基于强化学习的自动化珩车控制方法与流程
1.本发明涉及自动化控制技术领域,尤其涉及基于强化学习的自动化珩车控制方法。
背景技术:
2.作为世界最大的制造业产业国家,我国拥有大量的大型工厂和物流仓库,无一例外的都需要装备珩车进行各种物料的吊装和转运。自动化珩车技术能够大大提高工厂的生产效率,降低用人成本,提高国家综合竞争能力。
3.目前自动化珩车技术主要包括感知和控制两部分。感知主要包括珩车的位置定位和吊具的定位。传统的定位技术主要基于传统的传感器检测设备,大多采用编码器,激光雷达,红外传感器,imu等。这些检测设备对环境的要求较为苛刻,抗干扰能力差,成本高,并且在恶劣的工业作业环境下往往难以胜任一些检测需求。
4.自动化珩车的控制技术主要是珩车的高精度位置控制和吊具的位置控制。目前大多自动珩车控制采用lqr、fuzzy、pid等传统控制方法,这类方法往往需要大量的参数调试,传感器校准,后期维护等工作,具有部署时间周期长,维护成本高的缺点。珩车的根本目的为精准的将货物运送到期望的位置,对于传统控制在感知信息不准确的情况下往往很难达到,较小的感知偏差就会导致控制失效。
5.目前大多数自动珩车技术应用仍具有局限性,因此没有能够进行大规模的实际应用。面对广泛的应用需求,急需一种简单,低成本,可靠性高的控制方法。
技术实现要素:
6.(一)要解决的技术问题
7.本发明实施例提供一种基于强化学习的自动化珩车控制方法,用以解决现有的自动化行车的控制技术存在的部署时间周期长,维护成本高,控制精度低的缺陷。
8.(二)发明内容
9.本发明实施例提供基于强化学习的自动化珩车控制方法,包括以下步骤:
10.步骤一:获取仿真模型;在仿真环境中建立自动化珩车的作业环境模型;
11.步骤二:建立强化学习模型;使用sac、a3c、td3等算法中的任意一种建立对应的强化学习模型,将步骤一中获取的相关作业环境模型的相关参数导入所述强化学习模型进行训练;
12.步骤三:现场部署;将步骤二中训练好的强化学习模型部署至作业现场。
13.优选的,步骤一中获取仿真模型包括以下步骤:
14.步骤a)使用仿真软件建立自动化珩车以及其使用环境的物理模型,并对其进行尺寸标定和动力学标定;
15.步骤b)在自动化珩车上部署图像采集装置,并对其进行标定。
16.优选的,步骤a)中的动力学标定包括阶参数辨识、补偿和阶跃响应标定。
17.优选的,步骤b)中对图像采集装置进行标定包括以下步骤:
18.步骤
ⅰ
)使用图像采集装置来采集多张标定图片;
19.步骤
ⅱ
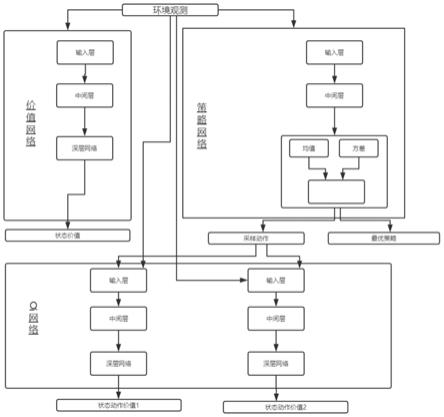
)对每一张标定图片,提取角点信息;
20.步骤
ⅲ
)对每一张标定图片,进一步提取亚像素角点信息;
21.步骤
ⅳ
)在棋盘标定图上绘制找到的内角点;
22.步骤
ⅴ
)相机标定;
23.步骤
ⅵ
)对标定结果进行评价;
24.步骤
ⅶ
)查看标定效果,利用标定结果对棋盘图进行矫正。
25.优选的,强化学习模型包括价值网络、策略网络和q网络,环境监测到的数据分别导入三者,价值网络输出状态价值,策略网络输出采样动作和最优策略,q网络接受环境监测数据和采样动作,并输出两种不同得状态动作价值。
26.优选的,价值网络、策略网络和q网络均包括输入层、中间层和深层网络。
27.优选的,强化学习模型的训练方法包括:
28.步骤c)初始化参数;
29.步骤d)智能体与作业环境交互,得到数据;
30.步骤e)训练智能体,所深度学习网络进行更新;
31.步骤f)评估训练效果。
32.(三)有益效果
33.本发明实施例提供的基于强化学习的自动化珩车控制方法,包括获取仿真模型、建立强化学习模型和现场部署步骤,利用深度学习和强化学习实现自动化珩车防摇控制,具有易部署,成本低、可靠性高的优点。
附图说明
34.为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作一简单地介绍,显而易见地,下面描述中的附图是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
35.图1是本发明实施例中的基于强化学习的自动化珩车控制方法的强化学习模型的系统框图;
36.图2是本发明实施例中的基于强化学习的自动化珩车控制方法的强化学习模型的训练方法流程图;
37.图3是强化学习后自动化珩车带着集装箱运动的情况示意图;
38.图4是传统算法控制下自动化珩车带着集装箱运动的情况示意图。
具体实施方式
39.为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
40.在本发明实施例的描述中,需要说明的是,除非另有明确的规定和限定,术语“第一”“第二”“第三”是为了清楚说明产品部件进行的编号,不代表任何实质性区别。“上”“下”“左”“右”的方向均以附图所示方向为准。对于本领域的普通技术人员而言,可以根据具体情况理解上述术语在本发明实施例中的具体含义。
41.需要说明的是,除非另有明确的规定和限定,术语“连接”应做广义理解,例如,可以是直接相连,也可以通过中间媒介间接相连。对于本领域的普通技术人员而言,可以具体情况理解上述术语在发明实施例中的具体含义。
42.本实施例提供的一种基于强化学习的自动化珩车控制方法,主要是利用深度学习和强化学习实现自动化珩车防摇控制,用一个或数个摄像机作为输入,控制小车动作,抑制起重机摆动。可以使负载移动到给定的位置,且残余摆动极小。
43.具体包括以下步骤:
44.步骤一:获取仿真模型;在仿真环境中建立自动化珩车的作业环境模型;在仿真软件msc adams中建立自动化珩车的物理模型,将其与实际起重机进行标定,使仿真环境和实际场景的动力学响应误差在一定范围内。标定包括尺寸标定和动力学标定。尺寸标定是指在现场测量相关尺寸与仿真环境中的尺寸进行标定。动力学标定是指在现场测试系统的动力学响应,例如阶跃相应,标定使仿真环境有类似的动力学响应。
45.同时建立相机模型,在自动化珩车上部署用于采集样图的摄像机,并对其进行标定并进行标定,同样的使相机误差在一定范围内。其中,相机标定使用opencv实现张正友法标定相机,其又包括以下步骤:
46.步骤
ⅰ
)使用图像采集装置来采集多张标定图片;
47.步骤
ⅱ
)对每一张标定图片,提取角点信息;
48.步骤
ⅲ
)对每一张标定图片,进一步提取亚像素角点信息;
49.步骤
ⅳ
)在棋盘标定图上绘制找到的内角点;
50.步骤
ⅴ
)相机标定;
51.步骤
ⅵ
)对标定结果进行评价;
52.步骤
ⅶ
)查看标定效果,利用标定结果对棋盘图进行矫正。
53.步骤二:建立强化学习模型;使用sac算法建立如图1所示的强化学习模型,将步骤一中获取的相关作业环境模型的相关参数导入强化学习模型进行训练;其中,强化学习模型包括价值网络、策略网络和q网络,环境监测到的数据分别导入三者,价值网络输出状态价值,所述策略网络输出采样动作和最优策略,q网络接受所述环境监测数据和所述采样动作,并输出两种不同得状态动作价值。价值网络、策略网络和q网络均包括输入层、中间层和深层网络。
54.如图2所示,强化学习模型的训练方法包括以下步骤:
55.步骤c)初始化参数;
56.步骤d)智能体与作业环境交互,得到数据;
57.步骤e)训练智能体,所深度学习网络进行更新;
58.步骤f)评估训练效果。
59.强化学习是智能体在与环境的交互过程中通过学习策略以达成回报最大化或实现特定目标的问题。通过与环境进行交互获得的指导评价,使智能体获得最大的总收益。
60.强化学习算法的算法有多种,比如sac、ppo、trpo、ddpg、a3c、 td3等算法中的任意一种等。
61.其中本实施例采用的sac是面向最大熵模型强化学习开发的一种离线训练算法。和ddpg相比,sac使用的是随机策略,相比确定性策略具有一定的优势。与目前的主流连续控制深度强化学习算法trpo和ppo 相比,sac将在线强化学习优化为离线强化学习算法。sac不仅仅可以在仿真环境中进行训练,而且可以在真实环境中进行训练,使得训练难度更低,训练结果更加准确。目前sac在公开的检测标准中取得了非常好的效果,并且能直接应用到真实机器人上,具有很高的实际应用意义。
62.本实施例采取了sac算法,运用多个神经网络作为核心,实现了对于最优目标策略函数的逼近模拟。策略函数神经网络的输入是摄像机的图像,从图像中获得系统的状态,输出是小车的动作控制信号,例如可以是速度目标值或者加速度目标值,结构如图1所示。值函数使用相似的神经网络结构,网络的输入是摄像机的图像,输出是当前状态的价值,这里的值是强化学习的概念,只在训练中使用。策略函数和值函数可以使用相同的神经网络输入,但进行分别输出来降低整体结构的复杂性。
63.回报函数的估计是强化学习的另一个非常重要的环节。本发明中,强化学习的回报可以使用独有的回报设计,根据具体环境给出最优的回报函数,也可以使用简单的0/1回报设计来降低设计难度。
64.使用sac,基于上文所述的模拟环境以及回报函数,可以对上面的策略函数神经网络和值函数神经网络进行优化训练,并得到最优神经网络参数。强化学习通过和环境互动进行训练,这里智能体可以和虚拟环境互动获得数据,或者直接在真实环境中获取数据,进行训练。具体训练过程参考图2。sac的优化目标为:
[0065][0066]
奖励设计是强化学习的重要环节,本实例使用0/1的奖励设计。即集装箱摇晃在
±
10cm以内时,奖励为1,其它任何情况奖励为0。
[0067]
图3为是训练后自动化珩车带着货物的运动情况。为了便于对比,起始状态为静止,图中给出货物运动到目标位置(0点)的运动情况。
[0068]
作为对比,图4为现有传统算法的控制下自动化珩车的运动情况。与强化学习的方法比较,运动较慢,虽然可以抑制摇摆,但效率较低。
[0069]
步骤三:现场部署;将步骤二中训练好的强化学习模型部署至作业现场。将俩个摄像头分别安装在小车两侧,把训练好的策略函数部署到一个工控机中,相机采集的图片传递到工控机,训练好的策略函数输出小车速度控制量,传递给小车的plc控制器,实现基于相机图片对小车进行控制。
[0070]
综上所述,本发明的基于强化学习的自动化珩车控制方法,利用深度学习和强化学习实现自动化珩车防摇控制,具有易部署,成本低、可靠性高的优点。
[0071]
最后应说明的是:以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1