基于审评评语的茶叶感官品质的比较方法及系统
本发明涉及一种自然语言处理技术,特别是涉及一种基于审评评语的茶叶感官品质的比较方法及系统。
背景技术:
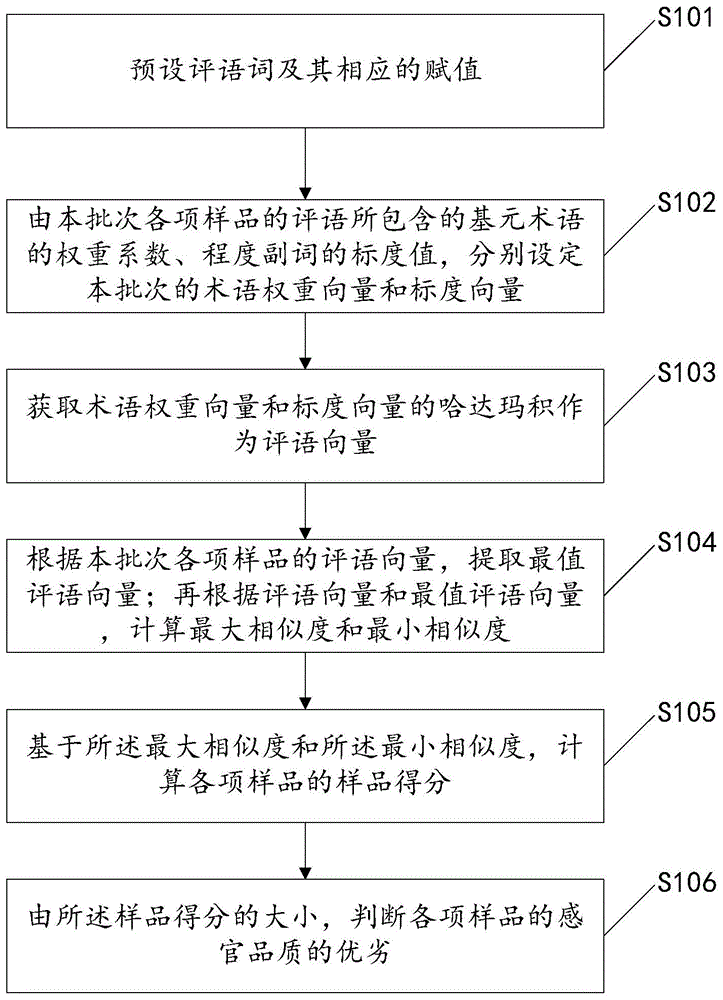
:茶叶品质主要源于茶汤和干茶的色、香、味、形。感官审评是评价茶叶品质最直观、最便利、最常用的方法,其结果对茶叶的商品价值判断有直接影响。审评评语是茶叶感官审评结果的载体,也是茶叶品质比较的基础。标准化的审评评语一般涵盖茶叶外形和内质中主要感官品质的特征描述和程度描述。然而,由于评语是文字信息且包含了各类型的感官描述,这使得评语间的直接比较困难,尤其是对于大量且品质各异的样品。因此,如何准确地“翻译”审评评语并实施比对,是开展茶叶品质比较的重点和难点。目前,先将审评评语转换为百分制评分、再借助评分实现茶叶品质比较是被最广泛采用的手段。这种方法具有规则简单、实施便利的优点。但是,其缺陷也十分明显:一方面,在将包含外形、滋味、香气等多维度品质描述的审评评语转换为单一评分时,必然导致评语中细节信息的丢失;另一方面,百分制评分的标度过于精细,与茶叶审评中对感官品质差异的表述不匹配,使得评分的判定具有较强的随意性。上述缺陷均会放大主观因素在评语向评分转换中的影响,降低茶叶品质比较的结果的准确性和稳定性。技术实现要素:基于此,有必要针对上述问题,提供一种基于审评评语的茶叶感官品质的比较方法及系统,能够提高茶叶品质比较的结果的准确性和稳定性。一种基于审评评语的茶叶感官品质的比较方法,包括:预设评语词及其相应的赋值,其中所述评语词包括基元术语、程度副词,所述基元术语的相应赋值包括权重系数,所述程度副词的相应赋值包括标度值;由本批次各项样品的评语所包含的基元术语的权重系数、程度副词的标度值,分别设定本批次的术语权重向量和标度向量;获取术语权重向量和标度向量的哈达玛积作为评语向量;根据本批次各项样品的评语向量,按预设方法提取评语向量间各维度的最大值和最小值作为最大值评语向量和最小值评语向量;再根据所述评语向量和所述最大值评语向量、所述最小值评语向量,按预设的相似度公式计算最大相似度和最小相似度;基于所述最大相似度和所述最小相似度,计算各项样品的样品得分;由所述样品得分的大小,判断各项样品的感官品质的优劣。在其中一个实施例中,所述基元术语的相应赋值包括权重系数之外,还包括:褒贬义系数;所述由本批次各项样品的评语所包含的基元术语的权重系数、程度副词的标度值,分别设定本批次的术语权重向量和标度向量的步骤,还包括,由本批次各项样品的评语所包含的基元术语的褒贬义系数,设定本批次的褒贬系数向量;所述获取术语权重向量和标度向量的哈达玛积作为评语向量的步骤,具体包括,获取术语权重向量、标度向量、褒贬系数向量的哈达玛积作为评语向量。在其中一个实施例中,所述预设评语词及其相应的赋值的步骤,具体包括:按预设的感官审评类目,定义评语词及其相应的赋值;所述感官审评类目包括滋味、香气、干茶外形、汤色、叶底当中的至少一项。在其中一个实施例中,所述按预设的相似度公式计算最大相似度和最小相似度的步骤,包括:按余弦相似度和/或杰卡德系数公式计算最大相似度和最小相似度。在其中一个实施例中,所述判断各项样品的感官品质的优劣的步骤之后,还包括:基于所述最大相似度和所述最小相似度,计算各项样品的特征向量;按预设的聚类方法及参数,对所述各项样品的特征向量实施聚类分组;根据各分组内的样品得分的平均值的大小,给本批次样品的感官品质分级。在其中一个实施例中,所述判断各项样品的感官品质的优劣的步骤之后,还包括:由所述样品得分的大小,给各项样品的感官品质的优劣排序。相应的,一种基于审评评语的茶叶感官品质的比较系统,包括:词库单元,用于预设评语词及其相应的赋值,其中所述评语词包括基元术语、程度副词,所述基元术语的相应赋值包括权重系数,所述程度副词的相应赋值包括标度值;向量转化单元,用于由本批次各项样品的评语所包含的基元术语的权重系数、程度副词的标度值,分别设定本批次的术语权重向量和标度向量;评语向量单元,用于获取术语权重向量和标度向量的哈达玛积作为评语向量;相似度计算单元,用于根据本批次各项样品的评语向量,按预设方法提取评语向量间各维度的最大值和最小值作为最大值评语向量和最小值评语向量;再根据所述评语向量和所述最大值评语向量、所述最小值评语向量,按预设的相似度公式计算最大相似度和最小相似度;得分计算单元,用基于所述最大相似度和所述最小相似度,计算各项样品的样品得分;结果判断单元,用于由所述样品得分的大小,判断各项样品的感官品质的优劣。相应的,在其中一个实施例中,所述词库单元,包括:赋值设置子单元;所述赋值设置子单元,用于预设评语词及其相应的赋值,其中所述评语词包括基元术语、程度副词,所述基元术语的相应赋值包括权重系数和褒贬义系数,所述程度副词的相应赋值包括标度值;所述向量转化单元,还用于由本批次各项样品的评语所包含的基元术语的褒贬义系数,设定本批次的褒贬系数向量;所述评语向量单元,还用于获取术语权重向量、标度向量、褒贬系数向量的哈达玛积作为评语向量。相应的,在其中一个实施例中,所述词库单元,包括:类目设置子单元;所述类目设置子单元,用于按预设的感官审评类目,定义评语词及其相应的赋值;所述感官审评类目包括滋味、香气、干茶外形、汤色、叶底当中的至少一项。相应的,在其中一个实施例中,所述相似度计算单元,包括:公式设置子单元,用于按余弦相似度和/或杰卡德系数公式计算最大相似度和最小相似度;所述结果判断单元,包括:分级子单元和/或排序子单元;其中,所述分级子单元,用于基于所述最大相似度和所述最小相似度,计算各项样品的特征向量;按预设的聚类方法及参数,对所述各项样品的特征向量实施聚类分组;根据各分组内的样品得分的平均值的大小,给本批次样品的感官品质分级;所述排序子单元,用于由所述样品得分的大小,给各项样品的感官品质的优劣排序。本发明具有如下有益效果:该方法实现了基于茶叶审评评语的品质比较,可确保比较结果与文字评语的一致性。方法中所述审评向量还原了审评评语中的品质描述信息。所述基元术语和所述程度副词的设置,与茶叶感官审评评语中“感官特征+感官强度”的品质描述方式一致。所述权重系数的设置,适应了各个感官品质特征对整体品质影响程度各异的茶叶评比习惯。所述程度副词标度值的尺度符合文字评语中感官强度的描述范围。于是,由所述权重系数、标度值组成的所述评语向量较大程度地避免保留了审评评语中的信息,确保评语中多数的品质描述信息直接参与样品间的比较。方法中所述审评向量的比较方法挖掘了样品间品质差异信息。采用所述评语向量与所述评语向量的最值比较的方法,反映了各个样品的优点与缺点的差异程度。于是,由各个所述最大和最小相似度计算所得的所述样品得分可有效反映原审评评语间差异。附图说明此处的附图,示出了本发明所述技术方案的具体实例,并与具体实施方式构成说明书的一部分,用于解释本发明的技术方案、原理及效果。除非特别说明或另有定义,不同附图中,相同的附图标记代表相同或相似的技术特征,对于相同或相似的技术特征,也可能会采用不同的附图标记进行表示。图1为本发明一种基于审评评语的茶叶感官品质的比较方法的流程图;图2为本发明一种基于审评评语的茶叶感官品质的比较方法的第一实施例流程图;图3为本发明一种基于审评评语的茶叶感官品质的比较方法的第二实施例流程图;图4为本发明一种基于审评评语的茶叶感官品质的比较系统的示意图。图5为本发明一种基于审评评语的茶叶感官品质的比较系统的第一实施例示意图;图6为本发明一种基于审评评语的茶叶感官品质的比较系统的第二实施例示意图。具体实施方式为了便于理解本发明,下面将参照说明书附图对本发明的具体实施例进行更详细的描述。除非特别说明或另有定义,本文所使用的所有技术和科学术语与所属
技术领域:
的技术人员通常理解的含义相同。在结合本发明的技术方案以现实的场景的情况下,本文所使用的所有技术和科学术语也可以具有与实现本发明的技术方案的目的相对应的含义。除非特别说明或另有定义,本文所使用的“第一、第二…”仅仅是用于对名称的区分,不代表具体的数量或顺序。除非特别说明或另有定义,本文所使用的术语“和/或”包括一个或多个相关的所列项目的任意的和所有的组合。图1为本发明一种基于审评评语的茶叶感官品质的比较方法的流程图,包括:s101:预设评语词及其相应的赋值,其中所述评语词包括基元术语、程度副词,所述基元术语的相应赋值包括权重系数,所述程度副词的相应赋值包括标度值;s102:由本批次各项样品的评语所包含的基元术语的权重系数、程度副词的标度值,分别设定本批次的术语权重向量和标度向量;s103:获取术语权重向量和标度向量的哈达玛积作为评语向量;s104:根据本批次各项样品的评语向量,提取最值评语向量;再根据评语向量和最值评语向量,计算最大相似度和最小相似度;具体地,根据本批次各项样品的评语向量,按预设方法提取评语向量间各维度的最大值和最小值作为最大值评语向量和最小值评语向量;再根据所述评语向量和所述最大值评语向量、所述最小值评语向量,按预设的相似度公式计算最大相似度和最小相似度。s105:基于所述最大相似度和所述最小相似度,计算各项样品的样品得分;s106:由所述样品得分的大小,判断各项样品的感官品质的优劣。该方法实现了基于茶叶审评评语的品质比较,可确保比较结果与文字评语的一致性。方法中所述审评向量还原了审评评语中的品质描述信息。所述基元术语和所述程度副词的设置,与茶叶感官审评评语中“感官特征+感官强度”的品质描述方式一致。所述权重系数的设置,适应了各个感官品质特征对整体品质影响程度各异的茶叶评比习惯。所述程度副词标度值的尺度符合文字评语中感官强度的描述范围。所述褒贬义系数的设置,还原了审评人对感官特征的喜恶。于是,由所述权重系数、标度值和褒贬义系数组成的所述评语向量较大程度地避免保留了审评评语中的信息,确保评语中多数的品质描述信息直接参与样品间的比较。方法中所述审评向量的比较方法挖掘了样品间品质差异信息。采用所述评语向量与所述评语向量的最值比较的方法,反映了各个样品的优点与缺点的差异程度。基于余弦相似度和/或杰卡德系数度量各个样品的所述最大和最小相似度,兼顾了所述评语向量在方向和有效长度的差异。于是,由各个所述最大和最小相似度计算所得的所述样品得分可有效反映原审评评语间差异。图2为本发明一种基于审评评语的茶叶感官品质的比较方法的第一实施例流程图。s201:预设评语词及其相应的赋值,其中所述评语词包括基元术语、程度副词,所述基元术语的相应赋值包括权重系数和褒贬义系数,所述程度副词的相应赋值包括标度值;s202:由本批次各项样品的评语所包含的基元术语的权重系数、程度副词的标度值,分别设定本批次的术语权重向量和标度向量;s203:由本批次各项样品的评语所包含的基元术语的褒贬义系数,设定本批次的褒贬系数向量;s204:获取术语权重向量、标度向量、褒贬系数向量的哈达玛积作为评语向量。s205:根据本批次各项样品的评语向量,提取最值评语向量;再根据评语向量和最值评语向量,计算最大相似度和最小相似度;具体地,根据本批次各项样品的评语向量,按预设方法提取评语向量间各维度的最大值和最小值作为最大值评语向量和最小值评语向量;再根据所述评语向量和所述最大值评语向量、所述最小值评语向量,按预设的相似度公式计算最大相似度和最小相似度s206:基于所述最大相似度和所述最小相似度,计算各项样品的样品得分;s207:由所述样品得分的大小,判断各项样品的感官品质的优劣;s208:基于所述最大相似度和所述最小相似度,计算各项样品的特征向量;按预设的聚类方法及参数,对所述各项样品的特征向量实施聚类分组;根据各分组内的样品得分的平均值的大小,给本批次样品的感官品质分级。在本实施例中,先确定需要执行感官品质比较的样品数量,将所有样品定义为一个批次,在一个批次所有样品的审评评语中提取出每一个与一种感官品质对应的基元术语。如果审评评语中包含有对应多个感官品质的组合术语,则将组合术语拆分为多个仅对应一种感官品质的基元术语,并在基元术语前保留修饰组合术语的程度副词。对于采用标准化审评方法获得的审评评语,基元术语的挑选可参考中华人民共和国国家标准《茶叶感官审评术语》(gb/t14487),根据茶叶样品的类型以及描述对象确定。gb/t14487囊括了大多数标准化审评中采用常用的术语,覆盖了所有茶类,是一个完备的基元术语库。对于未收录于gb/t14487中的术语,应先判断该术语是否与gb/t14487中已收录术语的语意相同或相似;若是,则将该用词认定为基元术语;若否,则排除该术语。对于未采用标准化审评方法获得的审评评语,基元术语的挑选则需根据参与该批次样品审评人员的对每个感官品质的区分和概括确定。将提取出的基元术语进行排序。例如,根据基元术语相应的权重系数由高至低排序。需要补充说明的是,步骤s201当中,所述基元术语的相应赋值包括权重系数,例如,若在一批茶叶审评评语中存在一种基元术语,其对茶叶整体品质判定的贡献大于其他基元术语,此时可将该术语对应的权重系数差异化设置。步骤s201当中,所述基元术语的相应赋值还包括褒贬义系数。不同基元术语与茶叶整体品质的相关性各异——有的呈正相关,有的呈负相关,还有的不呈现相关性。褒贬义系数的设定可反映不同基元术语与茶叶整体品质相关性的差异。本实施例中,步骤s203根据基元术语的褒贬义定义基元术语褒贬系数向量。“褒义基元术语”表示一种描述感官品质优点的术语,“贬义基元术语”表示一种描述感官品质缺点的术语,“中性基元术语”表示一种描述不具有褒贬义感官品质特征的术语。所述褒贬义系数的设置,还原了审评人对感官特征的喜恶。基元术语褒贬系数向量如下:s:=[s1…si…sn]t(1)(1≤i≤n)式中,s包括n个元素,每个元素对应一种基元术语的褒贬义系数,且在顺序上与基元术语的排序一致。向量中的元素si={-1,0,1},其中褒义基元术语对应元素设为1,贬义基元术语对应元素设为-1,中性基元术语对应元素设为0。根据感官品质在样品比较时的重要性定义术语权重向量。各基元术语的权重由其对应感官品质归属的审评因子确定,其中审评因子包括外形、汤色、香气、滋味和叶底五个方面。归属同一审评因子的基元术语,其对权重值既可保持一致,也可根据术语在具体品质比较的重要性差异化设定。基元术语权重向量如下式所示:w:=[w1…wi…wn]t(2)(1≤i≤n)式中,w包括n个元素,每个元素对应一种基元术语的权重值,且在顺序上与基元术语的排序一致。向量中的元素wi∈(0,1],其取值可参考中华人民共和国国家标准《茶叶感官审评方法》(gb/t23776)中“各茶类品质因子评分系数”的系数值,将系数值先除以100再开平方根,得最终取值。需要补充说明的是,权重系数取值也根据基元术语在茶叶总体品质评价中的重要性做差异化调整。例如,具体审评过程中规定了对总体品质起主要贡献的品质特征,则可提高该品质特征对应基元术语的权重系数。以样品为行、基元术语为列构建表格,用于统计基元术语在各个样品中的分布。表格中基元术语列与规定的排序一致。对应每个基元术语,从各个样品的审评评语中提取包含该术语的词组,并一一对应地填入所构建的表格中。所提取词组需反映相应基元术语指代的感官品质,并包含修饰该感官品质强度的程度副词。若样品中不存在相应的基元术语,则在表格记为“-”。从基元术语在一批次样品中分布情况的统计结果中,根据修饰基元术语程度副词种类的不同,汇中术语对应词组的种类,并以程度副词修饰强度“由弱至强”的次序排列。对于采用标准化审评方法获得的审评评语,可基于表t1中程度副词与感官强度的对应关系排序;而在表t1中未列出的程度副词,需根据其在评语中实际指代感官程度确定强弱及排列次序。对于未采用标准化审评方法获得的审评评语,程度副词与感官强度的对应关系应根据审评员的实际感受确定。表t1程度副词与感官强度的对应关系随后,对各个程度副词进行等距标度。根据每个基元术语程度副词的排序,由弱(或无)至强对应一个标度,以指代强度最弱或无基元术语的标度对应赋值为0,每提高一个标度对应赋值较前一个标度增加1,直至每一个程度副词均有一个对应的标度值。步骤s204代入各基元术语程度副词相应的标度值,形成标度向量。基于程度副词与标度值的对应关系,将标度值代入基元术语分布统计表。表格中的内容则形成标度矩阵,其中每一列对应一个样品的标度向量。标度矩阵和标度向量如下所示:(1≤j≤m,1≤i≤n)式中,标度矩阵d为一个m行、n列矩阵,每一行对应一个样品,每一列对应一种基元术语。标度矩阵d中的每一行均为一个样品的标度向量,以d(j)表示;标度矩阵中的每一个元素,以dj,i表示。首先,对标度矩阵d的每一列执行min-max规范化,形成规范化标度矩阵d′。此时规范化标度矩阵中的每一行均为一个规范化标度向量,以d′(j)表示。上述过程如式(4-5)所示:其次,对规范化标度向量d′(j)(标度矩阵d′中的每一行)、术语权重向量w及褒贬系数向量s逐元素相乘,所得的哈达玛积形成评语矩阵,以x表示。此时,评语矩阵x中的每一行均为一个样品的评语向量,以x(j)表示;评语矩阵中的每一个元素,以xj,i表示。上述处理过程如式(6-7)所示:x=d′⊙(s·j1,m)t⊙(w·j1,m)t(6)最后,步骤s205至s208是基于评语向量的聚类与品质级别判断。如下s1至s3步骤所示。s1,从加权评语矩阵中提取。提取评语矩阵x中各维度的最大值和最小值作为最大值评语向量和最小值评语向量,分别以xmax和xmin表示。上述处理过程如式(8-9)所示:s2-1,按余弦相似度计算相似度。分别计算各个样品评语向量x(j)与最大值和最小值评语向量的余弦相似度,以cmax,j和cmin,j表示。将各个样品与最大值和最小值评语向量的余弦相似度值分别组成向量,以cmax和cmin表示;其中,相似度值的排列顺序与评语矩阵中样品的排序一致。上述处理过程如式(10-13)所示:cmax:=[cmax,1…cmax,j…cmax,m]t(12)cmin:=[cmin,1…cmin,j…cmin,m]t(13)或者,s2-2按杰卡德系数公式计算相似度。采用单位阶跃函数f(x)将评语矩阵x、最大值评语向量xmax和最小值评语向量xmin转换为仅包含0和1的矩阵x′、向量x′max和x′min。上述处理过程如式(14-17)所示:x′=f(x)(15)x′max=f(xmax)(16)x′min=f(xmin)(17)矩阵x′中的每一行对应一个样品信息的向量,以x′(j)表示。分别计算各个样品向量x′(j)与向量x′max和x′min的杰卡德系数,以jmax,j和jmin,j表示。将各个样品的杰卡德系数jmax,j和jmin,j分别组成向量,以jmax和jmin表示;其中,杰卡德系数的排列顺序与评语矩阵中样品的排序一致。上述处理过程如式(18-22)所示:jmax:=[jmax,1…jmax,j…jmax,m]t(21)jmin:=[jmin,1…jmin,j…jmin,m]t(22)s3,样品聚类并判定优劣。进一步的,步骤s208给本批次样品的感官品质分级。将cmax、cmin、jmax和jmin连接成矩阵t,矩阵的每一行对应一个样品的相似度特征向量,以t(j)表示。此时,将矩阵作为一个数据集,每一个特征向量作为一个输入变量,以{t(1),…,t(j),…,t(m))表示。此外,确定样品分级的级别数量,以k表示。基于数据集{t(1),…,t(j),…,t(m)},执行实施k-均值聚类,k-均值聚类的参数设定如下:聚类簇数为k,初始化中心点方法采用“k-means++”的方法,k-均值聚类重复执行次数为50,单次k-均值聚类最大迭代次数为500。判断各个类的品质优劣,按公式(24)定义各个样品的样品得分,以r表示。将各个样品的样品得分组成向量,以r表示;其中,样品得分的排列顺序与评语矩阵中样品的排序一致。rj:=(cmax,j+jmax,j)-(cmin,j+jmin,j)(24)r:=[r1…rj…rm]t(25)根据k-均值分类结果,计算每个簇中所有样品得分的平均值。以样品得分的平均值由高至低对簇进行排序。样品得分值越大,代表簇中样品品质越好,级别越高;相反,样品得分值越小,代表簇中样品品质越差,级别越低。由于可以比较好地量化度量样品与样品间的差异,因此可以做到基于样品间的差异区分样品,对茶叶样品的分级完成。综上,本发明采用以“基元术语”为元素、以“程度副词”为大小的方法将审评评语转化为可用于比较的评语向量,减少了转化过程中评语信息的损失,确保多数审评信息都能直接贡献于样品间比较;采用样品评语向量与最值向量间的余弦相似度和/或杰卡德相似系数开展聚类,综合利用了审评评语中的描述感官品质类别和强度的信息,有利于挖掘样品间的品质差异信息,提高分级的准确性。本发明可实现基于茶叶间审评结果差异的分级,过程中无须茶叶分级实物标准样的参与。图3为本发明一种基于审评评语的茶叶感官品质的比较方法的第二实施例流程图。s301:按预设的感官审评类目,定义评语词及其相应的赋值;所述感官审评类目包括滋味、香气、干茶外形、汤色、叶底当中的至少一项。其中所述评语词包括基元术语、程度副词,所述基元术语的相应赋值包括权重系数和褒贬义系数,所述程度副词的相应赋值包括标度值;s302:由本批次各项样品的评语所包含的基元术语的权重系数、程度副词的标度值,分别设定本批次的术语权重向量和标度向量;s303:由本批次各项样品的评语所包含的基元术语的褒贬义系数,设定本批次的褒贬系数向量;s304:获取术语权重向量、标度向量、褒贬系数向量的哈达玛积作为评语向量。s305:根据本批次各项样品的评语向量,提取最值评语向量;再根据评语向量和最值评语向量,计算最大相似度和最小相似度;具体地,根据本批次各项样品的评语向量,按预设方法提取评语向量间各维度的最大值和最小值作为最大值评语向量和最小值评语向量;再根据所述评语向量和所述最大值评语向量、所述最小值评语向量,按预设的相似度公式计算最大相似度和最小相似度。s306:基于所述最大相似度和所述最小相似度,计算各项样品的样品得分;s307:由所述样品得分的大小,判断各项样品的感官品质的优劣;s308:基于所述最大相似度和所述最小相似度,计算各项样品的特征向量;按预设的聚类方法及参数,对所述各项样品的特征向量实施聚类分组;根据各分组内的样品得分的平均值的大小,给本批次样品的感官品质分级。s309:由所述样品得分的大小,给各项样品的感官品质的优劣排序。为了更好的说明本发明的实现方案,以下基于乌龙茶的感官审评结果对样品执行分类。(1)确定实施比较的乌龙茶样品共19个,将它们归为一个分析批次,各个样品的审评评语如下表1:表1茶样感官审评评语(2)基于19个样品的审评评语中提取出33个对应单一感官品质的基元术语。其中,干茶外形的“褐(乌/深/黄褐)”和汤色的“橙黄”在语意上无褒贬,其褒贬义系数设置为0,即在后续方法执行中不影响相似度、得分和分类计算,因此被排除,未见于表格。表2基元术语归纳表及术语对应的褒贬义系数和权重系数表2(续)基元术语归纳表及术语对应的褒贬系数和权重系数表2(续)基元术语归纳表及术语对应的褒贬系数和权重系数由表2数据可知,基元术语的褒贬系数向量s和术语权重向量w分别为:(3)从19个样品中统计各个基元术语在样品中的分布情况,结果如下表所示:表3各个样品评语中基元术语的分布表注:“-”表示样品审评结果中无相关基元术语表3(续)各个样品评语中基元术语的分布表注:“-”表示样品审评结果中无相关基元术语表3(续)各个样品评语中基元术语的分布表注:“-”表示样品审评结果中无相关基元术语(4)基于各个基元术语在样品间的分布情况,统计修饰基元术语程度副词的种类,并以程度副词修饰强度“由弱至强”的次序排列。随后定义程度副词与标度值的对应关系,具体如下表4所示。表4程度副词与标度值的对应关系表4(续)程度副词与标度值的对应关系表4(续)程度副词与标度值的对应关系(5)根据程度副词与标度值的关系,各个样品中的基元术语替换为标度值,形成标度向量。表5中每一行代表一个样品的标度向量。表5标度值取代后各个样品评语中基元术语的分布表表5(续)赋值取代后各个样品评语中基元术语的分布表由表5可知,标度矩阵和标度向量如下:(6)标度矩阵的每一列执行min-max规范化,形成规范化标度矩阵:(7)对规范化标度矩阵附加褒贬义系数和术语权重系数,形成评语矩阵。(8)从评语矩阵中提取“最大值评语向量”和“最小值评语向量”。两个向量分别如下:(9)计算样品评语向量与最值评语向量间的余弦相似度。(10)计算样品评语向量与最值评语向量间的杰卡德系数。需要补充说明的是,评语向量的差异主要体现在向量方向和有效长度(非0维度数量)两方面。余弦相似度可度量向量的方向差异,杰卡德系数可度量向量有效长度的差异。于是,优先选用这两种相似度计算方法。其他,可用于此处的相似度或距离度量方法还有:(1)欧氏距离、(2)汉明距离和(3)皮尔逊相关系数。(11)基于各个样品评语向量与最值评语向量间的余弦相似度和杰卡德系数实施k-均值聚类。k-均值聚类的参数设定如下:聚类簇数为3,初始化中心点方法采用“k-means++”的方法,k-均值聚类重复执行次数为50,单次k-均值聚类最大迭代次数为500。(12)基于k-均值聚类结果,计算各个聚类样品的平均样品得分。将样品分类按评价得分从高到低排序,并确定各个分类中样品的级别。(13)完成分级,乌龙茶样本被分为3个级别,结果如下表6:表6乌龙茶样本分级及排序结果需要补充说明的是,仅采用余弦相似度公式计算各项样品的样品得分的结果如下表6-1所示:表6-1基于余弦相似度的乌龙茶样本分级及排序结果由以上样品得分的大小,判断任意两个样品的感官品质的优劣比较。进一步的,仅基于余弦相似度执行k-均值聚类分组,聚类簇数为3,可将本批次茶叶分为如表6-1所示的三组,以实线分隔。其中,按各组内的样品得分的平均值可以实现优劣分级,如表6-1所示的1-3三个级别。进一步的,按其中一组内的样品得分排序,可实现各样品的优劣排序。以及,仅采用杰卡德系数相似度公式计算各项样品的样品得分的分类结果,见表6-2。表6-2基于杰卡德系数的乌龙茶样本分级及排序结果由以上样品得分的大小,判断任意两个样品的感官品质的优劣比较。进一步的,仅基于杰卡德系数相似度执行k-均值聚类分组,聚类簇数为3,可将本批次茶叶分为如表6-2所示的三组,以实线分隔。其中,按各组内的样品得分的平均值可以实现优劣分级,如表6-2所示的1-3三个级别。进一步的,按其中一组内的样品得分排序,可实现各样品的优劣排序。需要补充说明的是,上述基于“余弦相似度”、“杰卡德系数”以及“余弦相似度和杰卡德系数”分类效果的性能度量。采用davies-bouldin指数度量分类效果的好坏,该指数数值越小代表分类效果越好。可见,基于“余弦相似度和杰卡德系数”的分类效果最好,见表7:表7davies-bouldin指数对比实施例davies-bouldin指数基于余弦相似度,见表6-10.734基于杰卡德系数,见表6-20.603基于余弦相似度和杰卡德系数,见表60.555综上所述,由本实施例可知:样品间相似度的计算可基于余弦相似度公式和/或杰卡德系数公式,或除此以外的一种或多种相似度计算方法;聚类方法及聚类方法参数的设置是可选的;当不需要对样品实施分级或分类时,仅基于样品得分便能对各项样品的感官品质进行优劣排序;当对样品分为3个级别,如本实施例所示时,可将聚类方法的聚类簇数设为3;当对样品分为5个级别,如本实施例所示时,可将聚类方法的聚类簇数设为5,并进一步的,可同时实现各个分级内的各项样品的感官品质的优劣排序。其余聚类参数亦按需设置,不再一一赘述。故此,本发明可实现茶叶样品感官品质的优劣比较,分级,以及排序,且比较结果稳定、准确。图4为本发明一种基于审评评语的茶叶感官品质的比较系统的示意图,包括:词库单元,用于预设评语词及其相应的赋值,其中所述评语词包括基元术语、程度副词,所述基元术语的相应赋值包括权重系数,所述程度副词的相应赋值包括标度值;向量转化单元,用于由本批次各项样品的评语所包含的基元术语的权重系数、程度副词的标度值,分别设定本批次的术语权重向量和标度向量;评语向量单元,用于获取术语权重向量和标度向量的哈达玛积作为评语向量;相似度计算单元,用于根据本批次各项样品的评语向量,按预设方法提取评语向量间各维度的最大值和最小值作为最大值评语向量和最小值评语向量;再根据所述评语向量和所述最大值评语向量、所述最小值评语向量,按预设的相似度公式计算最大相似度和最小相似度;得分计算单元,用于基于所述最大相似度和所述最小相似度,计算各项样品的样品得分;结果判断单元,用于由所述样品得分的大小,判断各项样品的感官品质的优劣。图5为本发明一种基于审评评语的茶叶感官品质的比较系统的第一实施例示意图。如图5所示的实施例中,所述词库单元,包括:赋值设置子单元;所述赋值设置子单元,用于预设评语词及其相应的赋值,其中所述评语词包括基元术语、程度副词,所述基元术语的相应赋值包括权重系数和褒贬义系数,所述程度副词的相应赋值包括标度值;所述向量转化单元,还用于由本批次各项样品的评语所包含的基元术语的褒贬义系数,设定本批次的褒贬系数向量;所述评语向量单元,还用于获取术语权重向量、标度向量、褒贬系数向量的哈达玛积作为评语向量。如图5所示的实施例中,所述相似度计算单元,包括:公式设置子单元,用于按余弦相似度和/或杰卡德系数公式计算最大相似度和最小相似度。如图5所示的实施例中,所述结果判断单元,包括:分级子单元;其中,所述分级子单元,用于基于所述最大相似度和所述最小相似度,计算各项样品的特征向量;按预设的聚类方法及参数,对所述各项样品的特征向量实施聚类分组;根据各分组内的样品得分的平均值的大小,给本批次样品的感官品质分级。图6为本发明一种基于审评评语的茶叶感官品质的比较系统的第二实施例示意图。如图6所示的实施例中,所述词库单元,包括:类目设置子单元;所述类目设置子单元,用于按预设的感官审评类目,定义评语词及其相应的赋值;所述感官审评类目包括滋味、香气、干茶外形、汤色、叶底当中的至少一项。如图6所示的实施例中,所述结果判断单元,包括:排序子单元;其中,所述排序子单元,用于由所述样品得分的大小,给各项样品的感官品质的优劣排序。以上一种基于审评评语的茶叶感官品质的比较系统与前述方法一一对应,相应的说明如前所示,不再一一赘述。以上实施例的目的,是对本发明的技术方案进行示例性的再现与推导,并以此完整的描述本发明的技术方案、目的及效果,其目的是使公众对本发明的公开内容的理解更加透彻、全面,并不以此限定本发明的保护范围。以上实施例也并非是基于本发明的穷尽性列举,在此之外,还可以存在多个未列出的其他实施方式。在不违反本发明构思的基础上所作的任何替换与改进,均属本发明的保护范围。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1