基于警情间语义相似度判断串并案的方法及装置与流程
本发明涉及公安管理领域,特别是涉及一种基于警情间语义相似度判断串并案的方法及装置。
背景技术:
在公安的案件,有串案和并案两种叫法。串案,就是一系列不同的案件,通过对作案手段、痕迹、物证等分析,发现其存在联系,进而将这些案件放在一起侦破。并案,是指两个不同的案件,通过作案手段、痕迹、物证,发现其存在联系,而将两个案件放在一起侦破。
现有技术中对串案和并案的处理方式,是通过人的经验来对作案手段、痕迹、物证等已有的数据进行分析,来确定案件之间是否串案或并案处理。其缺点是,串案和并案全部依赖的是个人的经验,没有系统支撑,另外面对海量的警情,很难有效的找到串并案警情,并且存在一定错误率。
技术实现要素:
本发明的目的是克服现有技术中的不足之处,提供一种基于警情间语义相似度判断串并案的方法及装置。
为实现上述目的,本发明一方面提供一种基于警情间的语义相似度辅助判断串并案的方法,包括:
借助预先训练得到的公安领域训练词向量模型,将计算原始警情信息转化为公安警情词向量;
利用公安警情词向量,计算警情之间的相似度;
将所述相似度大于第一阈值的多个警情辅助判断为串并案。
优选地,所述利用公安警情词向量,计算警情之间的相似度包括:
使用余弦相似度,计算警情的公安警情词向量之间的相似度,确定警情之间的相似度。
本发明另一方面还提供一种基于综合相似度辅助判断串并案的方法,包括:
基于警情间的融合路径权重相似度计算警情间的第一类型相似度;
基于警情间的语义相似度计算警情间的第二类型相似度;
基于专家规则计算警情间的第三类型相似度;
基于第一类型相似度、第二类型相似度和第三类型相似度,辅助判断警情之间是否为串并案;
其中,基于警情间的语义相似度计算警情间的第二类型相似度包括:
借助预先训练得到的公安领域训练词向量模型,将计算原始警情信息转化为公安警情词向量;利用公安警情词向量,计算警情之间的第二类型相似度。
本发明再一方面还提供一种计算机,包括处理器和存储器,所述处理器用于执行存储器中存储的指令以执行如下步骤:
借助预先训练得到的公安领域训练词向量模型,将计算原始警情信息转化为公安警情词向量;
利用公安警情词向量,计算警情之间的相似度;
将所述相似度大于第一阈值的多个警情辅助判断为串并案。
本发明再一方面还提供一种计算机,包括处理器和存储器,所述处理器用于执行存储器中存储的指令以执行如下步骤:
基于警情间的融合路径权重相似度计算警情间的第一类型相似度;
基于警情间的语义相似度计算警情间的第二类型相似度;
基于专家规则计算警情间的第三类型相似度;
基于第一类型相似度、第二类型相似度和第三类型相似度,辅助判断警情之间是否为串并案;
其中,基于警情间的语义相似度计算警情间的第二类型相似度包括:
借助预先训练得到的公安领域训练词向量模型,将计算原始警情信息转化为公安警情词向量;利用公安警情词向量,计算警情之间的第二类型相似度。
本实施例提供的技术方案通过实现中警情间的语义近似度确定警情之间的相似度,并以此辅助确定多个警情是否为串并案,极大改善了公安人员的办案效率。
本发明的其他有益效果将在说明书中进行进一步说明。
附图说明
为了更清楚地说明本发明实施例中的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为本申请实施例一提供的一种基于警情间的语义相似度辅助判断串并案的方法的流程示意图;
图2为本发明另一实施例还提供一种基于综合相似度辅助判断串并案的方法的流程示意图;
图3是图2中步骤s201的一种具体实现流程图;
图4为警情概念本体库的概念层次关系的一个示例示意图;
图5是图2中步骤s202的一种具体实现流程图;
图6是图2中步骤s203的一种具体实现流程图;
图7是警情概念图谱形成的一个具体示例的示意图。
具体实施方式
为了便于理解本发明,下面将参照相关附图对本发明进行更全面的描述。附图中给出了本发明的较佳实施方式。但是,本发明可以以许多不同的形式来实现,并不限于本文所描述的实施方式。相反地,提供这些实施方式的目的是使对本发明的公开内容理解的更加透彻全面。
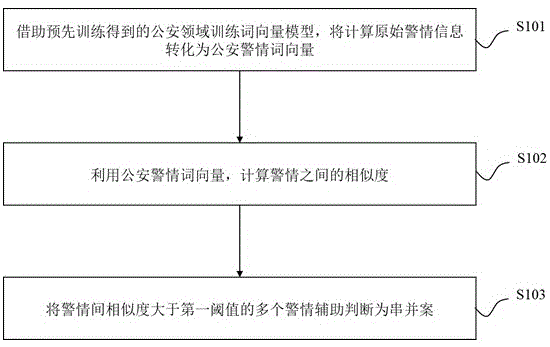
图1示出了本发明实施例一提供的一种基于警情间的语义相似度辅助判断串并案的方法的流程示意图,该方法包括:
步骤s101:借助预先训练得到的公安领域训练词向量模型,将计算原始警情信息转化为公安警情词向量。
可以利用利用word2vec算法在公安的警情语料中进行公安领域训练词向量模型。
具体地,可以采用word2vec的方法进行词向量模型训练。首先对警情语料进行分词,去除停用词,然后利用one-hot的形式进行表示。模型训练利用cbow方法来进行模型的训练。输入层为警情上下文单词的one-hot表示。然后对所有的one-hot表示词向量的输入乘以权重矩阵w。然后对所得到的向量相加求平均作为隐层向量,大小为1*n。最后乘以权重矩阵w,得到向量{1*v}激活函数处理得到v-dim概率分布,概率最大的index所指示的单词为预测出的中间词。训练的过程是loss函数最小。通过训练得到了权重矩阵w,词向量的one-hot表示乘以训练得到的权重矩阵w即为公安警情词向量。
步骤s102:利用公安警情词向量,计算警情之间的相似度。
一种具体的方式是使用余弦相似度,计算警情的公安警情词向量之间的相似度,确定警情之间的相似度。余弦值越大,则相似度越高。
步骤s103:将所述相似度大于第一阈值的多个警情辅助判断为串并案。
本实施例提供的技术方案通过实现中警情间的语义近似度确定警情之间的相似度,并以此辅助确定多个警情是否为串并案,极大改善了公安人员的办案效率。
本发明另一实施例还提供一种基于综合相似度辅助判断串并案的方法,参照图2所示,该方法包括:
步骤s201:基于警情间的融合路径权重相似度计算警情间的第一类型相似度。
其中步骤s201中基于警情间的融合路径权重相似度计算警情间的第一类型相似度,具体可以通过图3示出的流程图实现,包括如下步骤:
步骤s301:构建警情知识图谱,所述警情知识图谱将警情转化为结构化知识。
警情图谱的目的是为了将警情转化为结构化的知识,让机器可以理解警情,并且发现警情之间的一些关联关系。构建警情图谱首先是构建警情概念本体,然后基于本体进行要素信息抽取,将抽取的要素存储到图数据库构成警情知识图谱,供后续串并案关系发现。
具体地,警情概念本体的构建可以基于警情7何要(何时、何地、何事、何人、何因、何物、何果)对警情中涉及到的涉案人员,涉案地址,涉案物品,涉案时间,涉案手段等几大类概念要素进行细分,得到用于刻画警情的概念本体。由此,警情概念本体包括警情的多个概念要素。
对警情中的关键要素进行抽取的过程可以基于信息收取算法实现。例如可以使用基于预训练语言模型bert的信息抽取算法,对警情中的关键要素进行抽取。
步骤s302:计算不同警情中抽取的要素的概念之间的路径相似度进行加权求和,得到所述警情间的第一类型相似度。
具体地,可以根据警情知识图谱中的警情概念本体库的概念层次关系(如图4中所示的一种概念层次关系),基于不同警情中两个细粒度的概念在概念层次中的深度和路径关系,通过下式计算两个细粒度概念之间的第一类型相似度sim(ci,cj):
其中,depth(ci)和depth(cj)分别是术语ci和cj在概念层次中的深度,depth(clcs)表示术语ci和cj在概念层次中共同父概念的深度,lcs表示术语ci和cj在概念层次中的共同父概念。
而不同警情中抽取的要素的概念之间的路径相似度进行加权求和可以通过下式表示:
sim(j1,j2)=α1×simc1+α2×simc2+…+αn×simcn
其中,sim(j1,j2)为警情j1和j2的第一类型相似度,simci表示警情j1和j2在ci概念下两个细粒度概念的相似度,αi是加权求和中simci对应的权重。
步骤s202:基于警情间的语义相似度计算警情间的第二类型相似度。
其中步骤s202中基于警情问的语义相似度计算警情间的第二类型相似度可以具体通过图5中示出的流程图实现,包括如下步骤:
步骤s501:借助预先训练得到的公安领域训练词向量模型,将计算原始警情信息转化为公安警情词向量。本步骤与上述实施例一种步骤s101中的实现类似,这里不再赘述。
步骤s502:利用公安警情词向量,计算警情之间的第二类型相似度。本步骤与上述实施例一种步骤102的实现类似,区别仅在于,将步骤s102中计算得到的相似度,确定为第二类型相似度。
步骤s203:基于专家规则计算警情间的第三类型相似度;
其中,步骤s203中基于专家规则计算警情间的第三类型相似度具体可以通过如图6示出的流程图实现,包括如下步骤:
步骤s601:以产生式规则对研判专家知识进行表达。
例如可以生成如下研判规则:
if概念1=x1and概念2=x2and概念3=x3theny。
步骤s602:从警情中抽取关键要素并进行概念化,形成警情概念图谱。
例如参照图7示出的警情概念图谱形成的过程,首先从原始警情中抽取出关键要素,然后建立如图7中示出的警情概念图谱。
步骤s603:通过警情概念图谱,建立研判专家知识与警情的关系。
步骤s604:借助研判专家知识对警情进行研判,基于研判结论之间的相关性,确定警情之间第三类型相似度。
具体地,研判专家知识可以表达为多个研判规则,对于每个警情,基于全研判规则都可以得到多种类型的研判结论。而警情之间可以借助这些研判结论中相同或相近的结论占全部类型研判结论的比例,确定警情之间的第三类型相似度。例如,在两个警情之间,基于多个研判规则得出的相同研判结论的数量越多,则该两个警情之间的第三类型相似度越高。
步骤s204:基于第一类型相似度、第二类型相似度和第三类型相似度,辅助判断警情之间是否为串并案。
例如,可以将第一类型相似度、第二类型相似度和第三类型相似度进行加权求和,得到警情之间的综合相似度,并基于综合相似度确定多个警情是否为串并案。
将步骤s204中计算的相似度大于第一阈值的多个警情辅助判断为串并案,可以由相关公安人员再次人工核实,一经确认则可以做为串并案处理,加快侦破效率。
采用综合相似度辅助确定个警情是否为串并案,可以避免采用单一类型相似度导致遗漏发现警情之间的关联信息,进而遗漏发现串并案。
本发明另一实施例还提供一种计算机,包括处理器和存储器,所述处理器用于执行存储器中存储的指令以执行如下步骤:
借助预先训练得到的公安领域训练词向量模型,将计算原始警情信息转化为公安警情词向量;
利用公安警情词向量,计算警情之间的相似度;
将所述相似度大于第一阈值的多个警情辅助判断为串并案。
本发明再一实施例还提供一种计算机,包括处理器和存储器,所述处理器用于执行存储器中存储的指令以执行如下步骤:
基于警情间的融合路径权重相似度计算警情间的第一类型相似度;
基于警情间的语义相似度计算警情间的第二类型相似度;
基于专家规则计算警情间的第三类型相似度;
基于第一类型相似度、第二类型相似度和第三类型相似度,辅助判断警情之间是否为串并案;
其中,基于警情间的语义相似度计算警情间的第二类型相似度包括:
借助预先训练得到的公安领域训练词向量模型,将计算原始警情信息转化为公安警情词向量;利用公安警情词向量,计算警情之间的第二类型相似度。
以上所述仅为本发明的较佳实施例,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!