一种基于长短期兴趣与社会影响力的群体需求预测方法
1.本发明属于群体推荐技术领域,具体涉及一种基于长短期兴趣与 社会影响力的群体需求预测方法。
背景技术:
2.公共数字文化服务还存在不少瓶颈问题,诸如:资源采集交换缺 少统一的标准规范,数字资源“孤岛化”现象普遍存在,社会主体参 与资源建设单一,缺少个性化服务等,项目致力于从技术层面对上述 问题予以研究突破。本发明即基于长短期兴趣与社会影响力的群体需 求预测方法,围绕公共数字文化惠民服务中智能化对提升我国公共数 字文化服务水平,在梳理分析国内外相关机构和技术领域研究现状的 基础上,拟解决处于云端的公共文化资源在调度和分发时的效率问题 和公平问题,为实现我国公共文化资源智能共建共享与管理提供理论 基础和技术支撑。
3.与传统的群体需求预测技术不同,公共文化云资源中的群体需求 预测的最终目的是将云端资源按照用户需求预先调度到靠近群体用 户的位置,解决云资源使用的效率问题,因此,需要直接按照用户访 问时的ip地址进行群体划分,根据区域用户的历史访问记录和实时 访问情况预测群体需求。而且,在现有的大多数群体需求预测方法中, 主要考虑用户偏好问题,而较少考虑到影响群体决策的一些其他因 素,例如个体用户兴趣迁移问题和群体成员间社会影响力。在建立一 种实时性、高效率的群体需求预测机制时,将用户兴趣迁移与成员间 社会影响力纳入考量也是很有必要的。
技术实现要素:
4.为了克服上述现有技术的不足,本发明的目的是提供一种基于长 短期兴趣与社会影响力的群体需求预测方法,将用户的兴趣迁移与社 会影响力嵌入到群体需求预测中,提供一种基于长短期兴趣和社会影 响力的群体需求预测方法,用于实现根据用户历史访问行为分析用户 长短期兴趣偏好、对他人意见敏感程度以及与其他用户相互关系等信 息,进而对群体需求进行实时预测,以提高公共文化云平台资源访问 的效率。
5.为了实现上述目的,本发明采用的技术方案是:
6.一种基于长短期兴趣与社会影响力的群体需求预测方法,包括以 下步骤:
7.步骤1,群体划分:按照用户ip地址划分群体;
8.步骤2,用户访问数据处理:根据用户对资源的历史访问数据构 建用户在不同时刻的兴趣-评分关联表,挖掘用户需求随时间的变化 情况,具体包括:
9.1)对资源类别进行编号标码,构建资源类别标签词典,并根据 资源属性取值将资源归属到不同类别中,进而构建资源-类别表;
10.2)分别构建两个q行m列的矩阵,分别存放q个用户对m个资 源的访问时间和评分,即用户-资源访问时间表和用户-资源评分表; 扫描输入的样本数据集,提取用户对资源的访问时间以填充用户-资 源访问时间表,提取用户对资源评分以填充用户-资源评分表;
11.3)对于每一个用户,分别从资源-类别表、用户-资源访问时间 表、用户-资源评分表中筛选出与该用户相关的记录,构建该用户在 不同时刻的兴趣-评分关联表;其中,每个用户的兴趣-评分关联表中 的记录按照访问时间升序排序;
12.步骤3,建立基于lstm的个体项目评分预测模型:基于长短期 记忆神经网络(long short-term memory,lstm)模型,根据用户在 不同时刻的兴趣-评分关联表建立相应的个体项目评分预测模型,获 取用户对项目的初始评分矩阵,进而形成群体用户对项目的初始评分 矩阵,步骤如下:
13.1)逐行提取兴趣-评分关联表中的记录,将用户随时间发生变化 的部分作为lstm模型的输入,将用户评分作为模型的输出,去训练 每个用户基于lstm的网络模型;
14.2)lstm网络包括遗忘门f
t
、输入门i
t
、更新门c
t
和输出门o
t
四种门 结构,用以保持和更新细胞状态,其中t表示当前时刻,f、i、c、o 表示四种不同的门结构对应向量;
15.①
遗忘门层用以决定从细胞状态中丢弃的信息,它读取上一层的 输出h
t-1
和当前时刻的输入x
t
,输出一个数值f
t
,并赋值给当前细胞的 状态c
t-1
;其中f
t
计算方式为:
16.f
t
=σ(wf·
[h
t-1
,x
t
]+bf)
[0017]
其中h表示隐藏的状态结构,x
t
表示当前时刻lstm的输入向量, c表示细胞状态向量,f
t
表示遗忘门的激活向量,wf、uf和bf分别表示 的是遗忘门的输入权重、循环权重和偏置;
[0018]
②
输入门层用以筛选新旧信息并存放于细胞状态,它包含两个部 分:第一部分,通过sigmod函数决定需要输入的值;另一部分,通 过tanh函数创建一个新的候选值向量,该向量会被加入到状态c
t
中; 新的候选值向量计算为:
[0019]it
=σ(wi·
[h
t-1
,x
t
]+bi)
[0020][0021]
其中wi和bi、wc和bc分别表示的是输入门的输入权重和偏置以及 更新门的输入权重和偏置;
[0022]
③
更新门层更新旧细胞状态,将c
t-1
更新为c
t
,更新方式为:
[0023][0024]
其中,细胞状态用以存放模型中的关键信息,为lstm网络模型 能够得以存储用户的个性化信息的关键;
[0025]
④
输出门层基于细胞的状态输出数值:首先运行一个sigmoid层 来确定细胞状态将输出的部分o
t
;接着把细胞状态通过tanh进行处理 并把它和sigmoid门的输出相乘;最后输出确定要输出的部分h
t
,即 下一时间步的评分预测:
[0026]ot
=σ(wo·
[h
t-1
,x
t
]+bo)
[0027]ht
=o
t
*tanh(c
t
)
[0028]
其中wo和bo分别表示的是输出门的输入权重和偏置;
[0029]
由于四种门结构的存在,lstm能够智能“记忆”用户长短期访 问兴趣,以预测各用户在下一时刻对各个项目的评分;
[0030]
神经网络模型采用按时间展开的反向误差传播算法(bptt)进行 训练,依照预定义的损失函数迭代修正网络中的权重参数,以最小化 t时刻用户对某一项目的预测评分与
实际评分的误差;
[0031]
3)根据训练好的lstm网络模型,获取用户对项目的初始评分矩 阵;
[0032][0033]
步骤4,建立基于社会影响力的群体用户模型:通过社交网络上 的用户数据,获取用户对其他用户意见敏感程度以及群体成员之间相 互关系,从而构建基于社会影响力的群体用户模型,步骤如下:
[0034]
1)用户对其他用户意见的敏感程度主要是由于用户自身的个性 因素和专业性因素等所造成,通过收集用户在网络上的资源访问情况 与交互信息,分析用户专业性程度以及个性特点,如在与他人意见出 现分歧时属于独断型、协作型或者妥协型行为等;
[0035]
①
个性因素表示方法如下:
[0036]
personality
[0037]
=personality
1 personality
2 personality3…
personalityq]
t
[0038]
其中,personalityu取值在[0,1],用户个性越强,该用户个性值越 高,反之则越低,personalityu为0时代表该用户合作性很高,独断性很 低;personalityu为1时代表该用户独断性很高,而合作性很低;
[0039]
②
专业程度表示方法如下:
[0040]
expert(g)
[0041]
=[expert1(g) expert2(g) expert3(g)
…
expertq(g)]
t
[0042]
其中,expertj表示群体用户j的绝对专业性等 级程度,expertj(g)代表群体用户j在群体g中的专业性程度,群体g 中所有用户的相对专业性等级之和为1;
[0043]
③
通过对用户个性因素和在群组中的相对专业性因素设定不同 的权重因子,对用户这两种属性进行有效选择和控制,进而确定在其 对用户的敏感性程度因素的不同影响,群组g中用户u的敏感性程度 表示方法如下:
[0044][0045]
其中,α和β分别代表了用户u的个性因素personalityu和在群组g 中的相对专业程度因素expertu(g)在计算用户u的敏感性程度susceptibilityu时所占的权重;
[0046]
④
群体成员的敏感性程度表示为:
[0047]
susceptibility
[0048]
=[susceptibility
1 susceptibility2 susceptibility3…
susceptibilityq]
[0049]
2)通过收集用户在社交网络上的信息以及与他人的交互情况, 分析用户之间的相互关系;其中,度量指标包括用户认识时间长短、 用户间联系频率、用户密切程度、相互信任程度、用户间拥有的共同 朋友数量等;
[0050]
用户i和用户j之间相互关系,即亲密程度intimacy
(i,j)
表示方式如 下:
[0051][0052]
其中,li表示用户在k个相互关系量化指标上的评分值,max(li)表 示用户对评分量化指标的最高评分值,i=1,2,
…
,k;
[0053]
群体成员之间的相互关系可以表示如下:
[0054][0055]
3)群组g中q个用户的社会影响力sinfluence表示如下:
[0056]
sinfluence=(i-diag(susceptibility)intimacy)-1
(i
‑ꢀ
diag(susceptibility));
[0058]
步骤5,群体需求预测:利用群体用户对项目的初始评分矩阵, 通过基于社会影响力的群体用户模型,对不同群体的需求进行预测, 考虑社会影响力后的群体成员对项目的预测评分可以表示为:
[0059]
predictedr=sinfluence
·
r。
[0060]
进一步,所述的步骤1中根据用户访问资源时的ip地址将其划 分到具体的群体中,可以根据具体需求将群体划分省域级群体、市级 群体和机构群体三个级别。
[0061]
进一步,考察用户历史访问记录,在对项目进行分类与属性分析 的基础上,判断用户长短期兴趣偏好,形成用户对项目的初始评分矩 阵。
[0062]
进一步,考察用户个性特征、专业程度、与群体中其他成员相互 关系,分析用户的社会影响力,结合基于用户长短期兴趣所形成的当 前的用户对项目的初始评分矩阵,对群体需求进行预测。
[0063]
本发明的有益效果是:
[0064]
1.本发明在实现群体需求预测过程中构建的基于用户个体需求 预测模型对数据稀疏性、用户兴趣刻画不细致等问题提出了解决方 案。通过从资源-类别表、用户-资源访问时间表、用户-资源评分表 提取用户在不同时刻的兴趣-评分关联表,降低了数据稀疏性;通过 构建lstm个体需求预测模型,加入对用户长短期兴趣的考量,提高 个体用户需求预测准确率;
[0065]
2.本发明构建的基于长短期兴趣与用户影响力的群体需求预测 模型在考虑群体用户个体偏好的同时,考虑了群体成员之间的社会影 响因素,包括由于个体用户的专业性与本身个性等造成的在群体间表 现出来的敏感度和由于用户间密切程度、联系频率、用户间共同好友 数等所形成的用户间的相互关系,使得群体需求预测研究更贴合实际 情况,
并提高个体用户满意度与群体预测效果。
附图说明
[0066]
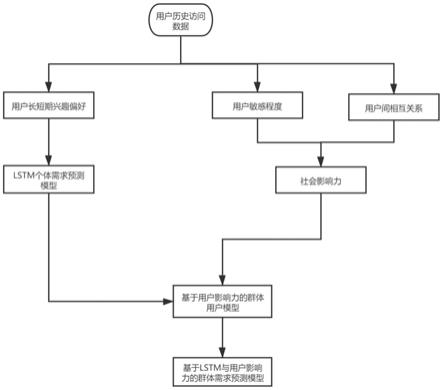
图1为本发明的流程示意图;
[0067]
图2为基于lstm的个体项目评分预测模型;
[0068]
图3为基于社会影响力的群体用户模型。
具体实施方式
[0069]
以下结合实施例及附图对本发明进一步叙述。
[0070]
如图1所示,一种基于长短期兴趣与社会影响力的群体需求预测 方法,包括以下步骤:
[0071]
步骤1,群体划分:按照用户ip地址划分群体;
[0072]
步骤2,用户访问数据处理:根据用户对资源的历史访问数据构 建用户在不同时刻的兴趣-评分关联表,挖掘用户需求随时间的变化 情况,具体包括:
[0073]
1)对资源类别进行编号标码,构建资源类别标签词典,并根据 资源属性取值将资源归属到不同类别中,进而构建资源-类别表;
[0074]
2)分别构建两个q行m列的矩阵,分别存放q个用户对m个资 源的访问时间和评分,即用户-资源访问时间表和用户-资源评分表; 扫描输入的样本数据集,提取用户对资源的访问时间以填充用户-资 源访问时间表,提取用户对资源评分以填充用户-资源评分表;
[0075]
3)对于每一个用户,分别从资源-类别表、用户-资源访问时间 表、用户-资源评分表中筛选出与该用户相关的记录,构建该用户在 不同时刻的兴趣-评分关联表;其中,每个用户的兴趣-评分关联表中 的记录按照访问时间升序排序;
[0076]
步骤3,建立基于lstm的个体项目评分预测模型:基于长短期 记忆神经网络(long short-term memory,lstm)模型,根据用户在 不同时刻的兴趣-评分关联表建立相应的个体项目评分预测模型,获 取用户对项目的初始评分矩阵,进而形成群体用户对项目的初始评分 矩阵,步骤如下:
[0077]
1)逐行提取兴趣-评分关联表中的记录,将用户随时间发生变化 的部分作为lstm模型的输入,将用户评分作为模型的输出,去训练 每个用户基于lstm的网络模型;
[0078]
2)如图2所示,lstm网络包括遗忘门f
t
、输入门i
t
、更新门c
t
和 输出门o
t
四种门结构,用以保持和更新细胞状态,其中t表示当前时 刻,f、i、c、o表示四种不同的门结构对应向量;
[0079]
①
遗忘门层用以决定从细胞状态中丢弃的信息,它读取上一层的 输出h
t-1
和当前时刻的输入x
t
,输出一个数值f
t
,并赋值给当前细胞的 状态c
t-1
;其中f
t
计算方式为:
[0080]ft
=σ(wf·
[h
t-1
,x
t
]+bf)
[0081]
其中h表示隐藏的状态结构,x
t
表示当前时刻lstm的输入向量, c表示细胞状态向量,f
t
表示遗忘门的激活向量,wf、uf和bf分别表示 的是遗忘门的输入权重、循环权重和偏置;
[0082]
②
输入门层用以筛选新旧信息并存放于细胞状态,它包含两个部 分:第一部分,通过sigmod函数决定需要输入的值;另一部分,通 过tanh函数创建一个新的候选值向量,
该向量会被加入到状态c
t
中; 新的候选值向量计算为:
[0083]it
=σ(wi·
[h
t-1
,x
t
]+bi)
[0084][0085]
其中wi和bi、wc和bc分别表示的是输入门的输入权重和偏置以及 更新门的输入权重和偏置;
[0086]
③
更新门层更新旧细胞状态,将c
t-1
更新为c
t
,更新方式为:
[0087][0088]
其中,细胞状态用以存放模型中的关键信息,为lstm网络模型 能够得以存储用户的个性化信息的关键;
[0089]
④
输出门层基于细胞的状态输出数值:首先运行一个sigmoid层 来确定细胞状态将输出的部分o
t
;接着把细胞状态通过tanh进行处理 并把它和sigmoid门的输出相乘;最后输出确定要输出的部分h
t
,即 下一时间步的评分预测:
[0090]ot
=σ(wo·
[h
t-1
,x
t
]+bo)
[0091]ht
=o
t
*tanh(c
t
)
[0092]
其中wo和bo分别表示的是输出门的输入权重和偏置;
[0093]
由于四种门结构的存在,lstm能够智能“记忆”用户长短期访 问兴趣,以预测各用户在下一时刻对各个项目的评分;
[0094]
神经网络模型采用按时间展开的反向误差传播算法(bptt)进行 训练,依照预定义的损失函数迭代修正网络中的权重参数,以最小化 t时刻用户对某一项目的预测评分与实际评分的误差;
[0095]
3)根据训练好的lstm网络模型,获取用户对项目的初始评分矩 阵;
[0096][0097]
步骤4,建立基于社会影响力的群体用户模型:如图3所示,通 过社交网络上的用户数据,获取用户对其他用户意见敏感程度以及群 体成员之间相互关系,从而构建基于社会影响力的群体用户模型,步 骤如下:
[0098]
1)用户对其他用户意见的敏感程度主要是由于用户自身的个性 因素和专业性因素等所造成,通过收集用户在网络上的资源访问情况 与交互信息,分析用户专业性程度以及个性特点,如在与他人意见出 现分歧时属于独断型、协作型或者妥协型行为等;
[0099]
①
个性因素表示方法如下:
[0100]
personality
[0101]
=[personality
1 personality
2 personality3…
personalityq]
t
[0102]
其中,personalityu取值在[0,1],用户个性越强,该用户个性值越 高,反之则越低,personalityu为0时代表该用户合作性很高,独断性很 低;personalityu为1时代表该用
户独断性很高,而合作性很低;
[0103]
②
专业程度表示方法如下:
[0104]
expert(g)
[0105]
=[expert1(g) expert2(g) expert3(g)
…
experta(g)]
t
[0106]
其中,expertj表示群体用户j的绝对专业性等 级程度,expertj(g)代表群体用户j在群体g中的专业性程度,群体g 中所有用户的相对专业性等级之和为1;
[0107]
③
通过对用户个性因素和在群组中的相对专业性因素设定不同 的权重因子,对用户这两种属性进行有效选择和控制,进而确定在其 对用户的敏感性程度因素的不同影响,群组g中用户u的敏感性程度 表示方法如下:
[0108][0109]
其中,α和β分别代表了用户u的个性因素personalityu和在群组g 中的相对专业程度因素expertu(g)在计算用户u的敏感性程度 susceptibilityu时所占的权重;
[0110]
④
群体成员的敏感性程度表示为:
[0111]
susceptibility
[0112]
=[susceptibility
1 susceptibility2 susceptibility3…
susceptibilityq]
[0113]
2)通过收集用户在社交网络上的信息以及与他人的交互情况, 分析用户之间的相互关系;其中,度量指标包括用户认识时间长短、 用户间联系频率、用户密切程度、相互信任程度、用户间拥有的共同 朋友数量等;
[0114]
用户i和用户j之间相互关系,即亲密程度intimacy
(i,j)
表示方式如 下:
[0115][0116]
其中,li表示用户在k个相互关系量化指标上的评分值,max(li)表 示用户对评分量化指标的最高评分值,i=1,2,
…
,k;
[0117]
群体成员之间的相互关系可以表示如下:
[0118][0119]
3)群组g中q个用户的社会影响力sinfluence表示如下:
[0120]
sinfluence=(i-diag(susceptibility)intimacy)-1
(i
‑ꢀ
diag(susceptibility));
[0122]
步骤5,群体需求预测:利用群体用户对项目的初始评分矩阵, 通过基于社会影响
力的群体用户模型,对不同群体的需求进行预测, 考虑社会影响力后的群体成员对项目的预测评分可以表示为:
[0123]
predictedr=sinfluence
·
r。
[0124]
进一步,所述的步骤1中根据用户访问资源时的ip地址将其划 分到具体的群体中,可以根据具体需求将群体划分省域级群体、市级 群体和机构群体三个级别。
[0125]
进一步,考察用户历史访问记录,在对项目进行分类与属性分析 的基础上,判断用户长短期兴趣偏好,形成用户对项目的初始评分矩 阵。
[0126]
进一步,考察用户个性特征、专业程度、与群体中其他成员相互 关系,分析用户的社会影响力,结合基于用户长短期兴趣所形成的当 前的用户对项目的初始评分矩阵,对群体需求进行预测。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1