一种基于高频共现的热点话题识别方法
本发明涉及热点话题识别
技术领域:
,尤其涉及的是,一种基于高频共现的热点话题识别方法。
背景技术:
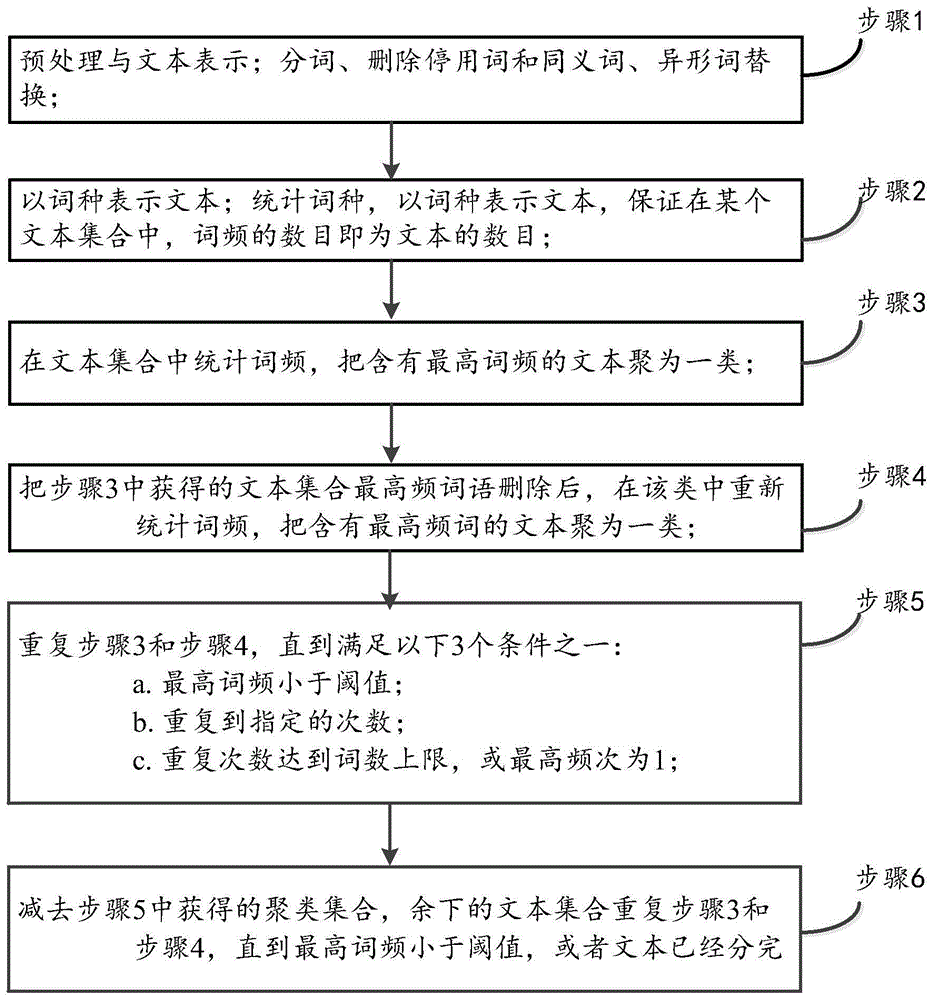
:热点话题识别属于话题识别的具体运用,话题识别相关的研究主要集中在tdt评测,在tdt中,话题识别任务一般采用自动聚类的策略。传统的聚类策略一般把文本分词后表示成词向量,其本质是基于内容的,聚类形成的报道集合内部具有较高的相似性,数量大的集合可判为热点话题。由于传统的聚类具有时间复杂度高,对初始聚类中心高度敏感等缺陷,在实际热点话题识别中,大部分系统采用了改进型的聚类策略。近年,较多的学者开始注意到提及数、转发数、参与数和评论数等形式特征在热点话题识别中的重要作用,一些新的算法不断被提出来,比如基于时序特征的聚类策略。下面分别从基于内容、基于形式、形式与内容相结合3个方面分别综述。1基于内容的方法基于内容的热点话题识别主要采用k-means、增量和层次聚类的方法。标准的k-means算法采用随机初始化聚类个数与聚类中心的方法,容易陷入局部最优。为获得最佳聚类个数与最有效的聚类中心,国内外许多学者就这个问题进行了较多的研究。taoli等人在2004年对如何自动预测文本集合的聚类个数进行了研究,likas等人在2003年则对初始聚点的选择提出了新的方案。增量聚类算法中,一般采用single-pass在1998年方法,马国栋在2014年改进了single-pass聚类质心不唯一的缺陷,提高了热点话题识别的速度,但其仅以词数较多的质心为唯一质心的做法仍需进一步研究。层次聚类算法一般采用自下而上的凝聚聚类策略,刘星星2008年提出了一种在多策略优化基础上的增量多层聚类的热点话题发现算法,算法的创新之处在于以凝聚聚类的微类为增量聚类的初始种子,结合了层次聚类与增量聚类的优点,通过腾讯网一年的数据的测试显示该方法具有较好的可行性,该方法时间复杂度较高。此外还有通过关键词或词频的方法,比如周亚东在2007年提出了通过对网络连接中流量的监控,以任意2个高频度词语的同时出现次数为基本热度度量,以此识别热点话题,该方法需在路由器上监测流量数据,主要适用于政府或者学校等网络管理部门。2基于形式特征的方法基于形式特征的方法对文本内容分析较少,代表性的算法是基于话题的提及(mention)数、评论数等时序变化特征的聚类方法。、yangetal.在2011年在大量的新闻、博客、twitter数据上对话题的关注度进行了分析,以话题在一定时间范围被提及的数量变化为基础,制定了k-spectralcentroid(k-sc)算法。实验证明该方法在话题关注度的判别上具有较高的精度,并且能较好地刻画话题的趋势变化。但该方法对初始类矩阵中心高度敏感,并且时间复杂度较高。韩忠明等2012年在yang等人2011年的基础上提出了wksc(wavelet-basedk_scalgorithm)算法,用haar小波变换将原始时间序列进行压缩,降低原始时间序列的维度;在haar反小波变换中,将低维聚类返回得到的矩阵中心作为高维聚类的初始矩阵中心,在迭代聚类过程中优化了对初始矩阵中心高敏感性的问题,提高了聚类的效果。该文把话题的热度定义为一定时间间隔内的评论数和相关报道数,而在实际的实验中仅以评论数为热度指标,评论数的变化显示的主要是用户的关注热度,而相关报道显示的是不同媒体的关注热度,因此仅以评论数为热度指标并不能完全反映话题的热度。周而重在2010年提出了基于用户视角的博客热点识别方法,通过话题的持续时间、成长程度、用户参与度和话题的新颖性来度量话题的热度,该方法各参数的获取较为复杂。3内容与形式相结合的方法李恒训在2009年分析了话题热度的决定参数,以主题词为基础结合热点话题决定参数中的形式特征(浏览数、评论数),制定了多维特征融合的热点话题识别方法。该方法以主题词表为基础,通过多重过滤从标题和文本中各选取两个主题词代表整个文本,以获得的主题词为基础查询其他文本的标题,当其他文本的标题中含有所获得的主题词时,则聚为一类。该算法具有较高的时效性和准确度,实用性较强,但其对所获得的主题词的精度要求较高,且对初始主题词表有较大依赖性。罗亚平在2007年对用户浏览行为进行量化,在传统词向量采用tf/idf值的基础上,添加用户浏览行为信息。该文所指的浏览行为如阅读时间、评论、收藏等,其中用户阅读时间等参数的获取难度较大。彭菲菲在2013年提出了基于特征优化的热点话题过滤算法,该方法以基丁蚁群优化的迭代自适应聚类算法为基础,同时结合不同用户对话题的发布、转发量多个特征,对热点话题进行过滤。以上从内容与形式两个方面综述了热点话题识别方法。基于内容的方法通过相似度计算实现对话题的归类,可获得某个话题相关(相同)的一系列报道的数量,但算法较为复杂,时间复杂度较高。基于形式特征的方法较少分析文本内容,评论数、提及数等参数的动态变化较为直接地显示了新闻的热度变化,在速度上要优于基于内容的方法,在热点话题识别上具有一定的优势,但其显示的仅为单条新闻报道的热度,并不能完全代表整个话题的热度变化,并且,大规模的记录海量网络新闻的时序特征具有相当的难度。归纳起来,当前热点话题识别算法的不足主要有3点:(1)传统的聚类策略时间和空间复杂度较高,不利于实时的热点发现;(2)改进的聚类策略自定义的参数获取复杂,可操作性不强;(3)对判定话题热度的形式特征缺乏系统的研究。因此,现有技术存在缺陷,需要改正。技术实现要素:本发明提供一种基于高频共现的热点话题识别方法,在热点话题识别的基础上,本发明从媒体关注和情感倾向两个维度的变化来共同完成热点话题的趋势预测。即媒体对热点话题的关注在当前状态下是趋向于上升,还是趋向于下降,公众对热点话题的情感倾向在时序变化的同时,是趋向于正面,还是趋向于负面。本发明的技术方案如下:一种基于高频共现的热点话题识别方法包括以下步骤:步骤1:预处理与文本表示;分词、删除停用词和同义词、异形词替换;步骤2:以词种表示文本;统计词种,以词种表示文本,保证在某个文本集合中,词频的数目即为文本的数目;步骤3:在文本集合中统计词频,把含有最高词频的文本聚为一类;步骤4:把步骤3中获得的文本集合最高频词语删除后,在该类中重新统计词频,把含有最高频词的文本聚为一类;步骤5:重复步骤3和步骤4,直到满足以下3个条件之一:a.最高词频小于阈值;b.重复到指定的次数;c.重复次数达到词数上限,或最高频次为1;步骤6:减去步骤5中获得的聚类集合,余下的文本集合重复步骤3和步骤4,直到最高词频小于阈值,或者文本已经分完。上述中,所述步骤1中的替换是以哈尔滨工业大学同义词词林为基础,并根据具体领域进行了一定的调整。上述中,所述步骤3中的词频数量即为文本数量。上述中,所述步骤3中,统计词频具体为:高频词共现次数越多,所获得的类中的成员相似性度越大,其结果类似于凝聚层次聚类形成的微类。上述中,所述高频词共现是指,在实现高频词共现过程中,每一步都会产生一个最高频词语,可根据每次共现的高频词语进行合并。上述中,所述步骤6之后,还包括步骤7:合并相似的类。本发明方法中的高频共现聚类策略算法简洁,准确率和召回率较高,可定义话题的热度且时间复杂度极低,具有较高的可操作性和较大的灵活性,可用于标题也可用于文本。附图说明图1为本发明方法流程图。具体实施方式为了便于理解本发明,下面结合附图和具体实施例,对本发明进行更详细的说明。除非另有定义,本说明书所使用的所有的技术和科学术语与属于本发明的
技术领域:
的技术人员通常理解的含义相同。本说明书中在本发明的说明书中所使用的术语只是为了描述具体的实施例的目的,不是用于限制本发明。本说明书所使用的术语“和/或”包括一个或多个相关的所列项目的任意的和所有的组合。在热点话题识别中,有三种聚类方法较为常用,分别是k-means、single-pass和凝聚层次聚类。这三种算法中k-means速度相对较快,能应付较大规模网络语料的聚类,但k-means是一种划分聚类法,网络文本的话题一般较分散,热点话题常常淹没在海量的噪声信息中,如果选择的初始中心个数过小,则容易把相关性小的文本划分到一个类中,热点话题无法突显出来,如果初始中心个数设置过大,速度会大大下降。single-pass属于经典的增量聚类策略,无需考虑聚类中心,相关的话题会不断被聚集到一起,热点话题较容易突显出来,但其是一种贪心算法,每次进入的文本要和所有的类中的文本比较,随着聚类数量的增加,系统的资源会被耗尽,故基本无法用于海量网络文本。凝聚层次聚类是一种自底向上的策略,算法十分严谨,该方法能把最相似的话题聚为一类,可获得令人满意的热点话题识别效果,但每次只能合并一个最相似的类,速度极其缓慢。层次聚类和增量聚类在热点话题识别中具有较大的优势,特别是层次聚类的效果很明显,但由于速度原因目前较少用于实时的大规模文本热点话题识别。实施例1基于以上内容,本发明提出了基于最小相似度为基础的高频共现聚类策略的一种基于高频共现的热点话题识别方法。该方法前提条件为:“相同(或近义)词的使用是话题相似的基础,使用了一个以上相同词的文本才有可能报道同一个话题,含有最多相同词的新闻集合最有可能报道相同的话题。”本方法具体包括以下步骤:步骤1:预处理与文本表示;分词、删除停用词和同义词、异形词替换;所述替换是以哈尔滨工业大学同义词词林为基础,并根据具体领域进行了一定的调整;比如“男人”与“男子、男子汉、男儿”是同义词,把“男子、男子汉、男儿”全部替换为“男人”。步骤2:以词种表示文本;统计词种,以词种表示文本,这样做的目的是保证在某个文本集合中,词频的数目即为文本的数目。步骤3:在文本集合中统计词频,把含有最高频词的文本聚为一类(词频数即为文本数)。步骤4:把步骤3中获得的文本集合最高频词语删除后,在该类中重新统计词频,把含有最高频词的文本聚为一类。步骤5:重复步骤3和步骤4,直到满足以下3个条件之一:a.最高词频小于阈值;b.重复到指定的次数;c.重复次数达到词数上限,或最高频次为1。步骤6:减去步骤5中获得的聚类集合,余下的文本集合重复步骤3、步骤4和步骤5,直到最高词频小于阈值,或者文本已经分完。步骤7:合并相似的类(可选步骤)高频词共现次数越多,所获得的类中的成员相似性度越大,其结果类似于凝聚层次聚类形成的微类。在共现过程中,每一步都会产生一个最高频词语,可根据每次共现的高频词语进行合并。例如表2是“英语退出高考”这一话题的3次共现聚类情况。表2合并举例表2显示,3次共现后,获得了两个类,第1类在第3次共现后共有20个文本,第2类共10个文本,可根据第1次与第2次共现相同的词语“高考、英语”两词将这两个类进行合并。可以看出,如果共现选择的次数为2,则不需要合并,因此本步骤是可选择的。合并可以排除无关文本和实现话题分级,如果选择的共现次数较少,则容易把具有一定相似度的无关文本聚到类中,通过控制共现次数,可以获得高度相似的微类,这个时候,再进行合并,还可以实现话题的分级。表2中的数据显示,共现两次后,获得的话题与“英语高考”相关;3次共现后,话题分得更细,可获得“英语退出高考”和“高考英语改革”两个微类。实施例2在实施例1的基础上,本发明以高等教育舆情相关的7个新闻标题详述本发明所述的高频共现方法的具体实现过程,所选标题详情如表3:表3高等教育舆情相关7个新闻标题及来源步骤1:预处理与文本表示;预处理包括分词、删除停用词和同义词替换,处理后的标题如表4所示。表4预处理与文本表示(步骤1)预处理后,对标题作词种统计,最后以词种表示标题。当标题词数小于共现次数时,可以考虑用空格或其他符号补齐,本次示例共循环7次,标题最小词数要求7个及以上,因此本次示例不需进行补齐。进一步举例说明实现步骤2、步骤3及步骤4;即步骤2:统计词种,以词种表示文本,从而保证在单个文本集合中,文本数即为词频;步骤3:在文本集合中统计词频,把含有最高频词的文本聚为一类(词频即为文本数);步骤4:把步骤3获得的文本集合的最高频词语删除后,在该集合中重新统计词频,将含有最高频词的文本聚为一类。表5:实现步骤2、步骤3及步骤4过程举例说明实现步骤5;即重复步骤3和步骤4,直到满足以下3个条件之一时得到一个话题聚类:a.最高词频小于阈值;b.重复到指定的次数;c.重复次数达到词数上限,或最高频次为1。表6:实现步骤4及步骤5过程表5、6说明,第1轮循环,所有标题中“教授”一词频次最高,含“教授”一词的6个新闻被聚为一类;第2轮循环,“辞职”一词频次最高,同时含有“教授、辞职”两词的5个新闻被聚合到一起;第3轮循环,有“教授、辞职、硕士生导师”同时共现的4个新闻被聚为一类,叙述的话题与教授辞去硕士生导师一职相关;第4轮和第5轮循环,有“办、私塾”两个最高频词共现,话题进一步明确为教授辞职办私塾;第6轮循环,话题明确到地点,即“中央财大”的教授辞职,共有3个相似新闻;第7轮循环后,共现高频词语为“中央财大、教授、辞职、硕士生导师、办、私塾、教育”7个,仅有2个具有高度相似的新闻,论述教授辞职这一事件引发的教育相关问题讨论。如果再循环下去最高频将为1,对于热点话题识别来说已经没有意义。高频词共现词语的详细情总如表7所示。表7:高频聚类词语频次变化详情,即实现步骤6的过程至此,一个完整的高频共现策略完成,下面通过实验论证方法的效果与可行性。为验证高频共现聚类策略的可行性,本发明选择了10个话题,其中高等教育舆情5个,语言文字舆情3个,社会舆情2个。除“提笔忘字”所包含的文本内容跨度较大外,其他话题都是内容较集中的舆情事件。共527个文本,文本长度在1000-1500字之间,总字符数507,617,其中汉字数399,288。语料详情如表8。表8:测试文本语料分布详情序号话题文本数领域1冯小刚繁体字议案25语言文字2七名教授套取科研经费72高等教育3浙江启动高校新课改40高等教育4河南某高校忘开必修课71高等教育5尼泊尔地震58社会舆情6汉字危机之提笔忘字68语言文字7创业创新纳入必修课27高等教育8湖南大学研究生转学事件56高等教育9英语退出高考风波83社会舆情实验所采用电脑基本参数:windows7中文旗舰版,64位操作系统,四核8线程,16g内存。一、选择对比算法热点话题识别中较为常用的聚类方法主要有k-means、single-pass和凝聚层次聚类等,本文选择这3种方法与高频共现方法作比较。3种常用的聚类算法都以词的tf/idf值组成的向量表示文本,文本的相似度以余弦相似度(cosinesimiliarity)来衡量。k-means聚类采用标准算法,聚类个数及聚类中心进行了一定的人工干预。single-pass聚类是一种动态聚类方法,新进入的文本需要循环比较与所有类中的每个成员的相似度,每次都要重新调整词的tf/idf值,计算量较大,因为测试的文本集合已经确定,本文把tf/idf值的计算过程看作一个静态的过程,在文本进入前已经计算完成。凝聚层次聚类簇与簇间的相似度采用单链(min),即定义簇的邻近度为不同两个簇的两个最近的点之间的距离。高频共现聚类策略分两种情况测试,一种以文本内容聚类,另一种仅以标题进行聚类。分词与删除停用词等预处理过程不参与到聚类的时间计算中,4种方法经多次聚类实验后,选择最好的一次聚类效果。二、实验过程及结果分析1.k-means聚类分析实验数据共10个热点话题,多次实验后,设定了12个初始类别,实验结果的原始数据如表9。表9k-means聚类文本分布详情表9说明:k-means是一种划分聚类,测试文本的527个文本被划分到12个类中。行中的数字表示测试的10个话题中的文本分布到聚类形成的12个类中的情况,列中的数字表示聚类形成的12个类每一类所获得的文本分别属于测试文本中的哪个话题。行中的数字以“七名教授套取科研经费”为例说明,该话题共72个文本,聚类后被分到了1、3、4、9四个类中,其中第1、4两类聚合的文本数较多,分别为43和27,对文本的内容分析后发现,1类中的43个文本所述及的内容主要集中在对事件本身的报道,而4类中的27个文本的内容主要集中在对该事件的评论上,比如谴责、声讨等。列中的数字以第11类为例说明,该类共61个文本,属于“浙江启动高校新课改”的32个文本和属于“创业创新纳入必修课”的24个文本被聚合到一起,两个话题在“课程、培养、改革”等词上相同,相似度较高。第11类包括“河南某高校忘开必修课”的4个文本,与前述的2个话题在“高校、必修课、毕业”等词上有较多的相似点。上述两个话题显示自动聚类所归纳的类与测试文本中人工归纳的话题有较大区别,此外“提笔忘字”被分到了4个类中,其中最大的两类为2和5,分别有36和27个文本,36个文本的内容集中在“提笔忘字”的原因讨论上,关键词为“计算机、手机、键盘”,而27个文本的内容集中在对“提笔忘字”的担忧上,关键词为“民族、文化、忧心”。因聚类形成的类别多于测试文本的10个话题,以聚类效果最好的类作为最终结果。比如第1、4类所概括的关键词语都与测试文本中的话题“七名教授套取科研经费”有较高的相似度,但第1类含有更多的文本,最终选择第1类。实验结果如表10所示。表101k-means聚类结果实验结果显示,k-means聚类平均准确率略高于召回率,f1值0.8,效果较好,但漏报率达到了0.2,因此还需进一步合并或根据相似度删除类中的干扰信息。2.single-pass聚类分析single-pass是一种增量聚类,可通过调整相似度优化聚类结果,多次测试后最终获得21个类,实验结果的原始数据如表11所示。表11single-pass聚类文本分布详情表11说明:单边聚类可以通过相似度大小的调整实现对聚类数量的控制,本实验把相似度定为0.2后,测试的527个文本分布到了21个类中。单边聚类形成的类虽然比测试文本的10个话题多了一倍,但从聚类后的文本分布可以看出效果较为理想,比如“冯小刚繁体字议案”共25个文本,有23个文本被聚合到一个类,且只有3个“提笔忘字”话题相关文本被分到该类。single-pass聚类实验效果如表12所示。表12single-pass聚类结果实验结果显示,single-pass聚类平均准确率很高,达到0.95,f1值达到了0.86,超过k-means0.06,但漏报率达到了0.19,仅比k-means减少0.01。因single-pass和k-means的初始聚类中心都是随机选择的,当新进入的文本相似度达不到阈值时,新的类就不断被产生。比如“提笔忘字”这一话题,被分到了9个类中,且有两个类的文本数量比较大,分别是26和23。因此,single-pass聚类的召回率仍需提高,可通过优化初台聚类中心或合并相近的类提高召回率。3.凝聚层次聚类分析本文采用自底向上的凝聚层次聚类进行实验,527个文本,共聚类526次,选择第371次聚类结果,该次聚类共形成156类,从中选择了12个类,文本分布如表13所示。表13凝聚层次聚类文本分布详情表13说明:凝聚层次聚类每次只选择最相似的一个类合并,本文选择的聚类结果是第371次,“提笔忘字”因话题内容较分散,仅召回3个。该话题只到420次聚类后才被较好的合并,此时其他几个相近的类也被合并,比如“创业创新纳入必修课”“浙江启动高校新课改”被聚合到一类。实验结果如表14所示。表14凝聚层次聚类结果表14的实验结果显示,凝聚层次聚类准确率极高,几乎完全正确,但f1值仅为0.79,比k-means还低0.01,漏报率达0.28。如从热点话题识别的角度看,似乎并不理想,但从整个聚类形成的树来看,话题聚合过程极其清楚,热点话题一目了然,并且可从聚合过程中归纳话题的子话题。4.高频共现聚类分析本次实验分别测试了文本和标题的高频共现效果,文本聚类终止条件设置为共现8次,话题热度阈值选择5,低于5个文本的类被舍弃,对含有3个相同关键词语的类进行合并,最后形成12个类,表15是文本分布情况。表15高频共现聚类文本分布详情(文本)表15说明:高频共现聚类策略随着共现次数的增加,聚合的文本相似度逐渐提高,同时漏报的可能性也加大。从分布情况看,聚合的话题相对比较集中,但“创业创新纳入必修课”和“冯小刚繁体字议案”漏报较多。聚类结果如表16所示。表16高频共现聚类结果(文本)表16的实验结果显示,文本层面的高频共现策略准确率较高,达0.93,但f1值仅为0.79,漏报率达0.27。文本内容较为分散,新闻标题一般能反映文章主旨,本文对标题也进行了高频共现聚类测试,共现1次,即只以一个高频关键词聚类。表17是文本分布情况。表17高频共现聚类文本分布详情(标题)表17显示,大部分话题被单独聚合在一起,效果较好。但“浙江启动高校新课改”与“创业创新纳入必修课”因为高频词“改革”被合并到第5类。本次实验把该类作为这两个话题的聚类结果。最终聚类结果如表18所示。表18高频共现聚类结果(标题)表18的实验结果显示,仅通过一个最高频词对标题聚类就得到了较为满意的聚类效果,其聚类效果的f1值为本次实验最好结果。5.综合分析前文分别论述了4种方法的实验结果,为比较方法的优劣,把各个方法的运行时间,10个话题的平均准确率、平均召回率、平均漏报率和平均f1值合成一张表,详情如下表19所示。表19四种聚类方法效果比较表19显示,漏报率最低的是标题层面的高频共现聚类,其次是single-pass聚类,最高的是凝聚层次聚类;准确率最高的是凝聚层次聚类,其次是single-pass聚类,k-means最低;速度最快的是高频共现,其次是k-mens聚类。综合来说,k-means聚类速度较快,适合较大规模的文本聚类,但准确率与召回率相对都不高,热点话题不易突显,需在聚类过程中,或聚类后通过相似度过滤垃圾信息、合并相似的类。single-pass聚类适合面向中小规模的语料,标准算法中,初始中心是随机定义的,因其是一种贪心算法,随着语料的增加,速度会越来越慢,目前采用改进的single-pass进行聚类的热点话题识别方法受到较多的重视。凝聚层次聚类准确率极高,但其运行时间太慢且存储代价太高,在热点话题识别中,可考虑使该方法获得微类,用于k-means或者single-pass的初始中心。高频共现聚类策略算法简洁,准确率和召回率较高,可定义话题的热度且时间复杂度极低,具有较高的可操作性和较大的灵活性,可用于标题也可用于文本。李恒训在2009年的做法就值得借鉴,该方法先识别主题关键词语,然后把标题中含有主题关键词语的文本聚为一类。该方法需要拥有覆盖面较大的主题词表和精度较高的主题关键词识别算法,而且即使主题关键词语识别准确,也不能有效的保证有多个标题含有该关键词语。标题是文章主旨的呈现,通过标题即可基本掌握新闻的主要内容,快速的把相同或相近的标题聚合在一起,就能实现对海量网络信息的实时热点发现。本文统计了154,366个新闻的标题,平均词数为9。删除停用词后,使用1个以上相同的标题已经具有一定的相似度,使用3个以上的相同词语的标题已经具有较高的相似度。该方法获得的聚类集合具有层次性,每共现一次,获得的标题集合相似度就更高,可根据需要选择合适的共现次数。本文通过多次实验后发现,通常来说标题可选择1-3次共现,1000-1500字的文本可选择8-12次共现。虽然标题层面的高频共现聚类在本次测试中有不俗的表现,但标题与内容不一致时,就无能为力了。因此可在识别热点话题后,采用增量聚类策略召回丢失文本。进一步地,本发明的实施例还包括,把基于高频共现的热点话题识别方法封装成了一个模块,在国家语言文字舆情监测系统中得到了实际的运用。本发明方法关注动态识别及其趋势预测:热点话题的动态识别的难点主要在时效上,本发明从内容和形式两个维度研究了热点话题的识别方法;而在趋势预测的方法上主要从媒体关注和情感倾向两个维度的变化来共同完成。传统的聚类方法一般把文本表示成词向量,其本质上是基于文本内容的,而新闻的点击数、参与数和评论数等特征与新闻内容无关,可视之为形式上的特征。门户网站通过点击数或评论数的简单排名即可获得民众一定时间内最为关注的热点话题,因此形式特征也是话题热度的重要因素,已有较多学者开始注意到形式特征在热点话题识别中的重要性,但对特征之间的关系方面,系统的研究尚不多见。本发明通过网络爬虫获得了点击数、参与数和评论数的大量数据,计算并获得了各参数的变化规律和参数之间的比值。在此基础上,关注热点话题在点击数、参与数和评论数变化时其趋势的变化,以此为依据制定了基于形式特征排名的热点话题识别方法。但是,经分析研究后发现:一方面,客观上来说,只有少数网站有点击、参与和评论数,另一方面即使有这些参数的网站,三个参数并不是同时呈现的,大部分只显示评论数,并且为了防止爬虫,一些网站的评论数还以图片的形式呈现。基于以上考虑,本发明以热点话题的识别方法应以基于内容的方法为主。本发明对比了传统的划分聚类(k-means)、增量聚类(single-pass)和层次聚类(凝聚层次聚类)方法的优劣,并在此基础上提出了以最小相似度为基础的高频共现聚类策略。通过实际语料测试,该方法在速度上远远超过传统聚类方法,而且准确率也表现不错,可以有效的解决实时动态热点识别在时效性上的需求。在热点话题识别的基础上,本发明从媒体关注和情感倾向两个维度的变化来共同完成热点话题的趋势预测。即媒体对热点话题的关注在当前状态下是趋向于上升,还是趋向于下降,公众对热点话题的情感倾向在时序变化的同时,是趋向于正面,还是趋向于负面。本发明在国家语言文字舆情监测系统中得到了实际的运用。本发明方法中的高频共现聚类策略算法简洁,准确率和召回率较高,可定义话题的热度且时间复杂度极低,具有较高的可操作性和较大的灵活性,可用于标题也可用于文本。需要说明的是,上述各技术特征继续相互组合,形成未在上面列举的各种实施例,均视为本发明说明书记载的范围;并且,对本领域普通技术人员来说,可以根据上述说明加以改进或变换,而所有这些改进和变换都应属于本发明所附权利要求的保护范围。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1