一种基于ElasticSearch快速搭建搜索平台的方法与流程
本发明涉及数据存储搜索技术领域,具体领域为一种基于elasticsearch快速搭建搜索平台的方法。
背景技术:
一般企业初期会选择关系型库mysql做为数据存储。随着业务增长,数据量每日剧增,对于部分场景,关系型库无法满足时。elasticsearch做为一个分布式、高扩展、高实时的搜索与数据分析引擎,能够很方便的使大量数据具有搜索、分析能力。对于开发中elasticsearch的引入,相应的要考虑数据同步的实现、elasticsearch数据搜索业务接口实现。
技术实现要素:
针对现有技术存在的不足,本发明的目的在于提供一种基于elasticsearch快速搭建搜索平台的方法。
为实现上述目的,本发明提供如下技术方案:一种基于elasticsearch快速搭建搜索平台的方法,其步骤为:
(1)设定平台化搜索架构;
(2)基于平台化搜索架构设定关系型数据库和与关系型数据库匹配的数据转换中间件;
(3)设定elasticsearch服务平台,将数据转换中间件与elasticsearch服务平台数据对接;
(4)设定sql转dsl引擎模块,将sql转dsl引擎模块与elasticsearch服务平台数据对接;
(5)设定统一api层和业务层,通过统一api层将业务层与sql转dsl引擎模块之间进行数据对接;
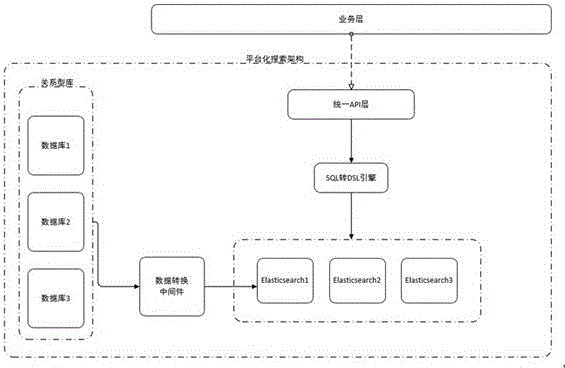
所述的平台化搜索架构包括服务器和设置在服务器内的数据转换中间件、elasticsearch服务平台、sql转dsl引擎模块、统一api层和业务层,业务层为图形化界面操作模块,统一api层用于设置elasticsearch服务平台对外暴露的统一接口和分装elasticsearch服务平台的查询接口,数据转换中间件用于对关系型数据库的异构数据进行处理并同步到elasticsearch服务平台,sql转dsl引擎模块用于将外部的sql查询语言转换为dsl查询语言并输出到elasticsearch服务平台。
优选的,数据转换中间件的设置为在服务器内配置elasticsearch-jdbc工具,并在elasticsearch-jdbc工具中设置环境变量,然后在服务器中elasticsearch-jdbc工具的根目录下新建odbc_es文件夹,在该文件夹内新建mysql_import_es.sh脚本,然后为该脚本添加可执行权限,通过数据转换中间件完成关系型数据库与elasticsearch服务平台之间查询数据的同步。
优选的,elasticsearch服务平台为基于lucene构建的开源、分布式、restful搜索引擎,将该引擎嵌入服务器中。
优选的,sql转dsl引擎模块的设置为构造树形结构的boolquery模型,并在bool中嵌套must和should,即boolmust和boolshould,设定查询条件为and时采用boolmust,查询条件为or时采用boolshould,
设定query内部的第一个boolmust作为根节点,内部嵌套的查询条件和第二个boolmust作为第一个boolmust的两个子节点,第二个boolmust作为第三个boolmust的根节点,第二个boolmust内部嵌套的查询条件和第三个boolmust作为第二个boolmust的子节点。
优选的,统一api层的设置为基于promise设计调用fetchapi,
fetchapi配置为:
fetch(url)
.then(res=>res.json())
.then(console.log)
.catch(console.error)。
优选的,业务层包括图形化管理数据和图形化管理elasticsearch,图形化管理数据用于对关系型数据库的接入配置、以及数据表和elasticsearch字段数据映射配置,图形化管理elasticsearch用于对elasticsearch服务平台中的数据结构进行管理和对集群中的节点进行管理。
优选的,elasticsearch服务平台的elasticsearch引擎数量根据实际需求的关系型数据库的容量进行设定。
与现有技术相比,本发明的有益效果是:
1、实现快速搭建平台化的搜索引擎
2、平台搜索支持近实时的查询
3、支持sql搜索。
附图说明
图1为本发明的原理框图。
具体实施方式
下面将结合本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
本发明提供一种技术方案:一种基于elasticsearch快速搭建搜索平台的方法,其步骤为:
(1)设定平台化搜索架构;
(2)基于平台化搜索架构设定关系型数据库和与关系型数据库匹配的数据转换中间件;
(3)设定elasticsearch服务平台,将数据转换中间件与elasticsearch服务平台数据对接;
(4)设定sql转dsl引擎模块,将sql转dsl引擎模块与elasticsearch服务平台数据对接;
(5)设定统一api层和业务层,通过统一api层将业务层与sql转dsl引擎模块之间进行数据对接;
所述的平台化搜索架构包括服务器和设置在服务器内的数据转换中间件、elasticsearch服务平台、sql转dsl引擎模块、统一api层和业务层,业务层为图形化界面操作模块,统一api层用于设置elasticsearch服务平台对外暴露的统一接口和分装elasticsearch服务平台的查询接口,数据转换中间件用于对关系型数据库的异构数据进行处理并同步到elasticsearch服务平台,sql转dsl引擎模块用于将外部的sql查询语言转换为dsl查询语言并输出到elasticsearch服务平台。
数据转换中间件的设置为在服务器内配置elasticsearch-jdbc工具,并在elasticsearch-jdbc工具中设置环境变量,
#vi/etc/profile
exportjdbc_importer_home=/elasticsearch-jdbc;
使环境变量生效:#source/etc/profile;
然后在服务器中对elasticsearch-jdbc工具进行配置使用,通过在elasticsearch-jdbc工具的根目录下新建文件夹odbc_es:
#ll/odbc_es/
drwxr-xr-x2rootroot4096jun1603:11logs
-rwxrwxrwx1rootroot542jun1604:03mysql_import_es.sh;
然后在该文件夹内新建脚本mysql_import_es.sh:
#catmysql_import_es.sh
’#!/bin/sh
bin=$jdbc_importer_home/bin
lib=$jdbc_importer_home/lib
echo'{
"type":"jdbc",
"jdbc":{
"elasticsearch.autodiscover":true,
"elasticsearch.cluster":"my-application",
#簇名,详见:/usr/local/elasticsearch/config/elasticsearch.yml
"url":"jdbc:mysql://10.8.5.101:3306/test",#mysql数据库地址
"user":"root",#mysql用户名
"password":"123456",#mysql密码
"sql":"select*fromcc",
"elasticsearch":{
"host":"10.8.5.101",
"port":9300
},
"index":"myindex",#新的index
"type":"mytype"#新的type
}
}'|java\
-cp"${lib}/*"\
-dlog4j.configurationfile=${bin}/log4j2.xml\
org.xbib.tools.runner\
org.xbib.tools.jdbcimporter;
然后为该脚本mysql_import_es.sh添加可执行权限:#chmoda+xmysql_import_es.sh;
执行脚本mysql_import_es.sh:
#./mysql_import_es.sh;
通过数据转换中间件完成关系型数据库与elasticsearch服务平台之间查询数据的同步。
上述中间件设置完成后,使用elasticsearch检索查询,测试数据同步是否成功:
#curl-xget'http://10.8.5.101:9200/myindex/mytype/_searchpretty'
{
"took":4,
"timed_out":false,
"_shards":{
"total":8,
"successful":8,
"failed":0
},
"hits":{
"total":3,
"max_score":1.0,
"hits":[{
"_index":"myindex",
"_type":"mytype",
"_id":"avvxkgeeun6ksbtikowh",
"_score":1.0,
"_source":{
"id":1,
"name":"laoyang"
}
},{
"_index":"myindex",
"_type":"mytype",
"_id":"avvxkgeeun6ksbtikowi",
"_score":1.0,
"_source":{
"id":2,
"name":"dluzhang"
}
},{
"_index":"myindex",
"_type":"mytype",
"_id":"avvxkgeeun6ksbtikowj",
"_score":1.0,
"_source":{
"id":3,
"name":"dlulaoyang"
}
}]
}
};
出现以上包含mysql数据字段的信息则为同步成功。
elasticsearch服务平台为基于lucene构建的开源、分布式、restful搜索引擎,将该引擎嵌入服务器中。
sql转dsl引擎模块的设置为构造树形结构的boolquery模型,并在bool中嵌套must和should,即boolmust和boolshould,设定查询条件为and时采用boolmust,查询条件为or时采用boolshould,
设定query内部的第一个boolmust作为根节点,内部嵌套的查询条件和第二个boolmust作为第一个boolmust的两个子节点,第二个boolmust作为第三个boolmust的根节点,第二个boolmust内部嵌套的查询条件和第三个boolmust作为第二个boolmust的子节点。
sql的select语句在被解析之后生成一个select的结构体,其where结构可解析为ast抽象语法树,根据查询条件的数量生成相应数量的节点,每个节点为一个comparisonexpr表达式,这个“比较表达式”即是所有复杂ast的叶子节点。叶子结点在ast遍历的时候一般也就是递归的终点。
当通过sql转dsl引擎模块进行转换,例如查询条件为aand(bandc)时,query{
boolmust{
a,
boolmust{
b,
c
}
}
};
把query内部的第一个boolmust当作根节点,内部嵌套的a和另一个boolmust当作它的两个子节点,然后b和c又是这个boolmust的子节点。可以看出来,实际上这棵树和ast的节点可以一一对应;
当查询条件为aand(band(cord)ande):即,
query{
boolmust{
a,
boolmust{
b,
boolshould{
c,
d
},
e
}
}
};
上述内容与sql的where解析后的ast树进行比较为完全匹配,因此对sql解析生成的ast进行递归,即可得到这棵树。
另外,如果子节点的类型和父节点的类型一致,例如都是and表达式或者都是or表达式,可以在生成dsl的时候将其作为并列的节点进行合并。
统一api层的设置为基于promise设计调用fetchapi,
fetchapi配置为:
fetch(url)
.then(res=>res.json())
.then(console.log)
.catch(console.error)。
async/await
try{
constdata=awaitfetch(url).then(res=>res.json())
console.log(data)
}catch(e){
console.error(e)
};
业务层包括图形化管理数据和图形化管理elasticsearch,图形化管理数据用于对关系型数据库的接入配置、以及数据表和elasticsearch字段数据映射配置,图形化管理elasticsearch用于对elasticsearch服务平台中的数据结构进行管理和对集群中的节点进行管理。
elasticsearch服务平台的elasticsearch引擎数量根据实际需求的关系型数据库的容量进行设定。
尽管已经示出和描述了本发明的实施例,对于本领域的普通技术人员而言,可以理解在不脱离本发明的原理和精神的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由所附权利要求及其等同物限定。
- 还没有人留言评论。精彩留言会获得点赞!