一种GSA-MLs相结合的小麦LAI估算方法
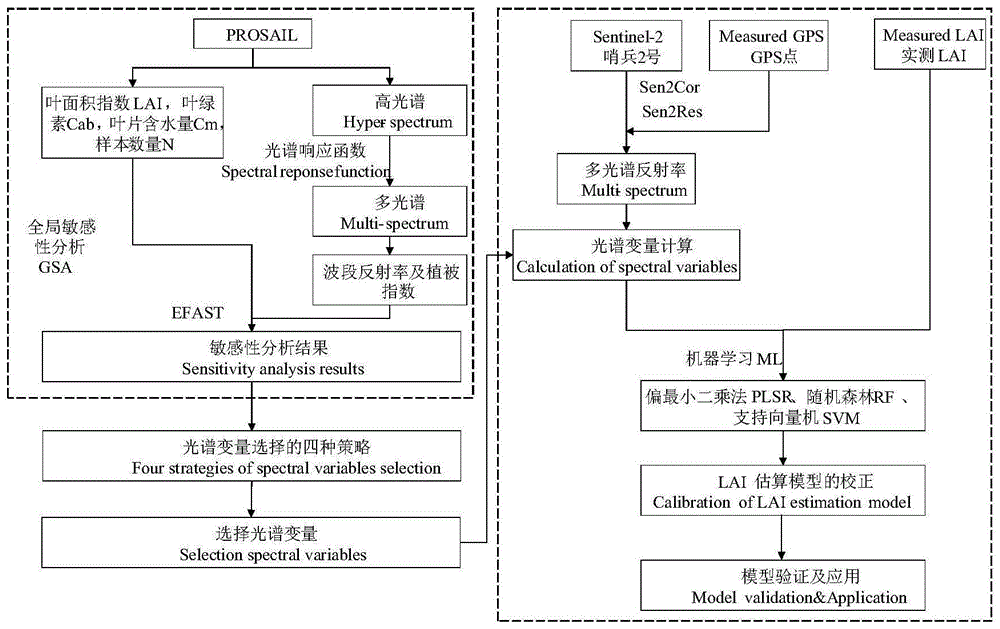
本申请属于作物叶面积指数反演方法
技术领域:
,尤其是涉及一种结合全局敏感性分析与机器学习的小麦lai估算方法。
背景技术:
:叶面积指数(lai)是冬小麦生长指标监测过程中重要的冠层结构参数,也是冬小麦估产模型中重要的输入参数。传统lai测量方法依赖于人工定点观察或仪器测量,效率低下且耗费人力、物力、财力,难以应用于大面积的冬小麦生长监测。随着对地观测技术的发展,富含丰富光谱信息的区域乃至全球尺度的影像获取已经成为可能,为大范围冬小麦lai的估算提供了数据基础。众多卫星平台已经搭载多光谱谱段的传感器,提供可用于提取植被的长势信息的可见光-近红外波段。如landsat8卫星、modis卫星、worldview-2卫星、rapideye卫星等包含可见光-近红外波段或短波红外波段的影像。此外,相关研究表明,红边信息在植被卫星遥感监测过程中具有较大优势(参见dongetal.remotesensingofenvironment,2018,222,133-143)。如worldview-2与rapideye等商业卫星在可见光-近红外波段的基础上均增加了一个红边波段,结果证明在植被生长监测方面具有较好的效果(参见lh,etal.forests,2019,10(2):107)。近几年欧空局发射的sentinel-2卫星因兼具较高空间分辨率和较高时间分辨率,且含有三个红边波段,为大范围的植被生长指标监测提供了诸多可能。在利用遥感影像估算植被lai的过程中,常见的方法有经验或半经验模型、机器学习算法等。其中,经验或半经验模型往往是通过影像的波段反射率构建植被指数,增强植被信息,通过统计回归分析构建lai的估算模型,实现lai的预测;机器学习算法则是基于不同的模型框架,根据训练数据集进行学习,构建lai估算模型,常见的有偏最小二乘法回归、高斯过程回归、支持向量回归、随机森林回归等。基于植被指数的经验或半经验模型通常具有较好的机理性、可操作性强,但易出现病态反演的问题。机器学习算法较强的数据解析能力,能够避免病态反演的问题且具有较高的精度,但模型的机理解释性尚待加强。已有研究通过融合两类算法,在原始波段反射率的基础上,将多个植被指数作为机器学习算法的输入变量,改善植被长势参数的估算模型(参见li,xc,etal..internationaljournalofappliedearthobservationandgeoinformation,2016,44:104-112.)。但是过多输入变量的引入会增加计算负荷,降低大范围lai估算效率,同时数据冗余的风险加大。因此,输入变量的筛选是必要且重要的。虽然部分机器学习算法自带变量筛选的功能,如plsr、rf,但是该筛选功能仅聚焦于输入变量与目标变量之间的相关性。然而,在植被lai的遥感估算方面,植被的光谱表现是一项综合指标,不仅仅受到lai的影响,同时也会受到叶绿素、叶倾角、干物质等其他参数的影响。因此需要具有同时评估多个参数对光谱影响大小的方法来弥补机器学习的不足。利用敏感性分析定量模型的各个输入参数对输出结果影响大小,显得尤为重要。常见的敏感性分析方法有两类,包括全局敏感性分析(gsa,globalsensitivityanalysis)和局部敏感性分析(lsa,localsensitivityanalysis);前者是对所有输入参数评估及分析对最终结果的贡献程度,常见的有扩展傅里叶振幅灵敏度试验(efast,extendedfourieramplitudesensitivitytest)、sobol法等;后者则在保持其他输入变量不变的情况下,逐个分析每个输入变量对输出结果影响的大小。当前,已有学者尝试结合全局敏感性分析与植被辐射传输模型(prosail模型等)开展植被长势参数对光谱变量影响大小的评估,尤其是多个长势参数之间的交互作用影响大小的评估,但是应用sentinel-2卫星结合全局敏感性分析与植被辐射传输模型,并结合机器学习进一步应用于大范围冬小麦lai的估算鲜有报道。技术实现要素:为了提高lai估算的精度和mls的计算效率本发明提供了基于全局敏感性分析(globalsensitivityanalysis,gsa)与mls(简称gsa-mls)相结合的小麦lai估算方法。具体,本发明提供了一种估算小麦叶面积指数(lai)的方法,包括以下步骤:s1:基于prosail模型模拟数据集,利用全局敏感性分析(gsa)量化不同光谱变量对植被生长参数的响应情况;s2:基于不同光谱变量对植被生长参数响应的一阶灵敏度,利用slai、slai+scab、slai-sinteraction和slai+scab-sinteraction策略筛选出对lai敏感性高且对其他参数敏感性低的光谱变量,作为最优变量;s3:选择最优变量作为机器学习算法(mls)的输入参数;s4:用mls整合筛选得到的光谱变量结合地面实测小麦lai建立小麦lai估算模型;s5:通过计算决定系数和均方根误差(rmse)衡量不同光谱变量、不同机器学习法估算小麦lai的模型构建精度;s6:通过最佳估算方法绘制了研究区lai的分布图;其中,slai是指仅根据lai的敏感性分析结果slai的大小进行光谱变量筛选;slai+scab是指同时考虑lai与cab两者敏感性的总和;slai-sinteraction是指同时考虑高lai敏感性与低交叉互作影响;slai+scab-sinteraction是指同时考虑高lai敏感性、高cab敏感性与低交叉互作影响。优选地,上述方法中,s1所述光谱变量是采用sentinel-2多光谱影像数据,通过获取sentinel-2影像数据经辐射定标与大气校正,然后利用sen2res1.0将sentinel-2影像中20m空间分辨率的波段降尺度至10m得到。更进一步的,获取的sentinel-2影像数据经过官方发布的sen2cor2.5.5进行辐射定标与大气校正。随后利用sen2res1.0将sentinel-2影像中20m空间分辨率的波段降尺度至10m。sentinel-2包含两颗卫星,分别是2015年发射的sentinel-2a与2017年发射的sentinel-2b,两者均搭载多光谱传感器,能够获取具有13个不同空间分辨率波段的多光谱影像。s1所述prosail模型设置的参数包括:结构系数,叶绿素含量,类胡萝卜素含量、等效水厚度、褐色素的含量、平均叶倾角、叶面积指数、热点、土壤亮度指数、太阳天顶角、观察者天顶角以及方位;参数在确定范围后经马尔科夫链-蒙特卡罗方法(mcmc)进行采样。进一步的,s1所述植被生长参数包括基于可见光-近红外构建的非红边植被指数,例如ndvi、rvi、dvi、gdvi、grvi、gndvi、evi、savi、cig等,加入红边波段后的红边植被指数,例如ndre、rervi、redvi、regdvi、regrvi、regndvi、mevi、sare、cired-edge等,以及基于短波红外波段构建的植被指数,例如ndwi、msi等。由于上述红边植被指数与短波红外相关的植被指数均只涉及一个红边波段或一个短波红外波段,而sentinel-2影像具有三个红边波段与两个短波红外波段,因此,优选地,在计算红边植被指数与短波红外相关植被指数过程中,所述的红边植被指数分别用sentinel-2的三个红边波段构建三次,而所有基于短波红外波段构建的植被指数分别用sentinel-2的两个短波红外波段构建两次。本发明所述的植被指数计算公式可以为本领域已知的计算公式,例如文献tuckercj.remotesensingandenvironment,1979,8(2):127-150;sims,da等.remotesensingofenvironment,2002,81(2):337-354;maik,b等.sensors,2019,19(24):5397;vincinim,frazzie等.precisionagriculture,2009;jordancf等ecology,1969,50(4):663-666;buschmannc等.internationaljournalofremotesensing,1993,14(4):711-722等公开的ndvi、ndre、rvi、rervi、dvi、redvi、gdvi、regdvi、grvi等植被指数的计算公式,这些文献公开的内容通过引用结合到本发明中。上述方法中,优选地,s1所述全局敏感性分析的方法包括efast、sobol和mirror,优选地为efast。进一步的,s2所述最优变量是基于gsa所得不同光谱变量对植被生长参数响应的一阶灵敏度(firstordersensitivity)结果(sparamete)利用slai、slai+scab、slai-sinteraction和slai+scab-sinteraction四种变量排序的策略,进行光谱变量的排序,分别筛选前10、20与30个光谱变量作为机器学习算法的输入变量。进一步的,s3所述机器学习算法包括采用偏最小二乘法(plsr)、支持向量(svm)和随机森林(rf)算法建立冬小麦lai估算模型。其中,偏最小二乘法(partialleastsquaresregression,plsr)综合了多元回归分析、典型相关分析和主成分分析的思想,能够在自变量存在严重多重相关性、样本点个数少于变量个数的条件下进行回归建模。支持向量机(supportvectormachine,svm)是一种以非线性映射为理论基础的小样本机器学习方法。它避开了从归纳到演绎的传统过程,实现了从训练样本到预测样本的高效“转导推理”。径向基核函数被认为是具有良好分类功能,是最常用的核函数。本发明选用svr_epsilon模型、高斯径向基核函数(rbf),通过调节拉格朗日乘上界,不敏感损失函数的参数、相对误差参数,实现模型最优解。svr中的参数用交叉验证法获得,同时为防止“过学习”,对参数c进行适当调整。随机森林算法(randomforests,rf)模型是建立在决策树基础上的一种集成学习方法,通过多次bootstrap抽样获得多个随机样本,并通过这些样本分别建立相对应的决策树,从而构成随机森林。进一步的,s5所述决定系数和均方根误差(rmse)的计算公式为:其中,n表示样本数;χi表示第i个样本光谱变量的值;表示所有光谱变量的平均值;υi表示第i个样本的目标值,即lai值;表示所有目标是的平均值,即所有lai的平均值;其中,n表示样本数,laip,i、laim,i分别表示lai的预测值、lai的实测值。进一步的,s6所述最佳估算方法为通过slai+scab-sinteraction策略进行光谱变量排序,通过rf估算小麦lai。术语解释:lai:小麦叶面积指数;mls:机器学习算法gsa:全局敏感性分析(globalsensitivityanalysis)plsr:偏最小二乘回归;svm:支持向量机;rf:随机森林;gsa-mls方法:全局敏感性分析与机器学习算法相结合的方法。本发明提出了结合全局敏感性分析与机器学习提高小麦lai估算精度、效率的方法(gsa-ml)。首先进行光谱变量的筛选,在提高机器学习法估算lai精度以及应用过程中计算机计算效率的同时,提高了机器学习应用过程中的机理性。综合对比lai估算精度、计算机运行效率,结果显示gsa-rf具有最佳的表现。本发明运用prosail模型进行全局敏感性分析,不仅能够考虑目标参数对光谱变量的影响,还能将目标参数以外其他参数以及不同参数之间交互作用影响纳入考虑。既能获取单个参数对模型输出变量的敏感性,也能获取参数单独作用及其与其他参数之间的交互作用对模型输出变量的敏感性。本发明提供的gsa-ml,利用全局敏感性分析综合评估现有的、敏感于lai的光谱变量,通过四种不同的策略(slai、slai+scab、slai-sinteraction和slai+scab-sinteraction)筛选出对lai敏感性高且对其他参数敏感性低的光谱变量,而后用机器学习法整合筛选得到的光谱变量来估算小麦lai。试验证明,本发明选用的光谱变量大部分对lai具有较好的敏感性。通过对比四种不同的光谱变量筛选策略以及不同机器学习法在lai估算方面的表现,结果显示,相对于51个光谱变量的运行时间缩短了54.13%,有效地避免了数据冗余造成的精度影响与计算效率低的风险。本发明提供的gsa-ml不仅适用于卫星平台,还适用于无人机与地面平台,尤其是普遍面临数据冗余风险的地面高光谱平台。附图说明下面结合附图和实施例对本申请的技术方案进一步说明。图1是利用gsa-ml估算小麦lai的方法的流程图;图2是本发明实施例研究区及地面调查样点分布图;图3是不同光谱变量全局敏感性分析结果图;图4是在冬小麦lai估算方面表现最佳的gsa-plsr(a)、gsa-svm(b)和gsa-rf(c)图。图5是由gsa-rf生成的小麦lai图。具体实施方式以下结合具体实施例对本发明的技术方案以及有益效果做进一步说明,应当理解的是,在不冲突的情况下,本发明中的实施例及实施例中的特征可以相互组合。实施例1、研究区域本实施例以研究区位于江苏省高邮与姜堰地区为例(如图2)。该区域的年均温度在15℃左右,年均降水量在1032.3mm左右,土壤类型主要为壤土,研究区内冬小麦为扬麦158,在2017年10月下旬播种,于2018年6月成熟收获。试验于2018年4月19日开展,选择了46个冬小麦田样点作为地面调查的对象,该田块为稻麦轮作与秸秆还田,且是在低机械化的条件下播种,甚至人工播种。2、sentinel-2影像获取及预处理:sentinel-2包含两颗卫星,分别是2015年发射的sentinel-2a与2017年发射的sentinel-2b,两者均搭载多光谱传感器,能够获取具有13个不同空间分辨率波段的多光谱影像,波段信息如表1所示。本实施例根据地面采样时间获取2018年4月19日的sentinel-2卫星影像,获取的sentinel-2影像数据经过官方发布的sen2cor2.5.5进行辐射定标与大气校正。随后利用sen2res1.0将sentinel-2影像中20m空间分辨率的波段降尺度至10m。本实施例究尚未涉及用于大气成分监测且分辨率为60m的三个波段,包括b1、b9、b10。表1sentinel-2波段信息bands中心波长(nm)空间分辨率b1-coastalaerosol44360b2-blue49010b3-green56010b4-red66510b5-rededge(re-1)70520b6-rededge(re-2)74020b7-rededge(re-3)78320b8-nir84210b8a-narrownir(nnir)86520b9-watervapour94560b10-swir-cirrus138060b11-swir-1161020b12-swir-22190203、小麦lai估算方法在prosail模型的基础上引入gsa,测试不同光谱变量对不同作物长势参数的响应情况,然后在gsa所得结果的基础上采用四种变量筛选的策略并将筛选得到的光谱变量应用于实测数据,作为机器学习估算小麦lai过程中的输入变量,形成了用于小麦lai估算方法,即gsa-ml,具体流程如图1所示。(1)、prosail模型模拟数据为了定量不同长势参数对同一光谱变量影响大小并筛选出用于lai估算的敏感变量,利用prosail模型进行数据模拟。其中,模型输入参数的设置如表2所示。prosail模型中的参数在确定范围后经马尔科夫链-蒙特卡罗方法(mcmc)进行采样,总计获取8000个样本,用于后面efast的敏感性计算。表2prosail模型的参数设置参数单位范围μ±σ结构系数(n)\1.3~1.71.5±0.1155叶绿素含量(cab)ug·cm-220~7045±14.4338类胡萝卜素含量(car)ug·cm-2cab/4\等效水厚度(cw)cm0.001~0.10.0505±0.0286lma(cm)g·cm-20.003~0.0110.007±0.0023褐色素的含量(cbp)\0.05\平均叶倾角(lidfa)度35~7052.5±10.1031叶面积指数(lai)m2/m20.1~9.04.5501±2.5691热点(hspot)\0.05~0.50.275±0.1299土壤亮度指数(psi)\0~10.5±0.2887太阳天顶角(tts)度25\观察者天顶角(tto)度30\方位(psi)度45\(2)植被指数用于植被lai估算的植被指数,包括ndvi、rvi、dvi、gdvi、grvi、gndvi、evi、savi、cig等基于可见光-近红外构建的非红边植被指数、ndre、rervi、redvi、regdvi、regrvi、regndvi、mevi、sare、cired-edge等加入红边波段后的红边植被指数以及ndwi、msi等基于短波红外波段构建的植被指数。在计算红边植被指数与短波红外相关植被指数过程中,所有的红边植被指数分别用sentinel-2的三个红边波段构建三次,所有基于短波红外波段构建的植被指数分别用sentinel-2的两个短波红外波段构建两次。表3用于估算小麦lai的植被指数(3)全局敏感性分析筛选光谱变量策略首先基于prosail模型模拟数据,利用全局敏感性分析中的efast比较不同光谱变量对不同长势参数响应的敏感性分析。其中,马尔科夫链-蒙特卡罗方法被用于模型输入样本的生成,根据表2中各输入参数的范围与模型设置的采样参数n进行采样(本实施例中设置n=1000),总计获取8000个样本用于不同光谱变量对各参数响应的敏感性分析。然后,基于efast所得不同光谱变量对各参数响应的一阶灵敏度(firstordersensitivity)结果(sparamete),利用以下四种不同策略进行机器学习输入变量的排序,分别为:策略一:仅根据lai的敏感性分析结果slai的大小进行光谱变量筛选;策略二:同时考虑lai与cab两者敏感性的总和,根据slai+scab的大小进行光谱变量筛选;策略三:同时考虑高lai敏感性与低交叉互作影响,根据slai-sinteraction进行光谱变量;策略四:为避免参数之间的交叉互作影响,同时考虑高lai敏感性、高cab敏感性与低交叉互作影响,根据slai+scab-sinteraction进行光谱变量的排序。根据以上四种变量筛选策略,分别筛选前10、20、30个变量用于机器学习估算小麦lai,并对比不同策略估算小麦lai的精度以及影像应用过程中计算机的计算速度。本实施例基于python3.7环境下的sklearn构建机器学习算法,计算机型号为联想thinkstationp520,操作系统为windows10,其gpu为nvidiaquadrop6000(32gb),cpu为inter(r)xeon(r)w-2125cpu(32gb)。(4)机器学习偏最小二乘法(partialleastsquaresregression,plsr)综合了多元回归分析、典型相关分析和主成分分析的思想,能够在自变量存在严重多重相关性、样本点个数少于变量个数的条件下进行回归建模。基于plsr建立的lai光谱预测模型能有效地减少光谱维数,揭示最大lai变化的主控因子,建立模型有更好的稳定性。支持向量机(supportvectormachine,svm)是一种以非线性映射为理论基础的小样本机器学习方法。它避开了从归纳到演绎的传统过程,实现了从训练样本到预测样本的高效“转导推理”本申请选用svr_epsilon模型、高斯径向基核函数(rbf),通过调节拉格朗日乘上界,不敏感损失函数的参数、相对误差参数,实现模型最优解。svr中的参数用交叉验证法获得,同时为防止“过学习”,对参数c进行适当调整。随机森林算法(randomforests,rf)模型是建立在决策树基础上的一种集成学习方法,通过多次bootstrap抽样获得多个随机样本,并通过这些样本分别建立相对应的决策树,从而构成随机森林。rf是通过随机采样点方式进行数据训练,因此能够有效避免过拟合,在对组分进行高效预测。本实施例应用python中scikitlearn库建立随机森林模型,回归树数量ntree为600,每棵树随机抽取特征变量mtry为6,其余参数选择默认设置。(5)模型构建及精度评估利用2017-2018年地面实测数据进行模型的构建,通过计算决定系数和均方根误差(rmse)来衡量不同光谱变量、不同机器学习法估算小麦lai的模型构建精度,具体公式如下:其中,n表示样本数;χi表示第i个样本光谱变量的值;表示所有光谱变量的平均值;υi表示第i个样本的目标值,即lai值;表示所有目标是的平均值,即所有lai的平均值;其中,n表示样本数,laip,i、laim,i分别表示lai的预测值、lai的实测值。4、试验结果:(1)不同光谱变量估算小麦lai的表现从相关性分析结果表4看,在各波段与lai相关性中,红波段r、红边波段re1、re2以及近红外nir、nnir波段光谱反射率与lai具有显著相关性,且五个波段的相关系数大都高于0.450,说明红边波段及近红外波段在冬小麦长势监测中具有很好的有效性。同时相关性最高的为近红外nir波段,相关系数为0.643,rmse为0.979。大部分植被指数与lai具有很强的相关,其中相关系数均高于0.500的植被指数有10个,分别为sare2、ndre2、redvi2、gdvi、cire2、rervi2、cig、grvi、gndvi、savi、rvi、mtvi2,其中sare2最佳,相关系数为0.707,其次为ndre2,相关系数为0.681。由于re-2相对于其他两个红边波段(包括re-1,re-3)位于红边区域的中心,大多数由re-2构建的红边植被指数相对于无红边波段或由其他红边波段构建植被指数具有对lai更高的敏感性。另外,ndre相较于ndvi来说,可以克服在高lai值下的饱和问题,同时对作物叶片水分和叶绿素含量表现出较弱的敏感性。总体来看,加入红边波段的植被指数与传统近红外植被指数相比,相关性表现出微弱的提升。表4、单波段反射率及植被指数与lai相关性(2)不同光谱变量全局敏感性分析的结果利用efast测试了prosail模型中不同作物长势参数对sentinel-2多光谱信息的影响情况,包括原始的波段反射率及其衍生出的多个植被指数,如图3所示。结果显示,大多数光谱变量都敏感于lai,但是受到其他参数不同程度的影响,影响较大的有叶绿素、叶倾角以及参数之间的耦合作用影响。其中,平均叶倾角(lidfa)虽然对红边波段(包括re-1、re-2、re-3)及nir具有明显的影响,但是通过植被指数的构建能够较大程度地降低这类影响;叶绿素(cab)虽然对re-2影响较小,但是植被指数的构建会放大其影响,包括3.1部分所得最佳表现的ndre2与sare2;而由swir波段及其构建的植被指数虽然不受叶倾角与叶绿素的影响,但是会遭受叶片含水量(cw)的影响。综合以上情况,大部分植被指数在估算小麦lai时会遭受其他参数影响,需要机器学习法整合多个变量的lai敏感性来提高小麦lai的估算精度。(3)光谱变量排序结果基于各长势参数对不同光谱变量影响大小的结果,即全局敏感性分析所得一阶灵敏度结果,利用四种变量排序的策略,包括slai、slai+scab、slai-sinteraction和slai+scab-sinteraction,进行光谱变量的排序(表5),并分别筛选前10、20与30个光谱变量作为不同机器学习法(plsr、svm、rf)的输入变量,对比lai估算的精度与机器学习法运算的效率。结果显示,在不考虑cab的(strategy1和strategy3)情况下,由于g、re-1、re-2波段构建的植被指数遭受cab的影响具有较低的lai敏感性未排列在前列,而大部分非红边植被指数由于遭受到的cab影响较小排在前列(图4);在同时考虑cab与lai敏感性(strategy2和strategy4)的情况下,部分由re-2构建红边植被指数排在前列。值得注意的是,这两个策略排列与筛选得到的光谱变量组合在通过机器学习估算lai过程中存在受植被叶绿素影响造成模型精度或普适性低的风险;除了参数各自敏感性影响外,参数之间的交互影响也是降低lai估算模型精度低的一大原因。因此,本研究进一步考虑低参数互作影响(strategy3和strategy4)的情况。另外,在四种筛选策略中,由g波段构建的mtvi2表现较为稳定,这是因为它能够有效地降低cab的影响并保留lai的敏感性,然而在lai估算过程中存在估算精度不如红边植被指数的表现(表4)。表5不同策略光谱变量排序结果(4)不同机器学习估算小麦lai的变现根据上述四种筛选策略的排序结果,选择前10、20、30个光谱变量作为机器学习法的输入变量,结合地面实测小麦lai,分别采用偏最小二乘法(plsr)、支持向量(svm)和随机森林(rf)算法建立冬小麦lai估算模型,结果如表6所示。在不同gsa-ml对比方面,gsa-svm,gsa-rf整体表现效果最佳,r2=0.900~0.940,rmse=0.380~0.480;在不同变量筛选策略对比方面,由于同时考虑了lai、cab以及植被长势参数之间耦合作用影响,通过slai+scab-sinteraction策略进行光谱变量排序与筛选更有利于lai的估算,其中通过rf估算小麦lai表现最佳,在利用10、20、30个变量的表现分别为r2=0.920,rmse=0.420、r2=0.920,rmse=0.420与r2=0.94,rmse=0.38;同ml对比,gsa-ml能过通过更少的输入变量来得到相似的lai估算效果,提高机器学习运行过程中计算机的计算效率。表6冬小麦lai估算模型对比表7mls法估算小麦lai的比较mlr2rmseplsr0.810.31svm0.411.06rf0.920.40应用例:基于上述对比结果,综合考虑lai的估算精度与计算机运算效率,选用了变量数为10的三种gsa-ml进行进一步的对比。利用所有变量和基于全局敏感性分析获取的策略slai+scab-sinteraction中的变量,分别训练机器学习模型,对保存的模型进行预测时间评估。选取研究区内一幅大小为2000×2000像素的影像,分别针对应用不同模型计算预测所需要的时间,如表8所示。未进行全局敏感性分析,参与计算的变量较多,增加了计算时间,其中plsr需要487.772s,而进行敏感性分析筛选后,计算时间节省了一般,同时gsa-svm和gsa-rf与此类似,均节省了一半的时间。表8不同估算模型应用过程中的计算机运行时间(s)进一步将lai估算方面表现最佳的模型(rf)应用姜堰地区,基于4748×4231像素的sentinel-2影像,绘制lai的空间分布(图5),期间机器学习的计算时长为618.920s。所得lai的空间分布均处于合理值范围,且同实际生产具有一致性,说明本发明提供的方法在应用过程中具有可行性。以上述依据本申请的理想实施例为启示,通过上述的说明内容,相关工作人员完全可以在不偏离本项申请技术思想的范围内,进行多样的变更以及修改。本项申请的技术性范围并不局限于说明书上的内容,必须要根据权利要求范围来确定其技术性范围。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1