基于VR技术及编程技术的英语语法学习系统的制作方法
基于vr技术及编程技术的英语语法学习系统
技术领域
1.本发明涉及学习系统领域,特别涉及一种基于vr技术及编程技术的英语语法学习系统。
背景技术:
2.英语语法是英语学习中非常重要的一个环节,通常在进行语法练习的时候,都是学生从英语的语句中进行语法的学习,这样的学习方法非常的枯燥乏味,久而久之,学生就不会对英语语法的学习提起兴趣。
技术实现要素:
3.本发明的目的是克服上述现有技术中存在的问题,提供一种基于vr技术及编程技术的英语语法学习系统,通过编程的方式确定英语的情景同时确定英语语句的语法,在通过图形的方式将英语语句进行填充,之后将填充的语句合成情景动画并通过vr技术展现出来,使得在英语语法的学习中,学生的兴趣更加高涨。
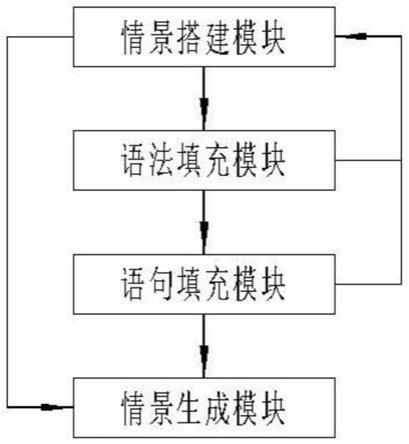
4.为此,本发明提供一种基于vr技术及编程技术的英语语法学习系统,包括:
5.情景搭建模块,通过编程软件设定每一个情景人物以及每一个情景人物依次进行交流的顺序,并预留每一个情景人物在每一次交流时候的语句填充部分。
6.语法填充模块,为每一个语句填充部分分别设置语句的数量,根据语句的数量将语句填充部分分割为多个语句填充子部分并使得每一个语句填充子部分都对应一个语句,然后分别在每一个语句填充子部分中录入语法的各个组成部分。
7.语句填充模块,分别在每一个语法的组成部分中录入英语单词,使得得到每一个完整的语句,并通过语音合成技术得到每一个完整的语句的语音。
8.情景生成模块,依次将每一个情景人物在每一次交流时候的完整的语句的语音进行顺序合成,并将每一个情景人物通过动画的形式进行展现,得到情景动画,并将情景动画通过vr技术进行呈现。
9.进一步,所述情景搭建模块包括情景人物设定模块,所述情景人物设定模块包括:
10.人物主体设定模块,用于接收用户录入的人物主体参数,所述人物主体参数包括人物头部参数、人物身体参数、人物臂部参数、人物腿部参数以及人物尾部参数,并根据人物主体参数得到人物主体结构。
11.人物主体绘制模块,用于接收用户录入的贴图数据,每一个贴图数据对应一个人物主体参数,并将每一个贴图数据添加在其所对应的人物主体参数中,并重新生成人物主体结构。
12.情景人物生成模块,将生成的人物主体结构进行渲染,得到情景人物。
13.进一步,所述情景搭建模块在设定交流的顺序的时候:
14.根据用户录入的交流的数量得到语句填充部分的数量,将所有的语句填充部分依次进行排列。
15.接收用户录入的情景人物,依次将用户录入的情景人物进行排列。
16.当用户录入的情景人物的数量与所述语句填充部分的数量一致的时候,停止接收用户录入的情景人物。
17.依次按照排列的顺序将每一个用户录入的情景人物与语句填充部分进行对应,得到交流的顺序。
18.进一步,所述语法的各个组成部分分别通过3d文字的形式存储在3d数据库中,该3d文字支持vr图像的显示。
19.更进一步,在语句填充子部分中录入语法的各个组成部分的时候:
20.从所述3d数据库中将语法的各个组成部分全部筛选出来。
21.接收用户的显示指令、插入指令以及删除指令。
22.所述显示指令,该显示指令是将用户所选择的语法的组成部分进行显示。
23.所述插入指令,该插入指令是将用户所选择的要插入的语法的组成部分插入到用户所选择的相邻的两个语法的组成部分的中间。
24.所述删除指令,该删除指令是将用户所选择的语法的组成部分进行删除。
25.将所保留的语法的组成部分通过vr技术进行动态显示。
26.更进一步,所述插入指令在执行的时候:
27.接收用户所选择的相邻的两个语法的组成部分。
28.将用户所选择的相邻的两个语法的组成部分的vr图像分别进行等距离反方向的位移。
29.接收用户所选择的要插入的语法的组成部分。
30.将用户所选择的要插入的语法的组成部分插入到用户所选择的相邻的两个语法的组成部分的中间。
31.本发明提供的一种基于vr技术及编程技术的英语语法学习系统,具有如下有益效果:通过编程的方式确定英语的情景同时确定英语语句的语法,在通过图形的方式将英语语句进行填充,之后将填充的语句合成情景动画并通过vr技术展现出来,使得在英语语法的学习中,学生的兴趣更加高涨。
附图说明
32.图1为本发明的整体系统连接示意框图;
33.图2为本发明的情景搭建模块的连接示意框图。
具体实施方式
34.下面结合附图,对本发明的一个具体实施方式进行详细描述,但应当理解本发明的保护范围并不受具体实施方式的限制。
35.在本申请文件中,未经明确的部件型号以及结构,均为本领域技术人员所公知的现有技术,本领域技术人员均可根据实际情况的需要进行设定,在本申请文件的实施例中不做具体的限定。
36.具体的,如图1
‑
2所示,本发明实施例提供了一种基于vr技术及编程技术的英语语法学习系统,包括:
37.情景搭建模块,通过编程软件设定每一个情景人物以及每一个情景人物依次进行交流的顺序,并预留每一个情景人物在每一次交流时候的语句填充部分。
38.上述的情景人物既是进行英语对话的人物,例如,amy和anni要进行一个情景对话,则amy和anni就分别是一个情景人物,对于每一个情景人物所要交流的顺序,既是每一个情景人物以时间轴为顺序依次要说话的顺序,例如,amy先开始进行说话,然后anni进行说话,之后再试amy进行说话,这个既是情景人物依次进行交流的顺序,并在每一个情景人物交流的时候,预留出其所要交流的语句填充部分,即在amy进行依次说话的时候,就预留出其所要说话的语句填充部分,上述的技术内容均通过编程软件实现其依次的顺序,本实施例中以两个情景人物为例,但是并不仅限于两个情景人物,三个及三个以上的情景人物与上述的同理,在此不再陈述。
39.语法填充模块,为每一个语句填充部分分别设置语句的数量,根据语句的数量将语句填充部分分割为多个语句填充子部分并使得每一个语句填充子部分都对应一个语句,然后分别在每一个语句填充子部分中录入语法的各个组成部分。
40.在进行交流的时候,每一个情景人物在依次交流中,即每一个情景人物进行一次说话,所说的话语并不一定只有一句,这里所说的一句,指的是以书面形式表达的时候,两个句号之间的语句属于一句。因此,通过设置语句的数量,即有多少句,就可以将语句填充部分根据需要分成多个语句填充子部分,这样就可以使得将每一个语句均匀的分布在语句填充部分中,使得空间被充分的利用。对于上述的语法组成部分,既是主语、谓语、宾语、定语、表语、状语、补语等语法的组成部分,就这些组成部分进行拼接,就可以得到一个英语的框架,即可以得到一个英语语句的框架。
41.语句填充模块,分别在每一个语法的组成部分中录入英语单词,使得得到每一个完整的语句,并通过语音合成技术得到每一个完整的语句的语音。
42.通过录入英语单词,使得每一个语句填充子部分中填充一个英语单词,这样就可以使得在进行英语语句录入的时候,更加的清楚,一目了然。这样就可以将英语单词或者短语,在此,认为英语的单词和短语没有区别,就可以使得英语的框架更加的充实,使得英语的语句更加的充实,从而构成一个完整的英语语句。之后,在通过语音合成技术得到每一个完整的语句的语音,这样即使得到每一个完整的语句的语音发音,该语音发音为声音的形式。
43.情景生成模块,依次将每一个情景人物在每一次交流时候的完整的语句的语音进行顺序合成,并将每一个情景人物通过动画的形式进行展现,得到情景动画,并将情景动画通过vr技术进行呈现。
44.在该模块中,给句上述已经得到的每一个情景人物依次进行交流的顺序,将所得到的语音根据上述顺序依次排序,之后在将排序后的语音依次进行合成,同时,使得每一个情景人物在说话的时候,通过动画的形式进行展现,即使得每一个情景人物在说话的时候,会有一些肢体动作,同时,人物的嘴巴处会进行反复的开合,使得效果更加的真实,由此,将所有的进行拼接合并,就可以使得得到情景动画,并通过vr技术进行呈现,即用户可以通过vr技术直观的感受到刚才所做的情景动画。
45.在本实施例中,所述情景搭建模块包括情景人物设定模块,所述情景人物设定模块包括:
46.人物主体设定模块,用于接收用户录入的人物主体参数,所述人物主体参数包括人物头部参数、人物身体参数、人物臂部参数、人物腿部参数以及人物尾部参数,并根据人物主体参数得到人物主体结构。
47.上述的人物主体参数是多种参数的组合,即人物头部参数、人物身体参数、人物臂部参数、人物腿部参数以及人物尾部参数的组合,每一个人物主体参数分别通过阿拉伯数字进行表示,表示这些部位的个数,例如人的人物主体参数中,既是人物头部参数为1、人物身体参数为1、人物臂部参数为2、人物腿部参数为2以及人物尾部参数为0的组合,即一个人拥有1个头部、1个身体、2个臂部、2个腿部以及0个尾部,而猴子的人物主体参数中,既是人物头部参数为1、人物身体参数为1、人物臂部参数为2、人物腿部参数为2以及人物尾部参数为1的组合,即一个人拥有1个头部、1个身体、2个臂部、2个腿部以及1个尾部。系统根据上述参数,搭建出情景人物的模型,该模型为空白的模型。
48.人物主体绘制模块,用于接收用户录入的贴图数据,每一个贴图数据对应一个人物主体参数,并将每一个贴图数据添加在其所对应的人物主体参数中,并重新生成人物主体结构。
49.该模块使用贴图的技术将上述的空白模型的对应部分进行贴图,这样有了贴图的技术,渲染之后就可以使得情景人物更加的生动。这样就构成了一个重新生成的人物主体结构。
50.情景人物生成模块,将生成的人物主体结构进行渲染,得到情景人物。这样就可以使得情景人物更加的生动。
51.在本实施例中,所述情景搭建模块在设定交流的顺序的时候:
52.根据用户录入的交流的数量得到语句填充部分的数量,将所有的语句填充部分依次进行排列。这样就可以得到全部所要交流的语句。例如全部所要交流的语句分别有7句,分别为a句、b句、c句、d句、e句、f句、g句等。
53.接收用户录入的情景人物,依次将用户录入的情景人物进行排列。这样就可以将上述的交流语句依次进行划分,这样就可以得到依次进行交流的顺序。对应的,上述的a句、b句、c句、d句、e句、f句、g句等,就可以将amy和anni进行排列,使得与上述的a句、b句、c句、d句、e句、f句、g句对应,排列出来即为amy、anni、amy、anni、amy、anni、amy等,这样就可以得到交流的顺序。即amy先说a句,anni再说b句,amy再说c句,anni再说d句,amy再说e句,anni再说f句,amy再说g句,既是完成情景对话。
54.当用户录入的情景人物的数量与所述语句填充部分的数量一致的时候,停止接收用户录入的情景人物。这样就可以有效的防止录入的错误,使得情景对话展现出来的顺畅,防止在使用的时候程序出现问题。
55.依次按照排列的顺序将每一个用户录入的情景人物与语句填充部分进行对应,得到交流的顺序。既是上述所描述的情景人物之间交流的顺序。
56.在本实施例中,所述语法的各个组成部分分别通过3d文字的形式存储在3d数据库中,该3d文字支持vr图像的显示。这样在使得对语法的组成部分进行选择的时候,就可以通过3d的形式将其展示出来。
57.同时,在本实施例中,在录入英语单词的时候,也可以通过3d图像的形式将其进行录入,该3d图像支持vr图像的显示,这样就可以在录入的时候,依然实现vr的技术效果,这
样就可以使得录入更加的具有生机,提升用户的学习使用兴趣。
58.英语单词的3d图像也存储在3d数据库中。
59.同时,在本实施例中,在语句填充子部分中录入语法的各个组成部分的时候:
60.从所述3d数据库中将语法的各个组成部分全部筛选出来。这样就可以给用户缩小其在数据库中的选择范围,同时也可以使得后期调用的速度更加的快速。
61.接收用户的显示指令、插入指令以及删除指令。这些指令的作用如下:
62.所述显示指令,该显示指令是将用户所选择的语法的组成部分进行显示。即将用户所选择的语法组成部分进行显示。
63.所述插入指令,该插入指令是将用户所选择的要插入的语法的组成部分插入到用户所选择的相邻的两个语法的组成部分的中间。即将用户所选择的语法组成部分插入到选择的位置中,在进行显示。
64.所述删除指令,该删除指令是将用户所选择的语法的组成部分进行删除。即将用户所选择的语法组成成分进行删除,同时,删除后不显示。
65.将所保留的语法的组成部分通过vr技术进行动态显示。这样既可以清楚的使得用户青岛自己所录入的指令的执行过程。
66.同时,在本实施例中,所述插入指令在执行的时候:
67.首先,接收用户所选择的相邻的两个语法的组成部分。
68.其次,将用户所选择的相邻的两个语法的组成部分的vr图像分别进行等距离反方向的位移。
69.再次,接收用户所选择的要插入的语法的组成部分。
70.最后,将用户所选择的要插入的语法的组成部分插入到用户所选择的相邻的两个语法的组成部分的中间。
71.经过上述的步骤,就可以完成将用户所选择的语法组成部分插入到选择的位置中去。
72.以上公开的仅为本发明的几个具体实施例,但是,本发明实施例并非局限于此,任何本领域的技术人员能思之的变化都应落入本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1