络模型参数文件;预测结果提升输出模块,用于将获取网络参数模块获得的最终的网络模型参数文件加载到准循环神经网络模型中,通过基于word2vec的cbow模型和迁移学习来提升业务流程剩余时间的预测效果,并获得最优的准循环神经网络模型,最终将测试集输入到最优的准循环神经网络模型中进行验证,从而获得准确的业务流程剩余时间预测结果,并对结果进行输出。实施例3本实施例公开了一种存储介质,存储有程序,所述程序被处理器执行时,实现实施例1所述的业务流程剩余时间预测方法。本实施例中的存储介质可以是磁盘、光盘、计算机存储器、只读存储器(rom,read-onlymemory)、随机存取存储器(ram,randomaccessmemory)、u盘、移动硬盘等介质。实施例4本实施例公开了一种计算设备,包括处理器以及用于存储处理器可执行程序的存储器,所述处理器执行存储器存储的程序时,实现实施例1所述的业务流程剩余时间预测方法。本实施例中所述的计算设备可以是台式电脑、笔记本电脑、智能手机、pda手持终端、平板电脑、可编程逻辑控制器(plc,programmablelogiccontroller)、或其它具有处理器功能的终端设备。综上所述,在采用以上方案后,本发明为业务流程剩余时间预测任务提供了新的方式,在提升剩余时间预测效果的同时,获得了准确的业务流程剩余时间预测结果,具有实际推广价值,值得推广。上述实施例为本发明较佳的实施方式,但本发明的实施方式并不受上述实施例的限制,其他的任何未背离本发明的精神实质与原理下所作的改变、修饰、替代、组合、简化,均应为等效的置换方式,都包含在本发明的保护范围之内。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1