一种作物产量的预测方法、系统、存储介质和电子设备与流程
本发明涉及农业
技术领域:
,尤其涉及一种作物产量的预测方法、系统、存储介质和电子设备。
背景技术:
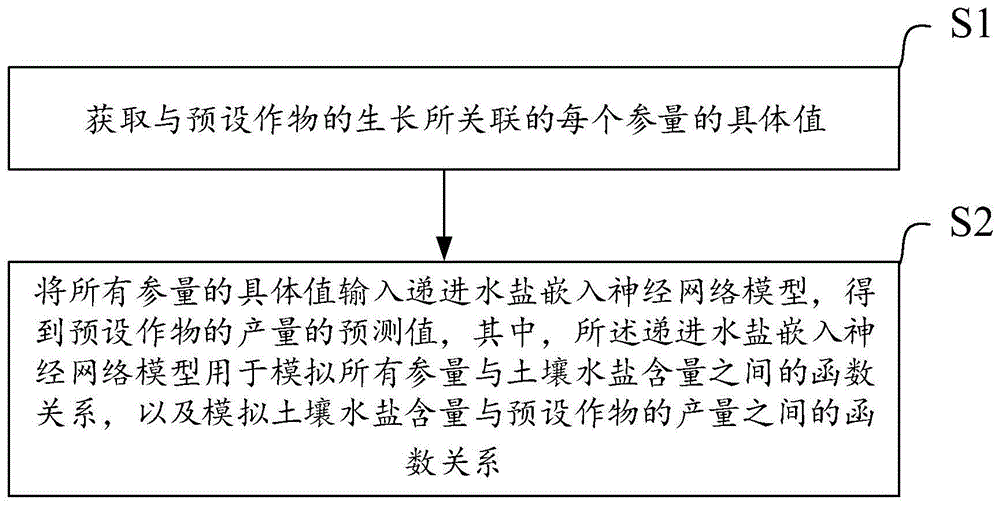
:河套灌区是我国重要的粮食生产基地。因引黄水量锐减、水资源管理利用不完善,导致灌区土壤次生盐渍化、农业面源污染等问题日益严重,制约着灌区农业持续健康发展。如何改良盐渍地、提效增产是灌区面临的主要问题。灌区盐渍土水盐分布影响着作物生长,研究水盐运移可为灌区提效增产、缓解土壤次生盐渍化提供理论依据。作物生育期,土壤水盐分布受气象、灌溉等多重因素的影响,水盐间相互作用,关系复杂,且水盐分布进一步会影响作物生产效益(产量、水分利用率等)。目前,研究土壤水盐分布的模型主要有:一是以水盐平衡为基础的水盐平衡模型;二是将水盐运移作为随机过程处理的系统模型。常用的模型有:hydrus、swap、feflow等,这些模型均进行了广泛的应用,并取得了一定的成果。然而,土壤水分运动及溶质运移方程的求解往往因边界条件复杂、计算参数众多等,在土壤水盐运移中运用受限,无法模拟大田秸秆深埋下不同灌水量及其它气候、生长因素对土壤水盐运移、作物生产效益的影响。技术实现要素:本发明所要解决的技术问题是针对现有技术的不足,提供了一种作物产量的预测方法、系统、存储介质和电子设备。本发明的一种作物产量的预测方法的技术方案如下:获取与预设作物的生长所关联的每个参量的具体值;将所有参量的具体值输入递进水盐嵌入神经网络模型,得到预设作物的产量的预测值。其中,所述递进水盐嵌入神经网络模型用于模拟所有参量与土壤水盐含量之间的函数关系,以及模拟土壤水盐含量与预设作物的产量之间的函数关系。本发明的一种作物产量的预测方法的有益效果如下:递进水盐嵌入神经网络模型包括2层递进因果关系,体现为:利用所有参量与土壤水盐含量之间的函数关系得到土壤水盐含量的具体值,基于土壤水盐含量的具体值,并利用土壤水盐含量与预设作物的产量之间的函数关系,得到预设作物的产量的预测值,模拟大田秸秆深埋下不同灌水量及其他气候、生长因素对土壤水盐运移、作物生产效益的影响。试验结果表明,递进水盐嵌入神经网络模型具有较高精度,能够有效表征预设作物生长的综合条件即关联的每个参量、土壤水盐含量运移与预设作物的产量三者间双层递进因果关系,捕捉各参变量内在依存联系,可用于模拟灌区水盐运移规律。在上述方案的基础上,本发明的一种作物产量的预测方法还可以做如下改进。进一步,还包括:将分级长短记忆网络构架的时间序列化数据构造的编码器与批标准化多层感知机构造的解码器进行耦合,并进行训练,得到所述递进水盐嵌入神经网络模型。进一步,训练所述递进水盐嵌入神经网络模型之前,还包括:采用dropout算法与adam算法进行耦合作为训练所述递进水盐嵌入神经网络模型时的收敛算法。本发明的一种作物产量的预测系统的技术方案如下:包括获取模块和预测模块,所述获取模块用于获取与预设作物的生长所关联的每个参量的具体值;所述预测模块用于将所有参量的具体值输入递进水盐嵌入神经网络模型,得到预设作物的产量的预测值,其中,所述递进水盐嵌入神经网络模型用于模拟所有参量与土壤水盐含量之间的函数关系,以及模拟土壤水盐含量与预设作物的产量之间的函数关系。本发明的一种作物产量的预测系统的有益效果如下:递进水盐嵌入神经网络模型包括2层递进因果关系,体现为:利用所有参量与土壤水盐含量之间的函数关系得到土壤水盐含量的具体值,基于土壤水盐含量的具体值,并利用土壤水盐含量与预设作物的产量之间的函数关系,得到预设作物的产量的预测值,模拟大田秸秆深埋下不同灌水量及其他气候、生长因素对土壤水盐运移、作物生产效益的影响,通过试验结果表明,递进水盐嵌入神经网络模型具有较高精度,能够有效表征预设作物生长的综合条件即关联的每个参量、土壤水盐含量运移与预设作物的产量三者间双层递进因果关系,捕捉各参变量内在依存联系,可用于模拟灌区水盐运移规律。在上述方案的基础上,本发明的一种作物产量的预测系统还可以做如下改进。进一步,还包括训练模块,所述训练模块用于:将分级长短记忆网络构架的时间序列化数据构造的编码器与批标准化多层感知机构造的解码器进行耦合,并进行训练,得到所述递进水盐嵌入神经网络模型。进一步,所述训练模块还用于:采用dropout算法与adam算法进行耦合作为训练所述递进水盐嵌入神经网络模型时的收敛算法。本发明的一种存储介质,所述存储介质中存储有指令,当计算机读取所述指令时,使所述计算机执行上述任一项所述的一种作物产量的预测方法。本发明的一种电子设备,包括处理器和上述的存储介质,所述处理器执行所述存储介质中的指令。附图说明图1为本发明实施例的一种作物产量的预测方法的流程示意图;图2为循环神经网络架构示意图;图3为短期记忆模型示意图;图4为递进水盐嵌入神经网络模型的架构示意图;图5为不同灌水量在播种后在不同时间点的土壤含水率的率定图;图6为不同灌水量在播种后在不同时间点的土壤含盐量的率定图;图7为夏玉米产量和水分生产率的率定图;图8为不同灌水量下土壤含水率的实测值与模拟值之间的数据对比图;图9为不同灌水量下土壤含盐量的实测值与模拟值的数据对比图;图10为不同灌水量下夏玉米产量和水分生产率实测值与模拟值的数据对比图;图11为单次灌溉量为60mm时,整个生育期各土层的土壤含水率的模拟值;图12为单次灌溉量为90mm时,整个生育期各土层的土壤含水率的模拟值;图13为单次灌溉量为120mm时,整个生育期各土层的土壤含水率的模拟值;图14为单次灌溉量为135mm时,整个生育期各土层的土壤含水率的模拟值;图15为单次灌溉量为60mm时,整个生育期各土层的土壤含盐量的模拟值;图16为单次灌溉量为90mm时,整个生育期各土层的土壤含盐量的模拟值;图17为单次灌溉量为120mm时,整个生育期各土层的土壤含盐量的模拟值;图18为单次灌溉量为135mm时,整个生育期各土层的土壤含盐量的模拟值;图19为不同灌水量夏玉米产量和水分生产率的模拟值;图20为本发明实施例的一种作物产量的预测系统的结构示意图。具体实施方式如图1所示,本发明实施例的一种作物产量的预测方法,包括如下步骤:s1、获取与预设作物的生长所关联的每个参量的具体值;s2、将所有参量的具体值输入递进水盐嵌入神经网络模型,得到预设作物的产量的预测值,其中,所述递进水盐嵌入神经网络模型用于模拟所有参量与土壤水盐含量之间的函数关系,以及模拟土壤水盐含量与预设作物的产量之间的函数关系。递进水盐嵌入神经网络模型包括2层递进因果关系,体现为:利用所有参量与土壤水盐含量之间的函数关系得到土壤水盐含量的具体值,基于土壤水盐含量的具体值,并利用土壤水盐含量与预设作物的产量之间的函数关系,得到预设作物的产量的预测值,模拟大田秸秆深埋下不同灌水量及其他气候、生长因素对土壤水盐运移、作物生产效益的影响,通过试验结果表明,递进水盐嵌入神经网络模型具有较高精度,能够有效表征预设作物生长的综合条件即关联的每个参量、土壤水盐含量运移与预设作物的产量三者间双层递进因果关系,捕捉各参变量内在依存联系,可用于模拟灌区水盐运移规律。其中,与预设作物的生长所关联的参量包括:地温、气温、辐射量、co2浓度、降水量、灌水量、土层深度、生育期时长及秸秆深埋等;预设作物可为玉米或小麦等;较优地,在上述技术方案中,还包括:将分级长短记忆网络构架的时间序列化数据构造的编码器与批标准化多层感知机构造的解码器进行耦合,并进行训练,得到所述递进水盐嵌入神经网络模型。较优地,在上述技术方案中,训练所述递进水盐嵌入神经网络模型之前,还包括:采用dropout算法与adam算法进行耦合作为训练所述递进水盐嵌入神经网络模型时的收敛算法。其中,“耦合”指:是指两个或两个以上的体系或运动间通过相互作用而彼此影响以至联合起来的现象。本申请中,将分级长短记忆网络构架的时间序列化数据构造的编码器与批标准化多层感知机构造的解码器进行耦合具体体现在:编码器与解码器耦合是通过土壤水盐分布联系起来,相互作用。dropout算法与adam算法进行耦合具体体现在:adam算法在编码器作用下模拟出土壤水盐分布,然后解码器通过dropout算法模拟作物生产效益,二者间相互影响。通过下面一个实施例对本申请的一种作物产量的预测方法进行详细说明:s10、选取试验区,具体地:田间试验于2017—2019年每年的5月至9月在河套灌区临河区双河镇农业节水示范区开展。s11、田间试验设计,具体地:田间试验于上一年秋浇前在35cm土层人工铺设5cm粉碎玉米秸秆,平整耕地,第2年5月初浅耙覆膜种植。秸秆深埋后形成土层依次为:耕作层(0~35cm)、秸秆隔层(35~40cm)、心土层(秸秆隔层以下土层)。试验设秸秆深埋下单次灌水定额60mm(w1)、90mm(w2)、120mm(w3)及当地135mm(ck),共4个处理,3次重复,12个小区,小区面积72m2,各小区间设2m保护带,四周用埋深1.2m聚乙烯塑料膜隔开,顶部留30cm,防止水肥互窜,田间管理与当地农户管理一致。供试材料为钧凯918玉米,5月初机械播种,9月末收获,株距0.35m,行距0.45m。s12、样品采集与分析,具体地:①土壤含水率及土壤含盐量:在播种前和每次灌水前、后(下雨后2~3d即2~3天加测一次),用土钻分别在0~20cm、20~40cm、40~60cm、60~80cm、80~100cm土层取样,测定土壤含水率及电导率。采用干燥称重测定土壤含水率,即质量含水率;将土样风干、经磨碎、过筛,以1:5的土水比例提取清液,用dds-307型电导率仪测定土壤电导率。土壤含盐量与土壤电导率ec1:5之间的关系式为si=2.5991ec1:5,i+0.4682(r2=0.997);②夏玉米考种测产及水分利用效率:每个小区随机选取10株夏玉米,测量夏玉米穗长、穗粗、百粒质量等产量的相关指标;干燥后称总质量并计算单位面积产量。作物耗水量(evaporationandtranspirationofcrop,et)的计算式为et=p+i+wg-d-r-δw;其中,et为作物耗水量,单位为:mm;p为生育期降雨量,mm;i为灌溉量,mm;wg为地下水补给量,mm;d为渗漏水量,mm,该示范区地下水位较高,地下水补给量远大于渗漏水量,故d忽略不计;r为地表径流,单位为:mm,该示范区地面平坦,无地表径流,r可忽略;△w为试验初期到末期土壤储水量的变化量,单位为:mm;s13、建立递进水盐嵌入神经网络模型:1)递进水盐嵌入神经网络模型的基本原理:本申请使用python进行编码,在pytorch框架上架构递进水盐嵌入神经网络(progressivesalt-waterembeddingneuralnetwork,pswe)模型,并进行模型的模拟与预测。pswe模型由分级长短记忆网络(hierarchicallongshort-termmemory,hlstm)编码器与批标准化多层感知机(batch-normalizedmulti-layerperceptron,bmlp)构造的解码器进行耦合,采用优化dropout和adam算法的耦合后作为pswe模型的收敛算法,即采用dropout算法与adam算法进行耦合作为训练所述递进水盐嵌入神经网络模型时的收敛算法,并进行数据的训练和优化。即:分级长短记忆网络(hlstm)编码器构架时间化序列数据,对以天为单位记录的农田气象数据、灌溉定额及土层深度进行学习并整体嵌入到一个低维度欧几里得空间中,同时对生长及气候条件、与土壤水盐间的因果关系进行学习与分析,最终学习到的土壤水盐动态变化情况。承接hlstm编码器所得结果,bmlp构造的解码器对土壤水盐动态变化与夏玉米生产效益之间的因果关系进行进一步分析与学习,得到作物产量、水分利用效率的预测结果。hlstm时间序列编码器与bmlp解码器在相互迭代更新学习的过程中,充分捕捉了夏玉米各项指标在生长时间序列上的依存关系,并协同分析了不同灌水量、生育期时长、土层深度、秸秆深埋及气候条件(地温、气温、辐射、co2浓度、降水量)对土壤水盐分布以及作物生产效益(产量、水分利用效率)的多维度影响,最终达到对土壤水盐运移、作物产量和水分利用率的准确预测。具体来讲,本文使用[x0,x1,x2,…,xt]来表示每个时间点上的夏玉米各项指标(灌水、生育期时长、土层深度及气候条件),其中每个x为一个m维的向量,m为每个时间点夏玉米指标的数量(本文中m=9)。时间序列化使得x自然拥有依次生成的性质,而深度学习(deeplearning)中的循环神经网络(recurrentneuralnetwork,rnn)可有效的模拟这一过程。因此,基于n阶马尔科夫链(markovchainofordern)的夏玉米在各个时间点上的各项指标值依次发生的概率为:式中,x为每个时间点上的夏玉米各项数据指标,为一个m维向量;t为夏玉米的整个生长周期,单位是天。对hlstm编码器、dropout算法、批标准化、adam算法进行具体解释,具体地:①hlstm编码器:是一种优化的循环神经网络(rnn)。rnn是一种定向连接成环的人工神经网络,其内部状态可分析动态时间序列,在保持内部状态的同时,将前一个样本的输出作为下一个样本输入的一部分传输到下一层,传输过程如图2所示。给定时间序列[x0,x1,x2,…,xt],rnn对应输出一个序列[h0,h1,h2,…,ht]。rnn每次的激活函数at的数学表达式为:式中,waa和wax分别为rnn中前一个输出和输入值的权重;ba为输入值偏差;为rnn的激活函数,如s型函数、正切函数和线性整流函数。输出项ht计算如式为:ht=φ(whaa(t)+bh),其中,wha为权重系数,bh为输出偏差,φ为输出激活函数,与可以不同。rnn架构在输入和输出较易对齐,二者间映射变化较多(如多对多、一对多和多对一)。但rnn存在梯度消失和爆炸的问题,随着神经网络输入的时间序列增加,反向传播的梯度累积到爆炸或者消失,限制了神经网络捕捉长期的记忆。而基于内存长短期记忆模型(lstm)使用三个专门设计的内部逻辑门有效的解决了这个问题。lstm进一步发展了rnn的记忆机制,满足了在未知持续时间滞后的情况下对时间轨迹进行分类、处理和预测。与rnn相比,lstm构造优势在于三个门:输入门、遗忘门和输出门,结构如图3所示,图3中σ和φ分布代表s型函数和双曲正切函数;为各元素间的相乘运算。输入门负责评估输入的数据流中的哪个值及具体值的大小应被用于记忆单元的调整与修改,即是将0~1间的输入数据和上一层隐藏数据通过s型函数进行合并和归一化,计算如下式所示:it=σ(xtwi+ht-1vi+bi);其中,it为时间节点t上的输入,ht-1为前一层隐层输出。wi,vi,bi分别是网络输入数据的学习权重值及输入偏差,σ为s型激活函数。然后使用正切激活函数对从-1到1的输入门的值进行加权:pt=φ(xtwp+ht-1vp+bp),其中,wp,vp,bp分别为与公式it=σ(xtwi+ht-1vi+bi)不同的网络输入数据学习权重值及输入偏差,φ代表正切激活函数。lstm的输入门的最终结果用it和pt点乘结果表示,如下式所示:根据制定的算法判断信息是否可用,符合规则的信息被利用,否则通过遗忘门被遗忘。遗忘门通过s型激活函数决定被遗忘的信息及数量,计算如下式所示:ft=σ(xtwf+ht-1vf+bf);当前t时间点的内存状态是当前输入流与过滤后的前一个内存状态的聚合,如下式所示:其中,st-1为最后一个时间点t-1的存储状态。输出门结合标准化后的数据输入和当前时间节点t的内存状态,通过元素式多重运算操作,可以得到时间节点t的隐层表达式:ot=σ(xtwo+ht-1vo+bo);其中,ht为时间节点t的隐层输出结果。每一个时间节点输出ot与该时间节点对应的土壤含水率及土壤含盐量利用huberloss进行损失计算:利用输入(灌水量、生育期时长、土层深度及气候条件指标)与输出(土壤含水率、土壤含盐量)之间的更新与映射。最后一个时间节点的隐层表示h被提取,作为学到整个时间序列上各项指标的嵌入(embedding),同时也是mlp解码器的输入项。其中,激活函数如下:将非线性函数引入到神经网络中,使神经网络能够依据输入流的分布较为随机的逼近真实的复杂函数。当无激活函数时,线性函数关系使得多层架构相当于单层模型。然而,目前许多研究均未正确地采用激活函数,大部分模型中采用s型函数作为激活函数,往往不能得到最优解。下面将说明s型函数不适用于农业水土工程的原因,并将直线整流函数(rectifiedlinearunit,relu)引入到所提出的递进水盐嵌入网络模型中。s型激活函数,又称作物生长函数,数学表达式为:从图4和公式可知,s型激活函数压缩变化的数值范围在0~1之间,这往往导致神经网络饱和时,神经元梯度易为0(隐藏的神经元的梯度值趋于0或1时,均取0)。显然,饱和神经元的权重值参数无法及时更新。同时,梯度更新在这些连接的饱和神经元中传播缓慢,这种现象称为梯度消失。此外,如果将其应用到每一层上,e-x运算使得s型函数计算成本很高,这也是现代深度学习架构弃用s型函数另一个原因。而直线整流函数(relu)有效地解决上述问题。relu函数其表达式为:relu(x)=max(0,x),具体地:当x<0时,relu函数输出为零,否则,x保持原始值,这样使得整个神经网络的传播和收敛方式更有效。由于relu将神经元从限制的边界中解放出来,至少有一定数量的神经元在正区域进行反向传播,避免了梯度消失的问题。本申请将relu函数应用于每一隐层并进行非线性变换,运算式为:②dropout算法:在模型训练数据集有限的情况下,深度复杂的网络结构通常会导致网络在训练过程中对输入的数据进行强行过度拟合,这称为过拟合或协同适应。dropout是一种计算成本低(计算复杂度为o(n))且可有效的解决模型训练数据有限的算法,它通过每次训练随机迭代出暂时闲置非线性模型中的非输出神经元。具体来说,dropout算法是对二进制掩码进行采样,将网络中输入和隐藏层生成结果相乘,并在训练迭代中暂时剔除输出值为0的元素。由于二进制掩码的采样是相互独立的,采样值为1的概率是整个神经网络的一个预定义超参数,参照公式ft=σ(xtwf+ht-1vf+bf),dropout的层级计算表达式如下式所示:hl=(hl-1⊙dl-1)twl+bl;d~bernoulli(p),其中,⊙为各元素点乘运算,dl-1为dropout算法中第l-1层掩码,p为模型训练前的预定义超参数。③批标准化:下面将如何对学习到的隐层表示进行标准化的批处理进行详细说明。当深度神经网络从深度架构中获得较好的泛化能力时,输入的数据在神经网络中各层的学习参数转换的过程中,也使得模型训练变得更加复杂。在这种情况下,随着网络结构的加深(即层数的增加),架构中这些参数的微小变化将被放大。由于每一层输入分布的移位,要求后续的各层输入不断服从新的分布规则,极大地削弱了模型训练过程的稳定性,也削弱了模型本身的稳定性。考虑到文中使用的六层ppn模型同样会遇到上述问题,本文利用标准化批处理来增强训练迭代,增强模型的稳定性。标准化批处理运算分为四步:首先,给定一个最小的批处理b,得到b中所有元素的均值,如下式所示:其中,m是批处理的样本的数量,采用各批次处理的平均值;然后,计算μβ对应的方差具体通过计算μβ对应的方差标准化批处理即批标准化操作可以用样本批次的μβ和表示为:其中,ε是个很小的值,但不等于0。最后通过2个可以学习的参数γ和β对标准化批处理隐层进行缩放和移位:其中,γ为缩放参数,β是移位参数,通过模型训练得到的用来提高递进水盐嵌入神经网络模型的表达能力,批量标准化转换建模算法如下:要求:b={hl1,...,hlm}:第l层隐层小批处理;l为数据层级;m为小批量b的样本的数量;γ为缩放参数,可学习得到;β为移位参数,可学习得到;输出:1:l=1,2,3...l;2:更新最小批量样本平均值:3:更新最小批量样本方差,附式(32):4:最小批量样本隐层规范化,附式(33):5:标准化批处理隐层缩放和移位,附式(34):6:结束④adam算法:要求:b={x1,...,xm},各个x对应相应的y值;m为小批量b的样本的数量;t为运算的迭代步数;v为动量项;s为指数损失平均值;βv为动量项的非负超参数;βs为指数损失平均值的非负超参数;ε是个很小的值,但不等于0;初始化:v=0,s=01:t=0,1,2,...,t2:生成累积梯度:3:t=t+14:动量项运算:5:指数损失平均值运算:6:动量项的偏差修正:7:指数损失平均值项偏差修正:8:重新调试梯度:9:更新参数:10:结束;2)批标准化mlp解码器:通过对夏玉米生育期内所有时间节点上各指标学习,从hlstm编码器得到各项指标嵌入,作为bmlp解码器的输入项,从而很好的捕获了生长时间序列上多变量的变化信息及其与土壤水盐动态变化间的因果关系。而利用bmlp解码器,将进一步获取土壤水盐变化与产量和水利用率之间的因果关系。hlstm编码器和bmlp解码器学习并获取2层递进的因果关系,更新整个pswe模型,有效完整的获取整个夏玉米生长链的多维度时间序列参变量。其中,层式仿射转换:递进水盐嵌入神经网络中的批处理mlp解码器是一种具有双隐含层的神经网络结构,各层间信息流的精确仿射转换至关重要。一般情况下,各层学习参数θ包含权矩阵w和偏差参数b。批标准化的mlp解码器第l隐层hl表达式可以定义为:hl(hl-1,wl,b1)=hlt-1wl+bl,其中,wl和bl为第l层的学习权重和偏差参数,hl-1为上一层的值;当l=1时,h0=embedding(embedding在本文中是一个专业名词,即:水盐嵌入)。使用层级间的更新规则,给定的输入数据通过层级的运算,最终输出结果。最后一层的隐层表达h1(一个2维向量)将与对应的田间实测产量与水利用率使用huberloss进行损失计算:lmlp=huber_loss(h1,y(yield,water-efficency));3)模型建立,具体地:递进水盐嵌入神经网络通过分级长短记忆网络hlstm构造的编码器与批标准化mlp构造解码器耦合所计算的损失对整体模型进行协同更新,使得整个递进水盐嵌入神经网络模型能有效的获取夏玉米的整个生长周期中的各项生长指标到土壤水盐动态变化,再从土壤水盐变化到产量、水利用率间的递进因果关系,以达到大幅提高预测精度的目的。具体来讲,递进水盐嵌入神经网络的最终损失函数计算值为公式和公式lmlp=huber_loss(h1,y(yieldwater-efficency))计算的平均值,即:因农田水利中广泛应用的均方根误差(rootmeansquareerror,rmse)和均方误差(meansquareerror,mse)会对数据中的异常值进行敏感拟合,并不适合数据分布并不平滑的农田水利数据。因此本文采用huberloss函数(也称为平滑l1loss函数)进行损失计算。同时,为了增强递进神经网络的的稳定性,本申请同样采用huberloss函数作为目标函数来计算梯度并实时更新pswe模型。huberloss函数采用下式的分段定义,该函数本质上平衡了rmse对异常值过于灵敏和平均绝对误差(mae)对异常值的钝性:其中,κ起到平衡调节作用,当损失值小于κ时,huberloss函数会通过线性运算放大loss的值;当loss的值小于1时,huberloss可以通过二次方程来降低线性运算的损失。目前采用随机梯度下降(sgd)作为优化器的神经网络(即:水利中的bp神经网络)在峰值处梯度比较平缓,未立即收缩或减小,且网络中所有参数的学习速率都是统一的。与上述模型不同的是,递进水盐嵌入神经网络在模型训练过程中利用adam优化算法使其能够更稳定、平滑地收敛。adam优化算法的两个基本组成部分是动量项v和指数加权移动平均项s(也称为指数损失平均值),两者通常初始值均为零。动量项v累积梯度元g减小梯度方差计算如下式所示:vt=βvvt-1+(1-βv)gt;其中,累积的梯度元推导得:其中,t为迭代步长,β为控制当前步长下降方向梯度的卷积,0≤β≤1;将指数加权移动平均项s的梯度方差累积以获得每个参数的学习速率:st=βsst-1+(1-βs)gt⊙gt;值得注意的是,由于v0和s0初始值均为0,造成大量的偏差主要倾向于小的值,为纠正这个问题,将vt和st重新归一化,使得所有步骤各项值总和为1,此纠正称为偏差校正:对vt进行偏差校正,得到:类似有:通过对vt和st进行偏差校正,可以对神经网络参数中各元素的梯度进行如下调整:其中,δ为预定义的学习速率,ε为数值稳定化且非常小的常数。参数更新可采用如下形式:至此,整个基于深度学习的递进水盐嵌入神经网络模型(pswe)建立完成,此时可以根据hlstm构造的编码器与bmlp构造的解码器中获取的2层递进因果关系进行迭代更新,对土壤水盐动态变化及作物生产效益进行模拟与预测。pswe模型架构示意图图4所示。s14、递进水盐嵌入神经网络模型率定与检验,具体地:s140、参数选取及样本处理,具体地:根据试验区实际情况,以秸秆深埋下不同灌水量处理的大田试验实测数据为基础,选取气候条件(地温、气温、辐射量、co2浓度、降水量)、灌溉条件(不同灌水量、土层深度)、生育期时长及秸秆深埋等9个参变量作为hlstm编码器的输入参数(第一层次输入),探寻上述参变量在时间序列上的自然发展逻辑,将其整体嵌入到一个低维欧几里得空间中,模拟各时间点的土壤水盐含量(第一层次输出),并与实测的土壤水盐含量对比,并迭代更新编码器,同时捕获:1)9个参变量在时间序列上的内在依存关系;2)各参变量与土壤水盐间的因果关系(第一层因果关系)。从hlstm编码器获得的土壤水盐含量的数值作为bmlp解码器的输入(第二层次输入),预测作物产量与水分利用效率(第二层次输出),并与田间实测数据对比验证,对bmlp解码器进行迭代更新,捕获各参变量和土壤水盐含量与作物生产效益间的因果关系(第二层因果关系),以此架构出pswe模型。所有相关样本均参与神经网络训练与检验。各参变量在数值上相差较大,且量纲也不尽相同,若直接训练会影响模型的学习速率和精度,故在训练之前对已有数据进行规范化预处理,并留一定的预报空间,训练时将数据归一化到[0,1]之间。s141、数据集划分及模型评价:本申请采用均方根误差(rootmeansquareerror,rmse)、平均绝对误差(meanabsolutedeviation,mae)及决定系数(coefficientofdetermination,r2)对模型的模拟效果评价,模型率定和检验的各指标均采用实测值与模拟值计算,具体地:其中,si和mi分别为模拟值和实测值;和分别为模拟值和实测值的平均值;n为样本数据个数;均方根误差(rmse)衡量模拟值和实测值间的平均差异,其值越接近于0,表示模拟值和实测值间偏差越小;平均绝对误差(mae)又称平均绝对离差,可避免误差相互抵消的问题,准确反映模拟值与实测值误差的大小,其值越接近于0,表示模拟值和实测值间偏差越小;决定系数(coefficientofdetermination,r2)也称为拟合优度,根据自变量的变异来解释因变量的变异部分,其值越接近于1,表示二者相关程度越好。本文采用3年540组数据作为输入、输出样本。其中选取2017年和2018年的360组实测样本数据作为pswe模型数据训练集,并对pswe模型进行率定。pswe模型在训练过程中表现出较好的误差收敛性能,模型率定结果如图5至图7所示(因篇幅所限,水盐率定图较多,仅选取2年单次灌水量90mm在播种后第17天和第135天的水盐分布及2年夏玉米产量与wue率定图为例)。模型率定的rmse均小于0.033,mae均小于0.579,r2均大于0.969,模拟率定效果较好。其中,图5-7是模型率定图,率定图比较多,此处仅选取部分率定图做展示。选取2018年单次灌水90mm和120mm分别在播种后第17天和135天的水盐含量及2018年夏玉米生产效益率定图为例进行说明,具体地:图5(a)中90-17d:表示单次灌溉量为90mm,时间点为播种后第17天,以此类推,图5(b)中的90-135d的含义、图5(c)中的120-17d的含义、图5(d)中的120-135d的含义;即是模型模拟出的土壤含水率值与田间试验实测值的比较。图6是选取不同灌水量下在不同时间点的土壤含水率的率定图,即是模型模拟出的土壤含水率值与田间试验实测值的比较,其中,图6(a)中的90-17d的含义、图6(b)中的90-135d的含义、图6(c)中的120-17d的含义、图6(d)中的120-135d的含义见上文;图7是2018年夏玉米产量和水分生产率的率定图,即是模型模拟出夏玉米产量和水分生产率的值与田间试验实测值的比较,通过前述构建的模型,并对模型进行率定调参后,将2019年的参变量输入模型,得到2019年的模拟值,然后用2019年的实测值检验模型的模拟值,得到如图9-图11所示的检验图。2019年夏玉米生育期有实测数据的时间点有9个,故选取单次灌水60mm、90mm、120mm和135mm处理在整个生育期20~40cm土层含水率和含盐量及生产效益的实测值检验模型的模拟值。采用2019年未参与训练的180组样本数据作为测试集,对pswe模型检验。因篇幅所限,仅选取各处理在整个生育期20~40cm土层含水率和含盐量的验证图为例,如图8至图10所示。结果表明,土壤含水率模拟值与实测值拟合程度较好,虽然土壤含盐量模拟结果相对稍差一些(可能是土壤蒸发与作物蒸腾过程中水盐间强烈的互作效应,且盐分的时空变异性远大于水分时空变异性导致),但模拟结果仍能有效反映土壤水盐运移及作物生产效益的变化趋势,模拟结果可以接受。模型整体检验的rmse为0.029,mae为0.570,决定系数r2为0.981。故pswe模型能够满足灌区秸秆深埋和不同灌水下土壤水盐运移模拟的需求,可用于实际模拟。其中,图8是选取不同灌水量下土壤含水率实测值与模拟值的检验,即是整个生育期土壤含水率模拟值变化与有实测数值的时间点实测值间的比较。图9是选取不同灌水量下土壤含盐量实测值与模拟值的检验,即是整个生育期土壤含盐量模拟值变化与有实测数值的时间点实测值间的比较。图10是2019年不同灌水量下夏玉米产量和水分生产率实测值与模拟值的检验。下面对pswe模型与传统模型进行对比分析,具体地:常用的数据分析模型有线性回归模型(linearregression)、逻辑回归模型(logisticregression)、线性支持向量机模型(linearsvm/svr)、poly支持向量机模型(polysvm/svr)及rbf支持向量机模型(rbfsvm/svr)。lr模型利用线性回归方程的最小二乘函数对一个或多个自变量和因变量间关系建模,是一对一分析。支持向量机(svm)是一类按监督学习方式对数据进行二元分类的广义线性分类器,决策边界是对学习样本求解的最大边距超平面,通过核函数变换增加新的特征,使得低维度空间中的线性不可分问题变为高维度空间中的线性可分问题。常见核函数有:线性(linearkernel)、多项式(polynomialkernel)和径向基(radialbasisfunctionkernel)核函数。其中,linearsvm/svr模型不通过核函数进行维度提升,仅在原始维度空间中寻求线性分类边界;polysvm/svr模型通过多项式函数增加原始样本特征的高次方幂;rbfsvm/svr模型通过高斯分布函数增加原始样本特征的分布概率。这类模型可用于线性/非线性分类或回归,泛化错误率低,具有良好的学习能力,且学到的结果具有很好的推广性,可解决小样本情况下的机器学习问题,避免神经网络结构选择和局部极小点;但其对参数调节和函数的选择要求较高,比较敏感,构建的模型一般只能一对一、一对多的变量分析。而本文提出的pswe模型能够实现多对多的分析。采用以往的模型对本试验设定的处理的因果关系进行分析及计算,与本文提出的pswe模型对比,得到表1所示的各类模型的效果评估。由于部分常规模型只能进行单变量及少变量分析,本文使用该类常规模型对每个变量依次分析获取指标,再对所有指标取平均值作为最后汇总的指标数值。linearlogisticlinearpolyrbfpswermse0.2010.1620.1020.1070.0870.029mae11.3428.6714.2454.1892.4650.570r20.4610.5120.6730.7810.8020.981表1下面对模型应用与分析进行阐述具体地:利用检验后的递进水盐嵌入神经网络模型(pswe)模拟河套灌区秸秆深埋、不同灌水量等因素综合作用下土壤水盐运移,并对夏玉米产量及水分利用效率进行预测。模型模拟0~100cm范围内土壤水盐运移,每20cm为一层,共分5层;模拟时间为夏玉米整个生育期,从5月10日至9月27日,共计140d,时间步长为1d;单次灌溉量在60~135mm间,全生育期灌溉3次,初始步长为5mm,最小步长1mm,最大步长为10mm(模型输入的灌溉时间点按照当地灌溉时间确定,其余时间点灌溉量均为0);其他气象参数均按照当天平均值输入;土壤水盐含量容许偏差为0.0005,产量容许偏差为1kg/hm2,wue容许偏差为0.001kg/(hm2·mm)。因模型模拟灌水量为60~135mm的土壤水盐运移规律,模拟图较多,仅选取灌溉60mm、90mm、120mm和135mm的土壤水盐分布模拟图。那么:1)不同灌水量对土壤含水率的影响:不同灌水量的土壤含水率分布如图11至图14所示。在夏玉米生育期内,土壤含水率变化趋势基本一致,灌溉时土壤含水率大幅增加,随着蒸腾蒸发逐渐降低。但从土层深度看,灌溉量为90和120mm时,0~40cm耕作层含水率保持在16%~24%之间,且灌溉后较长一段时间内耕作层含水率较高;而灌溉量为60mm时,耕作层含水率最低时仅为12%,且持续时间较长;灌溉量为135mm时,耕作层含水率变幅较大,在12%~26%间变化。随着土壤深度加深,土壤含水率有增大趋势,80cm以下土层平均土壤含水率为30%以上,且基本维持稳定,受灌溉影响较小。其中,图11-图14是不同灌水量下各土层含水率变化的模拟值,具体地:图11是单次灌溉量为60mm时,整个生育期各土层含水率的模拟值。图12是单次灌溉量为90mm时,整个生育期各土层含水率的模拟值。图13是单次灌溉量为120mm时,整个生育期各土层含水率的模拟值。图14是单次灌溉量为135mm时,整个生育期各土层含水率的模拟值。2)不同灌水量对土壤含盐量的影响:夏玉米生育期,不同灌水量的土壤含盐量分布如图15-图18所示。其中,图15是单次灌溉量为60mm时,整个生育期各土层含盐量的模拟值。图16是单次灌溉量为90mm时,整个生育期各土层含盐量的模拟值。图17是单次灌溉量为120mm时,整个生育期各土层含盐量的模拟值。图18是单次灌溉量为135mm时,整个生育期各土层含盐量的模拟值。可见,秸秆深埋和灌水量对土壤含盐量影响显著。灌溉60mm时,整个生育期土层含盐量逐渐增加,生育末期1m土体内土壤积盐严重;灌溉90mm和120mm时,除了0~20cm土层,其他土层含盐量变化平稳,生育末期根系层(20~40cm)脱盐,这是因为适宜的灌溉量下,秸秆隔层延长了土壤入渗水在耕作层停蓄时间,能够充分湿润耕作层和隔层,提高耕作层及隔层的含水率,与隔层下的心土层形成不连续的水分运移架构,只有超过隔层容纳量的部分土壤入渗水才能运移到心土层,最后形成连续水分运移通道,土壤水入渗趋于稳定;在蒸发蒸腾作用下,耕作层土壤水分逐渐减少,心土层土壤水上移补充,但秸秆形成的阻隔层,阻断心土层土壤水分通过毛管上移至耕层的通道,切断蒸发补给,抑制深层土壤盐分上迁,含盐量变化比较平稳,且隔层里储蓄的水分在蒸腾蒸发作用下逐步释放,补充根系层,从而在一定程度上稀释了土壤溶液的浓度;但当灌溉135mm时,灌溉量大,对隔层造成破坏,此时土壤质地均匀,土壤导水率无差异,湿润区优先流与其水分运移很快平衡,各层土壤含盐量变幅较大,灌溉后,耕作层含盐量大幅下降;随蒸发蒸腾作用增强,深层土壤水分通过土壤毛管进入耕作层,逐渐补给蒸发,盐分却留在耕作层,导致耕作层积盐,产生了次生盐渍化。这说明,秸秆深埋耕作模式下,过多灌溉或者灌溉不足均不能充分发挥隔层的作用,只有在适宜灌溉量下,土壤埋设秸秆形成的隔层,减缓了土壤水分入渗与蒸发,同时抑制盐分的上移和下渗,能够保持根系层(20~40cm)含盐量变幅较小,生育末期土壤脱盐效果显著。通过数值计算,在夏玉米生育末期,灌溉60mm和135mm根系层积盐率分别为20.2%和9.8%;而灌溉90mm和120mm根系层脱盐率为6.7%和5.9%。3)夏玉米产量和水分利用效率的预测:夏玉米生育期不同灌水量下夏玉米产量及水分利用效率(wue)的模型预测如图19所示。按照上述参数输入的步骤,将灌溉量为60~135mm,优化步长5mm依次输入模型,其他参数不变,得到一系列夏玉米产量和wue的数值,并导出该系列数值,进一步优化,得到秸秆深埋下夏玉米产量及wue随灌水量增大均呈先增后降的趋势,但二者达到峰值时的灌水量不同。夏玉米产量预测最大值可达8991kg/hm2,水分利用效率预测最大值可达21.32kg/(hm2·mm),综合考虑,秸秆深埋下较适宜的单次灌溉量为85~102mm。本申请针对河套灌区秸秆深埋下土壤水盐变化复杂,及现有土壤水盐运移模型边界条件和数值计算繁杂,可操作性差,运用受限等方面的不足,本文首次提出并建立基于深度学习的递进水盐嵌入神经网络模型(pswe),并对模型进行训练、率定与检验。pswe模型以试验数据为基础,通过自学习获得与提炼所需信息,模拟了灌区秸秆深埋、灌水量等综合因素下土壤水盐运移,并预测了产量和wue,得到以下结论:1)pswe模型通过多变量整体协同分析,追寻多因素在时间序列上的自然发展,并对秸秆深埋、不同灌水量等因素下土壤水盐运移时空变异规律进行模拟,经实测数据验证,结果表明,模型具有较高精度,能够有效表征夏玉米自然生长的综合条件、土壤水盐运移与夏玉米生产效益三者间双层递进因果关系,捕捉各参变量内在依存联系,可用于模拟灌区水盐运移规律。2)模型应用结果表明,秸秆深埋与不同灌水量对土壤含水率及含盐量影响显著,过多灌溉或灌溉不足均不能充分发挥秸秆隔层“蓄水阻盐”的作用,经模型数值计算,当灌溉90mm和120mm时耕作层含水率保持在16%~24%间,生育末期二者在大于40cm土层含水率保持平稳,隔层脱盐,脱盐率分别为6.7%和5.9%,淡化根系层,促进作物生长;但灌溉60mm和135mm时,耕作层含水率持续降低或者变幅较大,生育末期二者在隔层积盐,积盐率分别达到20.2%和9.8%。3)秸秆深埋耕作模式下,通过将模型预测的产量和wue系列值进行二次优化,发现,夏玉米产量及wue随灌水量增大均呈先增后降的趋势,二者达到峰值时的灌水量不同,综合计算分析,建议河套灌区夏玉米种植的单次灌水量为85~102mm,生育期灌3水。4)pswe模型将气候条件和生长条件、土壤水盐、夏玉米生产效益作为一个协同统一体,充分考虑了各因素间整体的协同效应,能够实现不同尺度的土壤水盐运移模拟与夏玉米生产效益预测的有机统一。因此将pswe模型应用到河套灌区秸秆深埋下水盐动态研究中是切实可行的。本申请为实现气候条件、秸秆深埋、不同灌水量等综合参变量与土壤水盐、作物生产效益间在时间序列上的双层递进因果关系的模拟,本文基于深度学习理论及技术,首次提出并建立了应用在农田水利上的递进水盐嵌入神经网络模型(progressivesalt-waterembeddingneuralnetwork,pswe)。本研究使用python进行编码,在pytorch框架上架构pswe模型,并进行模型的模拟与预测。pswe模型将分级长短记忆网络(hierarchicallongshort-termmemory,hlstm)构架的时间序列化数据编码器与批标准化多层感知机(batch-normalizedmulti-layerperceptron,bmlp)构造的解码器进行耦合,并将优化的dropout与adam算法进行耦合,作为模型面向收敛的改进算法。以2017—2018年2年的实测数据作为训练集,进行训练和率定,采用2019年田间实测数据检验。结果表明,pswe模型具有多变量整体协同性、自学习性和较高的精度,能够可靠的描述河套灌区秸秆深埋下土壤水盐运移规律、夏玉米生产效益与各参变量间的内在依存关系。pswe模型整体均方根误差rmse为0.029,平均绝对误差mae为0.570,决定系数r2为0.981,相比传统的支持向量机等模型,其具有更高的模拟预测精度。通过模型应用发现,随时间推移,单次灌溉60mm的耕作层(0~40cm)含水率持续降低,影响夏玉米正常生长,而当地单次灌溉135mm的耕作层含水率变幅较大,成熟期二者在秸秆隔层产生积盐,积盐率为20.2%和9.8%;单次灌溉90mm和110mm的耕作层含水率保持在16%~24%间,生育末期二者在大于40cm土层含水率保持平稳,秸秆隔层有脱盐趋势,脱盐率为6.7%和5.9%;建议秸秆深埋下夏玉米的单次灌水量为85~102mm,生育期灌3次水。综上,基于深度学习的pswe模型模拟河套灌区秸秆深埋和不同灌水量下土壤水盐运移是适用的,是对传统水盐运移研究方法的完善和创新,与传统的机理模型相比,深度学习理论及技术在农田水利领域具有更好的应用前景。在上述各实施例中,虽然对步骤进行了编号s1、s2等,但只是本申请给出的具体实施例,本领域的技术人员可根据实际情况调整s1、s2等的执行顺序,此也在本发明的保护范围内,可以理解,在一些实施例中,可以包含如上述各实施方式中的部分或全部。如图20所示,本发明实施例的一种作物产量的预测系统200,包括获取模块210和预测模块220,所述获取模块210用于获取与预设作物的生长所关联的每个参量的具体值;所述预测模块220用于将所有参量的具体值输入递进水盐嵌入神经网络模型,得到预设作物的产量的预测值,其中,所述递进水盐嵌入神经网络模型用于模拟所有参量与土壤水盐含量之间的函数关系,以及模拟土壤水盐含量与预设作物的产量之间的函数关系。递进水盐嵌入神经网络模型包括2层递进因果关系,体现为:利用所有参量与土壤水盐含量之间的函数关系得到土壤水盐含量的具体值,基于土壤水盐含量的具体值,并利用土壤水盐含量与预设作物的产量之间的函数关系,得到预设作物的产量的预测值,模拟大田秸秆深埋下不同灌水量及其他气候、生长因素对土壤水盐运移、作物生产效益的影响,通过试验结果表明,递进水盐嵌入神经网络模型具有较高精度,能够有效表征预设作物生长的综合条件即关联的每个参量、土壤水盐含量运移与预设作物的产量三者间双层递进因果关系,捕捉各参变量内在依存联系,可用于模拟灌区水盐运移规律。较优地,在上述技术方案中,还包括训练模块,所述训练模块用于:将分级长短记忆网络构架的时间序列化数据构造的编码器与批标准化多层感知机构造的解码器进行耦合,并进行训练,得到所述递进水盐嵌入神经网络模型。较优地,在上述技术方案中,所述训练模块还用于:采用dropout算法与adam算法进行耦合作为训练所述递进水盐嵌入神经网络模型时的收敛算法。上述关于本发明的一种作物产量的预测系统200中的各参数和各个单元模块实现相应功能的步骤,可参考上文中关于一种作物产量的预测方法的实施例中的各参数和步骤,在此不做赘述。本发明实施例的一种存储介质,所述存储介质中存储有指令,当计算机读取所述指令时,使所述计算机执行上述任一项所述的一种作物产量的预测方法。本发明实施例的一种电子设备,包括处理器和上述的存储介质,所述处理器执行所述存储介质中的指令。其中,电子设备可以选用电脑、手机等。所属
技术领域:
的技术人员知道,本发明可以实现为系统、方法或计算机程序产品。因此,本公开可以具体实现为以下形式,即:可以是完全的硬件、也可以是完全的软件(包括固件、驻留软件、微代码等),还可以是硬件和软件结合的形式,本文一般称为“电路”、“模块”或“系统”。此外,在一些实施例中,本发明还可以实现为在一个或多个计算机可读介质中的计算机程序产品的形式,该计算机可读介质中包含计算机可读的程序代码。可以采用一个或多个计算机可读的介质的任意组合。计算机可读介质可以是计算机可读信号介质或者计算机可读存储介质。计算机可读存储介质例如可以是一一但不限于——电、磁、光、电磁、红外线、或半导体的系统、装置或器件,或者任意以上的组合。计算机可读存储介质的更具体的例子(非穷举的列表)包括:具有一个或多个导线的电连接、便携式计算机磁盘、硬盘、随机存取存储器(ram),只读存储器(rom)、可擦式可编程只读存储器(eprom或闪存)、光纤、便携式紧凑磁盘只读存储器(cd-rom)、光存储器件、磁存储器件、或者上述的任意合适的组合。在本文件中,计算机可读存储介质可以是任何包含或存储程序的有形介质,该程序可以被指令执行系统、装置或者器件使用或者与其结合使用。尽管上面已经示出和描述了本发明的实施例,可以理解的是,上述实施例是示例性的,不能理解为对本发明的限制,本领域的普通技术人员在本发明的范围内可以对上述实施例进行变化、修改、替换和变型。所属
技术领域:
的技术人员知道,本发明可以实现为系统、方法或计算机程序产品。因此,本公开可以具体实现为以下形式,即:可以是完全的硬件、也可以是完全的软件(包括固件、驻留软件、微代码等),还可以是硬件和软件结合的形式,本文一般称为“电路”、“模块”或“系统”。此外,在一些实施例中,本发明还可以实现为在一个或多个计算机可读介质中的计算机程序产品的形式,该计算机可读介质中包含计算机可读的程序代码。可以采用一个或多个计算机可读的介质的任意组合。计算机可读介质可以是计算机可读信号介质或者计算机可读存储介质。计算机可读存储介质例如可以是一一但不限于——电、磁、光、电磁、红外线、或半导体的系统、装置或器件,或者任意以上的组合。计算机可读存储介质的更具体的例子(非穷举的列表)包括:具有一个或多个导线的电连接、便携式计算机磁盘、硬盘、随机存取存储器(ram),只读存储器(rom)、可擦式可编程只读存储器(eprom或闪存)、光纤、便携式紧凑磁盘只读存储器(cd-rom)、光存储器件、磁存储器件、或者上述的任意合适的组合。在本文件中,计算机可读存储介质可以是任何包含或存储程序的有形介质,该程序可以被指令执行系统、装置或者器件使用或者与其结合使用。尽管上面已经示出和描述了本发明的实施例,可以理解的是,上述实施例是示例性的,不能理解为对本发明的限制,本领域的普通技术人员在本发明的范围内可以对上述实施例进行变化、修改、替换和变型。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1