一种知识迁移方法、无线网络设备个体识别方法及系统
本发明涉及无线网络个体识别技术领域,具体涉及一种知识迁移方法、无线网络设备个体识别方法及系统。
背景技术:
由于电磁环境复杂和电磁对抗非合作、以及接收设备局限等原因,侦查设备只能接收到少量的样本数据,难以支撑需要大量样本数据训练的分类器。如果只针对小样本数据进行训练,那么得到的模型的泛化能力就会变差,致使个体识别的精度显著降低。
tradaboost算法利用辅助训练数据帮助训练目标领域分类器,是一种基于实例的迁移学习算法,被广泛应用,解决了归纳式迁移学习存在的问题。算法关键在于数据权重的调整策略,基本思想是在每一次重复迭代中,降低被误分类的辅助训练数据的权重。那么相对而言,正确分类的训练数据就拥有了更高的权重,通过不断的迭代循环训练,调整误分类样本权重,逐渐降低了差的训练样本对分类器的影响,增大了有益训练样本数据对分类器训练的提高。但是tradaboost算法将初始权重平均分配给所有样本,同等对待每一个训练样本;但是与整体样本数据相关性越大的样本数据,其重要性可能越大,则各个样本数据重要性均不相同,平均分配权重显然不合理。并且还存在源域权重下降过快、容易过拟合、易发生负迁移等问题。
技术实现要素:
本发明针对现有技术存在的问题,提供一种提高无线网络设备个体识别精度的知识迁移方法、无线网络设备个体识别方法及系统。
本发明采用的技术方案是:
一种无线帧数据归纳式知识迁移方法,包括以下步骤:
步骤1:获取目标域数据和源域数据作为训练数据;
步骤2:采用改进的tradaboost算法实现知识迁移;
其中改进的tradaboost算法中,以adaboost算法为基础,采用vfkmm算法确定源域和目标域的初始权重分布。
进一步的,所述改进的tradaboost算法中,以adaboost算法为基础,引入更新因子ct=2(1-εt)到源域权重更新,得到目标域权重更新;式中εt为目标误差率。
进一步的,所述更新因子确定过程如下:
假设p为第t+1步迭代正确分类目标权重的总和,q是第t+1步迭代错误分类目标权重的总和;设m为迭代次数,j=1:ntarget为目标数量,如下:
其中,
算法源域权重更新为:
由于
更新因子为:
将更新因子加入源域权重更新,可以得到目标域样本的权重更新
一种无线帧数据归纳式知识迁移方法的无线网络设备个体识别方法,包括以下步骤:
采用改进的tradaboost算法实现知识迁移,得到对应的分类器函数;
利用分类器函数对待识别的无线网络设备进行个体识别;无线网络设备实例包括文本、图像中的一种或两种。
进一步的,包括以下步骤:
步骤1:构建个体识别网络,初始化网络参数;
步骤2:采用权利要求4中的无线帧数据归纳式知识迁移方法得到的目标域数据集引入该网络,对网络进行训练;
步骤3:采用步骤2训练得到的网络,进行无线网络设备个体识别。
进一步的,所述个体识别网络为卷积神经网络、循环神经网络、深度信念网络、生成对抗网络、深度强化网络中的一种。
一种无线网络设备个体识别方法的个体识别系统,包括:
网络构造模块:构建个体识别网络,并初始化网络参数;
训练模块:将采用权利要求4中的无线帧数据归纳式知识迁移方法得到的目标域数据集引入该网络,对网络进行训练;
个体识别模块:对无线网络设备进行个体识别。
本发明的有益效果是:
(1)本发明采用vfkmm算法确定源域和目标域的初始权重,修正了域的分布;结合tradaboost算法结合后,可以充分结合两者的优点;减少了tradaboost迭代的次数,实现了模型性能的提升,降低出现过拟合的概率;
(2)本发明引入更新因子加入源域权重更新,可以防止权重转移;迭代稳定时可以实现更高的识别精度;
(3)本发明建立了基于小样本无线帧数据的归纳式知识迁移方法,提高了无线网络设备个体识别精度。
附图说明
图1为现有kmm算法模拟实验结果。
图2为实施例中经过vfkmm算法前后初始权重变化情况,a为经过vfkmm算法前,b为经过vfkmm算法后。
图3为实施例中引入更新因子前后权重更新变化示意图。
图4为实施例中不同组样本识别结果图。a为4组样本识别效果对比图,b为6样本识别效果对比图,c为8组样本识别效果对比图,d为10组样本识别效果对比图。
具体实施方式
下面结合附图和具体实施例对本发明做进一步说明。
一种无线帧数据归纳式知识迁移方法,包括以下步骤:
步骤1:获取目标域数据和源域数据作为训练数据;
步骤2:采用改进的tradaboost算法实现知识迁移;
其中改进的tradaboost算法中,以adaboost算法为基础,采用vfkmm算法确定源域和目标域的初始权重分布。改进的tradaboost算法中,以adaboost算法为基础,引入更新因子ct=2(1-εt)到源域权重更新,得到目标域权重更新;式中εt为目标误差率。
更新因子确定过程如下:
假设p为第t+1步迭代正确分类目标权重的总和,q是第t+1步迭代错误分类目标权重的总和;设m为迭代次数,j=1:ntarget目标数量,如下:
其中,
算法源域权重更新为:
由于
更新因子为:
将更新因子加入源域权重更新,可以得到目标域样本的权重更新
目标域测试集最后的测试误差为:
其中:
令目标域中测试错误的样本集合为t,则最终测试误差为
每次迭代得到的测试误差为:
其中:
当
当
于是
又有
其中:
因为
合并上述两式,可得:
则:
化简后,得:
可得:
所以,加入更新因子后,迭代过程可以正常进行。
一种无线帧数据归纳式知识迁移方法的无线网络设备个体识别方法,包括以下步骤:
采用改进的tradaboost算法实现知识迁移,得到对应的分类器函数;
利用分类器函数对待识别的无线网络设备进行个体识别;无线网络设备实例包括文本、图像中的一种或两种。
一种无线网络设备个体识别方法,包括以下步骤:
步骤1:构建个体识别网络,初始化网络参数;
步骤2:采用权利要求4中的无线帧数据归纳式知识迁移方法得到的目标域数据集引入该网络,对网络进行训练;
步骤3:采用步骤2训练得到的网络,进行无线网络设备个体识别。
个体识别网络为卷积神经网络、循环神经网络、深度信念网络、生成对抗网络、深度强化网络中的一种。
一种无线网络设备个体识别方法的个体识别系统,包括:
网络构造模块:构建个体识别网络,并初始化网络参数;
训练模块:将采用权利要求4中的无线帧数据归纳式知识迁移方法得到的目标域数据集引入该网络,对网络进行训练;
个体识别模块:对无线网络设备进行个体识别。
具体的改进的tradaboost算法过程如下:
输入为xsource,xtarget
输出为分类器hf(x)
步骤1:根据vfkmm算法得到源域和目标域的初始权重分布w。
步骤2:调用弱分类器,将xsource和xtarget的数据整体作为训练数据,过程如adaboost算法。
步骤3:计算误差率:
步骤4:设置更新权重βt=εt/(1-εt),
步骤5:设置更新因子2(1-εt),调整权重更新速率。
步骤6:更新源域与目标域的权重
步骤7:输出最终分类器:
通过以下内容说明本发明中基于vfkmm的源域优化
通常,源域和目标域的数据分布是不相同的,这时候需要使用一种策略来使得它们的域分布能够近似,通常是对样本或者特征进行加权。假设源域和目标域的输入空间用x表示,输出空间用y表示。显然源域和目标域的数据分布是不同的,即psource(x)≠ptarget(x),但是源域和目标域的条件分布是一致或者近似的,即psource(y|x)≠ptarget(y|x)。我们称这种现象为convariateshift。这时我们可以使用估计密度的比率β(x)=ptarget(x)/psource(x)的方法,给源域中的样本进行加权,从而修正样本的分布。但是这牵扯到很复杂的数学运算,实际中密度估计的操作是不可行的,通常采用kmm算法解决这个问题。
kmm不进行样本密度的估计,直接求得β(x)=ptarget(x)/psource(x)。kmm算法将源域和目标域的样本映射到一个高维的希尔伯特空间(rkhs)中,然后进行协方差的分布匹配,从而起到了修正样本分布的作用。该算法的核心思想就是在再生的希尔伯特空间中最小化加权的源域数据分布和β(x)psource(x)和ptarget(x)的mmd距离(度量距离),两个随机变量的mmd距离可以定义如下:
最小化mmd从而得到的最优权重等价于求解最小化一个二次规划的问题,该二次规划可以定义如下:
其中k和k为希尔伯特空间中得到的矩阵,nsource和nstarget表示源域和目标域中的样本数目。
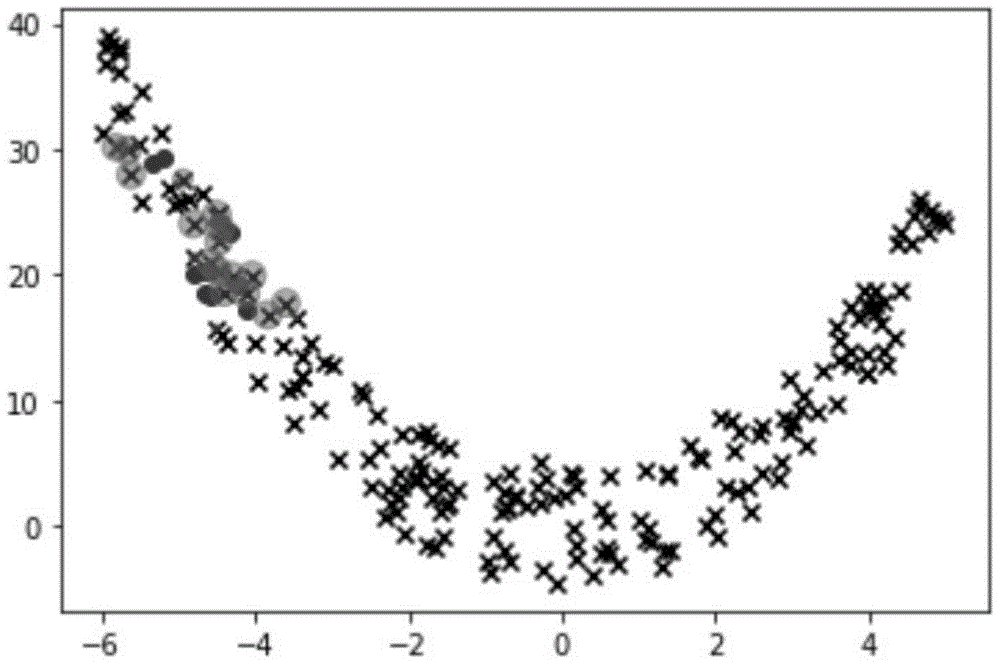
图1为kmm算法模拟实验结果,其中黑色“+”的点代表了随机生成的源域样本分布,黑色“圆点”代表了目标域的样本分布,黑色“圆点”和“+”的点代表了经过kmm算法优化得到的权重大的源域中的样本。
根据计算,kmm算法的时间复杂度为
因此采用veryfastkmm(vfkmm)算法在源域的样本中随机挑选固定容量大小的自助采样样本,然后在这些样本上使用kmm算法,每个样本进行有放回的采样,最终该样本的权重为多次采样后得到的权重的平均值。进而获得到源域样本初始的权重,更进一步可以定义目标域样本的权重,具体可以定义如下:
其中,ds为,test为。
在进行一次迭代后就可以得到了源域和目标域的初始权重,起到了修正域的分布的作用。通过与tradaboost算法结合,就可以充分结合两者的优点,进行源域和目标域样本权重的更新,在后续的迭代过程中,将减少tradaboost迭代的次数,实现模型性能的提升,降低出现过拟合的概率。
实施例
以4台相同型号无线路由器为实验对象,分别采集200组数据,共800组数据,源域数据设置为400组,目标域训练集数据分别设置为4组、6组、8组、10组,测试集数据设置为200组。然后分别在预设的数据集上进行基于暂态特征的个体识别实验(迁移学习前)、tradaboost算法实验、改进的tradaboost算法实验,结果如图2所示。
图2a为tradaboost算法的初始权重设置,图2b为经过vfkmm算法后的初始权重设置,可以看到,部分源域中的数据点经过vfkmm算法流程后权重大小有了较好的优化。图中的点为源域和目标域的数据映射在二维图像上的投影,黑色的点为源域的数据,灰色的点为目标域的数据,圆圈中的点为随机选取的数据点。
图3为源域中随机选取的某样本在引入更新因子前后,权重值的变化情况。从图中可以看出,在加入更新因子优化前,源域数据的权重下降是非常剧烈的,在进行了5次迭代之后,已经趋向为0,这样是不利于模型的训练的;在加入更新因子优化之后,权重的更新平滑了很多。
图4为采用本发明方法和现有的tradaboost算法的实验结果对比图,其中圆圈曲线为现有的tradaboost算法实验结果,星号曲线为本发明改进的tradaboost算法实验结果。黑色的虚线为基于暂态特征的个体识别实验(迁移学习前)的结果。
其中迭代次数m为20次,选用的分类器为带权重的kmm分类器(k=3);图4a为4组样本识别效果对比图,图4b为6组样本识别效果对比图,图4c为8组样本识别效果对比图,图4d为10组样本识别效果对比图。
从实验结果可以看出,改进的tradaboost相比于tradaboost算法可以降低迭代的次数,在迭代稳定时可以实现更高的识别精度,相比于迁移学习前提升效果显著。由此可见,本章所提出的改进的迁移学习算法在面对“小样本”情形下的无线网络设备个体识别时是有效的。
本发明基于vffkmm(核均值匹配)的源域优化和基于更新因子的权重更新优化改进tradaboost算法,基于无线网络设备个体暂态特征数据样本,实现小样本数据知识迁移。解决了现有无线网络设备个体识别技术中,面临小样本数据时个体识别精度低的问题。将与小样本数据相似的大量已知数据中提取相关知识,将这些知识迁移到目标数据中,解决目标任务。提高了现有分类模型的泛化能力,实现了“小样本”下无线网络设备个体识别精度的提升。
- 还没有人留言评论。精彩留言会获得点赞!