一种基于认知计算的新井目标井位推荐方法
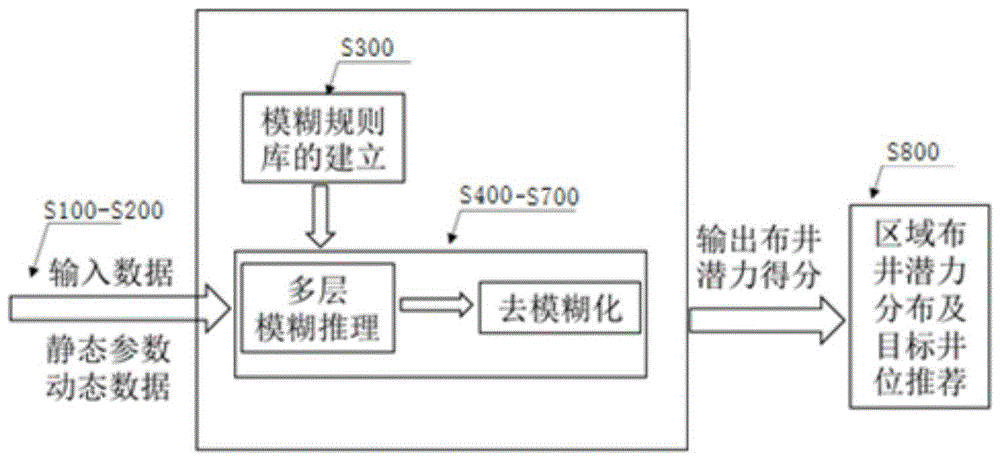
本发明涉及开发中后期油田部署新井动用剩余油
技术领域:
,具体涉及一种基于认知计算的新井目标井位推荐方法。
背景技术:
:石油是全球能源的重要组成部分,随着全球工业的迅速发展,石油能源供给与需求差距越来越大。而油田最终采收率仅为30%-40%,大量剩余油仍滞留在储层未被采出,开发中后期的油田仍具有极大的剩余油挖掘潜力,如果能有效动用剩余油,将大幅度提高油气产量,在一定程度上缓解能源需求紧张的问题。随着油田开发进程的推进,储层非均质性日益显著,可采储量逐步下降,剩余油分散程度及分布特征更加复杂,剩余油动用难度大大增加。为了最大程度地挖潜剩余油,保证油藏的全生命周期开发,无可避免地需要部署新井或加密井动用剩余油。新井目标井位确定是一个极其复杂且耗时的工作。传统的油田中后期开发部署新井的方法,主要是根据油藏静态参数、动态数据及相关政策多方面考虑,由油田专家人为确定新井目标井位。该过程基于专家经验决策新井目标井位,涉及大量的人为不确定性,且专家经验难以量化,难以均衡不同专家经验之间的不一致性,对最终方案设计造成不可逆的影响。技术实现要素:针对现有技术存在的上述问题,本发明的要解决的技术问题是:综合考虑油藏静态参数及动态数据,构建模糊规则集,提出一种新井目标井位推荐方法。为解决上述技术问题,本发明采用如下技术方案:一种基于认知计算的新井目标井位推荐方法,包括如下步骤:s100:针对待确定新井目标井位的油藏,建立该油藏对应的油藏地质模型,所述油藏地质模型共有n个网格,获取每个网格的油藏静态参数;此处的待确定新井目标井位的油藏通常是开发中后期的油藏,对于如何认定开发中后期的油藏属于本领域的公知常识,建立所述油藏对应的油藏地质模型,该建模方法是现有成熟的技术,通过所建立的油藏地质模型可以直接获取所需的油藏静态参数。s200:通过s100建立的油藏地质模型,获取每个网格的油藏动态数据;通过s100建立的油藏地质模型,利用油藏数值模拟的方法,即可获取该油藏的油藏动态数据,需要说明的是油藏数值模拟属于现有技术,通过油藏数值模拟主要为了模拟该油藏的生产历史状况,比如采用水驱开发、衰竭开发、聚合物驱等方案,根据实际油藏实施情况模拟油藏的生产动态。s300:根据先验知识,建立多个模糊变量的模糊规则库。s400:将s100获取的第i个网格的油藏静态参数和s200获取的第i个网格的油藏动态数据输入s300建立的对应的模糊变量的模糊规则库,得到第i个网格对应的多个模糊变量隶属度模糊集合。s500:将s400得到的多个模糊变量隶属度模糊集合进行去模糊化,得到多个对应的模糊变量清晰值。s600:将s500得到的多个对应的模糊变量清晰值输入s300建立的对应的模糊规则库,得到模糊变量布井潜力da的da隶属度模糊集合。将所述da隶属度模糊集合去模糊化得到da的清晰值即为第i个网格的da得分。s700:对于每个网格重复步骤s400-s600,得到每个网格的da得分。s800:以每个网格为中心,以r为半径的圆形区域定位为一个布井潜力区域,根据每个布井潜力区域内的所有网格的da得分计算所有布井潜力区域的区域布井潜力rda得分,区域布井潜力rda得分最高的布井潜力区域确定为新井目标井位的推荐区域并输出。由于在前一个步骤中已经计算得到了每个网格的da得分,因此此时可以通过一个布井潜力区域内所有网格da得分的加权平均或其他平均数来计算一个布井潜力区域的rda得分。作为改进,所述s100中的获取每个网格的油藏静态参数包括渗透率ki,孔隙度φi,净毛比ntgi,泥质含量shi和油层厚度hi,其中i代表网格编号,i=1,2,...n,n代表油藏地质模型的总网格数。作为改进,所述s200中的获取每个网格的油藏动态数据,包括油藏压力pi,剩余油饱和度soi,原油粘度μoi,原油密度ρoi,油相相对渗透率和原油体积系数boi,其中i代表网格编号,i=1,2,...n,n代表油藏地质模型的总网格数。作为改进,定义剩余油可采储量丰度aro和油相流动能力opfc。根据公式(1)计算剩余油可采储量丰度aro,根据公式(2)计算油相流动能力opfc。其中,ωoi表示剩余油可采储量丰度aro的表示符号,sori表示残余油饱和度,soi表示剩余油饱和度,toi表示油相流动能力opfc的表示符号,ki表示渗透率,kroi表示油相相对渗透率,μoi原油粘度。作为改进,当所述油藏内无天然水体时,所述s300中模糊规则库的建立方法如下:s310:建立隶属度函数μq(x),其中x为输入数值,μq(x)表示x对q的隶属程度。其中,a,b,c为隶属度函数的几个常数,可以设定为经验值;比如,油藏地质模型某个网格孔隙度x为0.2,模糊化表示为孔隙度“高”的隶属度μ(x)为0.35,孔隙度“中”的隶属度μ(x)为0.5,孔隙度“低”的隶属度μ(x)为0.15,高中低为语义标签。s320:获取待确定新井目标井位的油藏的多个油藏静态参数和油藏动态数据的历史数据,将开发中后期油藏的油藏静态参数和油藏动态数据的历史数据分别输入到公式(3),计算所有参数对应的隶属度值;将渗透率ki,孔隙度φi,净毛比ntgi,泥质含量shi和油层厚度hi对应的隶属度值利用现有的方法进行模糊规则的生成,即得到rspq模糊规则库。将剩余油可采储量丰度aro和油相流动能力opfc的隶属度值利用现有的方法进行模糊规则的生成,即得到moc模糊规则库。将油藏压力pi的隶属度值利用现有的方法进行模糊规则的生成,即得到ei模糊规则库。分别计算模糊变量rspq的清晰值的隶属度值、模糊变量moc的清晰值隶属度值和模糊变量ei的清晰值的隶属度值,再将rspq的清晰值的隶属度值,模糊变量moc的清晰值隶属度值和模糊变量ei的清晰值的隶属度值利用现有的方法进行模糊规则的生成,即得到da模糊规则库。可以利用现有技术生成模糊规则,例如可用mamdani模糊方法进行模糊规则的生成,还可以用takagi、sugeno和kang提出的tsk模糊系统进行模糊规则的生成,还可以根据自学习模糊系统及自适应模糊网络进行模糊规则的生成。生成的模糊规则可以是:rule1为if{a},then{c},则rule1隶属度的数学表达式为μ(rule1)=min{μ(a),μ(c)}。rule2为if{aandb},then{c},则rule2隶属度的数学表达式为μ(rule2)=min{min{μ(a),μ(b)},μ(c)}。rule3为if{aorb},then{c},则rule3隶属度的数学表达式为μ(rule3)=min{max{μ(a),μ(b)},μ(c)}。综合rule1,rule2和rule3,则最终的规则rules隶属度的数学表达式为μ(rules)=max{μ(rule1),μ(rule2),μ(rule3)}。作为改进,当所述油藏内无天然水体时,所述s400中得到每个网格对应的多个模糊变量隶属度模糊集合的过程如下:s410:将渗透率ki,孔隙度φi,净毛比ntgi,泥质含量shi和油层厚度hi的值输入s300所建立的rspq模糊规则库,得到模糊变量油藏静态参数质量rspq的rspq隶属度模糊集合。s420:将剩余油可采储量丰度aro和油相流动能力opfc的值输入s300所建立的moc模糊规则库,得到模糊变量可动油程度moc的moc隶属度模糊集合。s430:将油藏压力pi的值输入s300所建立的对应的ei模糊规则库,得到模糊变量能量指数ei的ei隶属度模糊集合。每个油藏静态参数或油藏动态数据输入所述模糊规则库中,所述模糊规则库中每条规则都会得到一个集合,那么对于模糊变量可动油程度moc得到moc隶属度模糊集合的过程为:将剩余油可采储量丰度aro和油相流动能力opfc同时输入moc模糊规则库中,每条规则将得到一个集合,将所有规则得到的集合进行并集得到即得moc隶属度模糊集合。其他例如rspq隶属度模糊集合或ei隶属度模糊集合得到方法相同。作为改进,当所述油藏内有天然水体时,所述s300中模糊规则库的建立方法如下:s310’:建立隶属度函数μq(x),其中x为输入数值,μq(x)表示x对q的隶属程度。其中,a,b,c为隶属度函数的几个常数。s320’:获取待确定新井目标井位的油藏的多个油藏静态参数和油藏动态数据的历史数据,将开发中后期油藏的油藏静态参数和油藏动态数据的历史数据分别输入到公式(3),计算所有参数对应的隶属度值;将渗透率ki,孔隙度φi,净毛比ntgi,泥质含量shi和油层厚度hi对应的隶属度值,利用现有的方法进行模糊规则的生成,即得到的rspq模糊规则库。将剩余油可采储量丰度aro和油相流动能力opfc的隶属度值,利用现有的方法进行模糊规则的生成,即得到moc模糊规则库。将距水源距离和水体通量系数的隶属度值,利用现有的方法进行模糊规则的生成,即得到nwdi模糊规则库。将nwdi清晰值的隶属度值和油藏压力pi的隶属度值,利用现有的方法进行模糊规则的生成,即得到ei’模糊规则库。分别计算模糊变量rspq的清晰值的隶属度值、模糊变量moc的清晰值隶属度值、模糊变量nwdi的清晰值的隶属度值和模糊变量ei的清晰值的隶属度值,再将模糊变量rspq的清晰值的隶属度值、模糊变量moc的清晰值隶属度值、模糊变量nwdi的清晰值的隶属度值和模糊变量ei’的清晰值的隶属度值利用现有的方法进行模糊规则的生成,即得到da’模糊规则库。作为改进,当所述油藏内有天然水体时,所述s400中得到每个网格对应的多个模糊变量隶属度模糊集合的过程如下:s410’:将渗透率ki,孔隙度φi,净毛比ntgi,泥质含量shi和油层厚度hi的值输入s300所建立的rspq模糊规则库,得到模糊变量油藏静态参数质量rspq的rspq隶属度模糊集合。s420’:将剩余油可采储量丰度aro和油相流动能力opfc的值输入s300所建立的moc模糊规则库,得到模糊变量可动油程度moc的moc隶属度模糊集合。s430’:将距水源距离和水体通量系数的值输入s300所建立的nwdi模糊规则库,得到天然水驱指数nwdi的nwdi隶属度模糊集合。s440’:将nwdi隶属度模糊集合进行去模糊得到nwdi的清晰值,将nwdi的清晰值和油藏压力pi的值输入s300所建立的ei’模糊规则库,得到模糊变量能量指数ei’的ei’隶属度模糊集合。作为改进,可以采用任何现有方法进行去模糊化的处理,本发明优选采用质心法去模糊化,采用质心法对多个模糊变量隶属度模糊集合进行去模糊化,具体如下:采用公式(5)计算模糊变量的清晰值:其中,表示模糊变量的清晰值,xj为模糊变量的第j个取值,μ(xj)为模糊变量的第j个取值在该模糊变量的模糊变量隶属度模糊集合中所对应的隶属度,m是模糊变量隶属度模糊集合中元素的个数。模糊变量的取值有预先定义,例如定义所有模糊变量的取值范围为tstart-tfinish,取值间隔为t,共取tcount个值,则该模糊变量对应的隶属度模糊集合中元素个数m=tcount,并且模糊变量的每个取值都与其的隶属度模糊集合中一个元素一一对应。作为改进,考虑到油藏剩余油成片聚集分布,新井部署旨在动用成片状聚集的剩余油,相比于每个点或每个网格的布井潜力,某个区域的布井潜力更重要。因此,定义区域布井潜力(rda)的概念,利用区域布井潜力表征以该点或该网格(xc,yc,zc)为中心,某一范围区域内的布井潜力平均值。所述s800中计算区域布井潜力rda得分的步骤为:s810:通过油藏地质模型单层某一网格中心坐标(xc,yc)确定一个四个网格共用的顶点(x0,y0),其中a,b分别为油藏地质模型网格的长度及宽度。s820:将y=y0代入(x-xc)2+(y-yc)2=r2,求出对应的两个横坐标x1,x2。s830:判断(x1-x0)(x2-x0)的正负,若为负,则计算其中int[·]为向下取整函数,(n1+n2)记作n0。若为正,设|x1-x0|<|x2-x0|,则计算其中(n2-n1)记作n0,roundup[·]为向上取整函数。s840:先沿y轴正方向进行迭代,迭代步长为矩形网格的宽度b,重复s810-s830,直至求出的对应横坐标不再为实数解,共计沿正方向迭代mpos次,有mpos-1次ni为实数值,从而得到mpos-1次迭代的ni值,其中i=0,1,2,...,mpos-1,记s850:再从y=y0开始,沿y轴负方向进行迭代,迭代步长为矩形网格的宽度b,当求出的横坐标再次求不出实数解,完成迭代,沿负方向共迭代mneg次,有mneg-1次nj为实数值,从而得到mneg-1次迭代的nj值,其中j=0,1,2,...,mneg-1,记s860:计算ng=∑(np+nn)即求出半径为r的圆形区域内所有的完整网格个数。s870:将距离该网格中心(xc,yc)最近的ng个网格的布井潜力值da取均值,即为该区域布井潜力相对于现有技术,本发明至少具有如下优点:本发明在认知计算的框架内,基于模糊推理建立了认知计算的新井目标井位推荐方法,通过多层模糊推理量化将先验知识引入,输出区域布井潜力的量化得分,从而量化新井目标井位推荐过程需要考虑的各个指标,提高了推荐井位的可靠性。附图说明图1为本发明开发中后期油藏内无天然水体时的技术流程图。图2为实施例1中,某水驱开发油藏地质模型图。图3为实施例1中,某水驱开发油藏静态参数(孔隙度、渗透率、净毛比)分布图。图4为实施例1中,某水驱油藏开发10年后剩余油饱和度分布图。图5为实施例1中,某水驱油藏孔隙度的三角隶属度函数图。图6为实施例1中,某水驱油藏经本发明提出的新井目标井位推荐方法得出的区域布井潜力分布图。图7为经典的punq-s3角点网格油藏地质模型对应的剩余油饱和度分布图。图8为利用本发明提出的新井目标井位决策方法,针对punq-s3角点网格油藏地质模型得出的区域布井潜力分布图。具体实施方式下面结合附图对本发明作进一步详细说明。实施例1:参见图1,一种基于认知计算的新井目标井位推荐方法,主要包括如下步骤:s1:针对水驱开发10年的油藏部署新井动用剩余油的问题,首先建立该油藏的地质模型如图2,该油藏地质模型共有(50×50×1)2500个块中心网格,获取2500个网格的部分静态参数,见图3,主要有渗透率ki,孔隙度φi和净毛比ntgi,其中i代表网格编号,i=1,2,...2500。由于本实施例简单,就单层2500个网格,使用三个参数就可以实现目标。s2:利用油藏数值模拟,在油藏地质模型的基础上,模拟该油藏水驱开发10年的生产状况,获得水驱开发10年后油藏的压力pi,剩余油饱和度soi以及该压力、该剩余油饱和度对应下的原油粘度μoi,原油密度ρi,油相相对渗透率原油体积系数boi等,其中i代表网格编号,i=1,2,...2500。水驱开发后的油藏剩余油饱和度分布见图4。s3:定义剩余油可采储量丰度aro,油相流动能力opfc,根据aro和opfc建立模糊变量可动油程度moc。其中,ωoi表示定义的aro的表示符号,sori表示残余油饱和度,soi表示剩余油饱和度,toi表示定义的opfc的表示符号,ki表示渗透率,kroi表示油相相对渗透率,μoi原油粘度。s4:根据先验知识,建立对应的模糊规则库。1)建立定义隶属度函数μq(x),其中x为输入数值,μq(x)表示x对q的隶属程度。其中,a,b,c为隶属度函数的几个常数;将某个参数明确的数值x用语义变量隶属度值模糊化表示,其中a,b,c为隶属度函数的几个常数,根据具体参数的大小人为指定即可。利用模糊逻辑输出每个输入参数的隶属度值。以油藏“中”孔隙度隶属度函数为例,如图5所示,孔隙度有高、中、低三个语义变量,孔隙度“高”的隶属度函数以点划线表示,孔隙度“低”的隶属度函数以实线表示,孔隙度“中”的隶属度函数以虚线表示。比如,当孔隙度φ为0.15,模糊化表示为孔隙度“高”的隶属度为0.347,孔隙度“中”的隶属度为0.653,孔隙度“低”的隶属度为0。2)获取所述水驱开发10年的油藏的多个油藏静态参数和油藏动态数据的历史数据,将开发中后期油藏的油藏静态参数和油藏动态数据的历史数据分别输入到公式(3),计算所有参数对应的隶属度值,然后利用现有的方法进行模糊规则的生成。例如,油藏压力pi的隶属度值,利用现有的方法进行模糊规则的生成,即得到ei模糊规则库具体见表1;分别计算模糊变量rspq的清晰值的隶属度值、模糊变量moc的清晰值隶属度值和模糊变量ei的清晰值的隶属度值,再将rspq的清晰值的隶属度值,模糊变量moc的清晰值隶属度值和模糊变量ei的清晰值的隶属度值利用现有的方法进行模糊规则的生成,即得到da模糊规则库见表2。表1pei低低中中高高表2rspqmoceida高中/中/高非低高低中低低以能量指数(ei)为例,基于模糊变量的隶属度值进行模糊数学运算,定量表示能量指数模糊规则,其数学描述具体如下:从表1可知,有三条规则,分别是rule1=if{p低},then{ei低};rule2=if{p中},then{ei中};rule3=if{p高},then{ei高}。各规则的隶属度数学表达式为:μ(rule1)=min{μ低(p),μ低(ei)};μ(rule2)=min{μ中(p),μ中(ei)};μ(rule3)=min{μ高(p),μ高(ei)}。现综合考虑以上三个规则,则最终的能量指数(ei)隶属度的数学表达式为:μ(rules)=max{μ(rule1),μ(rule2),μ(rule3)}。这里仅以ei模糊规则库为例定量化表示模糊规则,以此类推可以得到其他对应的规则库,用于后续模糊推理过程。s5:将s1获取的每个网格的油藏静态参数和s2获取的每个网格的油藏动态数据输入s4建立的对应的模糊规则库,得到每个网格对应的多个模糊变量隶属度模糊集合;通过对应的模糊规则库,输入参数如渗透率、孔隙度、净毛比、剩余油可采储量丰度、油相流动能力等具体的参数值,将参数的值转化为模糊变量语义标签的隶属度模糊集合。具体的:将渗透率ki,孔隙度φi,净毛比ntgi参数值分别输入公式(3),计算渗透率ki,孔隙度φi,净毛比ntgi对应的隶属度值,再将渗透率ki,孔隙度φi,净毛比ntgi对应的隶属度值输入rspq模糊规则库中,rspq模糊规则库中的每条规则都会得到一个集合,将渗透率ki,孔隙度φi,净毛比ntgi通过rspq模糊规则库得到的所有集合进行并集,即得到所述模糊变量rspq对应的rspq隶属度模糊集合。依次类推得到moc隶属度模糊集合和ei隶属度模糊集合。s6:为了得出该油藏地质模型各网格的布井潜力da得分,本实施案例1仅需采用两层模糊推理。采用公式(5)计算模糊变量的清晰值:其中,表示模糊变量的清晰值,xj为模糊变量的第j个取值,μ(xj)为模糊变量的第j个取值在该模糊变量的隶属度模糊集合中所对应的隶属度,m是模糊变量的隶属度模糊集合中元素的个数。第一层模糊推理,将rspq、moc和ei对应的隶属度模糊集合分别通过质心法去模糊后得到rspq的清晰值、moc的清晰值和ei的清晰值。质心法去模糊的方法为:将rspq的取值和将rspq隶属度模糊集合中与rspq取值所对应的隶属度值输入到公式(5)得到rspq的清晰值。将moc的取值以及将moc隶属度模糊集合中与moc取值所对应的隶属度值输入到公式(5)得到moc的清晰值。将ei的取值以及将ei隶属度模糊集合中与ei取值所对应的隶属度值输入到公式(5)得到ei的清晰值。第二层模糊推理,将得到的rspq的清晰值、moc的清晰值和ei的清晰值输入da模糊规则库得到模糊变量da对应的da隶属度模糊集合。再采用与上述相同的质心法去模糊的方法得到da的清晰值,da的清晰值即da的得分,具体的:将da的取值以及将da隶属度模糊集合中与da取值所对应的隶属度值输入到公式(5)得到da的清晰值。总之,先通过模糊推理输出各模糊变量的隶属度模糊集合,后利用去模糊函数将输出的各模糊变量的隶属度模糊集合清晰化。通过去模糊化可得出该油藏地质模型每个网格的布井潜力da的得分。分值越高,越适合在该网格所代表的位置布置新井。s7:考虑到油藏剩余油成片聚集分布,新井部署旨在动用成片状聚集的剩余油,相比于每个网格的布井潜力,某个区域的布井潜力更重要。因此,定义区域布井潜力rda的概念,利用区域布井潜力表征以某一网格为中心,某一范围区域内的布井潜力平均值,计算每个范围区域内的区域布井潜力rda得分,区域布井潜力rda得分最高的区域则为新井目标井位的推荐区域。因为该水驱油藏地质模型仅为单层,故假设该范围区域为半径r=500ft(约150m)的圆形区域,具体如下:1)通过油藏地质模型单层某一网格中心坐标(xc,yc)确定一个四个网格共用的顶点(x0,y0),其中a为油藏网格长度和宽度,大小为100ft(约30m)。2)将y=y0代入(x-xc)2+(y-yc)2=5002,求出对应的两个横坐标x1,x2。3)判断(x1-x0)(x2-x0)的正负,若为负,则计算其中int[·]为向下取整函数,(n1+n2)记作n0。若为正,不妨设|x1-x0|<|x2-x0|,则计算其中(n2-n1)记作n0,roundup[·]为向上取整函数。4)先沿y轴正方向进行迭代,迭代步长为100ft,重复s810-s830,直至求出的对应横坐标不再为实数解,共计沿正方向迭代mpos=6次,有5次符合条件,求出每次迭代完整矩形网格的个数ni,其中i=0,1,2,...,5。记求得np=35。5)再从y=y0开始,沿y轴负方向进行迭代,迭代步长为矩形网格的宽度100ft,当求出的横坐标再次求不出实数解,完成迭代。沿负方向共迭代mneg=5次,有4次符合条件,求出每次迭代完整矩形网格的个数nj,其中j=0,1,...,4。记求得nn=26。6)计算ng=∑(np+nn)即求出半径为r的圆形区域内所有的完整网格个数ng=61。7)将距离该网格中心(xc,yc)最近的61个网格的布井潜力值(da)取均值,即为该区域布井潜力如图6,推荐新井目标井位,从而实现基于认知计算辅助新井部署的推荐过程。区域布井潜力得分越高,该地质模型网格所在位置越适合部署新井,该位置越有利于动用剩余油。从图6可以看出,白色三角形位置是根据本发明提出的新井目标井位推荐方法,推荐的三个候选井位。该水驱油藏西北方向虽然剩余油饱和度很高,但渗透率极低、净毛比较小油层较薄,孔隙度也较小,整体油藏物性较差,并不适合布置新井。而本发明方法推荐的三个候选井位综合考虑各种因素,更具有布井潜力。此外,虽然本实施案例1针对的是块中心网格的油藏地质模型,但应当了解本发明提出新井目标井位推荐方法同样适用于角点网格的油藏地质模型。以经典的油藏地质模型punq-s3模型为例,验证该方法对角点网格的适用性。punq-s3模型采用的是角点网格,油层共分5层,每一层的油藏静态参数、动态数据等都各不相同。从图7可以看出,punq-s3油藏每一层的剩余油饱和度分布各有差异,推荐后续开发新井部署的位置具有很大的难度。利用本发明提出的新井目标井位推荐方法,综合考虑新井部署涉及到的各种因素,输出的区域布井潜力图见图8。从图8可知,本发明推荐方法推荐的每个角点网格的区域布井潜力较为合理,如后续部署新井,可部署在区域布井潜力较高的区域,即油藏物性较好位置,从而充分动用区域成片的剩余油。因此,证明了本发明方法在认知计算框架内,利用多层模糊推理搭建的布井潜力推荐井位具有可靠性。最后说明的是,以上实施例仅用以说明本发明的技术方案而非限制,尽管参照较佳实施例对本发明进行了详细说明,本领域的普通技术人员应当理解,可以对本发明的技术方案进行修改或者等同替换,而不脱离本发明技术方案的宗旨和范围,其均应涵盖在本发明的权利要求范围当中。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1