一种横向联邦学习的自适应性参数融合方法
本发明涉及人工智能技术领域,特别是涉及一种横向联邦学习的自适应性参数融合方法。
背景技术:
随着人工智能技术的发展,人们为了解决数据隐私问题,提出了联邦学习的概念,联邦学习是一种新型的分布式机器学习算法,它使得多个参与方在不用给出己方数据的情况下,通过共享参数来搭建高性能模型,避免了各方数据隐私泄露。
联邦学习划分为横向联邦学习和纵向联邦学习。横向联邦学习适用于联邦学习的参与方的数据特征是对齐的,即数据有重叠的数据特征,但是拥有的数据样本是不同的;纵向联邦学习适用于联邦学习参与方的训练数据样本是对齐的,即数据有重叠的数据样本,但是在数据特征上有所不同。
目前,横向联邦学习主要模型融合方法为梯度平均和模型平均。梯度平均即将各参与方训练后的模型梯度进行均值融合作为最新模型的更新梯度;模型平均即将各参与方训练后的模型参数进行均值融合作为最新的最新模型参数。
然而,“平均”参数融合方法对于各参与方参数信息的调节方法过于简单,缺乏一定的自适应性,从而容易忽略各参与方数据自身的分布差异特点,融合后的模型性能容易偏向部分参与方,导致融合后的最新模型在部分参与方上表现欠佳,而一般希望得到的是融合后的模型取得平均性能高,且要缩小所有参与方取得的模型性能方差。出现上述缺点的主要原因是,“平均”参数融合方法并不具备“可学习”的能力,即各参数方的参数信息所占权重无法根据训练情况进行自适应调节,或调节过程过于依靠人工参数。
因此,公开号为cn111522669a的中国专利申请提供了一种改进方法,其结合了梯度平均算法和模型平均算法各自的优点,实现了一种混合联邦平均机制,其过程为:按照预设策略从参数更新类型中确定各轮模型更新中各参与方需要发送的本地模型参数更新的目标类型,其中,参数更新类型包括模型参数信息和梯度信息;服务器向各参与方发送指示目标类型的指示信息,以供各参与方根据指示信息进行本地训练,并返回目标类型的本地模型参数更新;服务器对从各参与方接收的目标类型的本地模型参数更新进行融合,将融合得到的全局模型参数更新发送给各参与方,以供各参与方根据全局模型参数更新进行模型更新。然而,该方法虽然结合了梯度平均算法和模型平均算法各自的优点,但仍缺乏一定适应性。
公开号为cn111522669a的中国专利申请也提出了一种改进方法:服务器获取参与横向联邦学习的各参与方的设备资源信息;根据各所述设备资源信息分别配置各所述参与方对应的联邦学习模型训练过程中的计算任务参数,所述计算任务参数包括预计处理时间步长和/或预计处理批大小;将所述计算任务参数对应发送给各所述参与设备,以供各所述参与设备根据各自的所述计算任务参数执行联邦学习任务。然而,此方法虽然利用了各数据方的数据所带来的贡献,但计算预计处理时间步长/批大小增加了额外计算量。
公开号为cn110378487a的中国专利申请还提出了一种改进方法:通过服务器将各个模型训练设备上报的模型参数下发至除自身的模型训练设备之外的其他模型训练设备进行误差评估,使得服务器可以获得各个模型参数的误差值集合,从而可以根据各个模型参数的误差值集合,筛选出无效模型参数,进而在模型训练过程中,在确定下一个模型训练周期使用的初始模型参数时,可以剔除这些无效模型参数。然而,此方法虽然能够剔除一些无效模型参数,但参数融合方式仍未发生改变,缺乏一定自适应性。
技术实现要素:
为克服上述现有技术存在的不足,本发明之目的在于提供一种横向联邦学习的自适应性参数融合方法,将参与方的参数权重作为需要更新的“可学习”的参数,各参与方在第一阶段先更新自身的模型参数,在第二阶段即融合阶段对融合参数基于梯度下降的优化方法进行更新,使得参数权重能够不断地进行调整,适应最新的训练情况,实现融合过程的“可学习”。
为达上述及其它目的,本发明提出一种横向联邦学习的自适应性参数融合方法,包括如下步骤:
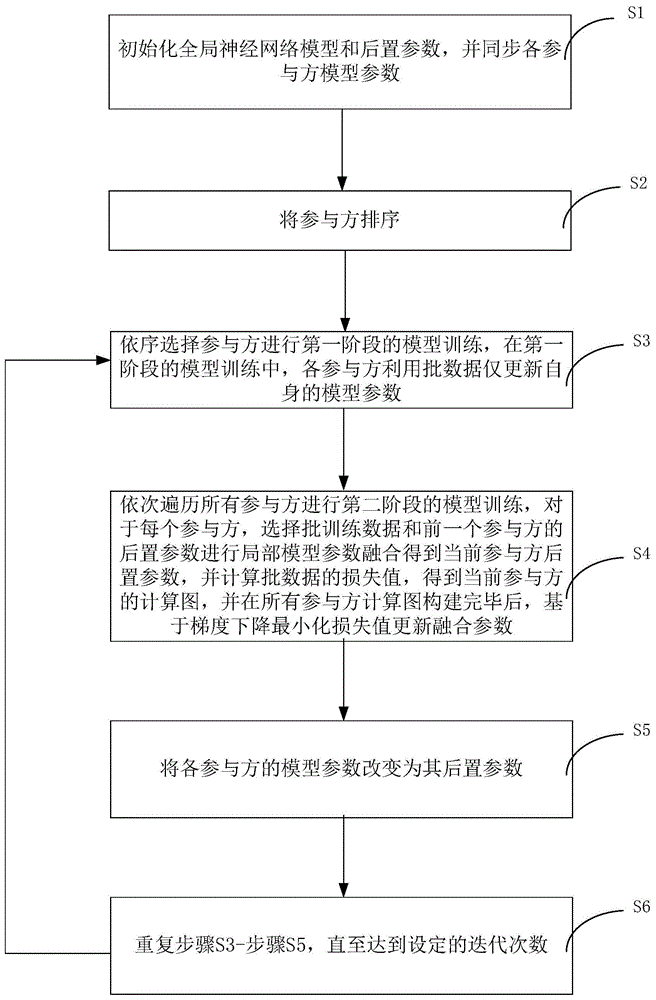
步骤s1,初始化全局神经网络模型和后置参数,并初始化同步各参与方模型参数;
步骤s2,将参与方排序;
步骤s3,依序选择参与方进行第一阶段的模型训练,在第一阶段的模型训练中,各参与方利用批数据仅更新自身的模型参数;
步骤s4,依次遍历所有参与方进行第二阶段的模型训练,对于每个参与方,选择批训练数据和前一个参与方l-1的后置参数hl-1进行局部模型参数融合得到当前参与方后置参数hl,并计算批数据的损失值,得到当前参与方的计算图,并在所有参与方计算图构建完毕后,基于梯度下降最小化损失值更新融合参数;
步骤s5,将各参与方的模型参数wl改变为其后置参数hl;
步骤s6,重复步骤s3-步骤s5,直至达到设定的迭代次数。
优选地,在步骤s1中,设定好全局神经网络模型的结构,初始化其网络参数,并构建统一的损失函数
优选地,步骤s3进一步包括:
步骤s300,依序选择参与方l;
步骤s301,判断是否遍历到最后一个参与方,若是,则进入步骤s4,否则进入步骤s302;
步骤s302,当前参与方选择批数据进行模型的小步迭代更新;
步骤s303,选择下一个参与方l+1,并返回步骤s301。
优选地,于步骤s302中,每个参与方随机选择一部分自身拥有的训练数据作为批数据,在批数据上,利用随机梯度下降法sgd进行模型训练,从而每个参与方的模型参数wl得到更新。
优选地,步骤s4进一步包括:
步骤s400,依序选择参与方l;
步骤s401,判断是否遍历到最后一个参与方,若是,则进入步骤s406,否则进入步骤s402;
步骤s402,当前参与方选择批训练数据和前一个参与方l-1的后置参数hl-1进行局部模型参数融合得到当前参与方后置参数hl;
步骤s403,根据得到的后置参数hl计算批数据的预测值
步骤s404,根据构建的损失函数
步骤s405,选择下一个参与方l+1,并返回步骤s401,直至遍历所有参与方;
步骤s406,根据每个参与方的损失函数值
优选地,于步骤s402中,当前参与方l随机选择批训练数据
优选地,根据如下公式融合得到当前参与方l的后置参数hl:
其中,gh函数为激活函数,,αl、βl、
优选地,于步骤s403中,根据如下公式计算批数据的预测值
其中,gy函数为激活函数,
优选地,于步骤s406中,根据每个参与方的损失函数值
与现有技术相比,本发明具有如下有益效果:
1、本发明通过将参数融合的过程转换为优化问题,使参数融合过程变得“可学习”,具备自适应性;而现有技术的融合方法普遍采用“平均”方法,缺乏自适应性;
2、本发明将参与模型训练各方的融合权重作为可更新的融合参数,利用梯度下降的优化方法来更新其融合参数;而现有技术的融合权重设定过于简单,难以根据训练情况来进行自适应地调节;
3、本发明将参数融合的过程分为两个阶段,一个阶段是各参与方利用批数据仅更新自身的模型参数,第二阶段是通过最小化总的损失值,来实现优化融合参数;而现有技术主要是仅采用第一个阶段,即更新模型的参数,就进行“平均化”的参数融合,并没有优化融合参数的过程。
附图说明
图1为本发明一种横向联邦学习的自适应性参数融合方法的步骤流程图;
图2为本发明实施例中横向联邦学习的自适应性参数融合方法的流程图;
图3为本发明实施例中第二阶段训练过程示意图。
具体实施方式
以下通过特定的具体实例并结合附图说明本发明的实施方式,本领域技术人员可由本说明书所揭示的内容轻易地了解本发明的其它优点与功效。本发明亦可通过其它不同的具体实例加以施行或应用,本说明书中的各项细节亦可基于不同观点与应用,在不背离本发明的精神下进行各种修饰与变更。
图1为本发明一种横向联邦学习的自适应性参数融合方法的步骤流程图。如图1所示,本发明一种横向联邦学习的自适应性参数融合方法,包括如下步骤:
步骤s1,初始化全局神经网络模型和后置参数,并初始化同步各参与方模型参数。
在本发明中,假设有n个参与方(由于数据隐私保护的要求,参与方之间不能共享隐私数据),在最初神经网络参数初始化的时候,所有参与方会协商构建一个相同参数的神经网络模型,即被称为全局神经网络模型(但当各参与方根据自己的数据更新后,就不再存在全局神经网络模型了,因为各参与方的数据不同,导致训练出来的神经网络参数也变得不同),其中,第l个参与方拥有其自己的神经网络模型dnnl,其网络结构中拥有其自身的参数wl,目的则是要将每个参与方神经网络模型的参数进行融合,在不需要共享训练数据且没有参数服务器参与的前提下,参与方之间对等地接收其他参与方的参数并进行融合。
具体地,在步骤s1中,先设定好全局神经网络模型的结构,并初始化其网络参数,所述网络参数指神经网络连接权重w,构建统一的损失函数
步骤s2,将参与方排序,以便依序进行模型训练。在本发明具体实施例中,输入参与方训练顺序,以便后续按照从前向后依次进行模型训练。
步骤s3,依序选择参与方进行第一阶段的模型训练,在第一阶段的模型训练中,各参与方利用批数据仅更新自身的模型参数(即神经网络连接权重wl)。
具体地,步骤s3进一步包括:
步骤s300,依序选择参与方l;
步骤s301,判断是否遍历到最后一个参与方,若是,则进入步骤s4,否则进入步骤s302,
步骤s302,当前参与方选择批数据进行模型的小步迭代更新。
在本发明中,每个参与方随机选择一部分自身拥有的训练数据(称为批数据)。每个参与方在批数据上,利用随机梯度下降法sgd进行模型训练,从而每个参与方的模型参数wl得到更新,当然每个参与方在模型训练中,本发明也可视任务采用其他梯度下降方法,本发明不以此为限。
步骤s303,选择下一个参与方l+1,并返回步骤s301。
步骤s4,依次遍历所有参与方进行第二阶段的模型训练,对于每个参与方,选择批训练数据和前一个参与方l-1的后置参数hl-1进行局部模型参数融合得到当前参与方后置参数hl,并计算批数据的损失值,得到当前参与方的计算图,并在所有参与方计算图构建完毕后,基于梯度下降最小化损失值更新融合参数,所述融合参数包括
具体地,步骤s4进一步包括:
步骤s400,依序选择参与方l;
步骤s401,判断是否遍历到最后一个参与方,若是,则进入步骤s406,否则进入步骤s402;
步骤s402,当前参与方选择批训练数据和前一个参与方l-1的后置参数hl-1进行局部模型参数融合得到当前参与方后置参数hl。
具体地,参与方l随机选择批训练数据
其中,gh函数为激活函数,默认可选双曲正切函数tanh,αl、βl、
需说明的是,在本发明中,最初第一个参与方需要的后置参数h0是符合正态分布的随机值并在未来的使用中都固定其值。
步骤s403,利用如下公式(2)计算批数据的预测值
其中,gy函数为激活函数(默认可选双曲正切函数tanh),
步骤s405,选择下一个参与方l+1,并返回步骤s401,直至遍历所有参与方。
步骤s406,根据每个参与方的损失函数值
在本发明具体实施例中,根据每个参与方的损失函数值
其中σ为更新步长参数。
步骤s5,将各参与方的模型参数wl改变为其后置参数hl,即
步骤s6,重复步骤s3-步骤s5,直至达到设定的迭代次数。
实施例
如图2所示,在本实施例中,一种横向联邦学习的自适应性参数融合方法,其过程如下:
步骤1,先设定好全局神经网络模型的结构,并初始化其网络参数(神经网络连接权重wl),构建统一的损失函数
步骤2,将参与方排序,按照从前向后依次进行模型训练:
步骤3,第一阶段:更新神经网络模型的自身参数(神经网络连接权重wl)。每个参与方随机选择一部分自身拥有的训练数据(即批数据)。参与方在批数据上,利用随机梯度下降sgd进行模型训练,从而每个参与方的模型参数wl得到更新。
步骤4,第二阶段:更新融合参数αl、βl、
a,遍历到第l个参与方
b,参与方l随机选择批训练数据
c,当前参与方l通过将前一个参与方l-1的后置参数hl-1和自身模型的参数wl依照以下公式融合得到当前参与方l的后置参数hl。
其中gh函数为激活函数(默认可选双曲正切函数tanh),αl、βl、
最初第一个参与方需要的h0是符合正态分布的随机值并在未来的使用中都固定其值。
d,依照以下公式计算批数据的预测值
其中gy函数为激活函数(默认可选双曲正切函数tanh),
e,根据构建的损失函数
f,完成当前参与方l的计算图构建。
依次遍历所有参与方,通过进行步骤a至f的计算来构建计算图。
接下来根据每个参与方的损失函数值
其中σ为更新步长参数。
步骤5,将各参与方的模型参数wl改变为其后置参数hl,即
步骤6,重复步骤3-5,直到达到设定的迭代次数。
综上所述,本发明一种横向联邦学习的自适应性参数融合方法针对协调方对各参与方模型参数信息所占权重的调节方法过于简单、缺乏自适应性的问题,将各参与方模型参数融合中的权重设置的过程转换为一个优化问题,通过利用梯度下降的优化方法,训练出一个全局的神经网络模型,从而实现融合过程“可学习”,有效地在保障融合后模型的整体性能的同时,使得各参与方取得的模型性能的方差得到降低(现有技术中为了防止模型的性能偏向部分参与方,这时模型的性能方差较大,因为各参与方模型性能差距较大,而本发明通过自适应性的调整,可以达到较低的模型性能方差,在模型“平均”性能上表现更佳)。
上述实施例仅例示性说明本发明的原理及其功效,而非用于限制本发明。任何本领域技术人员均可在不违背本发明的精神及范畴下,对上述实施例进行修饰与改变。因此,本发明的权利保护范围,应如权利要求书所列。
- 还没有人留言评论。精彩留言会获得点赞!