一种金融类pdf扫描件的文本识别方法及装置与流程
1.本发明属于文本识别技术领域,更具体地说,涉及一种金融类pdf扫描件的文本识别方法及装置。
背景技术:
2.近年来,深度学习技术在图形图像、自然语言处理、自动驾驶等多个领域得到大量应用,且表现效果要明显优于传统方法。
3.在文本信息处理中,存在大量不同样式的图像。当前技术对于图像信息的提取仍存在许多问题。如需要大量的标注语料,需要海量的文字排列组合,需要不同字体和大小,图像的背景色和版面类型也多种多样,也有字体模糊,方向倾斜,水印等复杂情况。仅仅依赖于标注既依赖于大量人工,也容易出错,性价比较低。
技术实现要素:
4.1、要解决的问题
5.针对现有技术中在对pdf扫描件进行文本识别时图像信息难以提取且工作量大、容易出错的问题,本发明提供一种金融类pdf扫描件的文本识别方法及装置,利用模板创建技术有效解决了人工标注的费时低效的问题,并利用深度学习的最新成果进一步提升识别效果。
6.2、技术方案
7.为解决上述问题,本发明采用如下的技术方案。
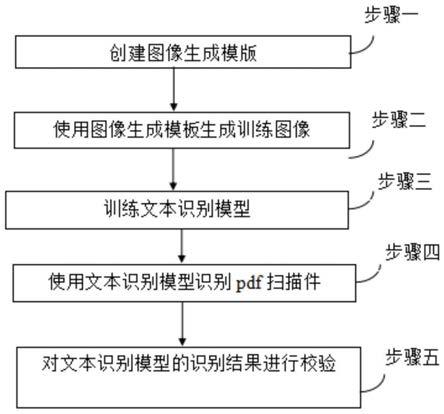
8.一种金融类pdf扫描件的文本识别方法,包括:
9.步骤1、创建图像生成模板;
10.步骤2、在图像生成模板中插入模板信息,使用图像生成模板生成训练图像;
11.步骤3、利用生成的训练图像作为训练数据,训练文本识别模型;
12.步骤4、使用文本识别模型识别pdf扫描件。
13.其优选的技术方案为:
14.如上所述的一种金融类pdf扫描件的文本识别方法,所述的模板信息包括版面、字体、背景以及水印样式。
15.如上所述的一种金融类pdf扫描件的文本识别方法,所述的模板信息来自于扫描件、非扫描件或随机生成。
16.如上所述的一种金融类pdf扫描件的文本识别方法,所述的文本识别模型包括:
17.文本倾斜度检测模型,用于检测整个图像页面的文本倾斜度,并对倾斜文本摆正;
18.文字检测模型,用于倾斜文本摆正后,检测每一行文字所在的文本框坐标;
19.文字识别模型,用于根据文本框坐标,识别文本框坐标所在文本框内的每一个文字;
20.文本结构化模型,用于把经文字识别模型识别的多行文字转化为结构化数据。
21.如上所述的一种金融类pdf扫描件的文本识别方法,步骤4之后,还包括:对文本识别模型的识别结果进行校验。
22.如上所述的一种金融类pdf扫描件的文本识别方法,所述文本识别校验包括:
23.步骤31、根据文本倾斜度检测模型的检测结果,对比文本倾斜度检测模型检测的文本倾斜度与实际角度的误差,若超过5
°
则判断为检测错误;
24.步骤32、根据文字检测模型的检测结果,对比文字检测模型检测的文本区域与实际区域的iou误差,若误差超过20%则判断为检测错误;
25.步骤33、根据文字识别模型的识别结果,对比文字识别模型识别的文字内容与实际内容是否一样,若不一样则判断为识别错误;
26.步骤34、根据文本结构化模型的处理结果,对比文本结构化模型生成的结构化数据与实际是否一样,若不一样则判断为结构化处理错误。
27.作为本技术的另一个方面还提供了一种实施如上任一项所述的一种金融类pdf扫描件的文本识别方法的装置,包括模板创建模块、训练图像生成模块、文本识别模型训练模块、文本识别服务模块、校验模块;
28.所述模板创建模块用于创建图像生成模板;
29.所述训练图像生成模块用于根据图像生成模板生成训练图像;
30.所述模型训练模块用于利用生成的训练图像作为训练数据,训练文本识别模型;
31.所述文本识别服务模块,用于根据训练好的文本识别模型识别pdf扫描件;
32.所述校验模块,用于对文本识别服务模块的识别结果进行校验。
33.其优选的技术方案为:
34.如上所述的装置,所述图像生成模板的模板信息来自于扫描件、非扫描件或随机生成。
35.3、有益效果
36.相比于现有技术,本发明的有益效果为:
37.(1)本发明在创建图像生成模板时,在图像生成模板上插入模板信息,其中,模板信息既可以来自于pdf扫描件,也可以来自于非扫描件或随机生成,从而保证训练前文本识别模型数据建立的全面性,为后续文本识别模型训练的文本识别准确率提供保障;
38.(2)本发明的文本识别模型在进行文本识别时,文本识别模型能够首先对训练图像中的文本进行检测,避免文本倾斜,再通过文字检测模型确定其中的文本框坐标,再基于文字识别模型识别文本框坐标所在文本框内的每一个文字;最后,通过文本结构化模型把经文字识别模型识别的多行文字转化为结构化数据,完成pdf扫描件的文本识别;本技术提出的金融类pdf扫描件的文本识别方法,无需大量人工标注,能够在字体模糊、方向倾斜、水印等复杂情况下实现对pdf扫描件的自动识别,且识别效率高,提高了pdf扫描件的识别准确率;
39.(3)本发明的文本识别模型在对使用图像生成模板生成的训练图像进行训练时,能够在文本识别模型的识别过程建立校检机制,针对文本倾斜度较大、iou误差较大以及识别文字不一致的情况建立校检标准,以能够使模型能够分别在方向倾斜、字体模糊、水印等复杂情况下实现对pdf扫描件的自动识别,为pdf扫描件的文本识别提供了一个新的解决方案,适用性能广,具有良好的使用前景。
附图说明
40.图1为本发明的一种金融类pdf扫描件的文本识别方法的流程图;
41.图2为本发明文本识别模型的架构示意图;
42.图3为本发明的文本识别校验的流程图;
43.图4为本发明的一种金融类pdf扫描件的文本识别装置的结构框图;
44.图中:1、模板创建模块;2、训练图像生成模块;3、文本识别模型训练模块;4、文本识别服务模块;5、校验模块。
具体实施方式
45.下面结合具体实施例和附图对本发明进一步进行描述。
46.实施例1
47.如图1~2所示,一种金融类pdf扫描件的文本识别方法,包括:
48.步骤1、创建图像生成模板。本实施例中,具体地,创建图像生成模板的目的在于能够在模板对各文本图像样本中的文本图像进行,得到各文本图像样本对应的扩充文本图像样本。
49.步骤2、在图像生成模板中插入模板信息,使用图像生成模板生成训练图像。
50.所述的模板信息包括版面、字体、背景以及水印样式。所述的模板信息来自于扫描件、非扫描件或随机生成。在步骤2中,使用模板与随机生成的文字,或者从其他数据源随机采样的文字,生成训练图像,并对图像进行模糊,旋转,加噪等操作,能够拟合真实场景的数据,完成样本扩充,从而保证训练前文本识别模型数据建立的全面性,为后续文本识别模型训练的文本识别准确率提供保障。
51.步骤3、利用生成的训练图像作为训练数据,训练文本识别模型。
52.本实施例中,具体而言,训练模型具体采用通用数据(如通过网络下载的文本图像和标签)训练的模型,例如ocr预训练模型。对ocr预训练模型而言,训练数据需要再100万张以上训练时间需要采用gpu训练一周,直至模型在测试集上的准确率达到95%以上后停止训练。
53.对所述ocr预训练模型而言,本实施例中,所述的ocr预训练模型包括:
54.文本倾斜度检测模型,用于检测整个图像页面的文本倾斜度,并对倾斜文本摆正;
55.文字检测模型,用于倾斜文本摆正后,检测每一行文字所在的文本框坐标;
56.文字识别模型,用于根据文本框坐标,识别文本框坐标所在文本框内的每一个文字;
57.文本结构化模型,用于把经文字识别模型识别的多行文字转化为结构化数据。
58.步骤4、使用文本识别模型识别pdf扫描件。
59.本发明的文本识别模型在进行文本识别时,文本识别模型能够首先对训练图像中的文本进行检测,避免文本倾斜,再通过文字检测模型确定其中的文本框坐标,再基于文字识别模型识别文本框坐标所在文本框内的每一个文字;最后,通过文本结构化模型把经文字识别模型识别的多行文字转化为结构化数据,完成pdf扫描件的文本识别;本技术提出的金融类pdf扫描件的文本识别方法,无需大量人工标注,能够在字体模糊、方向倾斜、水印等复杂情况下实现对pdf扫描件的自动识别,且识别效率高,提高了pdf扫描件的识别准确率。
60.实施例2
61.与实施例1基本相同。为了进一步保证对金融类pdf扫描件的文本识别的准确率和效率,本实施例中在训练文本识别模型时,步骤4之后,还包括:对文本识别模型的识别结果进行校验。如图3所示,所述文本识别校验包括:
62.步骤31、根据文本倾斜度检测模型的检测结果,对比文本倾斜度检测模型检测的文本倾斜度与实际角度的误差,若超过5
°
则判断为检测错误;
63.步骤32、根据文字检测模型的检测结果,对比文字检测模型检测的文本区域与实际区域的iou误差,若误差超过20%则判断为检测错误;
64.步骤33、根据文字识别模型的识别结果,对比文字识别模型识别的文字内容与实际内容是否一样,若不一样则判断为识别错误;
65.步骤34、根据文本结构化模型的处理结果,对比文本结构化模型生成的结构化数据与实际是否一样,若不一样则判断为结构化处理错误。
66.本实施例的文本识别模型在对使用图像生成模板生成的训练图像进行训练时,能够在文本识别模型的识别过程建立校检机制,针对文本倾斜度较大、iou误差较大以及识别文字不一致的情况建立校检标准,以能够使模型能够分别在方向倾斜、字体模糊、水印等复杂情况下实现对pdf扫描件的自动识别,为pdf扫描件的文本识别提供了一个新的解决方案,适用性能广,具有良好的使用前景。
67.实施例3
68.一种金融类pdf扫描件的文本识别装置,用于实施实施例1所述的一种金融类pdf扫描件的文本识别方法,如图4所示,包括模板创建模块1、训练图像生成模块2、文本识别模型训练模块3、文本识别服务模块4、校验模块5;
69.所述模板创建模块1用于创建图像生成模板,其中,所述图像生成模板的模板信息来自于扫描件、非扫描件或随机生成;
70.所述训练图像生成模块2用于根据图像生成模板生成训练图像;
71.所述模型训练模块用于利用生成的训练图像作为训练数据,训练文本识别模型;
72.所述文本识别服务模块4,用于根据训练好的文本识别模型识别pdf扫描件;
73.所述校验模块5,用于对文本识别服务模块4的识别结果进行校验。
74.本实施例提供的文本识别装置中,仅以上述各功能模块的划分进行举例说明,实际应用中,可以根据需要而将上述功能分配由不同的功能模块完成,即将装置的内部结构划分成不同的功能模块,以完成以上描述的全部或者部分功能。另外,本实施例的文本识别装置与上述实施例中的文本识别方法实施例属于同一构思,其具体实现过程和有益效果详见文本识别方法实施例,这里不再赘述。
75.本发明所述实例仅仅是对本发明的优选实施方式进行描述,并非对本发明构思和范围进行限定,在不脱离本发明设计思想的前提下,本领域工程技术人员对本发明的技术方案作出的各种变形和改进,均应落入本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1