一种全球250米分辨率时空连续的叶面积指数卫星产品生成方法
1.本发明属于定量遥感卫星产品生成领域,特别是涉及一种全球250米分辨率时空连续的叶面积指数卫星产品生成方法。
背景技术:
2.叶面积指数(leaf area index,lai)是全球气候观测系统(gcos)指定的陆地基本气候变量之一,广泛应用于陆地生态系统模型模拟、作物产量估算和植被变化监测等多种科学应用。卫星观测数据为lai全球时间序列测绘提供了唯一可靠的手段。目前全球lai产品存在着一些局限性。最突出的问题是,输入地表反射率往往受到云雾或高浓度气溶胶的污染,导致时间序列产品的波动或数据缺失。例如在多云有雪的地区,modis lai数据缺失率可达40%,尽管glass
‑
lai算法已经使用基于植被指数的平滑方法重建了地表反射率,但现有的v5产品在中高纬地区冬季仍存在异常值和假生长季的现象。此外,由于glass需要对地表反射率进行优化重建,导致其生产过程非常耗时。
3.其次,由于输入观测数据与反演算法的差异,现有的lai产品存在显著差异。例如,在热带林区,不同产品之间的平均赖氨酸差异可达1个lai标准单位。这会在植被变化分析和地表模型模拟中造成很大的不确定性。如何通过整合产品的差异,优势互补,仍是一个挑战。第三,全球气候观测系统(gcos)需要250米分辨率的lai产品用于碳建模(gcos 2016),然而,目前能够满足这种要求的lai产品只是区域性的或短于一年的,如多伦多大学(ufft)lai产品。因此,目前还没有满足该要求的叶面积指数产品。
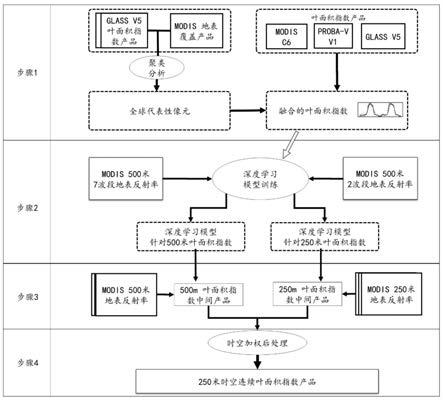
4.基于以后研究背景,目前迫切需要一种具有高计算效率、可生产高精度、高分辨率的长时间系列全球叶面积指数的新方法。
技术实现要素:
5.本发明针对现有技术的不足,基于modis(moderate resolution imaging spectroradiometer,中等分辨率成像光谱仪)卫星21年长的地表观测数据,提供一种全球250米分辨率时空连续的叶面积指数卫星产品生成方法。
6.为了达到上述目的,本发明提供的技术方案是:
7.步骤1,基于现有叶面积指数和地表覆盖分类产品,利用聚类分析和最小差规则创建可代表全球主要土地覆盖类型的训练样本;
8.步骤2,通过训练长短时记忆、门控递归单元、和双向lstm深度学习模型,确定最佳叶面积指数估算模型;
9.步骤3,通过将bilstm模型分别应用于modis 500米和250米地表反射率,生成分辨率为500米和250米的叶面积指数中间产品;
10.步骤4,利用时空加权平均后处理合并两个250米和500米分辨率lai中间产品,从而得到全球250米分辨率时空连续的叶面积指数产品。
11.进一步的,步骤1的具体实现方式如下,
12.首先,通过对2000年之后的任意一年的时间序列glass lai曲线进行k均值聚类分析,识别出不同类型的lai时间曲线,基于modis土地覆盖产品分别对每种土地覆盖类型进行聚类;
13.为确保每个聚类代表真实的lai时间序列,利用三个lai产品进行比较,即glass第五版、modis第六版和proba
‑
v第一版,以生成代表时间序列的连续lai样本,时间采样为k1年,每8天时间间隔,时间步为:k1*365/8向上取整;对于每个小类,选择这三个lai产品中差异最小的像元作为该小类的代表像元;由于modis lai比glass和proba
‑
v lai波动更大,在每个时间点,如果glase和proba
‑
v lai的差值小于一个单位,则取其平均值作为样本值,否则取modis、glase和cgls lai的中值;在此之后,在全球每个4
°×4°
的窗口中排查,如果窗口中没有选中的像元,则按最小差规则添加一个代表性像元;
14.选取代表性像元以后,提取其对应的modis时间序列地表反射率数据作为控制变量,融合后的时间序列lai作为目标变量,组成训练样本;随机将样本分为三组,分别是用于获得深度学习模型的训练数据集、用于选择最优模型的验证数据集和用于评估最终模型的测试数据集。
15.进一步的,利用最小差规则来选择代表性像元的具体实现方式如下,
16.由于modis和proba
‑
v时间序列lai在时间上可能是不连续的,因此这三种产品的lai序列的共同长度对于每个像素是不同的;这里应用一个最小差规则来选择代表性像元:当纬度低于50
°
,共有lai时间序列长度不小于70,当纬度高于50
°
且低于55
°
,共有lai序列长度不小于60,其他情况下共有长度不小于45。
17.进一步的,步骤2中,对于三个深度学习模型:lstm、gru和bilstm,保持相同的训练算法和参数:使用adam优化器,初始学习率为0.0001,批次大小为100,最大训练期数为200。
18.进一步的,步骤2中500米lai模型采用bilstm模型,利用modis 6个反射率波段以及3个太阳和卫星观测角作为特征序列;250m lai模型除采用modis红和近红外反射率波段组合作为特征输入外,其余设置与上述500m lai模型相同;其中modis 6个反射率波段中不含波段5,太阳和卫星观测角的时间长度为k1,间隔为8天。
19.进一步的,步骤3的具体实现方式如下;
20.利用步骤2中确定的bilstm模型和时间序列的modis地表反射率数据,估算出空间分辨率为500m、时间分辨率为8天的全球时间序列lai,然后利用250m地表反射率,采用红光和近红外两波段bilstm模型,估算全球250m 8天lai。
21.进一步的,步骤4的具体实现方式如下;
22.以任意一年为例,计算该年前一年及该年的lai序列1,以及该年及后一年的lai序列2,对这2个lai序列乘上时间加权函数,并在该年处相加,得到该年500米分辨率的lai时间序列,其中时间加权函数w设计为以下形式,其中t代表时间序列的步数:
[0023][0024]
由于500米lai的估算模型精度更高,为保持500米lai和250米lai的一致性,对250
米lai中间产品采用空间加权,即在每500米像素内,四个250米lai像元被标准化以匹配500米lai值:
[0025][0026]
最终得到空间分辨率为250米,时间分辨率8天,时间跨度从2000年至今的全球时空连续叶面积指数。
[0027]
与现有技术相比,本发明的优点和有益效果如下:1.该方法可生产自2000年21年长时间序列的250米分辨率的时空连续叶面积指数,填补目前产品在高纬地区的空白;是目前唯一可满足全球气候观测系统模拟碳循环的叶面积指数产品;
[0028]
2.不受长期缺少晴空无雪地表反射率等特殊情况的影响,经过全球观测网络大量地表数据的验证,新的方法可生产更高精度叶面积指数产品。
[0029]
3.采用深度学习模型,避免对了地表反射率产品的预处理,大幅提高了计算效率。
附图说明
[0030]
图1为本发明实施例流程图。
具体实施方式
[0031]
下面结合附图和实施例对本发明的技术方案作进一步说明。
[0032]
如图1所示,一种全球250米分辨率时空连续的叶面积指数卫星产品生成方法,具体包括如下步骤:
[0033]
步骤1:基于现有叶面积指数和地表覆盖分类产品,利用聚类分析和最小差规则创建可代表全球主要土地覆盖类型的训练样本;
[0034]
充分且具有代表性的训练样本是任何遥感反演深度学习模型的前提。我们的采样策略是选择全局样本,确保它们有足够的时间变化,同时也代表lai的地面真值。首先,为了减少数据冗余,确保lai足够的时间变化,通过对任意一年(2000年至今年中的任意一年,此处取2014年)
‑
的时间序列glass(global land surface satellite,全球陆表特征参量数据产品)lai(leaf area index,叶面积指数)曲线进行k均值聚类分析,识别出不同类型的lai时间曲线,基于modis土地覆盖产品分别对每种土地覆盖类型进行聚类。经过这个过程,总共生成了29000个小类。
[0035]
为确保每个聚类代表真实的lai时间序列,利用三个lai产品(glass第五版、modis第六版和proba
‑
v(project for on
‑
board autonomy
–
vegetation,星上自主项目
‑
植被监测)第一版)进行比较,以生成代表时间序列的连续lai样本。由于proba
‑
v产品自2014年后才提供,考虑到后期生产的效率,将时间采样设置为两年(2014年和2015年,每8天时间间隔,共92个时间步)。对于每个小类,选择这三个lai产品中差异最小的像元作为该小类的代表像元。由于modis和proba
‑
v时间序列lai在时间上可能是不连续的,因此这三种产品的lai序列的共同长度对于每个像素是不同的。这里应用一个最小差规则来选择代表性像元:当纬度低于50
°
,共有lai时间序列长度不小于70,当纬度高于50
°
且低于55
°
,共有lai序列长度不小于60,其他情况下共有长度不小于45。由于modis lai比glass和proba
‑
v lai波动更大,在每个时间点,如果glase和proba
‑
v lai的差值小于一个单位,则取其平均值作为样
本值,否则取modis、glase和cgls lai的中值。在此之后,在全球每个4
°×4°
的窗口中排查,如果窗口中没有选中的像元,则按上述规则添加一个代表性像元。
[0036]
选取代表性像元以后,提取其对应的2014
‑
2015年modis时间序列地表反射率数据作为控制变量,融合后的时间序列lai作为目标变量,组成训练样本。随机将样本分为三组,分别是用于获得深度学习模型的训练数据集(70%)、用于选择最优模型的验证数据集(20%)和用于评估最终模型的测试数据集(10%)。
[0037]
步骤2:通过训练长短时记忆(long short
‑
term memory,lstm)、门控递归单元(gated recurrent unit(gru))、和双向lstm深度学习模型(bilstm),确定最佳叶面积指数估算模型;
[0038]
在评估不同的机器学习模型时,只使用了一年的时间序列数据和modis地表反射率的红光和近红外波段。对于三个深度学习模型(lstm、gru和bilstm),我们保持相同的训练算法和参数:使用adam优化器,初始学习率为0.0001,批次大小为100,最大训练期数为200。
[0039]
然后,我们研究了不同时间序列长度对模型的影响。在此基础上,进一步评估modis地表反射波段的不同组合,为深度学习模型选择合适的特征集。最后,利用合适的特征集和时间长度对选择的深度学习模型进行再训练,确定最终的lai估算模型为:500米lai模型采用bilstm模型,利用modis 6个反射率波段(不含波段5)以及3个太阳和卫星观测角(时间长度为2年,间隔8天)作为特征序列;250m lai模型除采用modis红和近红外反射率波段组合作为特征输入外,其余设置与上述500m lai模型相同。
[0040]
步骤3:通过将bilstm模型分别应用于modis 500米和250米地表反射率,生成分辨率为500米和250米的叶面积指数中间产品;
[0041]
利用步骤2中确定的bilstm模型和时间序列的modis地表反射率数据,估算出空间分辨率为500m、时间分辨率为8天的全球时间序列lai。然后利用250m地表反射率,采用红光和近红外两波段bilstm模型,估算全球250m 8天lai。
[0042]
步骤4:利用时空加权平均后处理合并两个250米和500米分辨率lai中间产品,从而得到全球250米分辨率时空连续的叶面积指数产品。
[0043]
由于模型的训练误差,导出的两个连续时间窗的lai时间序列不一定是连续的。以2014年为例,首先需要计算2013和2014年的lai序列1(共92步),以及2014和2015年的lai序列2(同样也是92步),分别对这2个lai序列乘上时间加权函数,并在2014年时间步位置上相加,从而得到该年500米分辨率的lai时间序列。其中时间加权函数(w)设计为以下形式,其中t代表时间序列的步数:
[0044][0045]
该年份在时间步ts上的lai值为:
[0046]
lai(ts)=lai1(ts+46)
·
w(ts+46)+lai2(ts)
·
w(ts)(1≤ts≤46)
[0047]
由于500米lai的估算模型精度更高,为保持500米lai和250米lai的一致性,对250米lai中间产品采用了空间加权,即在每500米像素内,四个250米lai像元被标准化以匹配
500米lai值:
[0048][0049]
基于以上步骤,最终可得到空间分辨率为250米,时间分辨率8天,时间跨度从2000年至2021年的全球时空连续叶面积指数。
[0050]
本文中所描述的具体实施例仅仅是对本发明精神作举例说明。本发明所属技术领域的技术人员可以对所描述的具体实施例做各种各样的修改或补充或采用类似的方式替代,但并不会偏离本发明的精神或者超越所附权利要求书所定义的范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1