食药舆情分析方法与流程
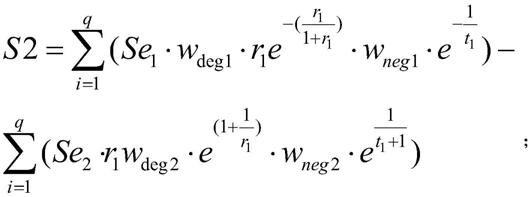
1.本发明涉及一种舆情分析方法,尤其涉及一种食药舆情分析方法。
背景技术:
2.食品和药物是关系到民生的两大主题,市面上的食品以及药物的种类不胜枚举,然而,用户对于某个品牌的食品或者药物的使用后的评价,则是关系到后续对于食品以及药物的质量反馈、市场监督等行为的实施。
3.随着网络技术和计算机技术的发展,用户对于食品或者药物的评价往往通过微博、贴吧等网络方式进行陈述,现有技术中,对于关于食药舆情的网络文本的分析均是基于情感分析,即通过对网络文本的处理、情感值计算等,但是,现有的情感分析方法存在准确性低,从而不能准确的把握用户评价倾向。
4.因此,为了解决上述技术问题,亟需提出一种新的技术手段。
技术实现要素:
5.有鉴于此,本发明的目的是提供一种食药舆情分析方法,能够对用户发表在网络上的评价进行准确处理,并得出准确的情感倾向值,从而能够为食药的厂家、质量监督部门提供准确的舆情参考依据,从而为质量反馈、市场监督的措施制定提供准确的数据支持。
6.本发明提供的一种食药舆情分析方法,包括以下步骤:
7.s1.采集网络文本,并对网络文本进行预处理;
8.s2.对预处理后的网络文本进行分句处理,并剔出网络文本中的重复评论句;
9.s3.对分句处理后的每个评论句进行分词处理,提取出文本中的食药特征词;计算食药特征词之间的相似度,任意两个相似度小于设定阈值,则剔除其中一个特征词;
10.s4.构建分类词典,将每个评论句中的食药特征词划分到所对应的词典类别;
11.s5.构建情感词典,并从评论句中识别出食药特征词、情感词、程度词以及否定词;
12.s6.确定情感词的基础情感值,程度词的权重值以及否定词的权重值;
13.s7.构建食药情感倾向值计算模型,并根据情感倾向值计算模型确定所采集网络文本的舆情倾向。
14.进一步,步骤s1中,具体包括:
15.s11.对网络文本进行有序化处理,并剔除网络文本中的停用词、无关词;
16.s12.对步骤s1中处理后的网络文本进行指代消解:
17.s121.基于fasttext分类模型对网络文本进行指代词检测;
18.s122.基于bilstm_crf深度学习模型进行网络文本中的实体词进行提取;
19.s123.将网络文本的指代词替换成相对应的实体词。
20.进一步,步骤s3中,食药特征词之间的相似度通过如下方法计算:
21.其中,β为食药特征词a和食药特征词b之间
的相似系数;dis(a,b)为食药特征词a和食药特征词b之间的语义距离,其中,β≥1.5。
22.进一步,根据如下方法确定网络文本的舆情倾向:
23.判断网络文本的总情感值s与设定的情感值范围[
‑
1,1]进行比较:
[0024]
当s<
‑
1时,则网络文本对于食药的评价倾向为负向评价;
[0025]
当s>1时,则网络文本对于食药的评价倾向为正向评价;
[0026]
当
‑
1≤s≤1时,则网络文本对于食药的评价为中性评价;
[0027]
将网络文本对于食药的负向评价记录为负向评价集,将网络文本的正向评价记录为正向评价集,将网络文本的中性评价记录为中性评价集。
[0028]
进一步,网络文本的总情感值s通过如下方法确定:
[0029]
s=s1+s2+s3,其中,s1为网络文本中一般陈述句的情感倾向值,s2为网络文本中转折句的情感倾向值,s3为条件句的情感倾向值。
[0030]
进一步,一般陈述句的情感倾向值通过如下方法计算:
[0031]
其中,w
deg
为第i个陈述句中的程度词的权重,se为第i个陈述句中的情感特征词的情感值,w
neg
为第i个陈述句中的否定词的平均权重,q为网络文本中一般陈述句的个数,m为陈述句中否定词的个数。
[0032]
进一步,转折句的情感倾向值通过如下方法计算:
[0033][0034]
其中,w
neg1
为转折句中正向情感特征词的否定词的平均权重,w
neg2
为转折句中负向情感特征词的否定词的平均权重,w
deg1
为转折句中正向情感特征词的程度词的权重,w
deg2
为转折句中负向情感特征词的程度词的权重,r1为转折句中程度词的权重调节系数,t1为转折句中否定词的权重调节系数;se1为转折句中正向情感特征词的情感值,se2为转折句中负向情感特征词的权重,q为转折句的个数。
[0035]
进一步,递进句的情感倾向值通过如下方法计算:
[0036][0037]
其中,se为递进句的情感特征词的情感值,w
deg
为递进句的程度词的权重,w
neg
为递进句中的否定词的平均权重,m为否定词的个数,r2为递进句中程度词的权重调节系数,t2为递进句中否定词的权重调节系数。
[0038]
本发明的有益效果:通过本发明,能够对用户发表在网络上的评价进行准确处理,并得出准确的情感倾向值,从而能够为食药的厂家、质量监督部门提供准确的舆情参考依据,从而为质量反馈、市场监督的措施制定提供准确的数据支持。
附图说明
[0039]
下面结合附图和实施例对本发明作进一步描述:
[0040]
图1为本发明的流程示意图。
具体实施方式
[0041]
以下结合说明书附图对本发明做出进一步详细说明:
[0042]
本发明提供的一种食药舆情分析方法,包括以下步骤:
[0043]
s1.采集网络文本,并对网络文本进行预处理;
[0044]
s2.对预处理后的网络文本进行分句处理,并剔出网络文本中的重复评论句;
[0045]
s3.对分句处理后的每个评论句进行分词处理,提取出文本中的食药特征词;计算食药特征词之间的相似度,任意两个相似度小于设定阈值,则剔除其中一个特征词;
[0046]
s4.构建分类词典,将每个评论句中的食药特征词划分到所对应的词典类别;
[0047]
s5.构建情感词典,并从评论句中识别出食药特征词、情感词、程度词以及否定词;对于食药特征词即是关于食品或者药物的相关特征的描述,比如包装、安全、添加剂含量等等,情感词比如好、差、不错等,程度词包括最、非常、尤其等,否定包括不、恶劣等等,这些都是可以通过现有的方法建立相应的词典实现,在此不加以赘述;
[0048]
s6.确定情感词的基础情感值,程度词的权重值以及否定词的权重值;其中,情感词的基础情感值采用现有的算法进行确定,比如tf
‑
idf算法;程度词以及否定词分别通过现有的方法建立程度词权重值对照表和否定词权重值对照表,然后根据程度词以及否定词查询相应的对照表即可确定;
[0049]
s7.构建食药情感倾向值计算模型,并根据情感倾向值计算模型确定所采集网络文本的舆情倾向,通过上述方法,能够对用户发表在网络上的评价进行准确处理,并得出准确的情感倾向值,从而能够为食药的厂家、质量监督部门提供准确的舆情参考依据,从而为质量反馈、市场监督的措施制定提供准确的数据支持。
[0050]
本实施例中,步骤s1中,具体包括:
[0051]
s11.对网络文本进行有序化处理,并剔除网络文本中的停用词、无关词;在网络评语中,用户的语言组织往往不是有序的,而是杂乱的,因此,需要对文本进行有序化处理,通过调整词语的顺序将语言表达合理化,准确化,而且,在文本中一些停用词,无关词(比如评价某一个食品安全性,而出现“我买了很多”这类,这就是无关的)。
[0052]
s12.对步骤s1中处理后的网络文本进行指代消解:
[0053]
s121.基于fasttext分类模型对网络文本进行指代词检测;
[0054]
s122.基于bilstm_crf深度学习模型进行网络文本中的实体词进行提取;
[0055]
s123.将网络文本的指代词替换成相对应的实体词;通过上述方法,能够准确的确定出情感特征词、与情感特征词有关的程度词、否定词等,从而确保后续处理的准确性。
[0056]
本实施例中,步骤s3中,食药特征词之间的相似度通过如下方法计算:
[0057]
其中,β为食药特征词a和食药特征词b之间的相似系数;dis(a,b)为食药特征词a和食药特征词b之间的语义距离,其中,β≥1.5,且β不大于4,根据实际评价对象进行相应的取值,语义距离dis(a,b)采用现有的算法实现,在此不加
以赘述,通过上述方法,能够有效提出重复食药特征词对于评价结果的影响,从而确保准确性。
[0058]
本实施例中,根据如下方法确定网络文本的舆情倾向:
[0059]
判断网络文本的总情感值s与设定的情感值范围[
‑
1,1]进行比较:
[0060]
当s<
‑
1时,则网络文本对于食药的评价倾向为负向评价;
[0061]
当s>1时,则网络文本对于食药的评价倾向为正向评价;
[0062]
当
‑
1≤s≤1时,则网络文本对于食药的评价为中性评价;
[0063]
将网络文本对于食药的负向评价记录为负向评价集,将网络文本的正向评价记录为正向评价集,将网络文本的中性评价记录为中性评价集,通过该方法,而且,每个评价集均针对于相对应的词典类别,从而为后续的质量反馈、市场监督提供准确的数据支持,传统中,对于正负向评价一般以0为区别,即大于零为正向评价,小于0为负向评价,等于0为中性评价,但是,在计算处理中存在误差,而通过上述中的区间,能够消除误差影响,从而防止中性评价被误归入正向评价或者负向评价。
[0064]
本实施例中,网络文本的总情感值s通过如下方法确定:
[0065]
s=s1+s2+s3,其中,s1为网络文本中一般陈述句的情感倾向值,s2为网络文本中转折句的情感倾向值,s3为条件句的情感倾向值。
[0066]
具体地址:一般陈述句的情感倾向值通过如下方法计算:
[0067]
其中,w
deg
为第i个陈述句中的程度词的权重,se为第i个陈述句中的情感特征词的情感值,w
neg
为第i个陈述句中的否定词的平均权重,q为网络文本中一般陈述句的个数,m为陈述句中否定词的个数。
[0068]
转折句的情感倾向值通过如下方法计算:
[0069][0070]
其中,w
neg1
为转折句中正向情感特征词的否定词的平均权重,w
neg2
为转折句中负向情感特征词的否定词的平均权重,w
deg1
为转折句中正向情感特征词的程度词的权重,w
deg2
为转折句中负向情感特征词的程度词的权重,r1为转折句中程度词的权重调节系数,t1为转折句中否定词的权重调节系数;se1为转折句中正向情感特征词的情感值,se2为转折句中负向情感特征词的权重,q为转折句的个数。
[0071]
递进句的情感倾向值通过如下方法计算:
[0072][0073]
其中,se为递进句的情感特征词的情感值,w
deg
为递进句的程度词的权重,w
neg
为递进句中的否定词的平均权重,m为否定词的个数,r2为递进句中程度词的权重调节系数,t2为
递进句中否定词的权重调节系数,上述中,通过不同的句型来确定相应的情感值,能够有效确保最终评价结果的准确性,事实上,评论句中,还存在疑问句、反问句,这些疑问句和反问句均可以转化为一般陈述句,而且其语义以及情感倾向变化不明显,可以仍然以一般陈述句的方式计算器情感值。
[0074]
最后说明的是,以上实施例仅用以说明本发明的技术方案而非限制,尽管参照较佳实施例对本发明进行了详细说明,本领域的普通技术人员应当理解,可以对本发明的技术方案进行修改或者等同替换,而不脱离本发明技术方案的宗旨和范围,其均应涵盖在本发明的权利要求范围当中。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1