一种多特征融合的文本情感分析模型及装置
本发明涉及智能智能文本情感分析技术领域,具体为一种多特征融合的文本情感分析模型及装置。
背景技术:
将深度学习应用于文本情感分析任务的过程中,首先需要对文本进行词向量化,然后输入到神经网络中提取情感特征。但由于微博文本内容丰富、形式多样的特点,仅仅由文本词向量构成的语义特征不能全面表达微博文本的情感信息,所以本发明提出一种基于多特征融合的文本情感分析方法。针对微博文本自身特点构建了多种特征,如基于词典的情感值特征、表情特征以及改进的语义特征。融合多特征形成文本情感分类模型,该模型可以从多特征向量矩阵中学习到文本更多维度的情感信息,在自建数据集上与传统cnn模型及其他单一特征模型进行对比,实验结果显示其情感分类能力得到有效提升。
随着社交媒体的迅速发展,微博成为热门网络社交平台之一,越来越多的用户在微博上发表评论去表达自己的观点态度,微博短文本也成为新兴的文本形式。挖掘微博文本背后隐藏的情感倾向,对舆情分析等有重要价值。相比于传统文本,微博文本具有内容较短、表情符号多、形式多样化等特点,因此,仅在文本词向量上提取语义特征不足以涵盖微博文本所有的情感信息,这类方法没有考虑到文本中丰富的表情符号,以及不同词语对文本的重要程度不同。
以表情符号为例,微博上表情符号越来越受欢迎,很多用户在发表评论时,会在文字中加入符合情绪的表情符号,相关研究表明,表情符号可以增强用户的情感表达。微博作为日常网络交流的平台,提供了许多默认的表情符号,便于用户更生动直观的表达自己的感受。可见,表情符号在微博文本情感分析中意义重大。然而现有方法大多只关注了文本的研究,忽略了表情符号等数据,这可能导致情感表达的缺失,从而影响后续情感倾向性判断。
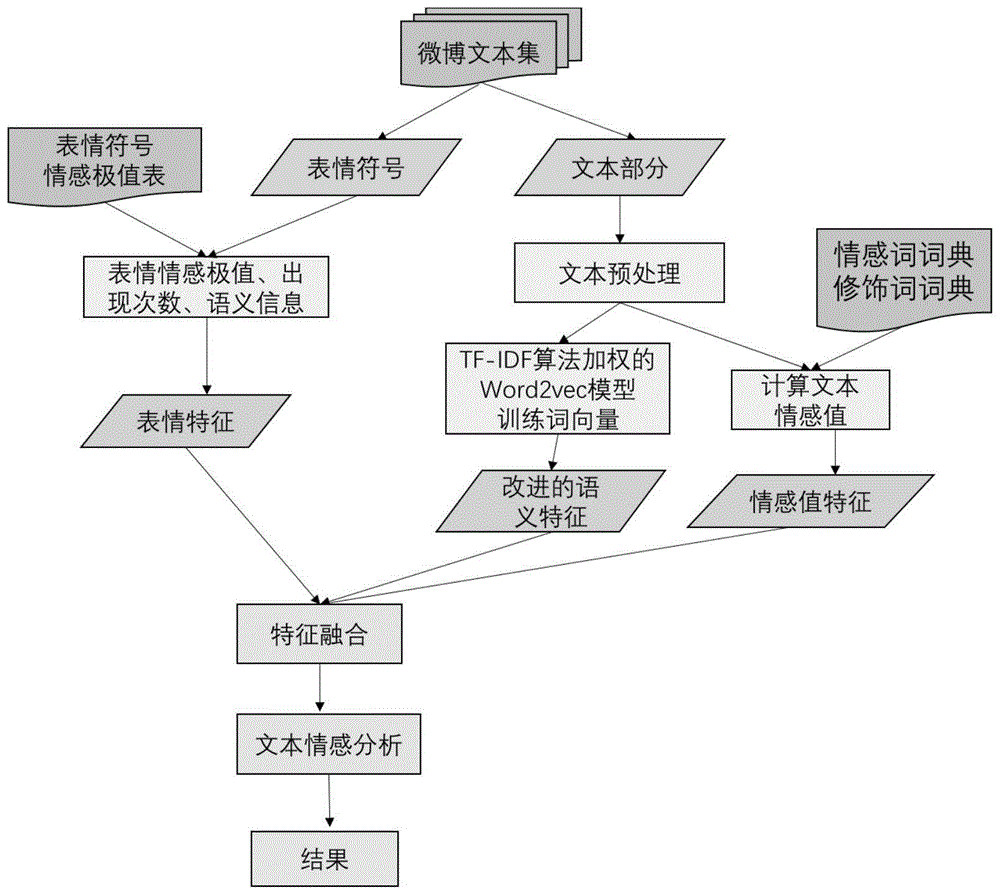
为了解决上述问题以及挖掘微博文本中更全面的情感信息,本发明提出一种基于多特征融合的文本情感分析方法,在文本词向量的语义特征基础上,增加了三种情感特征:基于词典的情感值特征、表情特征、改进的语义特征。根据情感词典计算整条文本的情感值作为基于词典的情感值特征。因为表情符号可以更直观的体现情感,提取出文本中表情符号的相关信息作为单独的表情特征。提出tf-idf算法加权的word2vec模型,称为改进的word2vec模型,用于文本向量化,作为改进的语义特征。将多种特征融合形成多特征向量矩阵,从更多角度学习文本中包含的情感特征。
技术实现要素:
本部分的目的在于概述本发明的实施方式的一些方面以及简要介绍一些较佳实施方式。在本部分以及本申请的说明书摘要和发明名称中可能会做些简化或省略以避免使本部分、说明书摘要和发明名称的目的模糊,而这种简化或省略不能用于限制本发明的范围。
鉴于现有文本情感分析模型中存在的问题,提出了本发明。
因此,本发明的目的是提供一种多特征融合的文本情感分析模型及装置,能够实现在使用的过程中,结合文本卷积神经网络与双向长短期记忆神经网络,并引入自注意力机制来增加文本中重要词语所占权重,提高了文本情感分析的准确率。
为解决上述技术问题,根据本发明的一个方面,本发明提供了如下技术方案:
一种多特征融合的文本情感分析模型及装置,其包括登录模块、单输入预测模块和批量预测模块
其中
登录模块,用户需要登录系统;
单输入预测模块,该模块可以预测一条文本的情感极性,由用户手动输入预测内容,如“今天天气不错”,点击提交则显示预测标签结果,预测标签共分为三种:积极、消极和中性;
批量预测模块,该模块可以对批量文本进行预测,先由数据上传模块上传待分析的文本集,遍历其中每条文本进行预测,结果可以以柱状图显示数据占比,统计三种情感文本各有多少条,并提供下载功能。
作为本发明所述的一种多特征融合的文本情感分析模型及装置的一种优选方案,其中:建立textcnn深度学习模型,在cnn基础上做出调整,使得textcnn模型更适用于提取文本的特征,在情感分析中常被使用,本发明将它作为核心模型,提出了基于多特征融合的情感分类模型mfcnn,将不同特征转化为对应向量,采用拼接方式进行特征融合,构建多特征向量矩阵,输入到文本卷积神经网络中,最终得到分类结果
(1)基于词典的情感值特征
1.1构建词典
本文构建的词典包括:基础情感词典,否定词词典和程度副词词典,采用了波森自然语言处理公司推出的bosonnlp情感词典作为基础情感词典,该词典由大量社交网站标注的文本构建,相较于传统的情感词典,bosonnlp情感词典包含了许多流行网络用语,更适用于对微博这种社交媒体的非正式文本进行情感分析;
本文的修饰词词典包括两种,分别是否定词词典和程度副词词典,若情感词前出现否定词,那么其情感倾向很可能相反,本文以汉语词典中的否定词为基础,结合微博文本中常用否定词进一步扩展,整理得到71个否定词构成否定词词典,否定词权重设为-1;程度副词词典参考知网提供的词典以及微博文本中部分程度副词作为补充,共筛选出219个程度副词组成的程度副词词典,并为每个程度副词赋予了权值,权值大于1表示情感加强,权值小于1表示情感弱化;
1.2构建情感值特征
基于词典的情感值特征是指依据情感词典及修饰词词典,构建特定的规则,匹配文本中包含的情感词和修饰词后进行加权计算,得到情感值特征作为文本情感的表示形式;
输入微博文本,输出文本基于词典的情感值特征,首先,读取微博文本并进行预处理,匹配情感词典与文本中的词语,若词语为积极词得1分,为消极词得-1分,两种情况都不是为0分,情感词前如果有修饰词,记录其数量及权值,计算文本的情感值,公式如下:
其中,m为文本中包含的情感词总数,n为某个情感词的修饰词个数,base为基础得分,weight为的程度副词或否定词权值;
(2)表情特征
情感词与表情符号都是常见的含有情感线索的载体,虽然情感词也具有情感信息,但仅仅通过制定规则来计算几个词语的情感得分是远远不够的,与情感词相比,表情符号使用图形表示,具有更丰富且直观的情感信息,同时它所表达的情感往往更强烈,当表情符号出现在文本中时,其更可能主导文本信息的情感,本文基于表情符号的多维信息构建表情特征,包括表情符号的情感极值、出现次数及语义信息;
首先是表情符号的情感极值,本文根据自建数据集中常用的微博表情符号,选择了85个表情构建了表情符号情感极值表;将表情分为积极、中性、消极3种类型,其中,积极情感表情符号37个,消极情感表情符号43个,对于有歧义或者没有明显情绪表达的表情符号,如“[微笑]”,设为中立情感,共5个,不同表情符号表达的情感不同,按照表达情感的正负及强弱给与-2到2的分值,表达积极情感的表情由弱到强取值范围为0至2,表达消极情感的表情由弱到强取值范围为0至-2,表达中性情感的表情赋值0;
提取文本中的表情符号,计算文本情感极值公式如下:
其中m,n为文本中积极表情符号与消极表情符号的数量,e为表情符号,pos,neg为积极与消极表情符号极值表,函数f的作用是取出极值表中相应表情符号的分值。
其次是表情符号出现的次数,便于直观了解微博文本中表情出现次数和文本情感极倾向性的联系,引入累积分布函数cdf(cumulativedistributionfunction,cdf),定义公式如下:
f_x(x)=p(x≤x)
最后是表情符号的语义信息,在构建数据集时,表情符号转化为“[表情词]”形式,将表情词经过word2vec模型进行词向量化,将该词向量作为对于表情符号的语义信息,计入表情特征。
表情符号可以直接体现用户在微博文本中想表达的情感,所以将表情符号加入到情感分析的对象中,增加了可参考的依据,能够有效提高情感分类的准确率;
(3)改进的语义特征
将文本词向量作为文本的语义特征,因为其含有词语的语义信息,所以将其作为文本的语义特征,通过word2vec模型将文本转化为词向量,缓解了矩阵稀疏、维数过大等问题,保留了文本中词语的序列信息,不过遗漏了不同词语对文本重要性不同,而tf-idf算法恰好解决了这个问题,所以将tf-idf与word2vec结合,由该模型训练得到的文本词向量,称为文本改进的语义特征。它结合了两者优点,既保留了文本中词语的序列信息,又赋予了文本中不同词语不同的权值;
假设一条文本d_i,分词后词语个数为m,词向量维度为n,该条文本表示为:
d_i=<w_1,w_2,…,w_m>
通过word2vec模型生成词向量,文本中包含多个词语,每个词语都有其对应的词向量,将他们进行拼接,得到该条文本m×n维的向量矩阵g(d_i),再与其权值矩阵相乘就是改进后的word2vec得到的向量矩阵w_g(d_i),表示公式如下所示
g(d_i)={w2v(w_1),w2v(w_2),…,w2v(w_m)}
w_g(d_i)={"weight"(w_1)w2v(w_1),…,"weight"(w_m)w2v(w_m)}
其中,g(d_i)向量矩阵中每个向量w2v(w_i),就是文本中词语w_i的词向量,通过word2vec模型训练而得;w_g(d_i)向量矩阵中每个向量"weight"(w_i)w2v(w_i),其中,"weight"(w_i)是词语w_i由tf-tdf算法算出的权重值;将"weight"(w_i)与w2v(w_i)相乘就是改进后word2vec的词向量,将文本中各词语词向量组成的文本向量矩阵w_g(d_i),作为本发明改进后的语义特征;
步骤三:构建的kcnn-bilstm-att模型,该模型利用了textcnn提取文本的局部语义信息以及双向lstm从前后两个方向学习序列特征的优势,将两种神经网络结合,提取文本特征更为丰富,此外,该模型在textcnn卷积层中使用多规模卷积核替代单规模卷积核,提取多维度局部特征;在textcnn池化层选用k-maxpooling代替最大池化,因为最大池化对每条文本仅保留一个最强特征信息,而在自然语言处理中,特征的频次和位置同样重要,所以池化层选用k-maxpooling,在一定程度上保留了特征的频率和部分位置信息
(1)卷积层
在本文构建的模型中,卷积层的目的是利用卷积核获取文本的局部特征,词向量矩阵作为输入,卷积层进行卷积操作,获得整个文本的最终特征图(featuremap)作为下一层的输入;
(2)池化层
池化层的作用是保留显著特征以及降低特征维度,对卷积层输出的特征图进行池化操作,提取出某些局部最优特征,舍弃卷积层冗余的特征,对特征进行压缩从而降低了模型的复杂度以及后续计算量,避免产生过拟合;
(3)双向lstm层
该模型采用的bilstm是长短期记忆神经网络的变体之一,与lstm相比,bilstm不仅可以访问前向上下文信息,还可以访问后向上下文信息。
与现有技术相比,本发明的有益效果是:本发明在自建数据集上,较其他情感分类对比模型的准确率高出0.15%至3.32%,说明本发明提出的模型可以从融合了多特征的向量矩阵中学习到文本更多维度的情感信息,证明了该方法的可行性与有效性。此外,融合多特征的模型相比于cnn模型在精确率和f1值上分别有了近5%和4%的提升,在召回率上提升了2%。
附图说明
为了更清楚地说明本发明实施方式的技术方案,下面将结合附图和详细实施方式对本发明进行详细说明,显而易见地,下面描述中的附图仅仅是本发明的一些实施方式,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其它的附图。其中:
图1为本发明步骤流程结构示意图;
图2为本发明kcnn-bilstm-att模型结构示意图;
图3为本发明mfcnn模型整体架构结构示意图。
具体实施方式
为使本发明的上述目的、特征和优点能够更加明显易懂,下面结合附图对本发明的具体实施方式做详细的说明。
在下面的描述中阐述了很多具体细节以便于充分理解本发明,但是本发明还可以采用其他不同于在此描述的其它方式来实施,本领域技术人员可以在不违背本发明内涵的情况下做类似推广,因此本发明不受下面公开的具体实施方式的限制。
为使本发明的目的、技术方案和优点更加清楚,下面将结合附图对本发明的实施方式作进一步地详细描述。
实施例1
首先启动系统进行初始化,加载模型。接着进入循环等待,如果顺利到达则获取初始文本,利用jieba分词对初始文本进行预处理,将其划分为一个个词语,使分词后文本中所有词语有序整齐的排列,构建相应的语料词典,每个词语在词典中都有对应的序号,建立词语到序号的映射,将文本转化为一段序号数据。输入到embedding层得到相应情感词向量,再由模型进行预测,把结果封装成json格式,返回给客户端。若将服务关闭,系统停止运行,否则跳转至第二步,持续等待请求到达。
对于搭建完成的文本情感分析的接口服务,将基于html、css和javascript等技术实现该服务的可视化展示。javascript是比较流行的开发web页面的脚本语言,通过其实现发送请求和处理响应等。
情感分析系统功能模块
登录模块,用户需要登录系统
单输入预测模块,该模块可以预测一条文本的情感极性,由用户手动输入预测内容,如“今天天气不错”,点击提交则显示预测标签结果,预测标签共分为三种:积极、消极和中性。
批量预测模块,该模块可以对批量文本进行预测,先由数据上传模块上传待分析的文本集,遍历其中每条文本进行预测,结果可以以柱状图显示数据占比,统计三种情感文本各有多少条,并提供下载功能。
虽然在上文中已经参考实施方式对本发明进行了描述,然而在不脱离本发明的范围的情况下,可以对其进行各种改进并且可以用等效物替换其中的部件。尤其是,只要不存在结构冲突,本发明所披露的实施方式中的各项特征均可通过任意方式相互结合起来使用,在本说明书中未对这些组合的情况进行穷举性的描述仅仅是出于省略篇幅和节约资源的考虑。因此,本发明并不局限于文中公开的特定实施方式,而是包括落入权利要求的范围内的所有技术方案。
- 还没有人留言评论。精彩留言会获得点赞!