一种基于高光谱图像和深度学习的茶叶分类方法
本发明属于茶叶检测技术领域,尤其涉及一种基于高光谱图像和深度学习的茶叶分类方法。
背景技术:
作为茶的故乡,我国具有历史悠久的茶文化。饮茶可以追溯到神农时代。茶是一种人们喜爱的绿色健康饮品。茶叶中富含有利于人体健康的多种氨基酸,矿物质和维生素等。研究已经证明茶叶具有一定的保健、药理等功效。长期饮用有益于人体健康,因此茶叶也越来越多的受到人们的青睐。随着饮茶群体的不断扩大以及人们生活质量的提高,人们对名茶的需求量也逐渐增加。实际生活中,由于名茶与普通茶叶的经济价值差距可达数倍,因此用外观较为接近的低价茶叶来冒充高价茶叶就成了不法商贩追逐暴力的常见手段之一,普通消费者仅凭肉眼根本难以区分。更有甚者,通过向经济价值高的茶叶中掺入外观接近的低价茶叶来欺骗消费者,掺假后的茶叶即便是经验丰富的饮茶者也难以正确辨别。目前,茶叶线上与线下销售中都存在着不同程度的售假情况,因此如何快速无损的对茶叶售假进行检测不仅有助于维护消费者利益,也有助于规范茶叶市场。
在诸多茶叶中,铁观音在外观上与部分乌龙茶如本山茶、金观音、黄金桂、毛蟹茶、大叶乌龙、梅占茶相似,但是其经济价值与铁观音大相径庭。以及市面上经常会出售掺假其他茶叶的铁观音现象出现,因此本发明在分别类似茶叶的研究上具有重大意义。
现有技术一的技术方案
茶叶品质判别的方法目前有电子舌和电子鼻,分别是通过模拟人的味觉和嗅觉对待测样品进行分析、识别和判断。电子鼻是由气敏传感器、信号处理和模式识别系统等功能器件组成,通过对气味,综合评价气体的整体信息,在茶叶检测中,得到茶叶的香气成分响应图,由模式识别方法的分析、鉴别和判断,实现对不同种类和等级的判断。电子舌是用类脂膜作为味觉传感器,以类似人的味觉感受方式检测味觉物质,通过输出与样品有关的信号模式,经过模式识别从而得到对样品味觉特征有关的总体评价。在不同茶叶类别方面,通过电子鼻检测搜集茶叶气味信息,从气味角度对茶叶进行识别;通过对电子舌对茶叶的基础滋味和回味进行评价。如今已经有人利用电子鼻、电子舌联用的茶叶品质检测方法。将茶叶回味信息用于茶叶品质的鉴别之中,采用pca降维和lda降维对引入的回味信息进行比较,通过svm进行相应的预测模型,对茶叶等级划分。用电子鼻检测气味信息对茶叶的滋味快速预测。茶叶滋味受呈味物质影响,而呈味物质又会影响茶叶中挥发性气体含量。
电子鼻和电子舌是对茶叶宏观信息进行检测,进而忽略了茶叶中的大量化学成分对茶叶品质的影响。在茶叶检测中,需要获取茶叶的茶汤,破坏茶叶原有结构,并不适用于实际运用中。另外电子鼻和电子舌的传感器的灵敏度和选择性较低、缺少完整的检测数据库、缺乏匹配的数据分析方法等问题也进一步限制了它们的实际应用。在茶叶分类过程中,因掺假茶叶中是由本茶叶和其他茶叶混合而成,因而会利用电子鼻和电子舌对茶叶掺假分析具有难度,难以分辨茶叶的真假。
现有技术二的技术方案
目前,在对于茶叶的品质等级评审中主要采取感官评审结合理化指标测定的模式进行等级评定。在感官评审中主要由评审专家依据外形、汤色、香气、滋味、叶底这五个指标进行综合评判;在理化指标测定的过程中主要按照国家标准测定茶叶的水分、茶氨酸、茶多酚等指标是否满足国家标准的规定。主要包括顶空固相微萃取、气相色谱-质谱联用法、液相色谱-质谱联用法以及高效液相色谱法等。
这种感官评审和理化指标的评审模式都有其不可避免的缺陷,主要表现在感官评审具有较大的主观性,理化指标测定需要多样品进行破坏,由此产生资源的浪费;此外理化测定过程繁琐、耗时,由此产生较多的人为误差,致使测定结果可信度不高;同时由于测定耗时,不能实现制茶过程中的实时监测,对于生产实际的指导意义不大;还有一个不可忽视的缺陷是理化指标测定昂贵,也限制了理化方法对于茶叶内含成分的测定应用。这些方法虽然能够达到较高的检测精度,但是检测过程中会对试验样本造成破坏,而且需要专业人员对试验进行操作,因此难以将其推广应用。
近年来,光谱技术的发展,使得在茶叶无损检测方面有重大突破,有近红外光谱检测技术、高光谱检测技术、拉曼光谱、傅里叶光谱检测等方法,多是利用光谱数据对样本进行分析,利用计算机深度学习的分类方法较少。
光谱技术也存在一定的局限性,因其数据采集方式多为点光源采样,采集到的数据信息较为有限,因此会对最终的检测效果造成影响。在茶叶检测中经常选择利用光谱数据进行分析,因而忽略了一些重要波段,故而检测效果难以得到保证。在计算机深度学习方面,数据集的选取常常没有保证,大多都是从网络中选取图片,既没有专家鉴定认证,图片的清晰度也不够。因此寻求一种可靠的数据集极为关键。
技术实现要素:
本发明的目的在于解决上述现有技术存在的缺陷,提供一种基于高光谱图像和深度学习的茶叶分类方法,解决现有技术中检测过程耗时长,依赖大量化学试剂,浪费大,有污染等问题,实现茶叶品质的无损检测。
本发明采用如下技术方案:
一种基于高光谱图像和深度学习的茶叶分类方法,包括如下步骤:
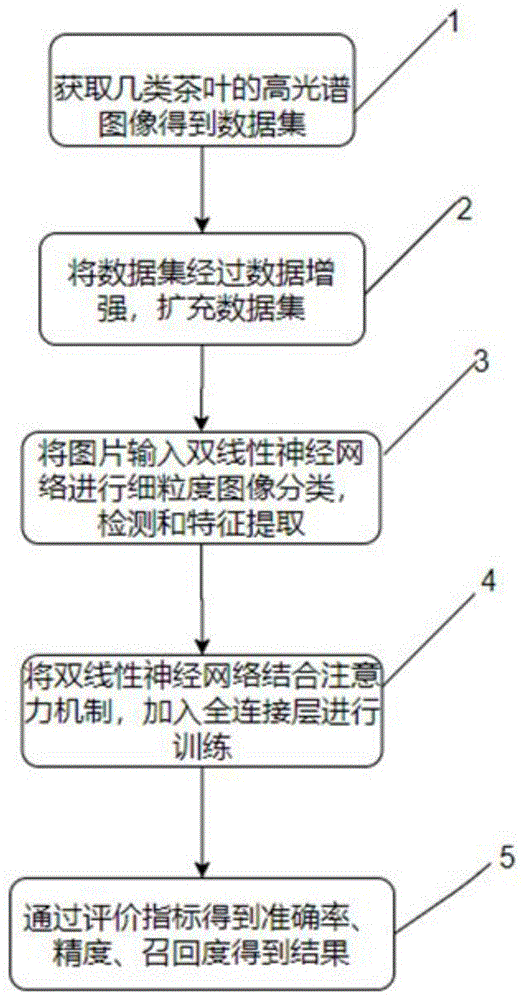
步骤1.获取茶叶的高光谱图像得到数据集;
步骤2.将数据集经过数据增强,扩充数据集;
步骤3.将图片输入双线性神经网络进行细粒度图像分类,检测和特征提取;
步骤4.将双线性神经网络结合注意力机制,加入全连接层进行训练;
步骤5.通过评价指标得到准确率、精度、召回度。
进一步的技术方案是,步骤1包括:获取多种茶叶,茶叶样本采用100×20的玻璃培养皿进行盛装,随机均匀铺满培养皿底部1cm为一个样本,每个样本为10g,每一类采集了50个样本。
进一步的技术方法,步骤2包括:原始的图片集有7种不同品种的茶叶,共350张,因为训练卷积神经网络需要大量图像数据,以防止过拟合;因此采用tensorflow2.0内置的imagedatagenerator接口来增强输入图像数据,通过将图片进行随机旋转、平移、剪切操作,融合在一起得到扩充图片增加了6倍的数据集,把经过数据拓展的图片,利用efficientnetb4网络架构来提取特征层,并对模型进行微调和原本模型的全连接层进行修改,根据需要分类的个数将softmax层修改为7层,根据模型的不同而分别冻结不同的层数,并使用迁移学习的方式,用imagenet的权重去进行预训练。
进一步的是,步骤3包括:通过综合优化网络宽度、网络深度和输入图像分辨率达到指标提升的目的,能够达到准确率指标和现有分类网络相似的情况下,大大减少模型参数量和计算量;
现有8个efficientnet-b0-b7模型,通过比较模型的参数和准确率综合考虑选定了efficientnet-b4的,把图片输入双线性神经网络进行细粒度图像分类过程中局部区域的检测与特征提取任务;双线性卷积神经网络(bilinearcnn)是利用a、b两路卷积神经网络提取图像每一位置的两个特征,再进行外积相乘,最后通过分类层来进行分类,模型通过cnna和cnnb网络相互协调,cnna的作用是对图像的特征部位进行定位,而cnnb则是用来对cnna检测到的特征区域进行特征提取,完成了细粒度图像分类过程中局部区域的检测与特征提取任务。
进一步的是,步骤4包括:将双线性卷积神经网络得到的结果结合cbam注意力模块,先通过一个通道注意力模块,得到加权结果之后,再经过一个空间注意力模块,最终进行加权得到提取结果。
进一步的是,步骤5包括:需要用到精度和召回率来评估模型的质量,精度是指正确检测到的物体在所有检测到的物体中所占的比例,而召回率是指正确检测到的物体在所有检测到的阳性样本中所占的比例,如下所示:
其中真阳性tp和真负值tn表示正确分类的图像,假阳性fp和假阴性fn表示图像被错误分类。
准确率:accuracy=(tp+tn)/(tp+fp+tn+fn),表示的就是所有样本都正确分类的概率,可以使用不同的阈值t。
精确率为:precision=tp/(tp+fp),表示的是召回为正样本的样本中,到底有多少是真正的正样本。
召回率为:recall=tp/(tp+fn),表示的是有多少样本被召回类。
f1是对精度和召回率综合考虑的一个指标,精确率和召回率的调和平均。
本发明的有益效果:
一方面,本发明突破传统单一高光谱成像的茶叶分类方法,通过获取高光谱图像从特征选择与特征提取的角度对高光谱做数据处理,本发明利用高光谱图像,获得真实可靠的数据集,采集到的数据更全面。另一方面,结合利用计算机深度学习的优点,选择了最优的网络模型和参数,本发明中选用双线性卷积神经网络结合注意力机制,efficientnetb4在精度、模型参数和模型大小方面都优于vgg16、resnet50等其他模型。更好的优化了网络模型。
两者的相互结合,针对目前没有公开可用的茶叶图片数据集,高光谱成像获取的图片更具可靠性和安全性,所制作的数据集,用于网络模型的训练,通过数据增强的方式扩大数据集,使得数据集的质量更有保障。对比多种网络模型结构选择最佳模型进行数据处理分析,得到分类结果。在数据集的选取中更加可靠,模型的准确率大有提高,训练的时间也有所加快,验证了此方法对茶叶分类的可靠性。
附图说明
图1为本发明的步骤流程图;
图2为efficient-b4的网络结构;
图3为双线性卷积神经网络结构示意图;
图4为双线性模型添加注意力机制图。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚,下面本发明中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
如图1所示,本发明的一种基于高光谱图像和深度学习的茶叶分类方法,包括如下步骤:
采集铁观音、金观音、本山茶、黄金桂、毛蟹茶、大叶乌龙、梅占茶的高光谱图像,将得到的数据集通过旋转、平移等操作融合在一起得到扩充图片,得到扩展后用efficientnetb4网络架构来提取特征层,将卷积层输出的结果再结合cbam,通过一个通道注意力模块得到加权结果之后,再经过一个空间注意力模块,最终进行加权得到提取结果,将cbam得到的提取结果与特征层逐一相乘,加入全连接层进行分类,最终得到最终分类结果。
实施例1
将长相相似的铁观音、金观音、本山茶、黄金桂、毛蟹茶、大叶乌龙、梅占茶利用深度学习从而进行分类。
获取茶叶高光谱图像
在市面上获取铁观音、金观音、本山茶、黄金桂、毛蟹茶、大叶乌龙、梅占茶,茶叶样本采用100×20的玻璃培养皿进行盛装,随机均匀铺满培养皿底部1cm左右为一个样本,每个样本约为10g,每一类采集了50个样本;
本实验所用高光谱成像系统采用的是卓立汉光公司image-λ“谱像”系列高光谱相机,主要由成像光谱仪和ccd组成,相机的光谱采集范围为400nm-1000nm,光谱的最小分辨率为2.8nm,光谱范围内共有520个波段,测定速度每个样品小于1min。高光谱相机像素为1344×1024,像素尺寸为6.45×6.45μm,采用dc12v电源供电,正常运行温度为0-40℃。
数据增强
原始的图片集有7种不同品种的茶叶,共350张。因为训练卷积神经网络需要大量图像数据,以防止过拟合。
本发明中采用tensorflow2.0内置的imagedatagenerator接口来增强输入图像数据,通过将图片进行随机旋转、平移、剪切等操作,融合在一起得到扩充图片大约增加了6倍的数据集。把经过数据拓展的图片,利用efficientnetb4网络架构来提取特征层。并对模型进行微调和原本模型的全连接层进行修改,根据需要分类的个数将softmax层修改为7层。本发明根据模型的不同而分别冻结不同的层数,并使用迁移学习的方式,用imagenet的权重去进行预训练。
efficientnet网络
通过综合优化网络宽度、网络深度和输入图像分辨率达到指标提升的目的,能够达到准确率指标和现有分类网络相似的情况下,大大减少模型参数量和计算量。
现有8个efficientnet-b0-b7模型(或者使用vgg16、resnet50、alexnet、vggnet、迁移学习等),通过比较模型的参数和准确率综合考虑选定了efficientnet-b4的,本发明所用的网络结构如图2中所示。
把图片输入双线性神经网络进行细粒度图像分类过程中局部区域的检测与特征提取任务。
双线性卷积神经网络(bilinearcnn)是弱监督细粒度分类的代表之作,它的思路是利用双路的卷积神经网络分别提取图片的特征,然后基于提取的两组特征进行双线性组合,让特征的信息更加丰富。其网络结构如图3所示,它是利用a、b两路卷积神经网络提取图像每一位置的两个特征,再进行外积相乘,最后通过分类层来进行分类。本发明中,模型通过cnna和cnnb网络相互协调,cnna的作用是对图像的特征部位进行定位,而cnnb则是用来对cnna检测到的特征区域进行特征提取,完成了细粒度图像分类过程中局部区域的检测与特征提取任务。
将双线性卷积神经网络得到的结果结合cbam注意力模块,首先会先通过一个通道注意力模块,得到加权结果之后,再经过一个空间注意力模块,最终进行加权得到提取结果,如图4所示。
模型评估
最后通过模型评估指标进行数据分类的评定
评价一个模型最简单也是最常用的指标就是准确率,但是在没有任何前提下使用准确率作为评价指标,准确率往往不能反映一个模型性能的好坏,因此需要用到精度和召回率来评估模型的质量。精度是指正确检测到的物体在所有检测到的物体中所占的比例,而召回率是指正确检测到的物体在所有检测到的阳性样本中所占的比例。如下所示:
其中真阳性(tp)和真负值(tn)表示正确分类的图像。假阳性(fp)和假阴性(fn)表示图像被错误分类。
准确率:accuracy=(tp+tn)/(tp+fp+tn+fn),表示的就是所有样本都正确分类的概率,可以使用不同的阈值t。
精确率为:precision=tp/(tp+fp),表示的是召回为正样本的样本中,到底有多少是真正的正样本。
召回率为:recall=tp/(tp+fn),表示的是有多少样本被召回类。
f1是对精度和召回率综合考虑的一个指标,精确率和召回率的调和平均。
实施例2
实施例2与实施例1的不同之处在于,利用高光谱获取图像信息。
在利用高光谱获取图像信息的同时也可以通过获取光谱特征来对茶叶进行分类。从模型建立与方法上来说,提取更加丰富而具有代表性的特征,采用不同的特征变量筛选方法进行特征变量的提取,方法有:iriv迭代保留信息变量算法,消除离子散射对光谱数据的影响;cars竞争自适应加权采样法,通过自适应重加权采样技术选择出plsr模型中回归系数绝对值大的波长点去掉权重小的波长点,有效寻出最优变量组合的算法;uve无信息变量消除算法,通过去除无用信息并提取特征波长的方法。利用偏最小二乘回归系数法对变量进行稳定性分析的算法,得到解释能力更好的特征变量,在建立模型方法还有极限学习机elm等。
1.本发明利用高光谱成像系统对样本进行采集,不损害茶叶样本结构。即利用高光谱获得可靠的数据集。
2.本发明通过高光谱图像获得数据集,研究并使用了双线性卷积神经网络,结合注意力机制,在时间和精确度上得到优化。
3.本发明保护重点即为高光谱采集茶叶创建数据集,然后进行分类的深度学习方法。
最后应说明的是:以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围。
- 还没有人留言评论。精彩留言会获得点赞!