一种联邦学习中基于局部模型梯度的用户筛选方法、系统、设备及存储介质
1.本发明涉及一种联邦学习中基于局部模型梯度的用户筛选方法、系统、设备及存储介质,属于分布式机器学习领域。
背景技术:
2.传统的机器学习方法要求将训练所用的数据集中在一台设备或一个数据中心,然而,由于对数据隐私的保护和无线通信资源的限制,将所有用于学习的数据传输到中心设备或数据中心对用户来说是不切实际的。这促使了分布式机器学习的出现,如图1所示,联邦学习是一种分布式机器学习算法,它可以使用户在本地收集数据,训练模型,只需要把局部模型参数传输给中央服务器,由中央服务器完成模型的整合,再广播给所有用户,训练过程一共进行t代,直至模型收敛。[s.a.rahman,h.tout,h.ould
‑
slimane,a.mourad,c.talhi and m.guizani,"a survey on federated learning:the journey from centralized to distributed on
‑
site learning and beyond,"in ieee internet of things journal,doi:10.1109/jiot.2020.3030072.]。
[0003]
然而,某些用户可能会由于特殊原因采集到受噪声或干扰的数据用来计算本地模型更新,或者受限与传输信道质量的影响,向服务器传输本地模型更新时也可能出现丢包或误码的现象;此外,由于服务器无法观测到用户数据,联邦学习很容易受到恶意攻击,如多个恶意用户将虚假训练样本注入自己的训练样本中用于本地模型的训练,这些虚假样本包括:训练数据被加入高斯噪声,训练标签被恶意修改等,这些具有噪声的局部模型更新参数和恶意攻击可能对联邦学习的过程产生严重影响。[d.cao,s.chang,z.lin,g.liu and d.sun,"understanding distributed poisoning attack in federated learning,"2019 ieee 25th international conference on parallel and distributed systems(icpads),tianjin,china,2019,pp.233
‑
239,doi:10.1109/icpads47876.2019.00042.]。
技术实现要素:
[0004]
针对现有技术的不足,本发明提供了一种联邦学习中基于局部模型梯度的用户筛选方法,该方法能够通过对用户传递到服务器的局部模型梯度进行用户数据质量测评,从而在训练过程中选择基于高质量数据计算的局部模型,用来进一步更新全局模型。当服务器接收到各个用户传输过来的局部模型梯度矩阵后,首先将各个用户的局部模型梯度矩阵按行或按列展开成一个向量,然后利用pca对展开的局部模型梯度的向量形式进行降维,接下来对所有降维的局部模型梯度利用dbscan聚类方法进行聚类,得到聚类结果中数量最多的一类,再求得此类中所有降维局部模型梯度的几何中心点,最后根据每个用户的降维局部模型梯度与上述几何中心点的距离选择用户,选择离中心点最近的部分用户的梯度用来更新全局模型。该筛选方法能够有效筛选基于高质量数据计算的局部模型梯度,提高联邦学习系统的鲁棒性。
[0005]
术语解释:
[0006]
1.联邦学习:令n个数据所有者为{f1,
…
,f
n
},他们都希望整合各自的数据{d1,
…
,d
n
}来训练出一个机器学习模型。传统的方法是把所有的数据放在一起并使用d=d1∪
…
∪d
n
来训练一个模型m
sum
。联邦学习系统是一个学习过程,数据所有者共同训练一个模型m
fed
(即全局模型),在此过程中,任何数据所有者f
i
都不会向其他人公开其数据d
i
,而是自己在本地利用自己的数据训练模型(即局部模型)并将局部模型梯度交给中央服务器来整合。
[0007]
联邦学习的流程:
[0008]
1)中央服务器初始化全局模型参数;
[0009]
2)中央服务器将模型参数广播给所有参与联邦学习的用户;
[0010]
3)用户将收到的模型作为自己新的模型(此时所有用户的模型都是全局模型);
[0011]
4)用户利用自己的数据集训练模型(局部模型),并计算局部模型梯度;
[0012]
5)用户将局部模型梯度上传到中央服务器;
[0013]
6)中央服务器将所有用户的局部模型梯度进行整合,计算新的全局模型;
[0014]
7)重复步骤2)到步骤6)(此为联邦学习过程中的一代),直至模型收敛。
[0015]
2.pca:principal component analysis的缩写,主成分分析法,是一种非监督机器学习方法,其主要思想是将n维特征映射到k(k<n)维上,新的k维特征是重新构造出来的正交特征,而不是简单地将原来的n维特征剔除n
‑
k维。pca主成分分析法的所用到的理论是最大方差理论,即映射得到的k维特征在每一维上的样本方差尽可能大。
[0016]
3.dbscan聚类方法:density—based spatial clustering of application with noise的缩写,是一种基于密度的聚类算法,这种算法假设样本类别可以通过样本分布的紧密程度来决定,同一类型的样本在空间上是比较紧密的,即他们之间的距离较短,也就是说,对于属于一个类别的样本,在这个样本的不远处很大可能有同一类别的样本。此聚类算法可以将样本密度高的区域检测出来。
[0017]
4.随机梯度下降法:是一种神经网络更新模型参数的方法,训练神经网络旨在最小化损失函数(反应网络模型性能的函数),而损失函数需要用样本点来计算梯度(模型参数更新的反方向),而一次性输入所有样本点会浪费大量资源和时间,因此采取随机选取部分样本点来计算梯度的方法。
[0018]
本发明的技术方案为:
[0019]
一种联邦学习中基于局部模型梯度的用户筛选方法,通过分析用户梯度的分布选择更准确的局部模型,联邦学习中包括服务器和n个用户,该用户筛选方法的具体步骤包括:
[0020]
(1)服务器初始化全局模型参数,并将全局模型参数广播给所有参与到联邦学习过程的n个用户;
[0021]
(2)用户接收到全局模型参数后,利用用户持有的数据集更新局部模型参数,然后将用户的局部模型梯度传输给服务器;
[0022]
(3)服务器将n个局部模型梯度均按行或按列展开成为向量形式,向量的维数与局部模型的参数中的元素个数相同;
[0023]
(4)为了方便依据展开的向量对用户数据进行测评,服务器利用pca算法对步骤(3)得到的展开的局部模型梯度的向量形式进行降维,从而减小展开的向量的长度;
[0024]
(5)服务器利用dbscan聚类方法对步骤(4)得到的n个降维局部模型梯度进行聚类,然后求聚类结果中数量最多的一类降维局部模型梯度的平均值,即降维局部模型梯度中心
[0025]
(6)计算每个用户的降维局部模型梯度到降维局部模型梯度中心的欧式距离;
[0026]
(7)根据步骤(6)计算得到的欧式距离,选取距离最近的m个用户;m为用户数量n的60%到80%;
[0027]
(8)利用选取的m个用户的局部模型梯度更新本代联邦学习训练过程的全局模型并将更新的全局模型广播给用户,全局模型满足:
[0028][0029]
式(i)中,表示第t
‑
1代联邦学习的全局模型,表示第t代联邦学习的全局模型;
[0030]
(9)重复执行步骤(2)
‑
步骤(8),直至模型收敛。
[0031]
根据本发明优选的,步骤(2)中,利用用户持有的数据集,使用随机梯度下降法得到用户的局部模型梯度。
[0032]
根据本发明优选的,步骤(4)中,服务器利用pca算法对步骤(3)得到的展开的局部模型梯度的向量形式进行降维,具体过程包括:
[0033]4‑
1、输入数据集x={x1,x2,x3…
x
n
},x
i
表示第i个用户的局部模型梯度对应的展开的向量,i=1,2,3,
…
n;
[0034]4‑
2、去中心化:计算数据集x的均值x
mean
,然后将x的每个元素减去x
mean
得到去中心化数据集x
new
;
[0035]4‑
3、求去中心化数据集x
new
的协方差矩阵c
ov
;
[0036]4‑
4、计算协方差矩阵c
ov
的特征值及特征值对应的特征向量;
[0037]4‑
5、选取从大到小的k个特征值对应的特征向量分别作为列向量组成特征向量矩阵w,k表示维度数;
[0038]4‑
6、计算x
new
w,即把去中心化数据集x
new
投影到所选取的特征向量上,得到的x
new
w即为降为k维特征的数据集。
[0039]
根据本发明优选的,步骤(4)中,利用pca算法将步骤(3)得到的展开的局部模型梯度的向量形式降维到二维或者三维,即k的取值为2或3。
[0040]
根据本发明优选的,步骤(5)中,dbscan聚类方法的具体的过程为:
[0041]
1)找到所有核心点,点为n个经过pca降维后的k维向量:
[0042]
当点的局部密度大于设定阈值时,则该点为核心点,然后进行步骤2);
[0043]
2)对于一个未处理的核心点,将未处理的核心点与其邻域内的点形成一个新的类c;
[0044]
3)将邻域内的点插入队列中;
[0045]
4)判断队列是否为空:
[0046]
当队列不为空,则从队列中任意删除一个点,然后进行步骤5);
[0047]
当队列为空,则进行步骤6);
[0048]
5)判断删除的点是否为核心点:
[0049]
当删除的点的局部密度大于设定阈值,则标记删除点为核心点,并将该删除点邻域内未分配的点分配给类c,并插入队列中;然后,重复步骤4)至步骤5),直至队列为空;
[0050]
当删除的点的局部密度小于设定阈值,则删除的点为边界点;然后,重复步骤4)至步骤5),直至队列为空;
[0051]
6)判断所有核心点是否均已处理完毕:
[0052]
当所有核心点判断完毕,则将所有未处理的点标记为噪声点,然后结束;如果点不属于核心点也不属于边界点,称点为噪声点;
[0053]
否则,重复步骤2)
‑
6),直至所有点处理完毕。
[0054]
应用dbscan算法时,需要估计数据集中特定点的密度,特定点的密度是通过计算该点在指定半径下数据点个数(包括特定点),这种计算得到的某个点的密度也被称为局部密度。计算数据集中每个点的密度时,我们需要把每个点归为以下三类:1.如果点的局部密度大于某个阈值,称这个点为核心点。2.如果点的局部密度小于某个阈值,但是它落在核心点的邻域内,称这个点为边界点。3.如果点不属于核心点也不属于边界点,称点为噪声点。除了标记数据集中每个点的类别,我们要做的是根据类别将每个样本进行聚类。对于同一个还未分配的核心点,我们将它邻域内的所有点归为一个新的类,如果邻域内有其他核心点的话,我们将重复上面相同情况的动作。
[0055]
一种联邦学习中基于局部模型梯度的用户筛选系统,包括向量展开模块、降维模块、聚类模块;
[0056]
向量展开模块用于将局部模型梯度按行或按列展开成为向量形式;
[0057]
降维模块用于利用pca算法对向量展开模块展开的局部模型梯度的向量形式进行降维;
[0058]
聚类模块用于利用dbscan聚类方法对降维模块得到的降维局部模型梯度进行聚类,根据欧式距离选取距离最近的m个用户更新本代联邦学习训练过程的全局模型,并将更新的全局模型广播给用户。
[0059]
一种计算机设备,包括存储器和处理器,所述存储器存储有计算机程序,所述处理器执行所述计算机程序时实现联邦学习中基于局部模型梯度的用户筛选方法的步骤。
[0060]
一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现联邦学习中基于局部模型梯度的用户筛选方法的步骤。
[0061]
本发明的有益效果为:
[0062]
本发明针对联邦学习中可能出现的用户数据质量良莠不齐或存在恶意攻击的情况,提出了一种基于局部梯度模型分析用户数据质量进而进行用户筛选的方法,服务器通过对用户传输过来的局部模型梯度参数进行展开、降维、聚类,能够有效选择基于高质量数据训练的局部模型梯度,识别并消除噪声用户和恶意用户的局部模型模型梯度的影响,增强系统的鲁棒性,提升模型的收敛速度,提高模型的识别或预测的准确度。利用本发明提供的筛选用户方法,联邦学习的性能能够达到无噪声用户和恶意用户干扰情况下的水平。
附图说明
[0063]
图1是联邦学习训练过程的系统示意图;
[0064]
图2是dbscan聚类方法的流程框图;
[0065]
图3是实施例1中联邦学习第1代所有用户需要传输给服务器的梯度的pca降维到两维的结果分布图;
[0066]
图4是实施例1中联邦学习第10代所有用户需要传输给服务器的梯度的pca降维到两维的结果分布图;
[0067]
图5是实施例中联邦学习第20代所有用户需要传输给服务器的梯度的pca降维到两维的结果分布图;
[0068]
图6是实施例中联邦学习第30代所有用户需要传输给服务器的梯度的pca降维到两维的结果分布图;
[0069]
图7是训练mnist数据集时分别在无噪声用户和恶意用户,有噪声用户和恶意用户但不识别,有噪声用户和恶意用户且利用本发明的提供的方法识别的平均训练损失曲线对比图;
[0070]
图8是训练mnist数据集时分别在无噪声用户和恶意用户,有噪声用户和恶意用户但随机选择,有噪声用户和恶意用户且利用本发明的提供的方法识别的平均训练准确度曲线对比图。
具体实施方式
[0071]
下面结合实施例和说明书附图对本发明做进一步说明,但不限于此。
[0072]
实施例1
[0073]
一种联邦学习中基于局部模型梯度的用户筛选方法,通过分析用户梯度的分布选择更准确的局部模型,联邦学习中包括服务器和n个用户,每个用户分别与服务器相连接,该用户筛选方法的具体步骤包括:
[0074]
(1)服务器初始化全局模型参数,并将全局模型参数广播给所有参与到联邦学习过程的n个用户;
[0075]
(2)用户接收到全局模型参数后,利用用户持有的数据集更新局部模型参数,然后将用户的局部模型梯度传输给服务器;
[0076]
步骤(2)中,利用用户持有的数据集,使用随机梯度下降法得到用户的局部模型梯度。
[0077]
(3)服务器将n个局部模型梯度均按行或按列展开成为向量形式,向量的维数与局部模型的参数中的元素个数相同;
[0078]
(4)为了方便依据展开的向量对用户数据进行测评,服务器利用pca算法对步骤(3)得到的展开的局部模型梯度的向量形式进行降维,从而减小展开的向量的长度;
[0079]
具体过程包括:
[0080]4‑
1、输入数据集x={x1,x2,x3…
x
n
},x
i
表示第i个用户的局部模型梯度对应的展开的向量,i=1,2,3,
…
n;
[0081]4‑
2、去中心化:计算数据集x的均值x
mean
,然后将x的每个元素减去x
mean
得到去中心化数据集x
new
;
[0082]4‑
3、求去中心化数据集s
new
的协方差矩阵c
ov
;
[0083]4‑
4、计算协方差矩阵c
ov
的特征值及特征值对应的特征向量;
[0084]4‑
5、选取从大到小的k个特征值对应的特征向量分别作为列向量组成特征向量矩阵w,k表示维度数;
[0085]4‑
6、计算x
new
w,即把去中心化数据集x
new
投影到所选取的特征向量上,得到的x
new
w即为降为k维特征的数据集。
[0086]
为了减少计算量,k可以在不影响识别的前提下尽可能的小,本实施例中,k等于2。
[0087]
(5)服务器利用dbscan聚类方法对步骤(4)得到的n个降维局部模型梯度进行聚类,然后求聚类结果中数量最多的一类降维局部模型梯度的平均值,即降维局部模型梯度中心
[0088]
步骤(5)中,dbscan聚类方法的具体的过程为:
[0089]
1)找到所有核心点,点为n个经过pca降维后的k维向量:
[0090]
当点的局部密度大于设定阈值时,则该点为核心点,然后进行步骤2);
[0091]
2)对于一个未处理的核心点,将未处理的核心点与其邻域内的点形成一个新的类c;
[0092]
3)将邻域内的点插入队列中;
[0093]
4)判断队列是否为空:
[0094]
当队列不为空,则从队列中任意删除一个点,然后进行步骤5);
[0095]
当队列为空,则进行步骤6);
[0096]
5)判断删除的点是否为核心点:
[0097]
当删除的点的局部密度大于设定阈值,则标记删除点为核心点,并将该删除点邻域内未分配的点分配给类c,并插入队列中;然后,重复步骤4)至步骤5),直至队列为空;
[0098]
当删除的点的局部密度小于设定阈值,则删除的点为边界点;然后,重复步骤4)至步骤5),直至队列为空;
[0099]
6)判断所有核心点是否均已处理完毕:
[0100]
当所有核心点判断完毕,则将所有未处理的点标记为噪声点,然后结束;如果点不属于核心点也不属于边界点,称点为噪声点;
[0101]
否则,重复步骤2)
‑
6),直至所有点处理完毕。
[0102]
应用dbscan算法时,需要估计数据集中特定点的密度,特定点的密度是通过计算该点在指定半径下数据点个数(包括特定点),这种计算得到的某个点的密度也被称为局部密度。计算数据集中每个点的密度时,我们需要把每个点归为以下三类:1.如果点的局部密度大于某个阈值,称这个点为核心点。2.如果点的局部密度小于某个阈值,但是它落在核心点的邻域内,称这个点为边界点。3.如果点不属于核心点也不属于边界点,称点为噪声点。除了标记数据集中每个点的类别,我们要做的是根据类别将每个样本进行聚类。对于同一个还未分配的核心点,我们将它邻域内的所有点归为一个新的类,如果邻域内有其他核心点的话,我们将重复上面相同情况的动作。
[0103]
(6)计算每个用户的降维局部模型梯度到降维局部模型梯度中心的欧式距离;
[0104]
(7)根据步骤(6)计算得到的欧式距离,选取距离最近的m个用户;m为用户数量n的
60%到80%;
[0105]
(8)利用选取的m个用户的局部模型梯度更新本代联邦学习训练过程的全局模型并将更新的全局模型广播给用户,全局模型满足:
[0106][0107]
式(i)中,表示第t
‑
1代联邦学习的全局模型,表示第t代联邦学习的全局模型;
[0108]
(9)重复执行步骤(2)
‑
步骤(8),直至模型收敛。
[0109]
本实例中所用到的数据集是mnist手写数据集,用联邦学习的方法训练用于分类mnist手写数据集的卷积神经网络,该卷积神经网络包含依次连接的两个卷积池化层和两个全连接层。
[0110]
联邦学习中包括服务器和n个用户;本实施例中,用户总数n为25个,正常用户的个数n
a
=15,噪声用户的个数n
b
=5,恶意用户的个数n
c
=5,噪声用户持有的数据集图片是存在噪声干扰的图片,恶意用户持有的数据集图片是纯高斯噪声图片。每个用户持有1000张用于训练的mnist手写数据集图片,并且数据服从独立同分布。
[0111]
局部模型采用随机梯度下降法更新模型,学习率lr=0.01;
[0112]
全局模型是利用降维局部梯度离聚类中心最近的10个用户的平均梯度来更新,共进行30代。
[0113]
图3、图4、图5、图6是实例中联邦学习第1、10、20、30代所有用户需要传输给服务器的局部模型梯度经过pca降维到两维的结果分布图,横纵坐标表示局部模型梯度利用pca降维得到的两维特征,加号表示正常用户的局部模型梯度,圆点表示噪声用户的局部模型梯度,方点表示恶意用户的局部模型梯度。
[0114]
在利用pca进行降维后,正常用户、噪声用户以及恶意用户的局部模型梯度在空间上存在明显的差异,因此比较适合利用本发明进行用户选择。
[0115]
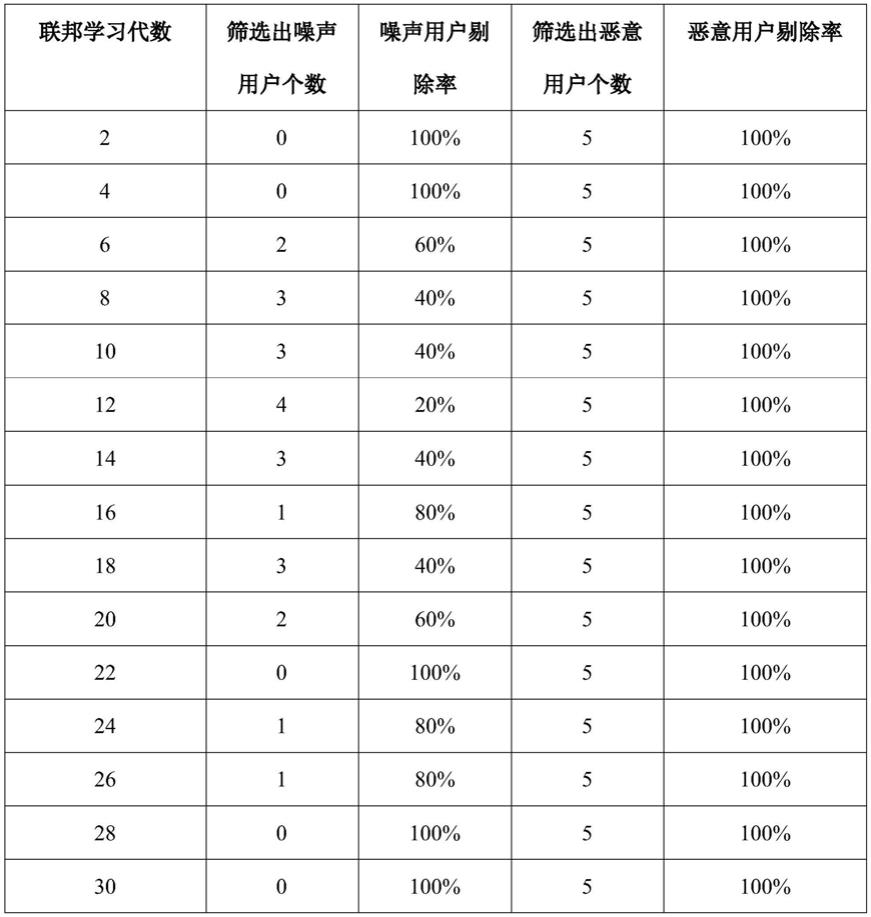
表1为联邦学习中每一代利用本发明方法筛选用户的结果,由于真实情况下噪声用户和恶意用户可能出现在联邦学习的任意一代,因此为了模拟真实情况,在此实例中每一代都有15个正常用户和5个噪声用户,5个恶意用户,更新全局模型时只用降维局部梯度离聚类中心最近的10个用户的局部模型梯度。
[0116]
表1
[0117][0118]
由表1可知,利用本发明提供的筛选方法筛选用户时,对噪声用户的剔除率达到了平均67%,对恶意用户的剔除率达到了100%。
[0119]
图7给出了联邦学习实例中训练mnist数据集时分别在无噪声用户和恶意用户,有噪声模型和恶意用户但随机选择,有噪声模型和恶意用户且利用本发明选择用户的平均训练损失曲线图;横坐标是联邦学习代数,纵坐标是平均训练损失。图8给出了联邦学习实例中训练mnist数据集时分别在无噪声用户和恶意用户,有噪声模型和恶意用户但随机选择,有噪声模型和恶意用户且利用本发明选择用户的平均训练准确度曲线图;横坐标是联邦学习代数,纵坐标是平均训练准确度。由图7和图8看出,当存在噪声用户和恶意用户影响训练过程时,利用本发明筛选用户,联邦学习的性能能够达到无噪声用户和恶意用户干扰情况下的水平。
[0120]
实施例2
[0121]
一种联邦学习中基于局部模型梯度的用户筛选系统,用于实现实施例1提供的一种联邦学习中基于局部模型梯度的用户筛选方法,包括向量展开模块、降维模块、聚类模块;
[0122]
向量展开模块用于将局部模型梯度按行或按列展开成为向量形式;
[0123]
降维模块用于利用pca算法对向量展开模块展开的局部模型梯度的向量形式进行降维;
[0124]
聚类模块用于利用dbscan聚类方法对降维模块得到的降维局部模型梯度进行聚类,根据欧式距离选取距离最近的m个用户更新本代联邦学习训练过程的全局模型,并将更新的全局模型广播给用户。
[0125]
实施例3
[0126]
一种计算机设备,包括存储器和处理器,所述存储器存储有计算机程序,所述处理器执行所述计算机程序时实现实施例1提供的联邦学习中基于局部模型梯度的用户筛选方法的步骤。
[0127]
实施例4
[0128]
一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现实施例1提供的联邦学习中基于局部模型梯度的用户筛选方法的步骤。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1