用于生成对话策略学习用高质量模拟经验的方法与流程
本发明属于机器学习技术领域,尤其是涉及一种用于生成对话策略学习用高质量模拟经验的方法。
背景技术:
任务完成型对话策略学习旨在构建一个以完成任务为目标的对话系统,该系统可以通过几轮自然语言交互来帮助用户完成特定的单个任务或多域任务。它已广泛应用于聊天机器人和个人语音助手,例如苹果的siri和微软的cortana。
近年来,强化学习逐渐成为了对话策略学习的主流方法。基于强化学习,对话系统可以通过与用户进行自然语言交互来逐步调整、优化策略,以提高性能。但是,原始强化学习方法在获得可用的对话策略之前需要进行大量人机对话交互,这不仅增加了训练成本,而且还恶化了早期训练阶段的用户体验。
为了解决上述问题并加速对话策略的学习过程,研究者们在dyna-q框架的基础上,提出了deepdyna-q(ddq)框架。ddq框架引入了世界模型,为了使其与真实用户更相似,该模型使用真实用户经验进行训练,用以在动态环境中生成模拟经验。在对话策略学习过程中,使用从实际交互中收集的真实经验和从与世界模型交互中收集的模拟经验共同训练对话智能体。借助引进世界模型,只需要使用少量的真实用户交互,能够显著提升对话策略的学习效率,然而,ddq在进一步优化基于有限对话交互的对话策略学习方面还面临着一些难题,例如ddq中的世界模型被构建为深度神经网络(dnn),其性能在很大程度上取决于训练所用的数据量。在真实经验相对较少的初始训练阶段,dnn对数据的高度依赖问题可能会使世界模型生成低质量的模拟经验,若要该模型生成高质量的模拟经验,则需要大量的真实经验。也就是说,由dnn等数据需求量大的模型实现的世界模型将削弱dyna-q框架带来的优势,并使得ddq在现实中的效率很低。
技术实现要素:
本发明的目的是针对上述问题,提供一种用于生成对话策略学习用高质量模拟经验的方法。
为达到上述目的,本发明采用了下列技术方案:
一种用于生成对话策略学习用高质量模拟经验的方法,包括以下步骤:
s1.由基于gp的世界模型预测产生模拟经验;
s2.将模拟经验存储至缓冲器以用于对话策略模型训练。
在上述的用于生成对话策略学习用高质量模拟经验的方法中,在步骤步骤s2之前,先由质量检测器对所述模拟经验进行质量检测,且在步骤s2中将质量检测合格的模拟经验存储至缓冲器。
在上述的用于生成对话策略学习用高质量模拟经验的方法中,基于gp的世界模型包括多个gp模型,且所述的世界模型由w(s,a;θw)表示,s为当前对话状态,a为最后一个响应动作,θw表示各个gp模型的参数。
在上述的用于生成对话策略学习用高质量模拟经验的方法中,在步骤s1中,通过多个gp模型预测生成至少一组模拟经验,且每组模拟经验包括响应动作au、奖励r和变量t。
在上述的用于生成对话策略学习用高质量模拟经验的方法中,所述的世界模型包括三个gp模型,且三个gp模型分别用于生成响应动作au、奖励r和变量t。
在上述的用于生成对话策略学习用高质量模拟经验的方法中,在步骤s1的模拟经验预测阶段通过三个gp模型生成元模拟经验ei=(aui,ri,ti)。
在上述的用于生成对话策略学习用高质量模拟经验的方法中,获取元模拟经验中响应动作aui、奖励ri和变量ti的50%置信区间,并依此得到上限模拟经验el=(aul,rl,tl)和下限模拟经验eb=(aub,rb,tb)。
在上述的用于生成对话策略学习用高质量模拟经验的方法中,在步骤s1中,当预测的响应动作au不是整数时,将au近似到最接近的整数;
当预测的响应动作au超出了定义的动作域时,直接选取动作域的上限或下限。
在上述的用于生成对话策略学习用高质量模拟经验的方法中,所述gp模型的模型如下:
其中,
在上述的用于生成对话策略学习用高质量模拟经验的方法中,所述的核函数采用如下形式:
其中,
本发明的优点在于:基于高斯过程的世界模型能够避免传统dnn模型生成的模拟经验质量需要依赖训练数据量的问题,能够生成高质量的模拟经验,以补充有限的实际用户经验,避免初始阶段因为真实经验较少而导致学习效果不佳,学习效率低等问题。
附图说明
图1为本发明实施例一中对话学习方法的架构图;
图2为本发明实施例一中对话学习方法中世界模型的训练阶段流程图;
图3为本发明实施例一中对话学习方法中世界模型的预判阶段流程图;
图4为本发明实施例二中对话学习方法中kl散度计算流程图;
图5为ddq和gpddq在不同参数设定下的学习曲线,其中,
(a)为ddq在m=5000;n=16;k=0,2,5,10,20时的学习曲线;
(b)为gpddq在m=5000;n=16;k=0,2,5,10,20时的学习曲线;
(c)为ddq在m=5000;n=4;k=0,2,5,10,20时的学习曲线;
(d)为gpddq在m=5000;n=4;k=0,2,5,10,20时的学习曲线;
图6为ddq/dqn和gpddq/gpdqn在m=5000,k=10,n=16时的学习曲线,其中,
(a)为ddq/dqn的学习曲线;
(b)为gpddq/gpdqn的学习曲线;
图7为ddq和kl-gpddq在不同参数设定下的学习曲线,其中,
(a)为ddq在m=5000,3500,2000,1000;k=20;n=4时的学习曲线;
(b)为kl-gpddq在m=5000,3500,2000,1000;k=20;n=4时的学习曲线;
(c)为ddq在m=5000,3500,2000,1000;k=30;n=4时的学习曲线;;
(d)为kl-gpddq在m=5000,3500,2000,1000;k=30;n=4时的学习曲线;
图8为d3q,ddq,gpddq,un-gpddq,kl-gpddq在不同参数设定下的学习曲线,其中,
(a)为m=5000,k=20,n=4时的学习曲线;
(b)为m=5000,k=30,n=4时的学习曲线;
图9是本发明实施例二中对话学习方法的架构图。
具体实施方式
下面结合附图和具体实施方式对本发明做进一步详细的说明。
实施例一
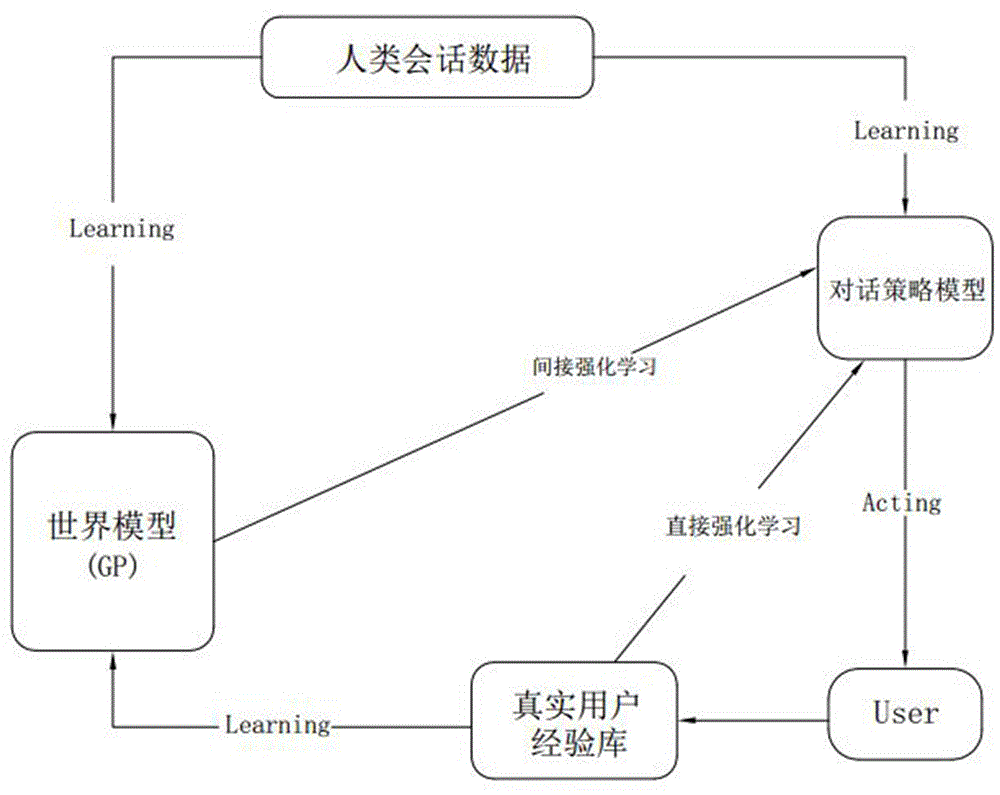
如图1所示,本方案提出一种用于对话策略学习的基于gp的深度dyna-q方法,其基本方法与现有技术一致,如使用人类会话数据来初始化对话策略模型和世界模型,并依此来启动对话策略学习。对话策略模型的对话策略学习主要包括直接强化学习和间接强化学习(也叫规划)两部分。直接强化学习,采用deepq-network(dqn)根据真实经验改进对话策略,对话策略模型与用户user交互,在每一步中,对话策略模型根据观察到的对话状态s,通过最大化价值函数q,选择要执行的动作a。然后,对话策略模型接收奖励r,真实用户的动作aru,并更新当前状态到s’,然后将真实经验(s,a,r,aru,t)存储至真实用户经验库,t用于指示对话是否终止。
最大化价值函数
其中,
间接强化学习期间,对话策略模型通过与世界模型进行交互来改善其对话策略,以减少训练成本,规划的频率由参数k控制,这意味着计划在直接强化学习的每一步中执行k步。当世界模型能够准确捕获真实环境的特征时,k的值往往会很大。在规划的每个步骤中,世界模型都会根据当前状态s来响应动作awu,在规划过程中生成模拟经验(s,a,r,awu,t’)。
特别地,本方案在上述现有技术的基础上,提出将世界模型构造成高斯过程模型,提供能够高效进行对话策略学习的世界模型。
具体地,本方法由基于gp的世界模型预测产生模拟经验,然后将模拟经验存储至缓冲器以用于对话策略模型训练。
具体地,本实施例的世界模型由w(s,a;θw)表示,s为当前状态,a为最后一个响应动作,θw表示各个gp模型的参数。且如图2和图3所示,该世界模型由三个gp模型gp1、gp2、gp3组成,并用不同的θw参数化。使用三个gp模型分别用于生成响应动作au、奖励r和变量t,并将模拟经验表示为e=(au,r,t)。
进一步地,本实施例通过三个gp模型生成元模拟经验ei=(aui,ri,ti),并获取响应动作aui、奖励ri和变量ti的50%置信区间,得到上限模拟经验el=(aul,rl,tl)和下限模拟经验eb=(aub,rb,tb)。即每个预测有三个模拟经验ei、el、eb。
与ddq不同,在该模型中,世界模型本质上是一个用于生成用户动作au的分类模型,考虑到用户操作应为整数并具有有限的动作域,因此本方案对世界模型生成的动作进行进一步处理:
首先,当预测的响应动作au不是整数时(本方案基于gp的世界模型是一个回归模型,而响应动作不是整数在回归情况下比较常见),将au近似到最接近的整数,用比aul大的最近的整数替换aul,并用比aub小的最近的整数替换aub;当预测的响应动作au超出了定义的动作域时,直接选取动作域的上限或下限。
具体地,在世界模型的gp回归问题中,通过添加独立的高斯噪声从函数
其中,
其中,
gp1通过该模型生成动作au,此时动作au便是观测目标y,gp2通过该模型生成奖励r,此时奖励r便是观测目标y,gp3通过该模型生成变量t,此时t便是观测目标y。
优选地,核函数采用matern:
其中,
在每轮世界模型的学习中,当前状态s和最后一个主体动作a被串联起来作为世界模型的输入。这里用均值和matern核函数设置所有gp先验,训练世界模型w(s,a;θw)以模仿真实的对话环境。具体地,如图2,这里的损失函数设置为三个gp模型的负对数边际似然(nll)的总和,在图2中被表示为“trainedwithsummationofthreenll”,由于具有共轭性质,每个nll都可以解析解决,其通式可以写为:
其中,
本方案提供了一种新的基于高斯过程的ddq,能够生成高质量的模拟经验以补充有限的实际用户经验。
实施例二
如图9所示,本实施例与实施例一类似,不同之处在于,本实施例在将模拟经验存储至缓冲器之前先由质量检测器对所述模拟经验进行质量检测,并将质量检测合格的模拟经验存储至缓冲器。
具体地,由质量检测器分别检测上限模拟经验el、下限模拟经验eb和元模拟经验ei的质量。这里的质量检测器可以使用传统的gan(生成式对抗网络)质量检测器,也可以采用本申请人自主研发的kl散度(kullback-leiblerdivergence)质量检测器。
下面对kl散度质量检测器进行简单介绍,如图4所示,其主要通过对比模拟经验与真实经验来进行模拟经验的质量检测,具体方法如下:
将世界模型生成的模拟经验存储至词库world-dict中,将真实用户生成的真实经验存储至词库real-dict中,词库world-dict和词库real-dict的主键均为用户动作auw、aur,主键对应值均为用户动作对应的频率。
词库real-dict与词库world-dict的交集主键在两个词库中的频率值被存储在事先建立的词库same-dict中,并由kl散度衡量词库world-dict与词库real-dict的相似度以进行模拟经验的质量检测;
衡量相似度的方式为事先定义一个变量klpre,变量klpre的初始值被设置为一个较大的值,用来跟踪词库real-dict与词库world-dict之间的kl散度。基于词库same-dict计算当前的kl散度,若当前kl散度小于或等于klpre,则表示由于当前经验使得世界模型与真实用户更相似了,所以将当前经验检测为合格经验,将合格的经验推入至缓冲器mp用于训练对话策略模型。
为了展示本方案的有效性和优越性,将它放在电影票购买任务中进行多组实验测试:
1.1数据集
使用与传统ddq方法相同的原始数据,其通过amazonmechanicalturk收集,该数据集已根据领域专家定义的模式手动标记,该模式包含11个对话行为和16个空位,该数据集总共包含280个带注释的对话,平均长度约为11次。
1.2用作参照物的对话智能体
提供不同版本的任务完成型对话智能体,以作为本方案的性能标杆:
•gpddq(m,k,n)是通过本方案的gpddq方法学习的智能体,m是缓冲器大小,k是规划步数,n是批次大小。最初的世界模型用人类对话数据预训练。这里不使用不确定性属性(即不进行置信区间的计算),也不使用质量检测;
•un-gpddq(m,k,n)与gpddq(m,k,n)相似,但是不确定性在此被纳入考量,在世界模型的预判阶段返回el,ei,eb;
•kl-gpddq(m,k,n)在un-gpddq(m,k,n)的基础上再纳入kl散度检查;
•gpddq(m,k,n,rand-initθw)是通过gpddq方法学习的智能体,但是其世界模型的初始化是随机的。r和t是从对应的gp模型中随机取样的,而对于动作au,统一从其定义的动作域中取样;
•gpddq(m,k,n,fixedθw)只在预热阶段借助人类对话数据进行修正,之后世界模型便不再改动;
•gpdqn(m,k,n)通过直接强化学习而得,在假设其世界模型与真实用户完美匹配的前提下,其性能可以看作gpddq(m,k,n)的上限。
1.3参数分析
为了展示本方案的模型在对超参数变化敏感度方面的优势,本方案做了一系列实验,不断改变对应的参数,例如批次大小,规划步数,参数更新策略,缓冲器大小等。
1.3.1批次大小和规划步骤
在这组实验中,设定批次大小为16和4,以不同规划步数k来训练智能体,主要结果如图5所示,看一看到,从统计学的角度讲,gpddq全面超越了ddq的性能。从图5(a)和5(b)可以清晰地看出,在同样k值情况下,gpddq的成功率收敛值远远优于ddq。gpddq的成功率在0.8附近收敛摆动,而ddq则是0.74。随着规划步骤增加,学习速度基本都变快了,这个现象符合直观认知,也即大量的规划步骤能够带来更快的学习速度。尽管如此,还是可以看到在k=20和k=10时,学习曲线并没有特别的差异,这是由于k值过大导致模拟经验质量下降。
由于gp方法在超参数的影响方面的鲁棒性更强,可以推测它在小批次情况下有更好的性能,故本组实验中,还进一步进行小批次试验,如图5(c),5(d),将批次大小缩小为4,其他参数不变,在k=0的情况下,gpddq的性能仍然超出ddq。更重要的是,在与批次大小为16时的结果进行比对时,其性能没有明显衰减。相反,ddq方法只有在k=10时,学习曲线才会在成功率方面强过k=0时,k提升至20时,其性能大幅降低,这是由于dnn在批次大小过小的时候的训练不足导致的。
1.3.2参数更新策略
在这组实验中,设定m=5000,k=10,n=16,并对其参数更新策略进行一定的改变,结果如图6所示,实验结果表明世界模型的质量对智能体的性能有极大影响。dqn和gpdqn方法是完全不考虑模型的方法,其训练数据量是其他方法的k倍,如图6所示。由于二者的随机性,其曲线虽然略有差别,但本质是一样的,很明显,在预热阶段后就被固定下来的世界模型产生了最坏的结果。ddq学习曲线在250次迭代后的大跌是由于缺乏训练数据造成的,而gpddq方法的每一条学习曲线的最高值都基本和dqn的最高值一样,哪怕是使用不同的参数更新策略,其最终的成功率并不会有多大的浮动。
1.3.3缓冲器大小
在这组实验中,通过变化缓冲器的大小来评估kl-gpddq方法。如图7,从全局性能的角度讲,本方案提出的方法在不同条件下都是更稳定的,包括但不限于不同的缓冲器大小和规划步数情况下。将缓冲器大小从5000减小到1000后,本方案方法的学习曲线并没有明显变化,然而ddq方法的性能变化却比较明显。出现这个现象是因为ddq中用dnn构建的世界模型会在规划过程中生成低质量经验,但是由于缓冲器容量变小导致高质量经验意外地成为了缓冲器中的主导者,才使性能有所提升。
而有关收敛的问题,kl-dpddq方法在k=20时的成功率在200次迭代后就收敛在了0.8附近,与此形成鲜明对比的是ddq方法在200次迭代后还没有收敛,且其成功率的浮动范围也基本在本方案方法之下,最后收敛时也低于本方案方法的成功率。这个实验结果充分证明了本方案的方法能够在使用相对小的缓冲器时仍然有更好的性能,且鲁棒性更强。
1.4性能比对
为了展示本方案方法的性能,将其与其他算法进行比对,如表1,可以发现ddq方法在全部5个当中仍是性能最差的。从gpddq,un-gpddq,和kl-gpddq智能体的运行结果中,可以很明显地看出,本方案kl散度检查对性能提升很有帮助,并且其对于成功率和奖励都有显著提升。与ddq对比,本方案方法能够在与用户交互更少的情况下,还提升20%的成功率
表1:缓冲器大小为5000的不同智能体训练迭代{100,200,300}次,k=20时的实验结果;
上表中,su(success,成功率),tu(turns,对话回合),re(reward,奖励)。
另外,由图8还可以看出,本方案提出的方法的学习速度远远高于ddq和d3q。需要注意的是d3q的曲线起伏很大,很不稳定,尤其是当k=30时,d3q甚至不能收敛到最优值,所以即使d3q能够剔除低质量经验,其仍然很难在现实中实现,因为gan太不稳定了。
由上述多个实验,我们能够看到相对于现有技术基于ddq框架的方法,本方案具有明显的优越性,能够在提高系统效率的同时提高鲁棒性。
本文中所描述的具体实施例仅仅是对本发明精神作举例说明。本发明所属技术领域的技术人员可以对所描述的具体实施例做各种各样的修改或补充或采用类似的方式替代,但并不会偏离本发明的精神或者超越所附权利要求书所定义的范围。
尽管本文较多地使用了模拟经验、真实经验、质量检测器、人类会话数据、gp模型、世界模型、缓冲器、对话策略模型、真实用户经验库等术语,但并不排除使用其它术语的可能性。使用这些术语仅仅是为了更方便地描述和解释本发明的本质;把它们解释成任何一种附加的限制都是与本发明精神相违背的。
- 还没有人留言评论。精彩留言会获得点赞!