一种基于授信模型的供应链金融平台的制作方法
1.本发明涉及供应链金融技术领域,具体涉及一种基于授信模型的供应链金融平台。
背景技术:
2.供应链是指围绕核心企业,从配套零件开始,制成中间产品以及最终产品,最后由销售网络把产品送到消费者手中的,包含原料供货商、供应商、制造商、仓储商、运输商、分销商、零售商以及终端客户等多个主体的系统。供应链中涉及到上下游产业涉及到的企业众多。其中不乏中小企业,甚至微型企业及初创企业。这些企业参与到供应链活动中,为其下游企业提供产品或服务,并从其上游企业购买产品或服务。这些微型企业及初创企业往往规模较小,管理不完善,资质较少,难以获得信贷的机构的信贷支持。但参与到供应链中,就会与供应链中的其他企业相互依存,"一荣俱荣、一损俱损"。因而目前出现供应链中的核心企业或具一定规模的企业为这些小微企业担保,以获得信贷支持。但这种担保给提供担保的企业带来了风险和成本,且由于银行无法获取完整的业务管理数据和资质数据,即使有担保也难以获得足够的信贷额度。
3.区块链技术是一种去中心化的分布式账本系统,记录其中的数据具有可追溯、不易丢失及不可篡改的特性,能够为各企业及机构数据提供可信证明,高效和低成本的为企业、机构之间构建信任度。
4.但使用区块链技术虽然能够提供可信的供应链企业的业务数据,但同时也造成了供应链企业的业务数据的泄密。给供应链企业的发展带来不利因素。因而需要提供一种既能够提供可信的业务、资质数据,又不会造成供应链企业的核心数据外泄的,可信性和保密性兼顾的信贷方案。
技术实现要素:
5.本发明要解决的技术问题是:目前供应链金融平台不能兼顾可信性和保密性的技术问题。提出了一种基于授信模型的供应链金融平台,本技术方案借助授信模型,使信贷机构在不获取申请贷款的供应链企业的原始数据的情况下,就能够获得可信的信贷额度评估结果,进行信贷业务,兼顾了可信性和保密性。
6.为解决上述技术问题,本发明所采取的技术方案为:一种基于授信模型的供应链金融平台,包括若干个供应链数据节点和交互服务器,供应链数据节点连接若干个供应链企业,所述供应链数据节点运行有数据存储模块、数据存证模块和授信模型执行模块,所述数据存储模块存储供应链企业的资质数据、可抵押资产数据和业务数据,所述数据存证模块将数据存储模块的数据进行存证,所述授信模型执行模块将供应链企业的业务数据输入授信模型,所述授信模型输出对应供应链企业的授信额度,所述交互服务器连接信贷机构并与信贷机构进行数据交互,所述交互服务器接收信贷机构提交的授信模型,并将授信模型发送至贷款目标供应链企业所连接的供应链数据节点执行,获得授信额度,根据授信额
度开展信贷业务。供应链企业的资质数据如通过了质量体系认证、注册资金满足预设条件以及取得的其他银行认可的证书等。可抵押资产数据包括不动产,如房产,以及动产,如汽车、持有的投资等。业务数据包括历史营业额、历史盈利、历史供应合同等。授信模型根据申请贷款的企业的各项数据,得出授信额度。具体的授信模型由银行根据自身需要具体制定,属于本领域的已知技术,本发明专利不需要也不便于明确限定授信模型的具体授信规则。将授信模型发送到供应链数据节点时,供应链数据节点提取其所存储的欲申请贷款的供应链企业的数据,如,企业的注册资金、是否通过质量体系认证、有无可抵押房产/车产、有无可抵押的投资、历史年度营业额及年度盈利,将这些数据输入授信模型,授信模型具体得出是否给予贷款,以及给予的最高信贷额度。银行具体调整授信模型所依据的数据,如不考虑企业的注册资金,则对应的供应链数据节点不需要提取企业的注册资金。对于历史年度营业额及年度盈利,供应链数据节点需要将所存储的全部业务数据,按照年度归集、汇总,计算获得。也可以在财年统一归集、汇总,将上一财年供应链企业的营业额及盈利计算出来,存储备用。
7.作为优选,所述数据存储模块收集供应链企业的业务数据,在存储空间开辟线性存储区域,以紧邻的方式存储业务数据,所述数据存证模块以第一周期在业务数据后插入存证点,所述存证点占用预设长度的存储空间,将两个存证点之间的业务数据关联企业标识和标准时间戳后提取哈希值,将哈希值存入存证点,将上一个存证点内的数据与当前存证点的业务数据哈希值一起提取哈希值,作为关联哈希值存入存证点,所述数据存证模块以第二周期将最新的关联哈希值发送给所述交互服务器,所述交互服务器将收到的关联哈希值打包为压缩包,提取压缩包的哈希值并上传到区块链存储,所述数据存证模块以第三周期将最新的关联哈希值上传到区块链存储。以线性空间存储不仅加快读取速度,事后恶意修改数据时,若改变数据所占用的存储空间,会带来大量的资源消耗,对应接入足够大量企业数据的供应链数据节点而言,能有效提高恶意修改已存储数据的代价和所需的时间。
8.作为优选,所述交互服务器周期性产生16的n次方个随机数和穷举数对,所述随机数和穷举数对满足预设的工作量证明条件,所述数据存证模块抽取关联哈希值的指定位构成若干个n位数,从所述交互服务器下载末尾n位与所述的n位数相同的随机数及相应的穷举数,存入存证点。交互服务器产生多个满足工作量证明的随机数和穷举数对,供多个供应链数据节点使用,若供应链数据节点的数量多于产生的随机数和穷举数对,则平摊下来后,反而能够节省大量的算力。供应链数据节点由于要实时同步大量供应链企业的业务数据,难以有足够的剩余算力进行工作量证明,采用本优选方案提出的关联已有工作量证明,能够方便快捷的建立工作量证明。但当周期结束后,若供应链数据节点恶意修改已存储的数据,则几乎必然的会导致关联哈希值的指定位发生变化,此时供应链数据节点就需要自行建立工作量证明,这是十分消耗算力和时间的,大幅提高了数据篡改的难度和成本。
9.作为优选,所述数据存证模块从最新的关联哈希值及上一个存证点存储的最后一个穷举数中按指定位置抽取若干个n位数,从所述交互服务器下载末尾n位与所述的n位数相同的随机数及相应的穷举数,存入当前存证点,所述预设的工作量证明条件的难度设置为以所述供应链数据节点的最大算力,计算获得所需要的全部随机数和穷举数对的平均时间大于第一周期。若篡改上一个周期已存储的数据,则几乎必然需要重新进行工作量证明,但本周期还需要获得上一周期的最后一个穷举数的指定位,若供应链数据节点来不及在本
周期结束前就明确的获得最后一个穷举数,以获得其指定位的值,就会错过本周期的下载机会。时间进入到下一周期后,供应链数据节点不仅需要弥补上上一周期的工作量证明,还需要弥补上一周期缺失的工作量证明。这一弥补过程必然又会错过当前周期的工作量证明下载机会,因而会导致供应链数据节点始终在弥补工作量证明,且需要弥补的漏洞将越来越大,确保了数据篡改必然留痕,提供数据的鉴伪存真。
10.作为优选,所述数据存储模块将两个存证点之间的业务数据使用自己的公钥加密后,发送给若干个其他供应链数据节点,在存证点中记录所发送的其他供应链数据节点的标识,当供应链数据节点本地存储的业务数据损坏或被意外修改时,从相应其他供应链数据节点获取损坏或被修改的业务数据。提供数据的备份,在数据被篡改后能够复原,数据丢失后有机会恢复数据。
11.作为优选,所述交互服务器提供授信模型编辑模块,所述授信模型的输入包括供应链企业的资质数据、可抵押资产数据和业务数据,所述授信模型的输出包括授信额度,信贷机构通过所述授信模型编辑模块编辑授信模型,在授信模型中指定其接受的供应链企业资质数据条件、可抵押资产数据条件和业务数据条件,而后编辑每项可抵押资产及业务规模能够对应获得的信贷额度,将授信模型签名后提交给所述交互服务器,所述交互服务器验证签名后赋予授信模型唯一标识并将授信模型上线,公开授信模型的摘要信息,所述摘要信息包括信贷机构信息和授信模型上线时间,供应链企业欲申请贷款时,选择目标信贷机构,由供应链企业所连接的供应链数据节点从交互服务器下载对应的授信模型,并由授信模型执行模块执行所述的授信模型,所述授信模型执行模块根据授信模型所要求的输入,从其存储的对应供应链企业的数据中抽取资质数据、可抵押资产数据和业务数据,代入所述授信模型并得出授信额度结果,将授信额度结果发送给交互服务器,由所述交互服务器转交给信贷机构,所述信贷机构根据得到的授信额度结果进行信贷业务。银行通过授信模型编辑模块进行授信模型的编辑,有助于形成统一形式的授信模型,避免数据格式不兼容等造成授信模型不能正确的被执行。
12.作为优选,所述授信模型执行模块执行所述的授信模型时,开辟单独的存储区域,将抽取的资质数据、可抵押资产数据和业务数据打包提取哈希值作为数据哈希值,将授信模型提取哈希值作为模型哈希值,将数据哈希值和模型哈希值上传到区块链存储。其他供应链数据节点能够以外部共识合约的方式,读取本供应链数据节点提取出来的含供应链企业敏感数据的资质数据、可抵押资产数据和业务数据,验证授信模型是否被正确执行,还可以验证本供应链数据节点提取的业务数据等是否真实正确。验证通过后对验证结果进行签名。若验证不通过则进行相应的举报,由交互服务器或供应链数据节点自治机制进行惩罚。
13.作为优选,信贷机构将授信模型签名后提交给所述交互服务器时,同时提交示例数据,所述示例数据包括供应链企业资质数据、可抵押资产数据、业务数据及对应的授信额度,所述交互服务器验证签名后,将示例数据代入接收到的授信模型,验证授信模型输出的结果与示例数据中的授信额度匹配后,将授信模型上线并公开授信模型的摘要信息。使用示例数据确保授信模型能够被正确执行。
14.作为优选,所述供应链数据节点邀请若干个其他供应链数据节点进行授信模型执行的验证,所述供应链数据节点将本次授信模型使用到的数据打包加密发送给验证的其他供应链数据节点,其他供应链数据节点收到数据后,从中抽取资质数据、可抵押资产数据和
业务数据,并代入所述授信模型并得出授信额度结果,与所述供应链数据节点得出的信贷额度对比,若一致,则验证通过,将验证结果进行签名发送给所述供应链数据节点保存,若不一致,则验证不通过,将验证结果关联相关信息并签名后发送给交互服务器。相关信息包括被验证的供应链数据节点及授信模型标识。
15.本发明的实质性效果是:1)借助授信模型由供应链数据节点使用供应链企业的资质数据和业务数据,进行授信额度的评估,供应链企业的业务数据不需要离开供应链数据节点,因而不会出现泄漏的情况,有效保护了供应链企业的隐私,通过区块链存证保证供应链数据节点评估得到的信贷额度是可信的,并提交给信贷机构进行信贷业务,保证了信贷数据的真实性;2)通过收集供应链企业的资质数据和业务数据,能够为授信额度评估提供全面的数据参考,有助于信贷机构提升信贷额度,促进资金流通,借助区块链存证保证企业数据的真实性,降低坏账率;3)通过工作量证明提高业务数据的可信度,使篡改数据的代价进一步提升,保证供应链企业的业务数据真实可信。
附图说明
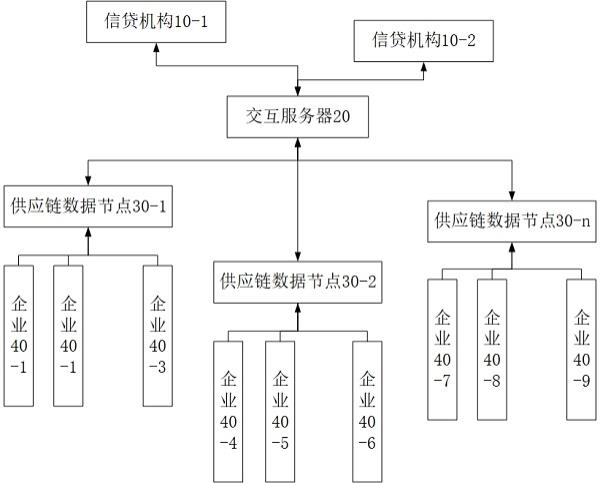
16.图1为实施例一供应链金融平台结构示意图。
17.图2为实施例一数据存储模块存储数据结构示意图。
18.图3为实施例一供应链数据节点结构示意图。
19.图4为实施例一授信模型上线结构示意图。
20.图5为实施例一授信模型结构示意图。
21.图6为实施例一授信模型验证方法示意图。
22.图7为实施例一数据存证模块工作过程示意图。
23.其中:10、信贷机构,20、交互服务器,30、供应链数据节点,40、企业,50、区块链,31、数据存储模块,32、数据存证模块,33、授信模型执行模块,51、唯一标识,52、摘要信息,53、资质数据,54、可抵押资产数据,55、授信额度, 311、业务数据,312、哈希值,313、关联哈希值,521、信贷机构信息,522、上线时间。
具体实施方式
24.下面通过具体实施例,并结合附图,对本发明的具体实施方式作进一步具体说明。
25.实施例一:一种基于授信模型的供应链金融平台,请参阅附图1,本实施例包括若干个供应链数据节点30和交互服务器20,供应链数据节点30连接若干个供应链企业40,供应链数据节点30运行有数据存储模块31、数据存证模块32和授信模型执行模块33,数据存储模块31存储供应链企业40的资质数据53、可抵押资产数据54和业务数据311,数据存证模块32将数据存储模块31的数据进行存证,授信模型执行模块33将供应链企业40的业务数据311输入授信模型,授信模型输出对应供应链企业40的授信额度55,交互服务器20连接信贷机构10并与信贷机构10进行数据交互,交互服务器20接收信贷机构10提交的授信模型,并将授信模型发送至贷款目标供应链企业40所连接的供应链数据节点30执行,获得授信额度55,根据授信额度55开展信贷业务。
26.供应链企业40的资质数据53如通过了质量体系认证、注册资金满足预设条件以及
取得的其他银行认可的证书等。
27.可抵押资产数据54包括不动产,如房产,以及动产,如汽车、持有的投资等。业务数据311包括历史营业额、历史盈利、历史供应合同等。授信模型根据申请贷款的企业40的各项数据,得出授信额度55。具体的授信模型由银行根据自身需要具体制定,属于本领域的已知技术,本发明专利不需要也不便于明确限定授信模型的具体授信规则。将授信模型发送到供应链数据节点30时,供应链数据节点30提取其所存储的欲申请贷款的供应链企业40的数据,如,企业40的注册资金、是否通过质量体系认证、有无可抵押房产/车产、有无可抵押的投资、历史年度营业额及年度盈利,将这些数据输入授信模型,授信模型具体得出是否给予贷款,以及给予的最高信贷额度。银行具体调整授信模型所依据的数据,如不考虑企业40的注册资金,则对应的供应链数据节点30不需要提取企业40的注册资金。对于历史年度营业额及年度盈利,供应链数据节点30需要将所存储的全部业务数据311,按照年度归集、汇总,计算获得。也可以在财年统一归集、汇总,将上一财年供应链企业40的营业额及盈利计算出来,存储备用。
28.数据存储模块31收集供应链企业40的业务数据311,在存储空间开辟线性存储区域,以紧邻的方式存储业务数据311,请参阅附图2,数据存证模块32以第一周期在业务数据311后插入存证点,存证点占用预设长度的存储空间,将两个存证点之间的业务数据311关联企业40标识和标准时间戳后提取哈希值312,将哈希值312存入存证点,将上一个存证点内的数据与当前存证点的业务数据311哈希值312一起提取哈希值312,作为关联哈希值313存入存证点,首个存证点将业务数据311的哈希值312和随机生成的一个随机数一起提取哈希值312作为关联哈希值313。供应链企业40的资质数据53有相关的部门公开核准,因而不需要存证,只需要在得到资质数据53后,向相关部门核对即可。且供应链企业40的资质数据53会随着企业40的发展而发生变化,也不适宜以存证的方式固定。
29.数据存证模块32以第二周期将最新的关联哈希值313发送给交互服务器20,交互服务器20将收到的关联哈希值313打包为压缩包,提取压缩包的哈希值312并上传到区块链50存储,数据存证模块32以第三周期将最新的关联哈希值313上传到区块链50存储。以线性空间存储不仅加快读取速度,事后恶意修改数据时,若改变数据所占用的存储空间,会带来大量的资源消耗,对应接入足够大量企业40数据的供应链数据节点30而言,能有效提高恶意修改已存储数据的代价和所需的时间。
30.请参阅附图3,交互服务器20提供授信模型编辑模块,授信模型的输入包括供应链企业40的资质数据53、可抵押资产数据54和业务数据311,授信模型的输出包括授信额度55,信贷机构10通过授信模型编辑模块编辑授信模型,在授信模型中指定其接受的供应链企业40资质数据53条件、可抵押资产数据54条件和业务数据311条件,而后编辑每项可抵押资产及业务规模能够对应获得的信贷额度,将授信模型签名后提交给交互服务器20,请参阅附图4,交互服务器20验证签名后赋予授信模型唯一标识51并将授信模型上线,公开授信模型的摘要信息52,摘要信息52包括信贷机构信息521和授信模型上线时间522,供应链企业40欲申请贷款时,选择目标信贷机构10,由供应链企业40所连接的供应链数据节点30从交互服务器20下载对应的授信模型,并由授信模型执行模块33执行的授信模型,请参阅附图5,授信模型执行模块33根据授信模型所要求的输入,从其存储的对应供应链企业40的数据中抽取资质数据53、可抵押资产数据54和业务数据311,代入授信模型并得出授信额度55
结果,将授信额度55结果发送给交互服务器20,由交互服务器20转交给信贷机构10,信贷机构10根据得到的授信额度55结果进行信贷业务。银行通过授信模型编辑模块进行授信模型的编辑,有助于形成统一形式的授信模型,避免数据格式不兼容等造成授信模型不能正确的被执行。
31.授信模型执行模块33执行的授信模型时,开辟单独的存储区域,将抽取的资质数据53、可抵押资产数据54和业务数据311打包提取哈希值312作为数据哈希值312,将授信模型提取哈希值312作为模型哈希值312,将数据哈希值312和模型哈希值312上传到区块链50存储。请参阅附图6,其他供应链数据节点30能够以外部共识合约的方式,读取本供应链数据节点30提取出来的含供应链企业40敏感数据的资质数据53、可抵押资产数据54和业务数据311,验证授信模型是否被正确执行,还可以验证本供应链数据节点30提取的业务数据311等是否真实正确。验证通过后对验证结果进行签名。若验证不通过则进行相应的举报,由交互服务器20或供应链数据节点30自治机制进行惩罚。
32.信贷机构10将授信模型签名后提交给交互服务器20时,同时提交示例数据,示例数据包括供应链企业40资质数据53、可抵押资产数据54、业务数据311及对应的授信额度55,交互服务器20验证签名后,将示例数据代入接收到的授信模型,验证授信模型输出的结果与示例数据中的授信额度55匹配后,将授信模型上线并公开授信模型的摘要信息52。使用示例数据确保授信模型能够被正确执行。
33.供应链数据节点30邀请若干个其他供应链数据节点30进行授信模型执行的验证,供应链数据节点30将本次授信模型使用到的数据打包加密发送给验证的其他供应链数据节点30,其他供应链数据节点30收到数据后,从中抽取资质数据53、可抵押资产数据54和业务数据311,并代入授信模型并得出授信额度55结果,与供应链数据节点30得出的信贷额度对比,若一致,则验证通过,将验证结果进行签名发送给供应链数据节点30保存,若不一致,则验证不通过,将验证结果关联相关信息并签名后发送给交互服务器20。相关信息包括被验证的供应链数据节点30及授信模型标识。
34.请参阅附图7,交互服务器20周期性产生16的n次方个随机数和穷举数对,随机数和穷举数对满足预设的工作量证明条件,数据存证模块32抽取关联哈希值313的指定位构成若干个n位数,从交互服务器20下载末尾n位与的n位数相同的随机数及相应的穷举数,存入存证点。交互服务器20产生多个满足工作量证明的随机数和穷举数对,供多个供应链数据节点30使用,若供应链数据节点30的数量多于产生的随机数和穷举数对,则平摊下来后,反而能够节省大量的算力。供应链数据节点30由于要实时同步大量供应链企业40的业务数据311,难以有足够的剩余算力进行工作量证明,采用本优选方案提出的关联已有工作量证明,能够方便快捷的建立工作量证明。但当周期结束后,若供应链数据节点30恶意修改已存储的数据,则几乎必然的会导致关联哈希值313的指定位发生变化,此时供应链数据节点30就需要自行建立工作量证明,这是十分消耗算力和时间的,大幅提高了数据篡改的难度和成本。
35.数据存证模块32从最新的关联哈希值313及上一个存证点存储的最后一个穷举数中按指定位置抽取若干个n位数,从交互服务器20下载末尾n位与的n位数相同的随机数及相应的穷举数,存入当前存证点。
36.本实施例中,n取值为2,交互服务器20生成了16x16个随机数和穷举数对,即256个
随机数和穷举数对,供应链数据节点30的最新关联哈希值313为:f6aa71ae9975e56a2755debfb543ef0a6f7cbd152340afe319b8b26e94e4f8fe,上一个存证点存储的最后一个穷举数为:5c1e2d776,其中的前2位、末尾2位、第5至6位、第13至14位和第19至20位,以及上一个穷举数的最后一位和当前关联哈希值313的倒数第4位,共6组指定位。分别为f6、71、e5、55、fe及f6,从交互服务器20下载末尾两位分别与该5组指定位相同的5个随机数和对应的穷举数,存入存证点。若供应链数据节点30篡改已存储的数据,则关联哈希值313必然发生变化,其中指定的6组指定位,均不变化的概率仅为1比16的12次方,约两百八十万亿分之一。若6组指定位均发生变化,则供应链数据节点30,需要自行生成6组工作量证明,这是难以完成的。6组均发生变化的概率约为0.92。可见,供应链数据节点30必然需要进行一组工作量证明,且具有极大的概率需要进行多组工作量证明。工作量证明指随机数和穷举数一起提取哈希值312,该哈希值312的前若干位取值为0。
37.预设的工作量证明条件的难度设置为以供应链数据节点30的最大算力,计算获得所需要的全部随机数和穷举数对的平均时间大于第一周期。若篡改上一个周期已存储的数据,则几乎必然需要重新进行工作量证明,但本周期还需要获得上一周期的最后一个穷举数的指定位,若供应链数据节点30来不及在本周期结束前就明确的获得最后一个穷举数,以获得其指定位的值,就会错过本周期的下载机会。时间进入到下一周期后,供应链数据节点30不仅需要弥补上上一周期的工作量证明,还需要弥补上一周期缺失的工作量证明。这一弥补过程必然又会错过当前周期的工作量证明下载机会,因而会导致供应链数据节点30始终在弥补工作量证明,且需要弥补的漏洞将越来越大,确保了数据篡改必然留痕,提供数据的鉴伪存真。
38.数据存储模块31将两个存证点之间的业务数据311使用自己的公钥加密后,发送给若干个其他供应链数据节点30,在存证点中记录所发送的其他供应链数据节点30的标识,当供应链数据节点30本地存储的业务数据311损坏或被意外修改时,从相应其他供应链数据节点30获取损坏或被修改的业务数据311。提供数据的备份,在数据被篡改后能够复原,数据丢失后有机会恢复数据。
39.本实施例中供应链企业40的业务数据311不需要离开供应链数据节点30,因而不会出现泄漏的情况,有效保护了供应链企业40的隐私,通过区块链50存证保证供应链数据节点30评估得到的信贷额度是可信的,并提交给信贷机构10进行信贷业务,保证了信贷数据的真实性。
40.实施例二:一种基于授信模型的供应链金融平台,建立在农产品供应链中,本实施例应用的农产品供应链具有一个核心企业40,即一家大型的农产品交易市场企业40,该农产品交易市场建立在靠近农产品产区附近,主要供应初级农产品或半加工农产品。其与当地的若干个县城中的多个农产品加工厂具有业务合作关系。农产品加工厂将其从农户收购得到的农产品,直接或经过简单加工包装后,在农产品交易市场企业40开设档口销售。本地及外地食品加工厂,从农产品交易市场购买农产品或者初加工产品。农产品交易市场具有良好的管理,对经由农产品交易市场成交的每笔交易或订购合同均有记录。
41.在每个县城建立一个供应链数据节点30,在其中一个县城建立一个交互服务器
20,交互服务器20与供应链数据节点30建立保密通信,县城中的多个农产品加工厂均接入同一个供应链数据节点30。
42.农产品加工厂将其资质数据53和可抵押资产数据54输入到对应的供应链数据节点30保存。当其资质数据53或可抵押资产数据54发生变化时,及时向供应链数据节点30更新。农产品加工厂将其业务数据311实时同步到供应链数据节点30,该数据同步仅能增加数据,不能删改交易数据,若要进行业务数据311的删改,则新增一条对应的修改交易数据或删除业务数据311的新的记录,同步到供应链数据节点30。供应链数据节点30按需或者按财年周期,将农产品加工厂的业务数据311汇总统计,获得年销售额和利润。
43.在农产品成熟季节,某个农产品加工厂,记为甲加工厂,需要在短期内收购大量农产品,导致资金不足,需要进行借贷。于是甲加工厂向乙银行提交了贷款申请。乙银行收到贷款申请后,将其授信模型及示例数据提交给交互服务器20。交互服务器20验证示例数据通过,将授信模型关联乙银行的名称和当前标准时间后,将授信模型上线。
44.表1 乙银行提交的授信模型
序号条件额度1具有营业执照必须满足2可抵押本地房产,本地房产情况大致相同+20万3可抵押外地房产,上传经认证的估价单+估价单显示价值*60%4可抵押车产,车产满足车龄低于8年,购买价高于10万低于50万,需上传购车发票+5万5可抵押车产,车产满足车龄低于8年,购买价高于50万,需上传购车发票+15万6上一年度营业额大于100万+30万7上一年度营业额大于20万+10万8上一年度营业额大于3万+1万9上一年度利润+利润*100%
甲加工厂通过供应链数据节点30下载乙银行的授信模型。供应链数据节点30的授信模型执行模块33,调取甲工厂存入的资质数据53和可抵押资产数据54,而后对甲工厂的业务数据311进行汇集统计。
45.甲工厂具有营业执照,具有可抵押本地房产,无车产,上一年度营业额26万,盈利8万。今年欲申请30万的贷款,用于购买一款新型设备和收购农产品。
46.表2 甲加工厂代入授信模型的结果
序号条件额度1具有营业执照满足2可抵押本地房产,本地房产情况大致相同+20万3可抵押外地房产,上传经认证的估价单+04可抵押车产,车产满足车龄低于8年,购买价高于10万低于50万,需上传购车发票+05可抵押车产,车产满足车龄低于8年,购买价高于50万,需上传购车发票+06上一年度营业额大于100万+07上一年度营业额大于20万+10万8上一年度营业额大于3万09上一年度利润+8万
ꢀꢀ
汇总:38万
经过乙银行的授信模型执行结果,乙银行知晓按照甲加工厂的资质、资产和运营情况,最多能够贷款38万,高于其所申请的30万贷款。因而决定给甲加工厂办理贷款。
47.乙银行将成功办理贷款的结果反馈给授信模型,授信模型根据最终贷款额度30
万,判断需要抵押房产。因而将甲加工厂的房产数据标记为已抵押,并由供应链数据节点30生成抵押记录存储,并经过数据存证模块32存证。
48.更进一步的,本实施例还可以借由授信模型直接通过电子形式,将甲加工厂抵押其房产的事件,通过公证处的公证,建立赋强公证。
49.在此过程中,乙银行仅知晓甲加工厂抵押了其房产,对甲加工厂的具体经营数据、营业额及利润则一无所知。但房产并非需要保密的隐私数据。虽然乙银行不知晓甲加工厂的具体运营数据,但乙银行仍然能够可信的将授信额度55给予甲加工厂。甲工厂成功申请到了贷款,且其需要保密的数据并未泄露给银行,仍然处在其所连接的供应链数据节点30上。仅需要保证供应链数据节点30的数据安全即可,相应的技术属于本领域的已知技术,同时不是本专利改进的重点,因而本实施采用已知技术保证供应链数据节点30的数据安全。
50.本实施例接入了多家银行,若甲加工厂需要申请40万元的贷款,则乙银行不会决定贷款。但丙银行更看重利润,因而在表1的基础上,其授信模型的第9项为:+利润*150%。同样的,供应链数据节点30的授信模型执行模块33,将甲加工厂的数据代入丙银行的授信模型得出的授信额度55为42万。因而在乙银行决定不贷款的情况下,丙银行决定进行贷款。
51.若还存在多家银行能够给予甲加工厂40万的贷款,则甲加工厂可以在这些银行中选择利率最低的银行去办理贷款。
52.在此过程中,甲加工厂的业务数据311没有泄露给任何一家银行,也没有单独去任何一家的银行柜台递交申请材料,全部由本供应链金融平台进行后台数据运算,就可以为甲加工厂提供其能够申请到贷款的多家银行,为其解决资金问题。
53.同时银行对其业务具有偏好,也不需要接收大量的琐碎的业务数据311,就可以知晓哪些企业40是其偏向于贷款的,即授信额度55高,哪些企业40是其偏向于保守的,即授信额度55低,为银行节省了大量的工作量。银行也无需进行数据的调查核实,加快了贷款业务的效率,保证了业务数据311的真实性。降低了贷款的风险,即降低电缆坏账率。同时本金融平台提供的数据存证模块32,将供应链企业40的数据进行了存证,当企业40赖账时,法院可根据存证数据显示的企业40利润,进行强制执行,进一步降低了坏账率,同时减少了银行维权的难度。
54.以上所述的实施例只是本发明的一种较佳的方案,并非对本发明作任何形式上的限制,在不超出权利要求所记载的技术方案的前提下还有其它的变体及改型。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1