一种基于半监督多目标优化的社交网络圈子识别方法
本发明涉及人工智能与复杂网络
技术领域:
,更具体的涉及一种基于半监督多目标优化的多层网络社团挖掘装置用于解决多通道社交网络圈子识别问题。
背景技术:
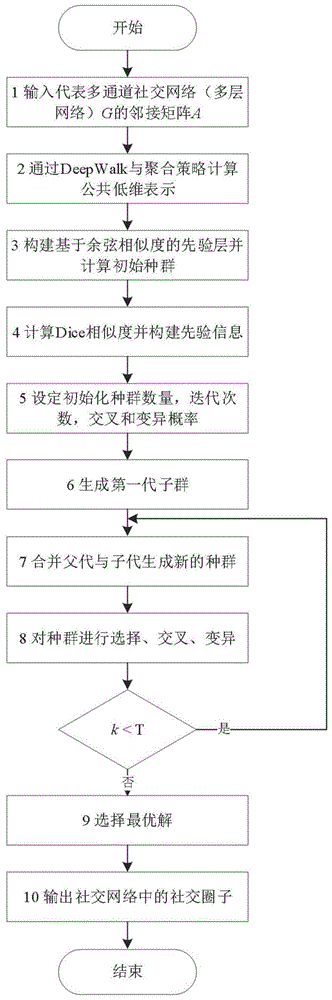
:人与人之间的社交关系,构成了人类社会。因此,对用户间社交关系的研究尤为重要。然而,直接处理现实世界中的社交系统较为困难。学者们通过将社交软件中的用户账号抽象成网络中的节点,用户间的联系(聊天、关注共同话题、相互评论等)抽象为节点的连边的方法对社交系统建模,通过将社交系统抽象为社交网络,方便表征社交网络中的信息。其中,社交圈子是社交网络中最基本的结构之一,对网络中潜在的社交圈进行研究具有重要的意义。社交圈子是一组拥有共同兴趣爱好且联系紧密的用户集合。随着信息化进程的发展和网络的普及,社交网络中用户社交圈的应用分析对不同的领域有着越来越重要的意义。对于科研机构而言,对不同社交圈子的分析有利于对不同特征的人群的行为进行预测。对软件供应商而言,通过准确识别社交圈子,可以通过定向推荐相关的主题内容提升用户体验,也可以与广告商合作,对不同的用户定向投放商品及广告推广获取利益。因此,根据社交网络中蕴含的各类信息,准确地识别社交网络中潜在的社交圈子,对用户行为预测,提高用户对社交软件的体验,获取经济收益等方面具有重要意义。因此,社交圈子的识别已经成为互联网企业的研究焦点。根据社交圈固有的属性(位于同一个社交圈内的用户,由于共同的兴趣爱好具有较为紧密的连接;而位于不同社交圈的用户由于共同话题较少则连接稀疏),通过网络科学中的社团挖掘技术能够有效实现社交圈子的挖掘。然而,用户作为现实世界中的个体,在现实世界中的社交关系是多维度的,仅仅通过对单一关系进行建模很难真正将用户在现实世界中的社交关系表现出来。在实际情况中,用户会通过不同的社交软件进行交互,在网络空间中拥有多种虚拟身份,因而信息可以通过不同通道在网络中进行传播,例如,用户们通常会使用微信与家人进行通讯,通过qq与同学朋友进行消息传递,使用微博等软件与陌生的但有共同话题爱好的网友交流,这些社交关系有着不同的重要性与意义。多通道社交网络中用户关系的多元化导致传统的基于单层网络的社团挖掘方法很难精准有效地识别社交网络中的圈子。鉴于此,该发明通过将多通道社交网络抽象为多层网络,并通过提出一种基于半监督多目标优化的多层网络社团挖掘方法,挖掘多层网络中潜在的社团(即多通道社交网络中的社交圈子)。通过该方法,能够有效还原用户在现实世界中的社交活动的多元化性质,更充分的考虑用户特征,从而更准确地挖掘多通道社交网络中的社交圈子。目前,学者们针对多层网络社团挖掘,已经提出了一些方法。其中,多目标优化方法由于其能够选择不同的优化函数,有效平衡不同网络层之间的关系,从而适配多层网络结构,取得了较好的效果。然而,现有的关于多层网络社团挖掘的研究方法大多基于拓扑结构,通过设定不同的目标函数,根据拓扑信息来优化目标函数从而达到优化社团结构的目的。然而,当网络中社团结构较为复杂或模糊时,这类方法的准确度就会有较大的下降,甚至使得结果不可用。然而,在大部分真实的复杂系统中,可以通过对数据的分析获取先验信息,利用有限的先验信息指导整个方法的运行,有效提升其准确率与鲁棒性,特别是在社团结构较复杂的网络中,通过先验信息的指导能够避免性能的降低,从而提高方法性能。这种利用了先验信息的方法称为半监督的方法。现有的半监督社团挖掘方法大多基于单层网络,很少有研究者聚焦于多层网络社团挖掘,并开发一种基于半监督的多目标优化方法。此外,现有的半监督方法大多仅仅通过先验信息重构网络结构(将先验信息作为权重加在每一层网络上),并未从根本上将先验信息融入每一轮迭代中。这种方式能够在一定程度上提供指导。然而,这种方法有其缺点,若先验信息权重较大,则会破坏网络拓扑结构,若太小则指导意义有限。因此,开发一种基于半监督多目标优化的多层网络社团挖掘装置解决多通道社交网络圈子识别问题,使得先验信息能够融合到每一轮迭代中,解决在社团结构(圈子)较复杂的网络中效果较差的问题,使提出的装置获得更高的准确率与鲁棒性。技术实现要素:本发明的目的在于解决多通道社交网络的社交圈子识别问题。针对该问题,本发明将多通道社交网络抽象为多层网络,并提出一种基于半监督多目标优化的多层网络社团挖掘方法,通过抽取多层网络社团的方式识别多通道社交网络中的社交圈子。为了使得装置充分运用先验信息与网络拓扑信息,该发明将先验信息从多个不同的维度与多目标优化方法相结合,发挥出先验信息的指导意义与多目标优化方法的局部搜索与全局搜索能力,从而使得该装置拥有较高的准确率与鲁棒性。本发明设计的装置是一种基于半监督多目标优化的社交网络圈子识别方法,将多通道社交网络抽象为多层网络,并获取该多层网络的邻接矩阵;通过多层网络的公共低维表示计算节点的dice相似度,并提取基于dice的先验信息;通过多层网络的公共低维表示获得高质量初始解,并构建先验层重构网络;将先验层重构网络与网络融合,并与高质量初始解一起进行优化,在优化过程中,通过dice的先验信息指导遗传操作,最终通过最优解选择策略求得多层网络的公共社团划分,挖掘出多通道社交网络中的社交圈子。输入多通道社交网络抽象的多层网络g={g1,g2,…,gl}该多层网络g的邻接矩阵a={a1,a2,…,al},其中,l为网络的层数。多层网络的公共低维表示是通过deepwalk与提出的density-based聚合策略求取;对求取的多层网络公共低维表示向量构建基于余弦相似度的先验层,并通过低维表示向量计算初始种群;计算节点间的dice相似度,构建基于dice的先验信息。设定初始化种群数量p,迭代次数t,交叉和变异概率;生成第一子代群,通过对初始化种群进行非支配排序并计算拥挤度,通过选择,交叉,变异操作产生第一代子群;合并父代与新产生的子代,形成新的种群;对形成的种群进行选择、交叉、变异产生子群;其中,所采用的技术为二进制锦标赛选择法,均匀交叉与基于先验信息的变异。首先对每一层网络使用deepwalk获得每一层的低维表示,然后根据聚合策略,计算每一层的density并根据所求权重进行聚合;density公式为:其中,ms为社团内连边数,ns代表节点数;构建基于余弦相似度的先验层,并计算初始种群;对公共低维表示向量分别使用k-means计算初始种群,使用余弦相似度构建虚拟先验层;余弦相似度公式如下:其中,vi和vj代表两个节点,x和y为vi和vj的低维表示向量,r为向量的维度;通过预先设定的保留阈值,保留部分具有最高相似度的节点对作为先验信息构建先验层;计算节点间的dice相似度,生成基于dice的先验信息;dice相似度计算如下:其中,commonneighbor(vi,vj)代表vi和vj在所有层的公共邻居,|neighbor(vi)|代表vi节点在每一层的所有邻居的数量;通过设定保留阈值,保留具有最高相似度的节点对作为先验信息。非支配排序根据支配关系对染色体进行排序;pareto支配关系为:在最小化多目标优化问题中,对于m个目标函数fj(x),j=1,…,m;对于染色体(每个染色体对应一个解)xa和xb,若有以下两个条件成立,则称xa支配xb;1)对于均有fi(xa)≤fi(xb)成立;2)均有fi(xa)≤fi(xb)成立;拥挤度公式如下:其中,id为第i个染色体的拥挤度,fji+1为第i+1个染色体的第j个目标函数值。基于先验信息的变异策略可表示为:其中,chro为需要变异的父代,pos为随机选择的需要变异的点,neighbor(pos)为pos节点的邻居集合,dice(pos)为dice先验信息中与pos节点具有较高相似度的节点的集合,rand为随机数,该公式表示变异节点的取值从这两个集合中选择的概率均为50%;遗传操作根据染色体的目标函数值来选取最优解产生子代,其中,所选的两个目标函数为每一层的模块度q的均值与规范截nc;其中,m为网络内的边数,a为网络对应的邻接矩阵,di表示节点i的度;c表示社团,ci表示i为属于c社团的节点;当第i和j节点属于同一个社团时,即ci=cj时,δ(ci,cj)=1否则δ(ci,cj)=0;其中ck代表第k个社团。与分别代表社团内的边数、社团间的边数、与第k个社团所有的连边数。当k<t时,重新进行合并父代与新产生的子代,形成新的种群;当k>t时,进行最优解的选择。通过基于kneepoint的方法选择最优解,从解集中选择某节点,该节点与其两侧的一阶与二阶邻居组成的直线的4个夹角中存在至少一个角为解集中所有节点的夹角的最大值;输出多层网络的社团划分c={c1,c2,…,ck},该划分就表示多通道社交网络中潜在的社交圈子。本发明的有益效果是:(1)通过重构网络改变多层网络拓扑结构,以及生成高质量的初始解,使装置能够在运行过程中始终受到先验信息的指导,提高装置准确率。(2)通过先验信息在每一轮迭代中的指导使得装置具有较高的鲁棒性,甚至在社团结构较复杂的网络中,也能通过先验信息对装置进行指导,将相似的节点分到同一个社团中,使得装置性能有所提升。(3)通过种群进化更新,逐步寻找更高质量的解。在寻优过程中,选择具有较高目标函数值的父代,通过交叉变异产生不同的子代,增加种群多样性。在多样性的种群中,寻找更优解,通过重复这个流程,得到在该目标函数下的最优解。(4)将本发明与其他方法在不同规模的人工数据集与真实数据集上进行对比实验,结果表明我们的装置明显具有较高的准确性与鲁棒性,证明了通过装置能够有效挖掘多通道社交网络中的社交圈。附图说明图1是本发明实施方式的流程图;图2是本发明实施方式的详细图解图;图3是本发明中为基于先验信息的变异策略的详细流程图;图4为鲁棒性分析实验图;图5为参数分析实验图。具体实施方式下面结合附图和实施例对本发明进行详细的描述。实施例一种基于半监督多目标优化的社交网络圈子识别方法,将多通道社交网络抽象为多层网络,并获取该多层网络的邻接矩阵;通过多层网络的公共低维表示计算节点的dice相似度,并提取基于dice的先验信息;通过多层网络的公共低维表示获得高质量初始解,并构建先验层重构网络;将先验层重构网络与网络融合,并与高质量初始解一起进行优化,在优化过程中,通过dice的先验信息指导遗传操作,最终通过最优解选择策略求得多层网络的公共社团划分,挖掘出多通道社交网络中的社交圈子。如图1所示按照如下步骤进行:s1:输入表示多通道社交网络的多层网络g={g1,g2,…,gl}的邻接矩阵a={a1,a2,…,al},其中,l为网络的层数;s2:通过deepwalk与提出的density-based聚合策略求取公共低维表示。首先对每一层网络使用deepwalk获得每一层的低维表示,然后根据聚合策略,计算每一层的density并根据所求权重进行聚合;为了简化计算,变形的density公式为:其中,ms为社团内连边数,ns代表节点数;s3:构建基于余弦相似度的先验层,并计算初始种群;对s2中的公共低维表示向量分别使用k-means计算初始种群,使用余弦相似度构建虚拟先验层;余弦相似度公式如下:其中,vi和vj代表两个节点,x和y为vi和vj的低维表示向量,r为向量的维度;通过预先设定的保留阈值,保留部分具有最高相似度的节点对作为先验信息构建先验层,在本发明中,该阈值取0.3;s4:计算节点间的dice相似度,生成基于dice的先验信息;dice相似度计算如下:其中,commonneighbor(vi,vj)代表vi和vj在所有层的公共邻居,|neighbor(vi)|代表vi节点在每一层的所有邻居的数量;通过设定保留阈值,保留具有最高相似度的节点对作为先验信息,在本发明中,该阈值取0.1;s5:设定初始化种群数量p,最大迭代次数t,交叉概率80%,变异概率40%,其中p=500,t=500;s6:生成第一代子群。装置通过对s5产生的初始种群进行非支配排序并计算拥挤度,并通过选择,交叉,变异操作产生第一代子群,非支配排序步骤如下,选择、交叉、变异,具体步骤见s8;非支配排序根据支配关系对染色体进行排序,pareto支配关系为:在最小化多目标优化问题中,对于m个目标函数fj(x),j=1,…,m;对于染色体(每个染色体对应一个解)xa和xb,若有以下两个条件成立,则称xa支配xb,在该发明中包含2个目标函数,即m=2;1)对于均有fi(xa)≤fi(xb)成立;2)均有fi(xa)≤fi(xb)成立;拥挤度公式如下:其中,id为第i个染色体的拥挤度,fji+1为第i+1个染色体的第j个目标函数值;s7:合并父代与新产生的子代,形成新的种群;s8:对父代种群进行选择、交叉、变异产生子群。选择、交叉、变异为产生子代的遗传操作。在本装置中,通过二进制锦标赛选择方法选择父代,然后通过均匀交叉与基于先验信息的变异产生子代;基于先验信息的变异策略可表示为:其中,chro为需要变异的父代,pos为随机选择的需要变异的点,neighbor(pos)为pos节点的邻居集合,dice(pos)为dice先验信息中与pos节点具有较高相似度的节点的集合,rand为随机数,该公式表示变异节点的取值从这两个集合中选择的概率均为50%。遗传操作根据染色体的目标函数值来选取最优解产生子代,其中,我们所选的两个目标函数为每一层的模块度q的均值与规范截nc;其中,m为网络内的边数,a为网络对应的邻接矩阵,di表示节点i的度。c表示社团,ci表示i为属于c社团的节点。当第i和j节点属于同一个社团时,即ci=cj时,δ(ci,cj)=1否则δ(ci,cj)=0;其中ck代表第k个社团。与分别代表社团内的边数、社团间的边数、与第k个社团所有的连边数;s9:通过基于kneepoint的方法选择最优解,从解集中选择某节点,该节点与其两侧的一阶与二阶邻居组成的直线的4个夹角中存在至少一个角为解集中所有节点的夹角的最大值;s10:输出多层网络的社团划分c={c1,c2,…,ck},该划分就表示多通道社交网络中潜在的社交圈子。表1为实验所用数据集汇总:表1数据集汇总netnodelayergroundtruthsnd7133mpd8736wtn183145cora166223citeseer331223syn1500039syn210000316为了验证性能,采用了7个不同的数据集,其中,前五个为真实数据集,syn1与syn2为较大规模的人工网络数据集。snd与mpd为社交网络,mpd为手机通讯组成的网络,三层分别代表物理位置、蓝牙扫描和电话通话。snd为一律师公司内的社交网络,每一层代表一种连接关系,分别为合作,友谊和建议。通过图2进行详细的图解对数据集进行处理;图3为基于先验信息的变异策略的详细流程;该策略基于两种变异方式,第一种是基于邻居节点的策略,对于随机选择的变异节点,目标节点的值随机变为该节点的一个邻居的值。第二种是基于先验信息的变异策略,对于随机选择的一个节点,其值变为先验信息中随机选择的与该节点相似的某个节点的值;图4中的图包含三个对比方法,其中ss-moml为该发明提出的装置。在该实验中,通过μ与dc控制网络结构,layers为网络层数。μ与dc越大,网络中社团结构就越模糊。该图展示了在不同网络结构,不同层数的网络中的鲁棒性测试的实验结果;从实验结果可以看出,在51个不同结构以及不同网络层数的网络上,ss-moml具有更高的社团划分准确率。此外,在不同的数据集中,ss-moml更稳定,也进一步证明了该方法具有更高的鲁棒性。在μ=0.5&dc=0.3网络中,社团结构比较复杂,对比方法准确率皆有较大的下降,而本发明由于有先验信息的指导,并且不完全依赖于拓扑结构,仍然可以取得较好的效果。图4中的图(d)中,各个方法波动较为剧烈,而该发明提出的装置在该图中的各个数据集中保持较为稳定的高准确率。进一步证明了提出的装置的性能。图5展示了参数分析的结果,纵轴代表余弦相似度先验信息的保留比例(s3中的预设的阈值),横轴代表dice相似度先验信息保留比例(s4中的阈值)。该实验通过参数分析的方式,验证先验信息能否起到指导作用,并通过参数分析的结果选取装置的参数;当dice与cos的保留比例均为0时,装置的准确率最低,随着先验信息保留比例提升,准确率提高。证明我们的装置通过使用先验信息作为指导确实提高了装置的性能。在mpd网络中,当先验信息保留比例超过0.5,装置准确率降低,原因在于mpd数据集本身结构较为复杂。因此随着先验信息保留比例的提升,使得节点对间的相似度(先验信息准确率)降低,从而导致装置性能降低。以上实施例仅仅是对本发明的举例说明,并不构成对本发明的保护范围的限制,凡是与本发明相同或相似的设计均属于本发明的保护范围之内。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1