一种基于企业特征预测中标概率的方法及装置与流程
本发明涉及到机器学习的技术领域,特别是涉及到一种基于企业特征预测中标概率的方法、装置、计算机设备和存储介质。
背景技术:
招标投标是在市场经济条件下进行的大宗货物的买卖、工程建设项目有发包与承包以及服务项目的采购与提供时所采用的一种交易方式。通常通过招标人发出招标单邀请投标人参加投标,但往往参与投标的投标人比较多,而中标的只有一个名额,竞争比较激烈,故而投标人通常会尽量收集对手的资料,基于对手资料进行预测以及评估自己的中标概率,进而改善自己的投标方案,目前的中标预测通常都是基于企业相关信息进行人力分析,不但耗时耗力效率低,而且准确率也不高。
技术实现要素:
本发明的主要目的为提供一种基于企业特征预测中标概率的方法、装置、计算机设备和存储介质,旨在解决现有技术中中标预测方法效率低的技术问题。
基于上述发明目的,本发明提出一种基于企业特征预测中标概率的方法,包括:
获取待测企业的当前的投标信息以及企业信息,所述企业信息包括历史投标记录以及企业资质信息;
从所述投标信息以及所述企业信息中提取所述待测企业的指定企业特征;
将所述指定企业特征输入至预设的预测模型进行计算,得到预测结果,所述预测模型基于gbdt以及lr构建训练而成,所述预测结果为所述待测企业当前投标的中标概率。
进一步地,所述预测模型包括gbdt模块以及lr模块,所述将所述指定企业特征输入至预设的预测模型进行预测,得到预测结果的步骤,包括:
将所述指定企业特征输入所述gbdt模块中,遍历所述gbdt模块每个决策树,得到一组离散的特征组合;
将所述特征组合进行转换得到相应的指定编码;
将所述指定编码传入所述lr模块进行线性加权预测,得到所述预测结果。
进一步地,所述将所述指定编码传入所述lr模块进行线性加权预测,得到所述预测结果的步骤,包括:
利用以下公式计算出所述预测结果:
y=sigmoid(xtw);
其中,y为所述待测企业的中标概率,x为所述指定编码,w为特征权重。
进一步地,所述预测模型的训练过程包括:
获取多个样本形成样本集,并将所述样本集分为训练集以及测试集,所述样本集中的样本为经过特征选择后的企业特征;
将所述训练集输入预设的初始决策树模型进行训练,以形成所述gbdt模块,并输出新的训练数据;
将所述新的训练数据输入至预设的初始线性分类模型进行训练,得到所述lr模块;
依据所述测试集对所述gbdt模块及lr模块进行测试,得到测试结果;
依据所述测试结果进行调整,以得到所述预测模型。
进一步地,所述获取预设的训练集的步骤,包括:
获取投标企业的多个不同的指定特征;
将所述指定特征分别进行分组,得到多个对应所述指定特征的特征组;
分别计算每个所述特征组内的中标企业占所有中标企业的第一比例,以及分别计算每个所述特征组内非中标企业占所有非中标企业的第二比例;
依据所述特征组内中标企业的数量、所述特征组内非中标企业的数量、所有中标企业的数量、所有非中标企业的数量、第一比例以及第二比例,计算得到所述指定特征的每个所述特征组的证据权重;
依据所述证据权重计算出每个所述特征组的iv值;
依据每个所述特征组的iv值计算出所述指定特征的iv值;
将iv值超过预设阈值的指定特征记为所述企业特征,并将所述企业特征作为所述样本加入所述样本集。
本发明还提供一种基于企业特征预测中标概率的装置,包括:
获取信息单元,用于获取待测企业的当前的投标信息以及企业信息,所述企业信息包括历史投标记录以及企业资质信息;
提取特征单元,用于从所述投标信息以及所述企业信息中提取所述待测企业的指定企业特征;
计算结果单元,用于将所述指定企业特征输入至预设的预测模型进行计算,得到预测结果,所述预测模型基于gbdt以及lr构建训练而成,所述预测结果为所述待测企业当前投标的中标概率。
进一步地,所述预测模型包括gbdt模块以及lr模块,所述计算结果单元,包括:
遍历决树单元,用于将所述指定企业特征输入所述gbdt模块中,遍历所述gbdt模块每个决策树,得到一组离散的特征组合;
转换编码单元,用于将所述特征组合进行转换得到相应的指定编码;
加权预测单元,用于将所述指定编码传入所述lr模块进行线性加权预测,得到所述预测结果。
进一步地,所述加权预测单元包括:
利用以下公式计算出所述预测结果:
y=sigmoid(xtw);
其中,y为所述待测企业的中标概率,x为所述指定编码,w为特征权重。
本发明还提供了一种计算机设备,包括存储器和处理器,所述存储器存储有计算机程序,所述处理器执行所述计算机程序时实现所述的基于企业特征预测中标概率的方法的步骤。
本发明还提供了一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现上述基于企业特征预测中标概率的方法的步骤。
本发明的有益效果为:通过基于gbdt以及lr构建训练而成的预测模型,对投标企业进行预测,只需提取相应的企业特征输入即可直接得到企业中标概率,方便快捷,效率大大提升,且准确率较高。
附图说明
图1为本发明一实施例中基于企业特征预测中标概率的方法的步骤示意图;
图2为本发明一实施例中基于企业特征预测中标概率的装置的结构示意框图;
图3是本申请的存储介质的一实施例的结构示意框图;
图4是本申请的计算机设备的一实施例的结构示意框图。
本发明目的的实现、功能特点及优点将结合实施例,参照附图做进一步说明。
具体实施方式
应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
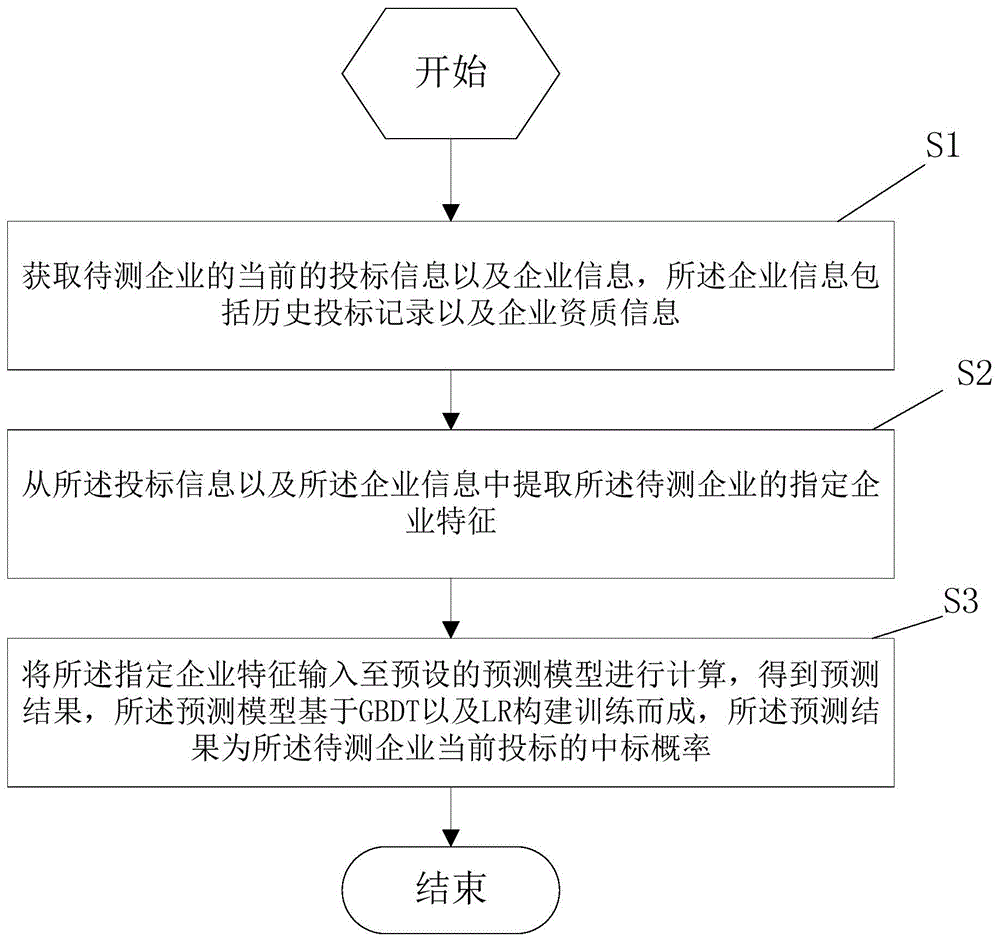
参照图1,本实施例中的基于企业特征预测中标概率的方法,包括:
步骤s1:获取待测企业的当前的投标信息以及企业信息,所述企业信息包括历史投标记录以及企业资质信息;
步骤s2:从所述投标信息以及所述企业信息中提取所述待测企业的指定企业特征;
步骤s3:将所述指定企业特征输入至预设的预测模型进行预测,得到预测结果,所述预测模型基于gbdt以及lr构建训练而成;
步骤s4:依据所述预测结果确定所述待测企业当前投标的中标概率。
如上述步骤s1-s2所述,上述待测企业为准备投标的企业,上述投标信息至少包括投标书中的内容,上述企业信息包括历史投标记录以及企业资质信息,历史投标记录包括该企业曾经每次的投标记录,例如投标哪些项目、投标时间、是否中标、投标书内容等;企业资质信息包括类型、成立日期、经营状态、注册资本、法人等信息。从上述投标信息以及企业信息中提取该待测企业的指定企业特征,例如企业信息中的类型、经营状态、注册资本等。
如上述步骤s3所述,上述指定企业特征输入预测模型进行计算得到预测结果,上述预测模型为基于gbdt(gradientboostingdecisiontree)以及lr(logisticregression)构建训练而成的神经网络模型,上述预测结果即为上述待测企业当前投标的中标概率。
在一个实施例中,所述预测模型包括gbdt模块以及lr模块,上述步骤s3包括:
步骤s31:将所述指定企业特征输入所述gbdt模块中,遍历所述gbdt模块每个决策树,得到一组特征组合;
步骤s32:将所述特征组合进行转换得到相应的指定编码;
步骤s33:将所述指定编码传入所述lr模块进行线性加权预测,得到所述预测结果。
本实施例中,上述gbdt模块为基于决策树算法构建的网络模型,lr模块为基于逻辑回归算法构建的网络模型,将上述指定企业特征输入已经训练好的gbdt模块进行运算,遍历gbdt模块每个决策树,得到一组特征组合,该特征组合为一组离散特征,然后将该组特征组合进行转换,此处将该特征组合进行特征数字化,得到上述指定编码,也即one-hot编码(独热编码),如此使得离散特征的取值扩展到欧式空间,让特征之间的距离计算更加合理,然后将one-hot编码传入lr模块进行线性加权预测,得到预测结果,具体而言,可以利用以下公式计算出所述预测结果:y=sigmoid(xtw);其中,y为待测企业的中标概率,x为指定编码,w为特征权重。
在一个实施例中,上述预测模型的训练过程包括:
步骤s01:获取多个样本形成样本集,并将所述样本集分为训练集以及测试集,所述样本集中的样本为经过特征选择后的企业特征;
步骤s02:将所述训练集输入预设的初始决策树模型进行训练,以形成所述gbdt模块,并输出新的训练数据;
步骤s03:将所述新的训练数据输入至预设的初始线性分类模型进行训练,得到所述lr模块;
步骤s04:依据所述测试集对所述gbdt模块及lr模块进行测试,得到测试结果;
步骤s05:依据所述测试结果进行调整,以得到所述预测模型。
本实施例中,对上述预测模型进行训练,首先获取样本集,上述样本集中的样本为经过特征选择后得到的企业特征。对于上述样本集,可以取其中80%样本作为训练集,剩下20%样本作为测试集。将上述训练集输入预设的初始决策树模型进行训练,该初始决策树基于gbdt构建,然后通过输入样本进行迭代计算建树,该过程即是自动进行的特征组合和离散化,从树的根结点到叶子节点的路径可以看成是不同特征进行的特征组合,用叶子节点可以唯一的表示这条路径,也可作为一组离散特征,也即为上述新的训练数据,然后将该新的训练数据输入初始线性分类模型进行训练,该初始线性分类模型基于lr构建,也即将上述离散特征传入lr进行二次训练,此处可使用正则化来减少过拟合,训练完成后,通过输入测试集来进行测试,当测试结果与实际结果重合超过预设阈值,则可认为测试通过,该预测模型可投入使用,否则,可依据测试结果进行调整,重新进行特征选择,再训练并测试,直至测试结果通过,得到上述预测模型。
在另一个实施例中,每个样本分别对应一个标签,该标签即标记为中标或不中标的标签,在得到新的训练数据后,可对每一个训练数据的重要度评估并筛选出重要程度较高的部分特征,然后将该部分特征以及其对应的样本的标签,输入初始线性分类模型进行训练。
在一个实施例中,上述步骤s01包括:
步骤s011:获取投标企业的多个不同的指定特征;
步骤s012:将所述指定特征分别进行分组,得到多个对应所述指定特征的特征组;
步骤s013:分别计算每个所述特征组内的中标企业占所有中标企业的第一比例,以及分别计算每个所述特征组内非中标企业占所有非中标企业的第二比例;
步骤s014:依据所述特征组内中标企业的数量、所述特征组内非中标企业的数量、所有中标企业的数量、所有非中标企业的数量、第一比例以及第二比例,计算得到所述指定特征的每个所述特征组的证据权重;
步骤s015:依据所述证据权重计算出每个所述特征组的iv值;
步骤s016:依据每个所述特征组的iv值计算出所述指定特征的iv值;
步骤s017:将iv值超过预设阈值的指定特征记为所述企业特征,并将所述企业特征作为所述样本加入所述样本集。
本实施例中,可通过爬取网络上公开的招标数据,记录每个招标项目投标企业和投标结果,或通过天眼查等渠道获取投标企业相关信息及资质,得到大量的投标企业的企业数据,从中获取相应的指定特征,例如企业的注册资本、经营状态等,然后将指定特征分别进行分组,得到多个对应指定特征的特征组,例如对于注册资本这个特征,可以分组成100万以下,100-1000万,1000-2000万,2000万以上等不同的特征组,然后分别计算每个特征组内的中标企业占所有中标企业的第一比例,以及分别计算每个特征组内非中标企业占所有非中标企业的第二比例,然后依据以下公式计算出上述每个特征组的证据权重:
本实施例中,依据证据权重计算出每个特征组的iv值,具体可通过以下公式计算出第i个特征组的iv值:ivi=(pyi-pni)*woei,得到指定特征的每个特征组的iv值后,依据指定特征的每个特征组的iv值计算出该指定特征的iv值,具体可通过以下公式:
本发明提供的基于企业特征预测中标概率的方法,通过基于gbdt以及lr构建训练而成的预测模型,对投标企业进行预测,只需提取相应的企业特征输入即可直接得到企业中标概率,方便快捷,效率大大提升,且准确率较高。
参照图2,本实施例中提供一种基于企业特征预测中标概率的装置,该装置对应上述基于企业特征预测中标概率的方法,该装置包括:
获取信息单元1,用于获取待测企业的当前的投标信息以及企业信息,所述企业信息包括历史投标记录以及企业资质信息;
提取特征单元2,用于从所述投标信息以及所述企业信息中提取所述待测企业的指定企业特征;
计算结果单元3,用于将所述指定企业特征输入至预设的预测模型进行计算,得到预测结果,所述预测模型基于gbdt以及lr构建训练而成,所述预测结果为所述待测企业当前投标的中标概率。
如上述获取信息单元1、提取特征单元2所述,上述待测企业为准备投标的企业,上述投标信息至少包括投标书中的内容,上述企业信息包括历史投标记录以及企业资质信息,历史投标记录包括该企业曾经每次的投标记录,例如投标哪些项目、投标时间、是否中标、投标书内容等;企业资质信息包括类型、成立日期、经营状态、注册资本、法人等信息。从上述投标信息以及企业信息中提取该待测企业的指定企业特征,例如企业信息中的类型、经营状态、注册资本等。
如上述计算结果单元3所述,上述指定企业特征输入预测模型进行计算得到预测结果,上述预测模型为基于gbdt(gradientboostingdecisiontree)以及lr(logisticregression)构建训练而成的神经网络模型,上述预测结果即为上述待测企业当前投标的中标概率。
在一个实施例中,所述预测模型包括gbdt模块以及lr模块,上述计算结果单元3包括:
遍历决树单元,用于将所述指定企业特征输入所述gbdt模块中,遍历所述gbdt模块每个决策树,得到一组特征组合;
转换编码单元,用于将所述特征组合进行转换得到相应的指定编码;
加权预测单元,用于将所述指定编码传入所述lr模块进行线性加权预测,得到所述预测结果。
本实施例中,上述gbdt模块为基于决策树算法构建的网络模型,lr模块为基于逻辑回归算法构建的网络模型,将上述指定企业特征输入已经训练好的gbdt模块进行运算,遍历gbdt模块每个决策树,得到一组特征组合,该特征组合为一组离散特征,然后将该组特征组合进行转换,此处将该特征组合进行特征数字化,得到上述指定编码,也即one-hot编码(独热编码),如此使得离散特征的取值扩展到欧式空间,让特征之间的距离计算更加合理,然后将one-hot编码传入lr模块进行线性加权预测,得到预测结果,具体而言,可以利用以下公式计算出所述预测结果:y=sigmoid(xtw);其中,y为待测企业的中标概率,x为指定编码,w为特征权重。
在一个实施例中,上述预测模型的训练过程包括:
获取多个样本形成样本集,并将所述样本集分为训练集以及测试集,所述样本集中的样本为经过特征选择后的企业特征;
将所述训练集输入预设的初始决策树模型进行训练,以形成所述gbdt模块,并输出新的训练数据;
将所述新的训练数据输入至预设的初始线性分类模型进行训练,得到所述lr模块;
步骤s04:依据所述测试集对所述gbdt模块及lr模块进行测试,得到测试结果;
依据所述测试结果进行调整,以得到所述预测模型。
本实施例中,对上述预测模型进行训练,首先获取样本集,上述样本集中的样本为经过特征选择后得到的企业特征。对于上述样本集,可以取其中80%样本作为训练集,剩下20%样本作为测试集。将上述训练集输入预设的初始决策树模型进行训练,该初始决策树基于gbdt构建,然后通过输入样本进行迭代计算建树,该过程即是自动进行的特征组合和离散化,从树的根结点到叶子节点的路径可以看成是不同特征进行的特征组合,用叶子节点可以唯一的表示这条路径,也可作为一组离散特征,也即为上述新的训练数据,然后将该新的训练数据输入初始线性分类模型进行训练,该初始线性分类模型基于lr构建,也即将上述离散特征传入lr进行二次训练,此处可使用正则化来减少过拟合,训练完成后,通过输入测试集来进行测试,当测试结果与实际结果重合超过预设阈值,则可认为测试通过,该预测模型可投入使用,否则,可依据测试结果进行调整,重新进行特征选择,再训练并测试,直至测试结果通过,得到上述预测模型。
在另一个实施例中,每个样本分别对应一个标签,该标签即标记为中标或不中标的标签,在得到新的训练数据后,可对每一个训练数据的重要度评估并筛选出重要程度较高的部分特征,然后将该部分特征以及其对应的样本的标签,输入初始线性分类模型进行训练。
在一个实施例中,上述特征选择的过程包括:
获取投标企业的多个不同的指定特征;
将所述指定特征分别进行分组,得到多个对应所述指定特征的特征组;
分别计算每个所述特征组内的中标企业占所有中标企业的第一比例,以及分别计算每个所述特征组内非中标企业占所有非中标企业的第二比例;
依据所述特征组内中标企业的数量、所述特征组内非中标企业的数量、所有中标企业的数量、所有非中标企业的数量、第一比例以及第二比例,计算得到所述指定特征的每个所述特征组的证据权重;
依据所述证据权重计算出每个所述特征组的iv值;
依据每个所述特征组的iv值计算出所述指定特征的iv值;
将iv值超过预设阈值的指定特征记为所述企业特征,并作为所述样本加入所述样本集。
本实施例中,可通过爬取网络上公开的招标数据,记录每个招标项目投标企业和投标结果,或通过天眼查等渠道获取投标企业相关信息及资质,得到大量的投标企业的企业数据,从中获取相应的指定特征,例如企业的注册资本、经营状态等,然后将指定特征分别进行分组,得到多个对应指定特征的特征组,例如对于注册资本这个特征,可以分组成100万以下,100-1000万,1000-2000万,2000万以上等不同的特征组,然后分别计算每个特征组内的中标企业占所有中标企业的第一比例,以及分别计算每个特征组内非中标企业占所有非中标企业的第二比例,然后依据以下公式计算出上述每个特征组的证据权重:
本实施例中,依据证据权重计算出每个特征组的iv值,具体可通过以下公式计算出第i个特征组的iv值:ivi=(pyi-pni)*woei,得到指定特征的每个特征组的iv值后,依据指定特征的每个特征组的iv值计算出该指定特征的iv值,具体可通过以下公式:
本发明提供的基于企业特征预测中标概率的装置,通过基于gbdt以及lr构建训练而成的预测模型,对投标企业进行预测,只需提取相应的企业特征输入即可直接得到企业中标概率,方便快捷,效率大大提升,且准确率较高。
参考图3,本申请还提供了一种计算机可读的存储介质10,存储介质10中存储有计算机程序20,当其在计算机上运行时,使得计算机执行以上实施例所描述的基于企业特征预测中标概率的方法。
参考图4,本申请还提供了一种包含指令的计算机设备40,计算机设备包括存储器30和处理器50,存储器30存储有计算机程序20,处理器30执行计算机程序20时实现以上实施例所描述的基于企业特征预测中标概率的方法。
在上述实施例中,可以全部或部分地通过软件、硬件、固件或者其任意组合来实现。当使用软件实现时,可以全部或部分地以计算机程序产品的形式实现。
所述计算机程序产品包括一个或多个计算机指令。在计算机上加载和执行所述计算机程序指令时,全部或部分地产生按照本申请实施例所述的流程或功能。所述计算机可以是通用计算机、专用计算机、计算机网络、或者其他可编程装置。所述计算机指令可以存储在计算机可读存储介质中,或者从一个计算机可读存储介质向另一计算机可读存储介质传输,例如,所述计算机指令可以从一个网站站点、计算机、服务器或数据中心通过有线(例如同轴电缆、光纤、数字用户线(dsl))或无线(例如红外、无线、微波等)方式向另一个网站站点、计算机、服务器或数据中心进行传输。所述计算机可读存储介质可以是计算机能够存储的任何可用介质或者是包含一个或多个可用介质集成的服务器、数据中心等数据存储设备。所述可用介质可以是磁性介质,(例如,软盘、硬盘、磁带)、光介质(例如,dvd)、或者半导体介质(例如固态硬盘solidstatedisk(ssd))等。
以上所述仅为本申请的优选实施例,并非因此限制本申请的专利范围,凡是利用本申请说明书及附图内容所作的等效结构或等效流程变换,或直接或间接运用在其他相关的技术领域,均同理包括在本申请的专利保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!