无监督视频分割方法
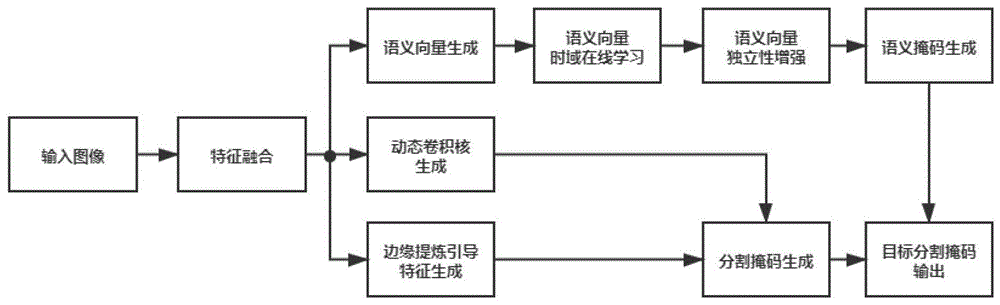
本发明属于视频分割技术领域,能够对在无人为干预的情况下对任意视频前景目标进行实例级分割,涉及到视频和图像处理的相关知识,尤其涉及一种无监督视频分割方法。
背景技术:
无监督视频分割任务近年来显示出越来越突出了作用,它的主要目的是在无人为干涉的情况下分割出视频中的主要运动物体。无监督视频分割广泛地被应用于视频推理,视频理解等领域。
无监督视频分割主要分为两大类:基于检测和跟踪,以及基于像素的匹配和传播。基于检测和跟踪的方法首先对单帧图像进行目标框的检测,然后利用对应检测框内的特征相似度来寻找不同目标在时域上的连续性。这种方法可以对各种尺度目标进行较好的处理,但是错误的检测结果对于后续的分割产生了不可消除的影响。lin等人在2020年cvpr提出的‘videoinstancesegmentationtrackingwithamodifiedvaearchitecture’方法在检测的基础上,为每个检测到的目标分配一个实例向量,通过对向量相似度的监督和计算来完成视频时域上的连续性。同时该方法增加了一个辅助迭代检测更好的解决了物体遮挡问题。luiten等人在wacv会议中提出了‘unsupervisedofflinevideoobjectsegmentationandtracking’,该方法主要利用检测的结果生成长短跟踪段,由短变长的跟踪段使得该方法更好的适应长序列的目标跟踪。基于像素匹配和传播的算法可以对模型进行端到端的训练,避免了中间结果的影响,但是相似的物体会有相似的特征表现,因此该种方法会造成物体时域上联系失败。athar在eccv会议中提出的stemseg模型可以直接对完整的视频序列进行逐像素的相似度学习和匹配,从而完成长序列的跟踪。
不仅如此,近年来提出了多种关于视频分割的发明。在专利cn202011124541.7中公开了《一种优化视频目标检测、识别或分割的精度和效率的方法》,该方法利用邻近帧的识别结果,先预测当前帧的待检测子区域,再在含有目标物的待检测子区域进行处理,不需要对无关背景进行处理,极大的减少了处理所需的运算量,提升了运算效率;2020年,李永杰等人在专利cn202010786958.3中提出的《一种视频图像前景像素深度信息分类与前景分割方法和装置》,利用视频帧的深度图对分割进行辅助;2021年,由陈祖国等人公开了专利cn202011227875.7《基于双通道卷积核与多帧特征融合动态视频图像分割方法》,通过双卷积核与多帧特征融合的方法,克服了传统边缘分割边界不封闭不连续的缺点,取得了良好的图像分割效果。
尽管目前的视频分割算法取得了不错的效果,但仍存在几个问题需要解决。首先,现有的大部分的视频分割方法都可以较好的解决运动明显,且外观突出的目标,但是处理外观相似且相近的实例目标时,很容易将多个目标分割成一个,这种错误会影响到后续的视频帧。另外,视频数据的范围非常广泛,场景复杂,当前景运动物体与背景相似或存在严重的遮挡时,会出现目标丢失或者错将背景分割成目标的问题。最后,现有的方法没有同时考虑到语义信息的获取和外观边缘区分,从而导致目标获取较好的方法在边缘处理上很粗糙,反之利用逐像素匹配细节的方法缺少物体的语义信息,造成相似外观物体无法区分。
技术实现要素:
本发明要解决的技术问题是:对于给定的任意一个视频序列,没有任何的先验信息的情况下对视频序列中的视频帧每个目标进行分割。不仅如此,该发明还要能够较好的捕捉语义模糊的目标,如在视频序列中尺度变化较大的目标,与背景具有相似的颜色和亮度的目标等。另外,本发明的视频分割模型还可以广泛地应用于各种类别的目标分割。
为了达到上述目的,本发明采用的技术方案为:
本发明的设计原理为:根据一个观测到的结论:视频序列中视频帧的语义信息比外观信息可以更好的区分不同目标与背景,目标的语义信息包括该目标在视频帧中的相对位置、颜色、尺度等。本发明通过学习单个视频帧中所有目标的语义信息的关系,并传播每个目标在连续视频帧间的语义信息,能够优化相似目标的分割效果,并更好地从复杂场景中定位到目标。同时,目标边缘信息的强化对于目标的定位和分割也有引导作用,因此本发明通过逐步的边缘提取并对边缘监督来增强细节并优化视频分割结果。
一种无监督视频分割方法,包括以下步骤:
第一步,生成目标语义向量
1.1)首先输入给定的视频序列中的一帧视频帧i,使用经典的金字塔结构fcn提取物体特征得到一系列金字塔特征图
1.2)fcn输出的每个金字塔特征图pi分别通过一系列的卷积层及上采样到与最浅层相同尺寸并求和得到融合特征:
其中,funif为融合特征,convupi表示第i层金字塔特征图经过多组卷积层和上采样。
1.3)对步骤1.2)得到的融合特征进行空间、通道上的增强和语义信息的挖掘,从而更好的为后续的语义向量在线学习提供引导。利用融合特征funif,采用公式(2)计算一个注意力图w:
w=sig(conv1×1(funif))(2)
其中,conv1×1表示一层卷积层,sig表示sigmoid函数;w越大,表示该位置是目标位置的概率越大。
融合特征在注意力图的引导下经过如下的增强:
fch=funif⊙sig(chavg(funif⊙w))(3)
fatt=conv3×3(concat(fch,w))(4)
式(3)输出fch表示通道增强特征,其中chavg表示通道平均操作。式(4)输出fatt表示空间增强特征,其中conv3×3表示卷积层,concat表示通道拼接。
1.4)最后空间和通道增强特征fatt经过四个相同组合结构(卷积层+组归一化+非线性激活函数),输出语义向量特征fie。语义向量特征fie中每一个像素点(一个语义向量)是对视频帧中一个目标或者背景的粗略语义表达。与外观像素的传播相比,本发明更多利用目标的语义全局特征(语义向量特征)的关系而不是局部外观的相似度。
第二步,语义向量的在线学习
初步得到的语义向量特征fie只有每帧视频帧自身的信息,当视频帧中的目标遮挡较严重或与背景相似时,会出现目标定位的模糊,此时会出现目标丢失或有背景物体被误检测成目标的现象。由于每个视频序列中同一目标在不同帧的语义向量表示相似且与其他目标和背景不同,本发明利用每个目标语义向量在时域上的传播来引导目标定位模糊视频帧中语义向量的学习,从而更好的定位目标。同时为了防止过去信息的错误积累,还融合了自身增强语义向量特征来权衡时域的传播正确性。特别地,对于每个视频序列第一帧无时域传播的情况,直接进入第三步,生成语义掩码。在随后处理视频序列后续帧时,会利用之前成成的语义掩码。具体如下:
2.1)对于每一帧视频帧t,首先将位置信息融合进语义向量特征fie;这里采用归一化坐标coord∈[-1,1]来代表位置信息,分别与当前t时刻视频帧的语义特征
其中,at和mt分别表示过去视频帧的语义对齐特征和自注意力图;ot表示过去视频帧预测的语义掩码;
采用公式(5)(6)描述的自注意机制用来过滤过去视频帧的误导性信息。
2.2)为了充分利用历史信息,每处理一帧后,全部过去时刻0≤t<t的视频帧过滤后的语义向量特征
其中,t表示当前时刻。
公式(7)表明每一帧过去时刻0≤t<t视频帧在传播过程中对当前时刻t视频帧有同等的作用而不是更多的依靠临近帧。
对于当前视频帧,有式:
其中,at和mt分别表示当前视频帧的语义对齐特征和自注意力图。
考虑到每个目标在视频序列中的运动变化较缓慢,当给定了记忆池memt和当前视频帧的对齐特征at后,本发明通过下式金字塔融合模块(aspp)将每一个位置的语义向量和相邻的一系列不同距离的语义向量进行信息的融合和匹配,输出匹配后的时域传播语义特征
另外,本发明对当前视频帧语义向量特征加入自注意力机制得到自增强语义向量特征:
2.3)为了防止在时域传播时出现错误积累,本发明通过拼接和卷积层融合时域传播语义特征
输出融合语义向量特征
第三步,语义向量的独立性增强
在第一步和第二步目标语义向量特征生成和学习的过程中,卷积变形操作可能导致一些语义向量包含多个相邻目标的信息(尤其是被大量遮挡的物体)。覆盖多个目标信息的语义向量会将只包含其中一个目标的语义向量削弱,从而造成目标丢失或定位错误。因此本发明设计一个残差模块来修正并突出可以表示单个目标的语义向量,从而提升目标定位和分割的精度。该残差模块的实现过程如下:
公式(12)中的金字塔融合模块aspp可以建立
输出预测ot是一个权重图,权重越高表示该位置表示单个目标的概率越高。
第四步,生成由边缘提炼引导的细节提取及视频帧实例分割掩码
第三步通过语义向量特征生成的语义掩码表示每个位置单个目标的概率,采用基底特征和动态卷积核的卷积输出生成每个位置对应的目标分割掩码,所述动态卷积核k由融合特征funif经过四个相同组合结构(卷积层+组归一化+非线性激活函数)生成,所述基底特征的细节信息直接影响到输出目标分割掩码的精度,因此基底特征通过对funif进行细节增强后生成。
边缘是视频分割以及所有分割相关任务一个重要的线索。充分的利用边缘信息能够增强基底特征的细节从而提升一些困难场景的目标分割精度,例如多个目标相连时连接处的分割。因此,本发明首先对融合特征funif进行降维得到降维特征frdu,然后通过公式(16)、(17)逐步的提取边缘信息:
bstr=conv3×3(deconv3×3(frdu))(16)
bsub=conv3×3(deconv3×3(bstr))(17)
公式(16)中的deconv3×3表示反卷积,它拥有恢复图像的功能,因此可以一定程度的恢复编码的降维特征frdu的细节,然后通过一个卷积层来强化恢复的信息,得到粗略细节特征bstr。公式(17)采用相同的结构进一步的恢复特征中的细节信息,得到细节特征bsub。上述两种细节特征和降维特征通过公式(18)融合后得到边缘特征:
fbdry=conv3×3(bstr+conv1×1(concat(bsub,frdu)))(18)
fbdry在边缘掩码真值的监督下,学习融合特征funif的边缘信息。
然后将边缘特征fbdry和融合特征funif结合来增强融合特征细节并生成基底特征
其中,ε表示一组3×3卷积,relu函数和1×1卷积。
最后分割预测m和语义掩码o,并通过已有技术matrixnms输出最后的分割结果。
本发明的有益效果为:
本发明提供的无监督视频分割方法能够通过同时在时空域挖掘同一视频序列中所有视频帧中目标和背景的语义信息来进行目标的定位,能够更好地处理外观相似目标的区分以及复杂背景中目标的检测,最后通过对基底特征边缘的强化来提高目标分割的精度。同时,本发明也能够很好的扩展应用于图像和视频处理的其他领域中,如图像补全等。
附图说明
图1是系统框图。
图2(a)是视频帧中物体(背景)和语义向量的对应位置关系,(b)是语义特征中前景实例对应的向量,(c)是实例掩码和语义向量的对应位置关系。
图3(a)是完整的结果,(b)是没有时域信息传播的结果,(c)是缺少单帧独立性强化的结果(d)同时移除时域和空间强化得结果。
具体实施方式
以下结合具体实施例对本发明做进一步说明。
一种无监督视频分割方法,包括以下步骤:
步骤1:本发明首先输入两条狗和一个人草坪活动场景(图2(a))的视频帧i并缩放到480×864×3,使用经典的金字塔结构fcn提取物体特征得到一系列金字塔特征图
步骤2:fcn输出的每个金字塔特征图pi通过公式(1)分别经过一系列的卷积层及上采样到与最浅层相同尺寸并求和得到融合特征
步骤3:对步骤2得到的融合特征funif,通过公式(2)计算一个注意力图
步骤5:对于每个视频序列第一帧无时域传播的情况,直接进入步骤9,生成语义掩码。在随后处理视频序列后续帧时,会利用之前成成的语义掩码。
步骤6:对于每一帧视频帧t,将位置信息融合进语义向量特征fie;这里采用归一化坐标
coord分别与当前t时刻视频帧的语义特征
步骤7:每处理一帧后,全部过去时刻0≤t<t的视频帧过滤后的语义向量特征
对于当前时刻视频帧,通过公式(8)生成对齐特征
步骤8:通过拼接和卷积层融合时域传播语义特征
步骤9:融合语义向量特征
步骤10:对于步骤9生成了单个目标的位置o,采用基底特征和动态卷积核的卷积输出生成每个位置对应的目标分割掩码,所述动态卷积核
本发明首先对融合特征funif进行卷积降维得到降维特征frdu,然后通过公式(16)(17)逐步的提取边缘信息。公式(16)中的deconv3×3表示反卷积,它拥有恢复图像的功能,因此可以一定程度的恢复编码的降维特征frdu的细节,然后通过一个卷积层来强化恢复的信息,得到粗略细节特征bstr。公式(17)采用相同的结构进一步的恢复特征中的细节信息,得到细节特征bsub。两种细节特征和降维特征通过公式(18)融合后得到边缘特征fbdry。fbdry在边缘掩码真值的监督下,学习融合特征funif的边缘信息。然后将边缘特征fbdry和融合特征funif结合通过公式(19)来增强融合特征细节并生成基底特征
步骤11:训练过程中,对于边缘特征fbdry的监督通过生成边缘掩码
bdry=fbdry*k(21)
来完成。对于分割掩码和边缘掩码预测的监督方式为公式(22)(23)所示。
其中l表示损失值npos表示正样本数目,k表示每一个语义向量对应位置,1是一个判断方程,当pk>0时为1否则为0。mk表示预测的分割(边缘)掩码,tk表示真值。i表示分割掩码中的每一个像素点。
步骤12:在测试过程中,将语义掩码o和分割掩码m通过matrixnms进行更新,matrixnms的算法如公式(24)-(26)所示:
f(d(mi,mj))=1-d(mi,mj)(26)
其中mi和mj分别表示不同的预测掩码,d与公式(23)相同,oi和oj表示语义掩码o中的两个不同的位置点,decayj表示预测第j个分割掩码的抑制率,抑制率越高,该分割掩码最后作为结果输出的可能性越低。最后,去除语义掩码概率小于0.1的位置的分割掩码,得到最终的视频帧分割结果(分割掩码)。
以上所述实施例仅表达本发明的实施方式,但并不能因此而理解为对本发明专利的范围的限制,应当指出,对于本领域的技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进,这些均属于本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!