一种结合3D脸部结构先验的人脸超分辨方法与流程
一种结合3d脸部结构先验的人脸超分辨方法
技术领域
1.本发明属于计算机视觉人脸超分辨领域,尤其涉及一种结合3d脸部结构先验的人脸超分辨方法。
背景技术:
2.人脸图像信息在当今社会计算机分析中有众多应用,例如人脸识别和医学诊断。但往往各种技术都要求人脸图像拥有较高的分辨率。当面部图像的分辨率相对较低时,技术准确率会急剧下降。因此,人脸超分辨算法应运而生,帮助人脸图像从低分辨率恢复到高分辨率。
3.现在先进的人脸超分辨算法通常利用深层卷积网络去学习从低分辨到高分辨的人脸模式映射关系。但是,大多数方法没有充分利用脸部结构及身份信息且很难处理脸部姿态变化。这种情况下,大多方法会忽视人脸例如边缘,亮度和表情等的信息。因此,人脸超分辨,尤其是在高放大倍数情况下,仍然是一个具有挑战性的问题。
技术实现要素:
4.本发明的目的在于针对现有技术的不足,提供一种结合3d脸部结构先验的人脸超分辨方法。本发明能够显式地结合3d脸部先验,这种先验能够抓取到高清的脸部结构信息,能够为网络提供一些基于脸部属性的3d拓扑信息,例如身份、表情、纹理、亮度和脸部姿态。
5.本发明的目的是通过以下技术方案来实现的:一种结合3d脸部结构先验的人脸超分辨方法,包括以下步骤:(1)输入低分辨率图像,和对应的高分辨率图像作为真实值;(2)用步骤(1)输入的低分辨率图像与真实值来训练上半分支的resnet
‑
50网络;resnet
‑
50网络输出的是从低分辨率图像中学习的3d脸部信息,再重建成一个脸部渲染结构;通过损失函数迭代训练resnet
‑
50网络;(3)将步骤(2)得到的3d脸部信息及脸部渲染结构连接后,再经过卷积得到3d脸部结构先验;(4)用步骤(1)输入的低分辨率图像与真实值来训练下半分支网络,包括空间注意力机制网络和残差通道注意力机制网络;空间注意力机制网络的输入为低分辨率图像,输出的特征向量为残差通道注意力机制网络的输入;下半分支网络先用空间注意力机制结合3d脸部结构先验与特征向量,再使用残差通道注意力机制来在特征通道中挖掘最有用的信息;通过损失函数迭代训练下半分支网络;(5)将待恢复的低分辨率图像输入步骤(2)~(4)训练好的人脸超分辨模型中,得到对应的高分辨率图像。
6.进一步地,所述3d脸部信息包括身份、表情、纹理、亮度和脸部姿态特征。
7.进一步地,步骤(2)中,所述3d脸部信息参照morphable模型重建成脸部渲染结构。
8.进一步地,步骤(2)中的损失函数l
r
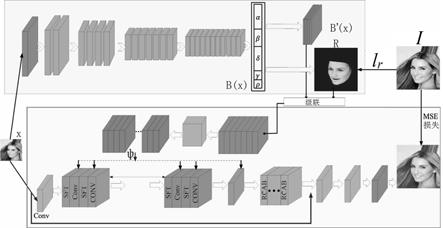
如下:
其中,l为输入低分辨率图像的数量,j为低分辨率图像的索引;m表示脸部区域,i为像素点索引;a是基于肤色的注意力掩膜,a
i
代表注意力掩膜中的像素点i;i为真实值,i
ji
代表第j个低分辨率图像中像素点i的真实值;x代表输入的低分辨率图像,b(x)代表将x对应的3d脸部信息,r代表脸部渲染结构,r
ji
(b(x))代表第j个低分辨率图像生成的脸部渲染结构的像素点i。
9.进一步地,注意力掩膜a通过训练一个贝叶斯分类器得到。
10.进一步地,步骤(4)中,3d脸部结构先验输入空间注意力机制网络的空域特征转换层,学习得到一对调制参数,用于在空间上对空间注意力机制网络中的中间特征进行精细变换。
11.进一步地,调制参数用于在空间上对空域特征转换层前一层的输出f进行如下精细变换:其中,sft为空域特征转换层对应的函数,代表逐元素相乘。
12.进一步地,步骤(4)中的损失函数为均方差损失。
13.进一步地,步骤(3)具体为:将3d脸部信息通过特征转换生成与输入低分辨率图像一样大小的矩阵,并与脸部渲染结构级联连接后,再经过多个卷积层得到3d脸部结构先验。
14.本发明的有益效果是:本发明相比于未结合先验或只结合2d先验的算法来说,本发明可以有效地提高人脸超分辨效果,得到更加清晰,现实的图片,并且可以避免常见的面部扭曲(face artifacts/distortion)的问题。
附图说明
15.图1为人脸超分辨总体架构示意图;图2为脸部渲染结构结果示意图;其中,(a)列为低分辨率图像,(b)列为脸部渲染结构,(c)列为高分辨率图像;图3为空域特征转换层结构示意图;图4为残差通道注意力模块结构示意图;图5为输入低分辨率图像为(16
×
16),
×
8倍的不同算法超分辨结果示例图;其中,(a)对应celeba数据集,(b)对应menpo数据集;图6为输入低分辨率图像为(32
×
32),
×
4倍的不同算法超分辨结果示例图;其中,(a)对应celeba数据集,(b)对应menpo数据集。
具体实施方式
16.本发明针对现有超分辨算法在未运用面部先验或运用2d面部先验的情况下,人脸超分辨效果不好的问题,提出一种结合3d脸部结构先验的人脸超分辨方法。
17.本发明人脸超分辨模型为一个深度学习网络,利用高分辨图像作为真实值,对应的低分辨率图像作为输入,当低分辨率图像输入进人脸超分辨模型后,上半分支从图像中抓取3d脸部信息作为先验,下半部分利用输入的低分辨率图像及3d脸部结构先验预测对应的高分辨率图像,每一步迭代计算预测图像(恢复的高分辨图像)和真实值之间的差距,训练网络往减小差距的方向收敛。具体地,人脸超分辨模型总体包括两个分支。上半部分分支包含一个resnet
‑
50网络来从输入的低分辨率图像中挖掘隐藏的3d脸部信息,将3d脸部信息分别通过特征转换生成3d脸部特征,通过3d人脸重建生成一个脸部渲染结构(face rendered structure);所述3d脸部信息包括身份、表情、纹理、亮度和脸部姿态。下半部分分支利用空域特征转换层(spatial feature transform(sft))结合3d脸部特征及脸部渲染结构作为3d脸部结构先验,再利用空间注意力机制及残差通道注意力机制实现人脸超分辨,输出恢复的高分辨率图像。
18.下面结合实施例来说明本发明的有效性。
19.实验数据采用celeba数据集(liu, z., luo, p., wang, x., tang, x.: deep learning face attributes in the wild. in:iccv (2015))和menpo数据集(zafeiriou, s., trigeorgis, g., chrysos, g., deng, j., shen, j.: the menpo facial landmark localisation challenge: a step towards the solution. in: cvprw (2017)),训练数据集为162080张来自celeba的图像,测试数据集为40519张来自celeba的图像及3000张来自menpo的脸部姿态变化较大(large
‑
pose
‑
variation)的图像。
20.如图1所示,本实施例步骤如下:(1)首先进行数据预处理。对于给定的人脸图片集的高分辨率图像,本实施例使用双三次下采样(bicubic downsampling)生成低分辨率图像x作为网络输入,利用中心裁剪(center
‑
cropping)处理原高分辨率图像,裁剪成大小128
×
128,作为真实值i。如图2所示,图2中的(a)列为低分辨率图像,(c)列为对应的高分辨率图像。
21.(2)用步骤(1)得到的低分辨率图像与高分辨率图像来训练上半分支的resnet
‑
50网络。resnet
‑
50网络输出的是从输入的低分辨率图像中学习来的具有代表性的3d脸部信息。
22.将3d脸部信息参照morphable模型(blanz, v., vetter, t.: a morphable model for the synthesis of 3d faces. in acm siggraph (1999))3d人脸重建生成一个脸部渲染结构r。在上半分支网络训练中运用如下损失函数l
r
,计算脸部渲染结构r
ji
(b(x))与步骤(1)得到的真实值i(128
×
128高分辨率图像)之间的差距:其中,l代表了训练图像总数,j代表了训练图像的索引;m表示脸部区域,i表示区域内的像素点索引;a是通过训练一个贝叶斯分类器得到的基于肤色的注意力掩膜,a
i
代表像素点i的注意力掩膜;真实值i代表高分辨率图像,i
ji
代表第j个训练图像中像素点i的真实值;x代表输入的低分辨率图像,b(x)代表将x输入resnet
‑
50网络后的3d脸部信息,r代表生成的脸部渲染结构,r
ji
(b(x))代表第j个训练图像生成的脸部渲染结构的像素点i。
23.通过网络训练迭代不断减小损失函数l
r
的值,认为训练的resnet
‑
50网络收敛后,可以有效提取3d脸部信息b(x)。如图2所示,图2中的(b)列是对应得到的脸部渲染结构,可以看出即使是脸部有不同的姿态(如左右脸)或是部分被遮挡,本发明都可以提供清晰的脸部渲染结构。
24.(3)将步骤(2)得到的3d脸部信息b(x)通过特征转换,生成与输入低分辨率图像一样大小的矩阵b’(x);并与脸部渲染结构级联连接后再经过多个卷积层得到3d脸部结构先验ψ,输入下半分支结构。
25.(4)下半分支结构先用空间注意力机制结合步骤(3)中的3d脸部结构先验ψ与空间注意力机制网络产生的特征向量;再使用残差通道注意力机制来在特征通道中挖掘最有用的信息。
26.(4.1)在空间注意力机制网络中,利用空域特征转换层sft(wang, x., yu, k., dong, c., loy, c.: recovering realistic texture in image superresolution by deep spatial feature transform. in: cvpr (2018))结合步骤(3)中的3d脸部结构先验ψ指导空间注意力机制网络学习空间上的特征。
27.如图3所示,空域特征转换层sft根据输入的3d脸部结构先验ψ学习得到一对调制参数;这对调制参数用于在空间上对每层深度网络的中间特征f进行如下精细变换:其中,f代表空域特征转换层sft的输入,代表逐元素相乘。
28.将学习到的3d脸部结构先验ψ,应用于空间注意力机制神经网络通过级联的sft与卷积层,从输入低分辨率图像中学习到的特征向量f0。
29.(4.2)残差通道注意力机制由一系列如图4所示的残差通道注意力模块(rcab)组成,其中第b个rcab模块的输出f
b
为:f
b
=f
b
‑1+c
b
(x
b
)
·
x
b
其中,f
b
‑1是第b个rcab模块的输入,也是第b
‑
1个rcab模块的输出;其中,第一个rcab模块的输入f0是步骤(4.1)中空间注意力机制网络产生的特征图;x
b
是由经过两个连接的卷积层得到的,c
b
是通道注意力函数,检测不同通道中特征图对结果的重要性,c
b
(x
b
)
·
x
b
表示根据计算出的重要性给予不同通道不同的权重。
30.(5)将步骤(3)中的3d脸部结构先验ψ输入步骤(4)构建的下半分支的网络,根据真实值i,采用均方差损失(mse)作为损失函数,进行训练。运用空间注意力机制及残差通道注意力机制让下半分支神经网络从输入低分辨率图像信息最丰富的部分学习特征。至此构建了结合3d脸部结构先验的人脸超分辨模型。
31.(6)将待恢复的低分辨率图像输入步骤(5)训练好的人脸超分辨模型中,即可得到恢复的高分辨率图像。
32.本发明的评价指标采用峰值信噪比(psnr)和结构相似性(ssim)。按照本发明方法分别对celeba数据集和menpo数据集进行
×
4倍、
×
8倍的人脸超分辨,并对超分辨结果计算psnr和ssim。表1、表2分别给出了本发明与其它人脸超分辨算法的在celeba数据集和menpo数据集上的比较结果;本发明的指标值均大于其它算法。
33.表1:与其它先进人脸超分辨算法在celeba数据集上的比较结果表2:与其它先进人脸超分辨算法在menpo数据集上的比较结果图5表示在celeba和menpo数据集上输入低分辨率图像为(16
×
16),
×
8倍时,本发明与其它人脸超分辨算法的比较图;图6表示在celeba和menpo数据集上输入低分辨率图像为(32
×
32),
×
4倍时,本发明与其它人脸超分辨算法的比较图;可以看出本发明的恢复的图像与真值最接近。
34.综上,无论在celeba数据集还是在脸部姿态变化较大的menpo数据集上,本发明皆
优于其它人脸超分辨算法。由此可以证明本发明提出的方法的有效性,能够利用面部区域中存在的规律性,从而得到更好的效果。
35.以上所述仅为本发明的实施例,并非因此限制本发明涉及范围,凡是利用本发明说明书及附图内容所作的等效结构或等效流程变换,或直接或间接运用在其它相关的技术领域,均同理包括在本发明请求保护范围内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1