一种基于规则引擎的配置化汽配调度方法与流程
本发明属于互联网技术领域,具体涉及一种基于规则引擎的配置化汽配调度方法。
背景技术:
电商系统中,供应商为了实现最好的配送时效和客户体验,更低的物流成本,通常会在全国设置多个中心仓,在核心城市设置前置仓,在区县设置区域仓和门店仓。用户在线上下单后,由哪个仓库发货才是最合理的,较近的仓库不能满足用户订单时,是拆分成多个包裹发货还是从较远可满足订单的仓库发货,调度就是解决上述问题的一个系统。然而现有的调度方式不仅调度系统复杂,且不能满足实时性的要求,对于订单渠道复杂多变的中大型规模公司,不能实现物流成本低,实时性高的要求。
技术实现要素:
本发明解决的技术问题:提供一种自动配置决策因子和优先级,实现发货成本最低的既能够满足实时性的要求,又能降低系统复杂度的基于规则引擎的配置化汽配调度方法。
技术方案:为了解决上述技术问题,本发明采用的技术方案如下:
一种基于规则引擎的配置化汽配调度方法,包括:针对业务场景配置可发货仓列表决策策略;针对业务场景配置不同的决策因子和优先级,实现可发货仓列表中最优仓决策,最优仓决策策略中,加载业务场景定义的决策因子和优先级,通过贪心算法,按优先级依次执行决策因子并收敛得到最优发货仓。
作为优选,所述业务场景根据订单属性确定,订单属性包括订单渠道、订单标签、是否拆单以及是否跨时效。
作为优选,所述可发货仓列表决策策略配置中,首先设置调度配置属性的类,类的数据结构中包含的字段有:是否拆单、是否需要跨区域发货的判断、以及需要配置的仓库调度属性。
作为优选,针对每种业务场景上调度的具体需求,分别采取不同的仓库策略算法,去获取对应的仓库列表,如果在使用时需要新增一种仓库的策略,则增加一个仓库策略的处理器。
作为优选,决策因子的值的设定由系统自动判断,通过库存调度模块分析计算优先级和决策因子的设值;在设定决策因子之前,采用预估打分系统根据以下方法计算出当前决策因子中最佳的调度路径:
tscore=scorewn*weightwn+scoredi*weightdi+scorep*weightp
上式中:tscore表示总加权分数;scorewn表示仓库数指标的分数;scoredi表示距离指标的分数;scorep表示省份数指标的分数;weightwn表示仓库数这项指标的权重;weightdi表示距离指标的权重;weightp表示省份数指标的权重。
作为优选,针对决策因子的权重,库存调度模块针对每个订单制定订单调度分析计划表,定期分析因为调度过程中决策因子的权重变更是否使得物流成本增加。
作为优选,库存调度模块自动调整决策因子的权重,使物流成本最低;步骤如下:
s1:获取订单相关数据,初始根据业务人员的经验设定决策因子;
s2:系统自动分析各种比例决策因子以及对应的物流成本,重新得到预判的决策因子:
s3:针对系统设定的预判决策因子数据,微量调整之后进行数据分析;
s4:针对步骤s3中调整的数据,进行再次调整,找出最优比例的决策因子。
有益效果:与现有技术相比,本发明具有以下优点:
本发明的基于规则引擎的配置化汽配调度方法,不仅能做到仓库列表中筛选出最优的仓库作为订单的最佳发货仓,同时能够对可选择的仓库列表进行路由配置,基于中大型规模公司复杂多变的订单渠道,订单标签等不同业务场景实现全面配置又能灵活支持运营的调度策略,在节省物流成本,提高发货时效的同时又能兼顾到业务层面多样化的需求,节省开发运营的成本压力,同时决策因子的设定交于系统的不断尝试,最终找出能使发货成本最小的决策因子。
附图说明
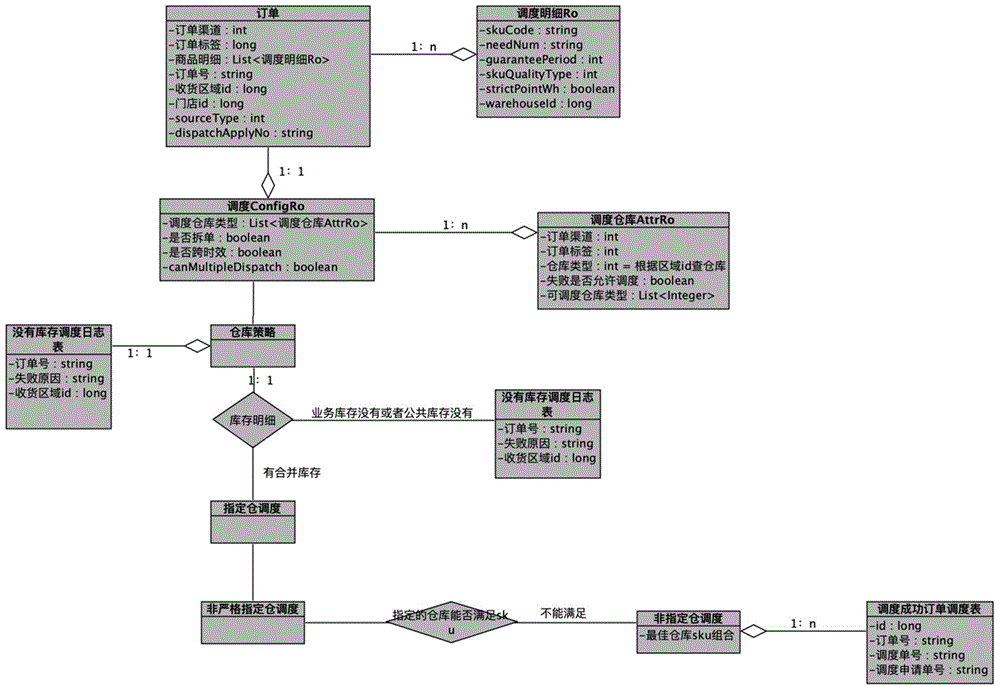
图1是基于规则引擎的配置化汽配调度方法可发货仓列表决策模块er图;
图2是基于规则引擎的配置化汽配调度方法业务场景选择页面;
图3是基于规则引擎的配置化汽配调度方法可发货仓列表决策配置页面。
具体实施方式
下面结合具体实施例,进一步阐明本发明,实施例在以本发明技术方案为前提下进行实施,应理解这些实施例仅用于说明本发明而不用于限制本发明的范围。
一种基于规则引擎的配置化汽配调度方法,包括:针对业务场景配置可发货仓列表决策策略;针对业务场景配置不同的决策因子和优先级,实现可发货仓列表中最优仓决策。本发明的调度过程分解成可发货仓库列表决策和发货仓列表中最优仓决策两步,即第一步是为了找到所有可以发货的仓库集合,第二步是从可发货仓库集合中找到最优的发货仓。
调度系统要求非常高的实时性,在用户下单过程中,就得计算出最优发货仓,并锁定库存防止超卖;同时,调度系统包含了复杂的业务规则,且规则复杂度会随着业务发展而增长,例如:
可发货仓列表决策考虑因素主要包括:(1)气门嘴发货仓必须与轮胎发货仓一致;(2)是否强制指定仓调度;(3)是否允许协同仓发货;(4)是否允许跨区域调度;(5)是否允许拆单(6)不同渠道的业务需要不同类型的仓库发货;(7)不同订单标签的业务有的时候只允许某种类型的仓库发货;(8)业务上面在某种发货仓列表调度失败的情况下,能否继续调度其他的仓库。
发货仓列表中最优仓决策的主要考虑因素包括:
(1)最快时效优先;(2)最小距离优先;(3)最少包裹数优先(最小仓);
(4)最低运费成本优先。
首先确定业务场景,业务场景根据订单属性确定,订单属性包括订单渠道、订单标签、是否拆单以及是否跨时效等等。越来越多的仓库选择规则随着业务的发展会添加到库存调度中来,为了更好的支持业务定制化调度规则,将每个订单的共性抽取出来,比如每个订单中包含订单渠道,订单标签,是否拆单,是否跨时效等属性,这些属性共同决策出一种业务场景。如图1所示,进行调度参数配置,通过勾选订单的属性就可以定义出一种业务场景。
对业务场景,可以分别配置可发货仓列表决策策略和最优仓决策策略。
针对业务场景,配置不同的可发货仓列表决策策略,示例如下:
示例:场景scenario1
策略:根据订单收货地址区域id查询可发货仓列表
数据:订单收货地址:浙江省杭州市余杭区
仓库列表:[w1,w2,w3,w4,w5]
仓库覆盖范围:w1:湖北、湖南、安徽、江西、浙江、江苏、福建;
w2:浙江、江苏、福建、上海;
w3:浙江、江苏、福建、上海;
w4:湖北、湖南、安徽、江西;
w5:湖北、湖南、安徽、江西;
执行过程:w1,w2,w3均可发货到浙江省;
执行结果:[w1,w2,w3]。
针对业务场景,发货仓列表中最优仓决策配置不同的决策因子和优先级,通过贪心算法,快速收敛。配置页面如图2所示,示例如下:
示例:场景scenario2
决策因子:最小包裹数-优先级1,最小距离-优先级2(优先级数值越小,优先级越高)。
数据:可发货仓列表为[w1,w2,w3],w1地址:湖北省武汉市洪山区;w2地址:浙江省杭州市余杭区;w3地址:浙江省杭州市余杭区。
订单商品列表为:[sku1,sku2,sku3]。
仓库商品库存满足情况:w1满足[sku1,sku2,sku3],w2满足[sku2,sku3],w3满足[sku1,sku2,sku3]。
订单收货地址:浙江省杭州市余杭区。
决策过程:1、按照最小包裹数计算规则,w1和w3均为最优。2、按照最小距离规则,从[w1,w3]中找出距离收货地址最近的仓,w3最优。
决策结果:w3仓发货。
本发明通过上述的业务场景配置化+可发货仓列表决策配置化+发货仓列表中最优仓决策配置化,既降低了系统复杂度,保障了接口性能,也使得快速支持业务变化成为可能。
在软件实现上,可发货仓库列表决策模块的er图如图3所示。
可发货仓列表决策策略配置中,首先设置调度配置属性的类,类的数据结构中包含的字段有:是否拆单、是否需要跨区域发货的判断、以及需要配置的仓库调度属性。仓库列表的调度属性中,会包含中如何的数据结构:仓库选择类型,失败是否允许继续常识调度;可调度仓库类型。调度的模式,分别有门店铺货仓、门店前置仓、根据区域id查询仓库列表和指定仓。
本发明采用策略模式的设计思想,针对每种业务场景上调度的具体需求,分别会采取不同的仓库策略算法,去获取对应的仓库列表,如果到时候需要新增一种仓库的策略,通过该种方式只需增加一个仓库策略的handler(处理器)就可以了。失败了允许继续尝试,在业务上有些需要是需要前置判断后,先走一遍流程,如果不合理,也许再更改一些条件又继续走一遍之前的流程,这种业务就可以通过配置这个字段,如果这个字段设置true的话,再调度失败后,会继续拿到第二遍需要尝试的条件,再继续走一遍业务流程,如果有多种业务流程需要尝试的话,只需更改下上面的字段属性然后增加一个新的调度的条件就好了,做到完全的代码隔离,只需更改下配置文件即可。针对不同的业务,有些渠道是调度到主仓,有些只能调度到协同仓,这样的话,就可以增加一个仓库属性的列表,真正做到不同的渠道,不同的订单标签只需更改下可调度的仓库类型就可以自动实现调度到不同的仓库列表上去了。
决策因子如何影响调度路径:加载业务场景定义的决策因子和优先级,通过贪心算法,按优先级依次执行决策因子并收敛得到最优发货仓。决策因子的值的设定由系统自动判断,通过库存调度模块分析计算优先级和决策因子的设值;优先要以发货的经济性考虑,但是发货的经济性是由多方面组成,运营人员的优先级设定很难在一定程序上保证优先级的顺序就是能找到最优的经济发货的策略。通过大数据的不断调整,逐步找到最优的决策因子。
在设定决策因子之前,采用预估打分系统根据以下方法计算出当前决策因子中最佳的调度路径:
tscore=scorewn*weightwn+scoredi*weightdi+scorep*weightp
上式中:tscore表示总加权分数;scorewn表示仓库数指标的分数;scoredi表示距离指标的分数;scorep表示省份数指标的分数;weightwn表示仓库数这项指标的权重;weightdi表示距离指标的权重;weightp表示省份数指标的权重。
预估打分系统的打分规则如表1所示:
表1
预估打分系统的案例:现在有订单a收货地是武汉现在有几种调度方案:
plana:仓库1(杭州)和仓库2(诸暨)发到武汉,距离总和700公里分析a:仓库数量2个,距离总和700公里,省份1个总分数=8*0.4+4*0.2+8*0.3=6.4;
planb:仓库1(海南)发到武汉,距离总和1200公里分析a:仓库数1个,距离总和1200公里,省份1个总分数=10*0.4+1*0.2+8*0.3=6.6;
planc:仓库1和2和3(仓库1、2、3均在武汉区域)发到武汉,距离总和100公里分析a:仓库数3个,距离总和100公里,省份1个总分数=6*0.4+10*0.2+8*0.3=6.8;
可以判断出planc>planb>plana最终选择出来的是planc。
如何判定当前的决策因子是否能使物流成本最低,本发明针对决策因子的权重,库存调度模块针对每个订单制定订单调度分析计划表,定期分析因为调度过程中决策因子的权重变更是否使得物流成本增加。具体算法如下:
针对上述的决策因子的权重,库存调度系统针对每个订单设计出订单调度分析计划表(dispatch_order_analy_plan),该表会包含订单号、订单sku的数量、sku的总重量、渠道号、标签、订单履约的物流成本、订单已发货时间、订单已完成时间点以及各种决策因子的权重、订单状态、调度单号、调度的状态,通过该订单调度分析计划表系统会定期分析因为调度决策因子的权重变更是否使得物流成本增加,目前判断物流成本有一套分析策略:
1)每个sku的平均物流成本(总成本/总的sku数目)(权重1.0);
2)每公斤的物流成本(总成本/总公斤)(权重0.0);
3)运费费率(运费/货品价值)(权重0.0)。
上述算法中几个关键的分析字段的数据来源的简要说明如下:订单已发货时间:订单中心更改当前订单为已发货状态的时候,通知库存中心更新并落下订单已发货的时间。订单已完成时间点:订单中心更改当前订单为已完成状态的时候,通知库存中心更新并落下订单已完成的时间。订单履约的物流成本:订单号在按照当前在每个订单完成的时候,由订单中心发货订单状态变更成完成的消息,由库存中心调度模块先去发货中心获取当前订单的各个通知单号,然后去物流中心查询每个包裹的物流成本,统计出当前订单的物流履约成本,记录到该字段。订单sku的数量:一个订单中有多少个商品。订单中sku的总重量:订单中每个sku在商品中心获取到的重量加总。
本发明的库存调度模块可自动调整决策因子的权重,使物流成本最低:
(1)库存调度模块会每两周执行定时任务,拉取到相同订单渠道、标签等公共属性的订单数量(on),获取最近的总物流成本(tm),订单的sku总数目(st),订单的sku的总重量(sw)以及货品价值(sv),通过tm/st计算出每个sku的平均物流成本。
(2)针对步骤(1)的结果增加或者减少部分决策因子比例,然后对调整之后决策因子,通过模拟调度流程,获取到最新的调度结果同时结合物流中心获取预估物流成本的能力,得出调整决策因子之后获取到总的物流成本,通过不断分析,判定得出能使每个sku的平均物流成本最低的权重因子。
(3)为了验证步骤(2)得到的决策因子是否能使发货成本最经济,使用步骤(2)得到的决策因子,对其增加或者减少0.01的幅度进行调整,调整之后,继续运行两周,然后不断分析每个月其中的每个sku的平均物流成本,重复步骤(3)的步骤,让系统自动为当前的系统找出能最节省物流成本的决策因子,具体调整步骤如下:细节可参照表2-表5:
s1:如表2所示,获取订单相关数据,初始根据业务人员的经验设定决策因子;
表2
s2:如表3所示,物流中心预判物流成本,系统自动分析各种比例决策因子以及对应的物流成本,重新得到预判的决策因子;
表3
s3:针对系统设定的预判决策因子数据,微量调整之后进行数据分析,微调仓库数或者最小包裹数等;
表4
s4:如表5所示,针对步骤s3中调整的数据,进行再次调整,找出最优比例的决策因子。
表5
以上仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!