一种基于语义位置网的地址位置推测方法
本发明涉及一种地址位置推测方法,尤其涉及一种基于语义位置网的地址位置推测方法。
背景技术:
随着数字城市的快速发展,城市当中的各种数据都会进入到城市信息空间下面,根据位置对这些数据进行整合和共享是数字城市的终极目标。地址作为描述位置的数据形式,广泛存在于城市的各个部分,是一种非常适用于沟通城市不同领域数据的桥梁。今后,不论是在城市规划、行政管理、科学研究还是百姓生活等各领域,对地址空间定位的需求将会越来越广泛,对位置的精度要求也越来越高。提供准确的地址定位,成为数字城市以及智慧城市必须面对的问题。
针对这个问题,目前的主要方法是采用地理编码技术,它作为地理信息系统(gis)领域下的重要研究和应用领域,能够提供强大的解决方案。但是对于数字城市下各领域不同地址库中的地址,地址编码技术在地址位置定位时依然存在地址解析错误、地址匹配困难和缺乏地址位置推理能力的问题。针对地址位置定位中的前两个问题,国内外已经有很多相关的研究和专利,而对于地址位置推测,相关研究很少,本发明提出一种基于语义位置网的地址位置推测方法。本发明提出了一种对地址库中缺失地址进行定位、提高地址的定位精度的地址位置定位方法。
语义位置网是在地址元素编码基础上,针对基础地址语义空间和地理位置空间关系映射进行管理的结构模型。语义位置网中语义关系、空间关系、节点关系等可以有效改变现有地址编码对地理空间和语义空间的一对一映射关系,为地址位置的推理提供更多参考信息。
技术实现要素:
为了实现对地址库中缺失的地址进行定位和提高地址的定位精度,本发明以此为出发点,提出一种基于语义位置网的地址位置推测方法,其实现复杂度较低,可以在构建语义位置网的基础上实现地址位置的推理定位。
方法步骤描述如下:
一种基于语义位置网的地址位置推测方法,其特征在于:包括以下步骤:
步骤1、对用来构建语义位置网的地址库中的地址进行预处理,具体是去除没有数字门牌号和字段重复的地址。处理后的地址库中地址的地址地段都唯一并且包含数字门牌号。
步骤2、将步骤1中处理过的数据进行切分,构建语义位置网;
步骤3、从语义位置网中获取待推测地址的空间包围盒;
步骤4、从空间包围盒中获取最优分布;
步骤5、从最优分布中提取方向、角度、距离这三种参数信息,结合最优分布中点集的空间坐标进行计算,得到待推测地址的空间坐标。
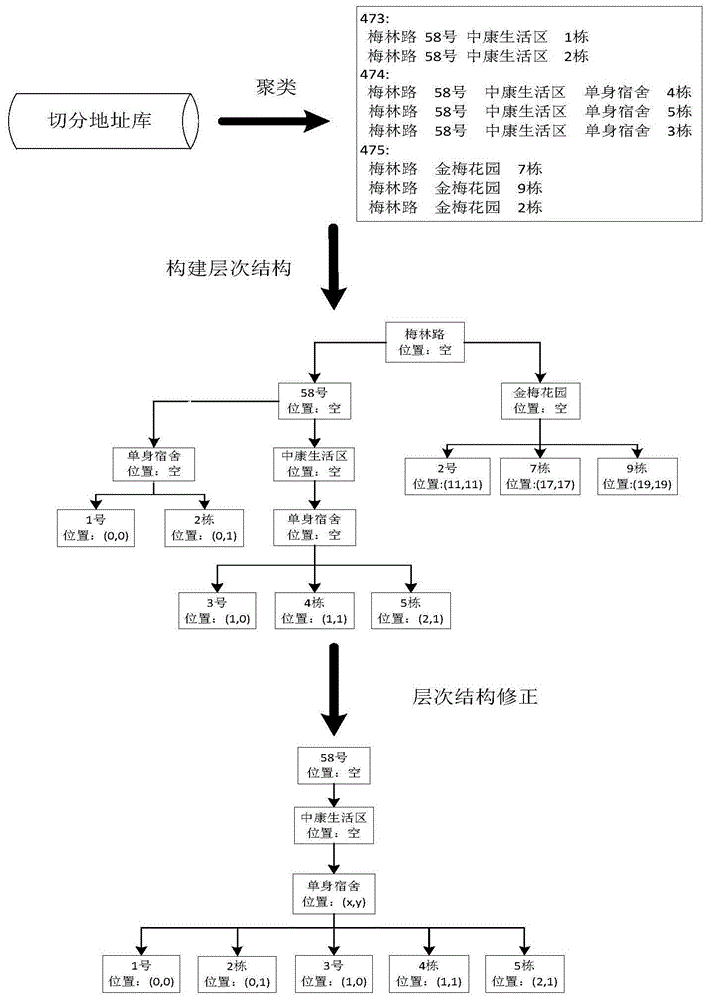
在上述的一种基于语义位置网的地址位置推测方法,在步骤2中,需要将经过预处理的地址库中的地址进行切分,然后对切分结果进行聚类,根据聚类结果生成语义位置网初始层次结构,最后对初始层次结构中的问题进行修正,得到最终语义位置网,具体包括:
步骤2.1:采用目前常用的基于规则与统计的方法对地址进行地址元素的解析和提取,完成对经过预处理的地址库中的地址的切分。
步骤2.2:将切分后的地址根据地址字符串中相同位置字符串拼音首字母的ascii码大小按照升序进行排列,排列后可以将地址库中相邻的地址放在序列当中邻接位置,通过计算邻接地址之间的相似度,将地址结构近似的地址放到同一个类,完成地址库聚类。
步骤2.3:将每个类中的地址按照地址元素的等级构建语义位置网的初始层次结构,然后完成地址不完整修正和地址空间位置错误修正,形成最终的语义位置网结构。
在上述的一种基于语义位置网的地址位置推测方法,在步骤3中,从步骤2获取的语义位置网中获取和待推测地址具有语义形似关系的位置单元集合,这些单元集合构成的空间范围代表了待推测地址的空间范围,这个范围即为所求空间包围盒,具体包括:
步骤3.1:根据待预测地址的地址元素组成,从步骤2中获得的语义位置网中找到与待预测地址具有语义相近关系的位置单元。
步骤3.2:根据位置单元所构成的地址集合的空间位置,得到待预测地址可能的空间范围。
在上述的一种基于语义位置网的地址位置推测方法,在步骤4中,根据邻接距离和邻接语义位置最小原则,从包围盒中选取8到20个点,这些点集的空间分布称为最优分布。
步骤4.1:在空间包围盒所包含的点集之中,根据点集数量确定要用来构成最优分布的点的数量n,n范围为8到20。
步骤4.2:根据邻接距离和邻接语义距离的定义,从空间包围盒中确定n的点,分别能够使邻接距离最小和邻接语义距离最小,得到邻接距离最小对应的空间分布,邻接语义距离最小对应的空间分布。
在上述的一种基于语义位置网的地址位置推测方法,在步骤5中,从最优分布中提取方向、角度和距离信息。
步骤5.1:从最优分布中提取方向信息,同方向表示待预测点相对于基准线的偏转方向和基准点与前邻段线之间的偏转方向相同;反方向表示被预测点相对于基准线的偏转方向与基准点与其前邻段线之间的偏转方向相反,统计最优分布中点集所处方向的占比,待预测地址所采用的方向策略和占比大的方向一致。
步骤5.2:从最优分布中提取角度信息,角度采用最优分布中所有点相对于其前邻段线之间偏转角度的统计平均值。
步骤5.3:从最优分布中提取距离信息,距离采取从基准点到起点全部线段的欧式距离除以语义距离比值后的统计平均值。
在上述的一种基于语义位置网的地址位置推测方法,在步骤5中,将最优分布中点集的空间坐标信息和获取的方向、角度和距离信息汇集在一起,完成地址推测的数学计算。
步骤6.1:在最优分布中确定与待预测地址语义最为邻近的地址,得到其空间坐标(x1,y1)。
步骤6.2:根据步骤5所获得的方向d,角度a,距离l信息。将空间坐标(x1,y1)沿基准线平移距离l,得到坐标(x2,y2)。
步骤6.3:将坐标(x2,y2)沿着方向d旋转角度a,得到坐标(x3,y3),即为所求待预测地址的空间位置。
因此,本发明具有如下优点:能有效地对未被包含在地址库中的地址进行有效的预测,解决现有的地址数据库虽然覆盖面广泛但仍存在地址数据缺失的问题。同时也能够用于提高地址定位精度,满足人们对高精度的定位服务的需求。
附图说明
图1是语义位置网构建流程示意图。
图2是地址包围盒获取方法示意图。
图3是从最优分布中获取方向、角度和距离示意图。
图4是一种基于语义位置网的地址位置推测方法流程图。
具体实施方式
步骤1:对地址库中的地址进行预处理,去除地址字段中没有数字门牌号的地址,去除地址字段重复的地址。
步骤2:如图1所示,将经过预处理的地址库中的地址进行切分,对切分结果进行初始聚类,根据初始聚类生成语义位置网初始层次结构,最后对初始层次结构中的问题进行修正,得到语义位置网。
步骤3:如图2所示,给定待推测的地址位置,取地址的空间包围盒可以看作根据原始地址获取的语义位置网中和该地址具有语义形似关系的位置单元集合,由这些单元集合构成的空间范围代表了待推测地址的空间范围,这个范围被称为包围盒。
步骤4:得到包围盒之后,需要得到这些地址在地址的语义编码和空间上表现出来的连续性特征,即包围盒的空间分布。包围盒中点集数量往往多达上百,对于位置推测计算,本发明从点集中取8个到20个点。在本发明中,将每个地址仅包含的地址字段和位置坐标都转换为可计算的度量,将地址之间的编码之间的差异称为语义距离,例如地址“爱华路2号”和“爱华路8号”分别对应语义编号为2号和8号,所以它们之间的语义距离等于2。结合欧式距离,本发明提出邻接距离和邻接语义距离的公式,如表1所示,ck代表一个分布,pi代表分布的点,其中邻接距离(adjacentdistance)用于计算分组中邻接两点之间的平均欧式距离差值。邻接语义距离(adjacentsemanticdistance)用于计算分组中邻接两点之间欧式距离除以语义距离差值的平均。根据邻接距离最优和邻接语义距离最优,可从包围盒中选取合适数量点集,得到最优分布。
表1.点集分布的度量公式和最优分布策略
步骤5:根据步骤4得到的最优分布,从中获取方向、角度、距离参数信息,如图3所示,本发明中方向选择有两种,一种是同方向,同方向表示被推测点相对于基准线的偏转方向和基准点和其前邻段线之间的偏转方向相同,反方向表示表示被推测点相对于基准线的偏转方向和基准点与其前邻段线之间的偏转方向相反,具体选取根据最优分布中方向的占比确定。角度采用分布中所有点相对于其前邻段线之间偏转角度的统计平均值。距离则是采用平均语义距离,即从基准点到起点全部线段的欧式距离与语义距离比值的统计平均值。
步骤6:根据步骤5中从最优分布中得到了方向、角度和距离这三种参数信息,结合最优分布中已知的点集的地址坐标,进行相应的数学计算,即可求出待推测地址的空间坐标。
本文中所描述的具体实施例仅对本发明精神作举例说明。本发明所属技术领域的技术人员可以对所描述的具体实施例进行各种各样的修改、补充或采用类似的方式对其中部分技术特征进行等同替换,但并不会偏离本发明的精神或者超越所附权利要求书所定义的范围。
- 还没有人留言评论。精彩留言会获得点赞!