基于遗传算法的末端物流网点布局方法、装置、设备及介质与流程
本发明涉及到物流智能化领域,具体涉及一种基于遗传算法的末端物流网点布局方法、装置、设备及介质。
背景技术:
随着我国网络媒介与电子商务的蓬勃发展,各大物流公司的竞争日趋激烈。快递物流的末端配送网点是快递公司在区域内运营的空间聚集点,末端物流网点的数量、规模与位置反映了快递公司末端的服务水平和能力。在整个物流配送环节中,末端物流配送成本占整个配送网络的30%以上。因此,区域内的末端配送网点的布局是否合理,对快递企业提高经济效益与服务水平,降低管理成本,实现持续发展起着重要作用。
现阶段,各快递公司的末端物流配送服务网点的规模不断扩大,但整体来说仍存在很多亟待解决的问题,如末端物流网点规模小、业务分散、重复设点、重复配送等,这些问题极大地增加了快递公司的配送成本。因此,合理选择、布局末端配送网点,可以有效地优化物流资源配置、降低物流成本。
技术实现要素:
为了实现上述技术目标,本发明第一方面提供了一种基于遗传算法的末端物流网点布局方法,其具体技术方案如下:
一种基于遗传算法的末端物流网点布局方法,其包括:
获取区域内客户点集合和末端物流网点集合的基本信息;
设定区域内所有末端物流网点的运营状态并对区域内的所有客户点和末端物流网点建立业务量分配模型;
建立末端物流网点布局模型;
使用遗传算法求解所述末端物流网点布局模型从而完成对末端物流网点的选择布局。
在一些实施例中,所述设定区获取区域内客户点集合和末端物流网点集合的基本信息包括:
获取区域内客户点集合:客户点集合
获取末端物流网点集合的基本信息:末端物流网点集合
获取客户点集合和末端物流网点集合的基本信息还包括:从客户点ci到末端物流网点nj的距离dij,从客户点ci到末端物流网点nj的最大距离kij,从客户点ci到末端物流网点nj的单位距离的运输成本cij。
在一些实施例中,所述设定区域内所有末端物流网点的运营状态并对区域内的所有客户点和末端物流网点建立业务量分配模型包括:
设定区域内所有末端物流网点的运营状态:区域内末端物流网点nj的运营状态包括两种:保留和舍弃,设定一二元决策变量xj来表示末端物流网点nj的运营状态,其中,xj∈{0,1},当xj=0时,表示末端物流网点nj被舍弃,当xj=1时,表示末端物流网点nj被保留;
对区域内的所有客户点和末端物流网点建立业务量分配模型:一个客户点的业务量可以被分配到多个末端物流网点,设定一个非负整数决策变量表示客户点分配给末端物流网点的业务量,其中,yij∈{0,1,…,min{pi,qj}}表示客户点ci分配给nj的业务量,如果yij=0,表示末端物流网点nj没有覆盖客户点ci,否则,表示末端物流网点nj覆盖了客户点ci。
在一些实施例中,所述末端物流网点布局模型为:
目标函数:
约束条件包括:
约束条件1:
约束条件2:
约束条件3:0≤dij≤kij,i=1,2,…,n,j=1,2,…,m;
约束条件4:,xj∈{0,1},j=1,2,…,m;
约束条件5:yij∈{0,1,…,min{pi,qj}},i=1,2,…,n,j=1,2,…,m;
其中:目标函数,使得区域内末端物流网点和客户点之间的总分配成本最小,总分配成本为末端物流网点运营成本与末端物流网点到客户点的运输成本之和;
约束条件1表示末端物流网点承担的业务量不超过末端物流网点的所能提供的业务量上限;
约束条件2表示客户点的业务需求量被完全满足;
约束条件3表示客户点到末端物流网点的运输距离不超过客户点到末端物流网点的最大距离。
在一些实施例中,所述使用遗传算法求解所述末端物流网点布局模型包括:
染色体编码:采用自然数自然数编码,其中,1,2,…,m表示m个待选的末端物流网点,m+1,m+2,…,m+n表示n个客户点,每条染色体有m+n个基因位,每个基因位的取值是[m+1,m+n]中的自然数,代表客户点的一个排列;然后将m个代表网点的基因位,采用插空法的方式插入客户点的排列中,且保证排列的末尾为网点基因位;
初始种群的产生:随机生成200~500个满足所述约束条件的个体,
适应度计算:基于所述目标函数值计算个体的适应度,以确定各个体的遗传机会;
遗传算子:根据种群中个体的适应度大小,采用轮盘赌的方式选择遗传算子,个体被选中的概率与其适应度函数值大小成正比,适应度越高,被选择的概率越大;
交叉变异:采用交叉及变异运算产生新个体,设置交叉概率为0.5,变异概率为0.2。
在一些实施例中,在所述使用遗传算法求解所述末端物流网点布局模型从而完成对末端物流网点的选择布局之后至,还包括:
采用蚁群算法规划配送路径,包括:
构建带权有向图g=(r,e),其中:r为节点的集合,包括所述区域的客户点集合内的所有客户点及选定的所有末端物流网点,e为带权重有向边的集合,带权重有向边表示节点之间的配送成本;
获取区域内客户点集合的配送需求,采用蚁群算法在所述带权有向图g=(r,e)中寻找最优的配送路径。
本发明第二方面提供了一种基于遗传算法的末端物流网点布局装置,其包括:
获取模块,用于获取区域内客户点集合和末端物流网点集合的基本信息;
设定模块,用于设定区域内所有末端物流网点的运营状态并对区域内的所有客户点和末端物流网点建立业务量分配模型;
建模模块,用于建立末端物流网点布局模型;
求解模块,用于使用遗传算法求解所述末端物流网点布局模型从而完成对末端物流网点的选择布局。
本发明第三方面提供了一种电子设备,包括存储器、处理器及存储在存储器内并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现上述的基于遗传算法的末端物流网点布局方法。
本发明第四方面提供了一种计算机可读存储介质,计算机可读存储介质上存储有计算机程序,该程序被处理器执行时实现上述的基于遗传算法的末端物流网点布局方法。
本发明通过对已有的各末端物流网点的运营成本、与客户点之间的距离、业务量大小等因素进行综合考虑从而建立末端物流网点布局模型,并采用遗传算法对末端物流网点布局模型进行求解,从而获得最终的末端物流网点的布局方案。
本发明实现了对末端物流网点的优化布局,降低了物流公司的配送成本。
附图说明
图1为本发明实施例提供的基于遗传算法的末端物流网点布局方法的执行流程示意图;
图2为本发明实施例提供的基于遗传算法的末端物流网点布局方法中的使用遗传算法求解末端物流网点布局模型的执行流程示意图;
图3为本发明实施例提供的基于遗传算法的末端物流网点布局方法的执行流程示意图;
图4为本发明实施例提供的基于遗传算法的末端物流网点布局方法中的使用蚁群算法规划配送路径的执行流程示意图;
图5为本发明实施例提供的基于遗传算法的末端物流网点布局装置的结构框图;
图6为本发明实施例提供的电子设备的结构框图。
具体实施方式
为使本发明的上述目的、特征和优点能够更加明显易懂,下面结合附图和具体实施方式对本发明作进一步详细的说明。
现阶段,各快递公司的末端物流配送服务网点的规模不断扩大,但整体来说仍存在很多亟待解决的问题,如末端物流网点规模小、业务分散、重复设点、重复配送等,这些问题极大地增加了快递公司的配送成本。
本发明提供的基于遗传算法的末端物流网点布局方法、装置、设备及介质旨在解决现有技术中的上述技术问题。
实施例一
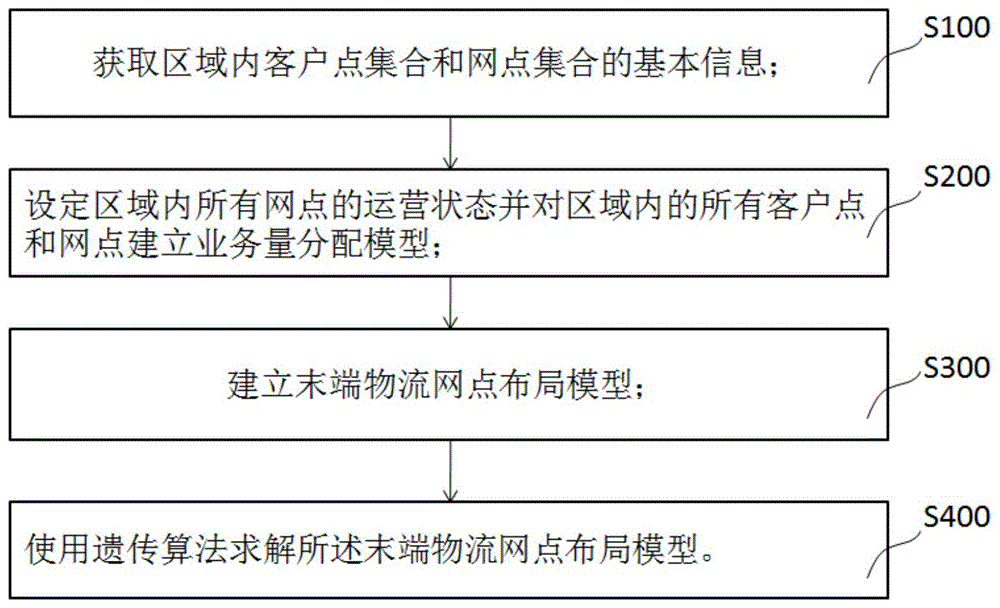
本申请实施例提供了一种基于遗传算法的末端物流网点布局方法,如图1所示,包括:
步骤s100、获取区域内客户点集合和末端物流网点集合的基本信息。
可选的,步骤s100包括如下子步骤:
s101、获取区域内客户点集合:客户点集合
s102、获取末端物流网点集合的基本信息:末端物流网点集合
s103、获取客户点集合和末端物流网点集合的基本信息还包括:从客户点ci到末端物流网点nj的距离dij,从客户点ci到末端物流网点nj的最大距离kij,从客户点ci到末端物流网点nj的单位距离的运输成本cij。
步骤s200、设定区域内所有末端物流网点的运营状态并对区域内的所有客户点和末端物流网点建立业务量分配模型。
可选的,步骤s200包括如下子步骤:
步骤s201、设定区域内所有末端物流网点的运营状态:区域内末端物流网点nj的运营状态包括两种:保留和舍弃,设定一二元决策变量xj来表示末端物流网点nj的运营状态,其中,xj∈{0,1},当xj=0时,表示末端物流网点nj被舍弃,当xj=1时,表示末端物流网点nj被保留。
步骤s202、对区域内的所有客户点和末端物流网点建立业务量分配模型:一个客户点的业务量可以被分配到多个末端物流网点,设定一个非负整数决策变量表示客户点分配给末端物流网点的业务量,其中,yij∈{0,1,…,min{pi,qj}}表示客户点ci分配给nj的业务量,如果yij=0,表示末端物流网点nj没有覆盖客户点ci,否则,表示末端物流网点nj覆盖了客户点ci。
步骤s300、建立末端物流网点布局模型。
具体的,本实施例中的末端物流网点布局模型如下:
目标函数:
约束条件包括:
约束条件1:
约束条件2:
约束条件3:0≤dij≤kij,i=1,2,…,n,j=1,2,…,m;
约束条件4:,xj∈{0,1},j=1,2,…,m;
约束条件5:yij∈{0,1,…,min{pi,qj}},i=1,2,…,n,j=1,2,…,m;
其中:
目标函数,即寻找最优的二元决策变量xj以确定保留哪些末端物流网点,最终使得区域内的保留下来的末端物流网点和客户点之间的总分配成本最小,其中的总分配成本则为末端物流网点运营成本与末端物流网点到客户点的运输成本之和。
约束条件1表示末端物流网点承担的业务量不超过末端物流网点的所能提供的业务量上限。
约束条件2表示客户点的业务需求量被完全满足。
约束条件3表示被允许的客户点到末端物流网点的实际运输距离不超过客户点到末端物流网点的最大距离。
步骤s400、使用遗传算法求解所述末端物流网点布局模型,从而完成对末端物流网点的选择布局。
如图2所示,本实施例中,步骤s400包括如下子步骤:
步骤s401、染色体编码:采用自然数自然数编码,其中,1,2,…,m表示m个待选的末端物流网点,m+1,m+2,…,m+n表示n个客户点,每条染色体有m+n个基因位,每个基因位的取值是[m+1,m+n]中的自然数,代表客户点的一个排列;然后将m个代表网点的基因位,采用插空法的方式插入客户点的排列中,且保证排列的末尾为网点基因位。
如此,每个网点基因位前紧邻的客户点基因位即为分配给此网点的客户点。例如,在某个实施例中,包括3个待选的末端物流网点及5个客户点时,即m=3,n=5。对应的,待选的末端物流网点集合为{1,2,3},客户点集合为{4,5,6,7,8}。其中,经过插空处理后的其中一个解的编码为45126783,则表示:网点1被分配为处理客户点4、5的业务,网点3被分配为处理客户点2、6、7、8的业务。
步骤s402、初始种群的产生:随机生成200~500个满足所述约束条件的个体。
生成过程中,其余其中的不满足约束条件的个体,将其重新生成,直至所有的个体均满足约束条件。
步骤s403、适应度计算:基于所述目标函数值计算个体的适应度,以确定各个体的遗传机会。
步骤s404、遗传算子:根据种群中个个体的适应度大小,采用轮盘赌的方式选择遗传算子,个体被选中的概率与其适应度函数值大小成正比,适应度越高,被选择的概率越大。可选的,步骤s404的具体执行过程如下:
计算出各个体的适应度fi以及所有个体的适应度总和σfi。
计算出每个个体的相对适应度大小fi/σfi。
计算出每个个体的累积概率
在[0,1]区间内产生一个随机数r,依据该随机数的数值确定被选中的个体。若r<q(1),则选择个体1;若q(k-1)<r≤q(k)成立,则选择k。重复选择一定次数,直至产生足够数量的新个体。
步骤s405、交叉变异:采用交叉及变异运算产生新个体,设置交叉概率为0.5,变异概率为0.2。可选的,步骤s405的具体执行过程如下:
对群体进行随机配对;
随机设定交叉点的位置;
互换配对染色体间的部分基因;
随机产生变异点,再根据变异概率阈值进行变异操作,由于此处染色体编码表示的是排列组合,所以变异操作为互换两个基因位的位置。
迭代上述步骤,直至模型收敛,所得到的解即为所述末端物流网点布局模型的最优解。
执行完步骤s405,即获得末端物流网点布局模型的最优解,也就是前文提交的二元决策变量xj的最优解,根据求得的各二元决策变量xj的值,即可以确定保留哪些末端物流网点,舍弃哪些末端物流网点。如x1=1,则表示保留末端物流网点1;反之,如x1=0,则表示舍弃末端物流网点1。
可见,本实施例提供的基于遗传算法的末端物流网点布局方法,其通过对已有的各末端物流网点的运营成本、与客户点之间的距离、业务量大小等因素进行综合考虑从而建立末端物流网点布局模型,并采用遗传算法对末端物流网点布局模型进行求解,从而获得最终的末端物流网点的布局方案,其显著地降低了物流公司的配送成本。
实施例二
如图3所示,本实施例提供的基于遗传算法的末端物流网点布局方法的执行步骤与实施例一基本相同,其存在的区别在于。
在完成末端物流网点的优化布局(即步骤s405)后,本实施例提供的基于遗传算法的末端物流网点布局方法还包括:
步骤s500:采用蚁群算法规划配送路径。即,如何规划配送路线,以进一步降低配送成本。
可选的,如图4所示,步骤s500包括如下子步骤:
s501、构建带权有向图g=(r,e),其中:r为节点的集合,包括所述区域的客户点集合内的所有客户点及选定的所有末端物流网点,e为带权重有向边的集合,带权重有向边表示节点之间的配送成本;
s502、获取区域内客户点集合的配送需求,采用蚁群算法在所述带权有向图g=(r,e)中寻找最优的配送路径。
由于采用蚁群算法在带权有向图中寻找节点之间的最优路径的具体算法过程为本领域一般技术人员所熟知,因此本说明书中不再对其具体过程进行详细描述。
实施例三
图5为本实施例提供的基于遗传算法的末端物流网点布局装置10的结构框图,该末端物流网点布局装置10包括获取模块11、设定模块12、建模模块13及求解模块14,其中:
获取模块11,用于获取区域内客户点集合和末端物流网点集合的基本信息。
可选的,获取模块11还包括第一获取子模块、第二获取子模块及第三获取子模块。其中:
第一获取子模块、用于获取区域内客户点集合:客户点集合
第二获取子模块、用于获取末端物流网点集合的基本信息:末端物流网点集合
第三获取子模块、用于获取客户点集合和末端物流网点集合的基本信息还包括:从客户点ci到末端物流网点nj的距离dij,从客户点ci到末端物流网点nj的最大距离kij,从客户点ci到末端物流网点nj的单位距离的运输成本cij。
设定模块12,用于设定区域内所有末端物流网点的运营状态并对区域内的所有客户点和末端物流网点建立业务量分配模型。
可选的,设定模块12包括第一设定模块和第二设定模块,其中:
第一设定模块、用于设定区域内所有末端物流网点的运营状态:区域内末端物流网点nj的运营状态包括两种:保留和舍弃,设定一二元决策变量xj来表示末端物流网点nj的运营状态,其中,xj∈{0,1},当xj=0时,表示末端物流网点nj被舍弃,当xj=1时,表示末端物流网点nj被保留。
第二设定模块、用于对区域内的所有客户点和末端物流网点建立业务量分配模型:一个客户点的业务量可以被分配到多个末端物流网点,设定一个非负整数决策变量表示客户点分配给末端物流网点的业务量,其中,yij∈{0,1,…,min{pi,qj}}表示客户点ci分配给nj的业务量,如果yij=0,表示末端物流网点nj没有覆盖客户点ci,否则,表示末端物流网点nj覆盖了客户点ci。
建模模块13,用于建立末端物流网点布局模型。
求解模块14,用于使用遗传算法求解所述末端物流网点布局模型从而完成对末端物流网点的选择布局。
由于所述末端物流网点布局装置10的各功能模块的处理过程与前述实施例一中的末端物流网点布局方法的处理过程一致,因此本实施例不再对末端物流网点布局装置10的各功能模块的处理过程进行重复描述,可以参考实施例一中的相关描述。
采用本实施例提供的末端物流网点布局装置10,能够实现对末端物流网点的优化整合,从而获得最终的末端物流网点的布局方案,显著地降低了物流公司的配送成本。
继续参考图5所示,可选的,本实施例中的末端物流网点布局装置10还包括配送路径规划模块15,其用于采用蚁群算法规划配送路径,包括:
构建带权有向图g=(r,e),其中:r为节点的集合,包括所述区域的客户点集合内的所有客户点及选定的所有末端物流网点,e为带权重有向边的集合,带权重有向边表示节点之间的配送成本;
获取区域内客户点集合的配送需求,采用蚁群算法在所述有向图g=(r,e)中寻找最优的配送路径。
实施例四
图6为本实施例提供的电子设备20的结构示意图,如图6所示,该电子设备20包括处理器21和存储器23,处理器21和存储器23相连,如通过总线22相连。处理器21可以是cpu,通用处理器、dsp,asic,fpga或者其他可编程器件、晶体管逻辑器件、硬件部件或者其他任意组合。其可以实现或执行结合本申请公开内容所描述的各种示例性的逻辑方框,模块和电路。处理器21也可以是实现计算功能的组合,例如包括一个或多个微处理器组合,dsp和微处理器的组合等。总线22可以包括一通路,在上述组件之间传送信息。总线22可以是pci总线或eisa总线等。总线22可以分为地址总线、数据总线、控制总线等。为了便于表示,图中仅以一条粗线表示,但是并不表示仅有一根总线或一种类型的总线。存储器23可以是rom或可存储静态信息和指令的其他类型的静态存储设备,ram或者可以储存信息和指令的其他类型的动态存储设备,也可以是eeprom、cd-rom或其他光盘存储、光碟存储、磁盘存储介质或其他磁存储设备、或者能够用于携带或存储具有指令或数据结构形式的期望程序代码并能够由计算机存取的任何其他介质,但不限于此。存储器23用于存储本申请方案的应用程序代码,并由处理器21来控制执行。处理器21用于执行存储器23中存储的应用程序代码,以实现实施例一、实施例二中的基于遗传算法的末端物流网点布局的方法。
本申请实施例最后还提供了一种计算机可读存储介质,该计算机可读存储介质上存储有计算机程序,该程序被处理器执行时实现实施例一、实施例二中的基于遗传算法的末端物流网点布局的方法。
上文对本发明进行了足够详细的具有一定特殊性的描述。所属领域内的普通技术人员应该理解,实施例中的描述仅仅是示例性的,在不偏离本发明的真实精神和范围的前提下做出所有改变都应该属于本发明的保护范围。本发明所要求保护的范围是由所述的权利要求书进行限定的,而不是由实施例中的上述描述来限定的。
- 还没有人留言评论。精彩留言会获得点赞!