一种基于YOLO和U-Net的口腔曲断影像智齿分割方法
本发明涉及医学图像分割技术领域,具体涉及一种基于yolo和u-net的口腔曲断影像智齿分割方法。
背景技术:
牙齿是人类重要器官之一,且由智齿引起的问题在口腔疾病占据了相当一部分比例,智齿的生长状态也是需要对其进行手术移除与否的重要依据;同时,在法医学中,智齿对年龄的判定有着至关重要的作用。因此相比于其他牙齿,选取智齿作为研究目标具有更广泛的受众与更高的临床应用价值。同时,口腔医学影像在国内最普遍的形式为口腔曲断图像。
2015年,longjonathan等人[1]提出全卷积网络,可以对图像进行像素级的分类,从而解决了语义级别的图像分割问题。此工作是深度学习应用于图像分割的开山之作。然而,全卷积网络在对图像进行分割时,上采样层将特征恢复到原图像的大小,此过程会导致像素定位不精确,从而影响分割结果的准确性。
针对上述局限性,olafronneberger等人[2]提出了u-net网络结构,u-net是基于fcn的一种语义分割网络,适用于做医学图像的分割。u-net网络结构与fcn网络结构相似,也是分为下采样阶段和上采样阶段,网络结构中只有卷积层和池化层,没有全连接层,网络中较浅的高分辨率层用来解决像素定位的问题,较深的层用来解决像素分类的问题,从而可以实现图像语义级别的分割。
然而,u-net直接应用于口腔曲断影像智齿分割中,存在以下两个问题:(1)在特征较为复杂的口腔曲断影像中,由于智齿与其余牙齿的结构相似只是空间位置不同,u-net可以捕捉牙齿的形态特征,但无法准确捕捉智齿的空间位置特征,因此单纯使用u-net无法得到准确的智齿分割结果;(2)口腔曲断影像尺寸较大,而智齿的占比较小,单颗智齿仅占全片约0.6%的面积,使用u-net对口腔曲断影像直接进行智齿分割会导致大部分算力浪费在没有智齿的背景区域。
[1]e.shelhamer,j.long,andt.darrell,“fullyconvolutionalnetworksforsemanticsegmentation,”ieeetransactionsonpatternanalysisandmachineintelligence,2016.
[2]o.ronneberger,p.fischer,andt.brox,“u-net:convolutionalnetworksforbiomedicalimagesegmentation,”ininternationalconferenceonmedicalimagecomputingandcom-puter-assistedintervention,pp.234–241,springer,2015.
技术实现要素:
为了解决现有基于u-net的口腔曲断影像智齿分割应用中存在的问题,本发明的目的在于提供一种基于yolo(“你只看一次”算法)和u-net的口腔曲断影像智齿分割方法,用于分割,在连通成分分析方面比现有方法的查准率和查全率都有效提高。
为达到以上目的,本发明采用如下技术方案:
一种基于yolo和u-net的口腔曲断影像智齿分割方法,首先对口腔曲断影像进行图像预处理,对预处理后图像中的智齿进行位置标注得到位置标签,并划分训练集和测试集;随后利用图像和位置标签训练yolo模型,设置空间位置的置信度阈值,得到智齿的空间位置信息;然后基于智齿的空间位置信息进行切片处理,将得到的所有包含智齿的切片进行预处理,预处理后对训练集的切片进行像素级的类别标注;最后采用训练集的切片图像和位置标签训练u-net模型,设置像素类别的置信度阈值进行二值化,最终得到智齿的像素级分类信息,完成智齿分割;具体包括如下步骤:
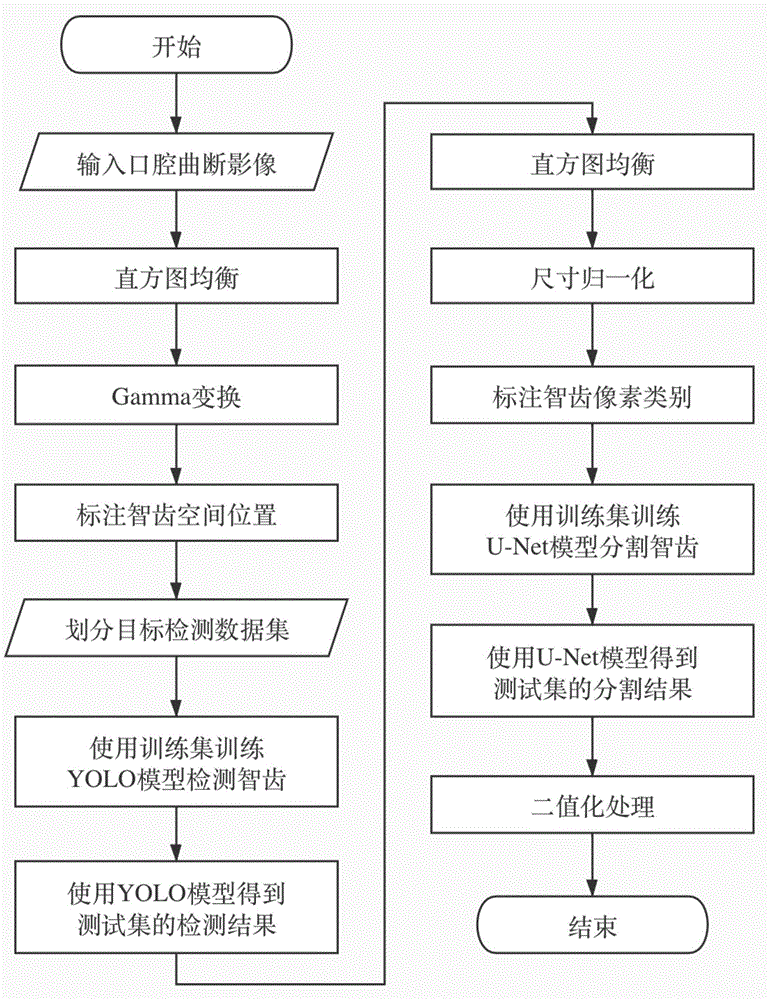
步骤1:对原始的口腔曲断影像进行图像预处理,提升图像质量;对预处理后图像中的智齿进行空间位置的手工标注得到使用智齿区域左上坐标和右下坐标表示的位置标签,并将图像和标签按照7:3的比例划分为训练集和测试集;
步骤2:为检测智齿空间位置,使用基于c语言的darknet框架搭建yolo模型,将训练集输入yolo模型进行训练;完成训练后,将测试集输入yolo模型得到目标检测预测结果,与位置标签进行比较,计算目标检测的精度;
步骤3:将训练集和测试集中包含智齿的区域进行切割,得到包含智齿的局部切片,训练集的切片是由手工标注得到,测试集包含智齿的切片是yolo模型预测的结果;对所有切片进行预处理,提升切片图像的质量,并对训练集和测试集的切片进行像素级标注,得到用于u-net图像分割的新数据集;
步骤4:使用基于python的keras框架搭建u-net模型,将训练集切片输入u-net模型进行训练;完成训练后,将测试集切片输入u-net模型得到智齿分割结果,与位置标签进行比较,计算智齿分割的精度;最后设置阈值,对分割结果进行二值化处理。
步骤1所述的对原始的口腔曲断影像进行图像预处理的具体方式为,直方图均衡结合gamma系数为1.6的gamma变换,以均衡图像的灰度并放大特征。
优选的,步骤1所述的对预处理后图像中的智齿进行空间位置的手工标注的过程中,利用了智齿的位置在所有牙齿边缘的特点,对标注框进行了尺寸设计,强化了智齿的特征。
优选的,步骤2所述的基于c语言的darknet框架搭建yolo模型,设置的超参数为:设置学习率为0.0001,迭代次数为20000,优化器为adam,激活函数为leakyrelu。
优选的,步骤3所述的对所有切片进行预处理,具体操作为尺寸归一化、直方图均衡。
优选的,步骤4所述的基于python的keras框架搭建u-net模型,设置的超参数为:设置学习率为0.0005,迭代次数为200,优化器为adam,激活函数为relu。
本发明采用的基于yolo和u-net的口腔曲断影像智齿分割方法与已有技术相比创新点如下:
1)解决了u-net空间定位能力不足的问题:相比于单纯依靠u-net从口腔曲断影像中分割智齿的方法,本发明将分割过程中的智齿空间定位独立出来,使用目标检测的算法实现,同时由于智齿在所有牙齿中的边缘位置,基于这个特性进行标注,可以有效的提取智齿的空间位置;基于51张口腔曲断影像训练的yolo模型,可以在测试集上达到97%的精度,远远高于单纯使用u-net所得到的定位精度,同时由于分割过程在切片中进行,切片外的背景区域不会有任何假阳性的分割结果,同样提升了分割的精度;
2)解决了u-net应用于大图片的小物体分割中的低效问题:由于单颗智齿前景面积仅占全片的约0.6%,近97%的区域都是无关的背景,通过yolo目标检测得到预测的切片后,智齿前景面积约占切片的35%,简化了u-net完成智齿分割的计算量,同时通过目标检测过程剔除了特征较为相似的其他牙齿,降低了分割过程中的噪声。
附图说明
图1为本发明基于yolo和u-net的口腔曲断影像智齿分割方法的流程图。
图2为步骤2中使用yolo模型进行目标检测的输出图,方框中标题为“智齿”部分为输出的智齿区域的可视图,箭头所指区域为智齿区域的局部放大图。
图3(a)为步骤3中像素级类别标注的经过尺寸归一化后的智齿区域,图3(b)为步骤3中像素级类别标注的智齿对应的标签,白色部分为前景,黑色部分为背景。
图4(a)为齿分割结果的经过尺寸归一化后的智齿区域,图4(b)为齿分割结果的智齿对应的标签,图4(c)为齿分割结果的u-net的分割结果。
具体实施方式
以下结合附图及具体实施例,对本发明作进一步的详细描述。
本发明一种基于yolo和u-net的口腔曲断影像智齿分割方法,图1为方法流程图,包括如下步骤:
步骤1:
口腔曲断影像预处理是为了消除由于影像科医生的个人习惯或不同型号的设备造成的影像偏差,同时对图像中的牙齿部分进行特征增强,预处理主要包含两个阶段:
1)对口腔曲断影像进行直方图均衡处理,将图像的灰度均匀的分散到0-255之间,使灰度的分布更加均匀,增加图像的对比度;
2)对直方图均衡处理后的影像进行gamma变换,压缩图像中灰度较低的部分,拉伸灰度高的部分,突出牙齿在影像中的特征,本发明中的幂次γ取值1.6。
完成预处理后,对影像进行空间位置标注,由于使用yolo进行目标检测是为了对智齿进行定位,所以标注过程考虑到智齿在牙齿中处于边缘位置的特性,将智齿旁边的空白区域和智齿一同构成标签,通过标注过程提升训练和测试过程的精度。
随后对处理后的影像和标签按照7:3的比例划分训练集和测试集。
步骤2:
使用基于c语言的darknet框架构建yolo模型,将数据集格式转换为pascalvoc2007,训练过程中,yolo的损失函数由以下函数表示:
lossyolo=losscoord+lossconf+lossclass
losscoord表示检测框位置预测的损失函数,形式为:
其中,λcoord表示检测框位置的损失函数所占的权重,此处取5;s2表示的是对图片进行切割的网格数量,此处取7的平方49;b表示的是预测框的数量,此处取2;(xi,yi)、(wi,hi)分别是第i个预测的检测框的中心点坐标和宽高,
lossconf表示检测框存在目标物体的置信度,形式为:
其中,λnoobj表示的是没有物体的背景区域误判时的损失权重,为了更加突出前景的损失,本发明中的值为0.5,表示对背景区域进行抑制;ci表示预测第i个网格中存在目标的置信度,
lossclass表示目标类别的置信度,形式为:
其中,pi(c)表示的是预测第i个网格中包含类别c的置信度,
训练过程使用darknet-53模型作为主干网络,学习率设置为0.0001,迭代次数设置为20000,优化器设置为adam,激活函数设置为leakyrelu,输入120个训练样本对yolo模型进行训练,得到收敛后的权重,并将测试集中的52个样本输入训练好的yolo模型,设定置信度阈值为0.6,得到满足阈值智齿区域的预测结果的精度为96.7%,同时获取各个输出结果的中心点坐标和宽高。如图2所示,方框中标题为“智齿”的部分为输出的智齿区域的可视图,箭头所指区域为智齿区域的局部放大图。
步骤3:
基于智齿区域的预测结果和手工标注的标签,对口腔曲断影像进行切割,从每张影像中获取0-4个智齿切片,并对所有切片进行预处理,预处理包含以下两个阶段:
1)为满足u-net输入尺寸一致的要求,对切片进行尺寸归一化,本发明中尺寸归一化后的切片大小为为512×512;如图3(a)和图4(a)所示。
2)对归一化后的切片进行步骤2所述的直方图均衡;
完成预处理后,分别对训练集和测试集中的智齿切片进行像素级标注,标签为二值图像,灰度255为前景,0为背景,如图3(b)和图4(b)所示,得到用于智齿分割任务的新训练集和测试集;
步骤4:
使用基于python的keras框架搭建u-net模型,调整输入和输出相关的尺寸设置,选用focalloss作为训练u-net的损失函数,focalloss的形式如下:
其中,i,j表示图片中的像素点,n表示图片编号,图片总数为n,
训练过程使用的学习率设置为0.0005,迭代次数设置为200,优化器设置为adam,激活函数设置为relu,输入128个训练样本对u-net模型进行训练,得到收敛后的权重,并将测试集中的56个样本输入训练好的u-net模型,得到智齿分割的预测结果dice系数为0.8827,并得到每个输入对应的分割结果灰度图像;图4(a)是输入样本,图4(b)是像素级分类的标签,图4(c)是u-net输出结果。
最后设置判断前景与背景的阈值为0.6,对灰度图像进行二值化处理,得到最后仅包含前景与背景的二值图像,即最终的分割结果。
- 还没有人留言评论。精彩留言会获得点赞!