一种智能互联网舆情预警与处置方法及系统与流程
1.本发明涉及舆情处理领域,具体涉及一种智能互联网舆情预警与处置方法及系统。
背景技术:
2.随着移动互联网、物联网等新技术得迅速发展,人类进入了数据时代,数据带来得信息风暴正在无时无刻得改变着我们得生活、工作以及思维方式,同时对互联网舆情管理也带来深刻影响。网络舆情具备传播速度快、传播范围广和突发性强的特点。全媒体时代,人人都有话语权,广大网民借助网络表达自己的意见和态度,当网民意见聚合时,网络舆论呈现爆炸式的增长。进行网络舆情监测,可以及时控制舆论进一步发酵,控制舆情。
技术实现要素:
3.鉴于现有技术中存在的技术缺陷和技术弊端,本发明实施例提供克服上述问题或者至少部分地解决上述问题的一种智能互联网舆情预警与处置方法及系统,旨在解决网络舆情的监控,控制负面新闻的进一步发酵,从而对舆情进行更加精准控制,具体方案如下:
4.一种智能互联网舆情预警与处置方法,所述方法包括:
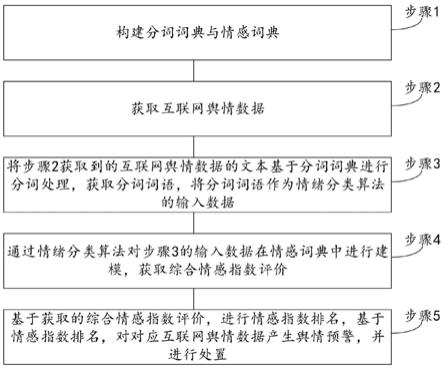
5.步骤1,构建分词词典与情感词典;
6.步骤2,获取互联网舆情数据;
7.步骤3,将步骤2获取到的互联网舆情数据的文本基于分词词典进行分词处理,获取分词词语,将分词词语作为情绪分类算法的输入数据;
8.步骤4,通过情绪分类算法对步骤3的输入数据在情感词典中进行建模,获取综合情感指数评价;
9.步骤5,基于获取的综合情感指数评价,进行情感指数排名,基于情感指数排名,对对应互联网舆情数据产生舆情预警,并进行处置。
10.进一步地,步骤1中,所述分词词典采用互联网开源的ik analyzer分词器构建;所述情感词典为利用已有电子词典扩展生成,具体为:利用pmi 互信息计算与左右熵来发现所需要的新词,将其添加到已有的情感词典,以对已有电子词典进行扩展。
11.进一步地,利用pmi互信息计算与左右熵来发现所需要的新词,将其添加到已有的情感词典具体为:
12.基于开源的情感词典情感种子词,计算分好词的语料中各个词语与情感种子词的互信息度与左右熵,再将互信息度与左右熵结合起来,选择出与情感种子词关联度最高的topn个词语,将其添加到对应的情感词典。
13.进一步地,步骤2中,获取互联网舆情数据具体为:
14.注册公众开放平台api调用及开发者账号;
15.申请消息接口,成为开发者,获取access_token;
16.调用message_api_start接口进行获取互联网舆情数据,并保存在存储设备中。
17.进一步地,步骤3中,采用逆向最大匹配法(rmm)对互联网舆情数据的文本进行分词处理。
18.进一步地,采用逆向最大匹配法(rmm)对互联网舆情数据的文本进行分词处理具体为:
19.先设置一个k值,然后从互联网舆情数据文本的最后一个字开始向前截取k个字,先把这k个字和步骤1产生的分词字典进行匹配,确定能否找到匹配的词语,若不能,则剔除这k个字最左边的字,然后再把这k-1个字与分词字典匹配,依次类推,一直到匹配成功,或者前k-1个字都没匹配成功,则将第k个字当成一个独立的词,然后再向前移动分出来的词的长度,再截取k个字,依次类推,一直到全部文本分好词为止。
20.进一步地,通过情绪分类算法对步骤3的输入数据进行建模,获取综合情感指数评价具体为:
21.通过情绪分类算发逐个遍历分词后的语句中的词语,如果词语命中情感词典,则基于词语的性质进行相应权重的处理,获取综合情感指数评价,具体为:对正面性质的词语的权重做加法处理,负面性质的词语的权重做减法处理,否定性质的词语的重取相反数处理,程度副词性质的词语的权重则和对应修饰的词语权重做相乘处理。
22.作为本发明的第二方面,提供一种智能互联网舆情预警与处置系统,所述系统包括词典构建模块、舆情获取模块、分词模块、综合评价模块以及预警模块。
23.所述词典构建模块用于构建分词词典与情感词典;
24.所述舆情获取模块用于获取互联网舆情数据;
25.所述分词模块用于将获取到的互联网舆情数据的文本基于分词词典进行分词处理,获取分词词语,将分词词语作为情绪分类算法的输入数据;
26.所述综合评价模块用于通过情绪分类算法对输入数据在情感词典中进行建模,获取综合情感指数评价;
27.所述预警模块用于基于获取的综合情感指数评价,进行情感指数排名,基于情感指数排名,对对应互联网舆情数据产生舆情预警,并进行处置。
28.进一步地,所述分词词典采用互联网开源的ik analyzer分词器构建;所述情感词典为利用已有电子词典扩展生成,具体为:利用pmi互信息计算与左右熵来发现所需要的新词,将其添加到已有的情感词典,以对已有电子词典进行扩展。
29.进一步地,采用逆向最大匹配法(rmm)对互联网舆情数据的文本进行分词处理。
30.本发明具有以下有益效果:
31.本发明基于文本情感分析,提供一种互联网舆情分析方法,旨在解决网络舆情的监控,控制负面新闻的进一步发酵,从而对舆情进行更加精准控制。
附图说明
32.图1为本发明实施例提供的一种智能互联网舆情预警与处置方法流程示意图。
具体实施方式
33.下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分,而不是全部的实施例。基于本发明
中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其它实施例,都属于本发明保护的范围。
34.如图1所示,为本发明实施例提供的一种智能互联网舆情预警与处置方法,所述方法包括:
35.步骤1,构建分词词典与情感词典;
36.构建分词词典:采用开源ik analyzer分词器,分词器存储结构如下表:
[0037][0038][0039]
构建情感词典:情感词典的构建主要是通过将目前开源的情感词典整合起来,筛去重复和无用的单词,目前网上开源的情感词典包含有:知网 (hownet)情感词典、台湾大学(ntsusd)简体中文情感极性词典、大连理工大学情感词汇本体,由于上述情感词典年代都已经比较久远,所以我们可以采取一定方法对其扩展。这里我们采用的方法是将词典的同义词添加到词典里,构建互联网舆情领域的情感词典需要利用pmi互信息计算与左右熵来发现所需要的新词。
[0040]
简单的说,如果一个词和积极的词语一起出现的频率高,那么这个词是积极倾向的可能性也会大,反之亦然。所以,只要计算一个词和积极词出现的频率和消极词出现的频率之差,并设定某个阈值,就可以粗略的得知这个词的情感倾向了;
[0041]
体方法我们可以基于网上开源的情感词典情感种子词,来计算分好词的语料中各个词语与情感种子词的互信息度与左右熵,再将互信息度与左右熵结合起来,选择出与情感词关联度最高的topn个词语,将其添加到对应的情感词典。
[0042]
其中互信息度公式为;
[0043][0044]
其中,p(x,y)为两个词一起出现的概率,p(x)为词x出现的概率,p(y) 为词y出现的概率;
[0045]
例如:4g,上网卡,4g上网卡;如果4g的词频是2,上网卡的词频是10,4g 上网卡的词频是1,那么记单单词的总数有n个,双单词的总数有m个,则有下面的公式:
[0046][0047]
其中,左右熵来衡量主要是想表示预选词的自由程度(4g上网卡为一个预选词),左右熵越大,表示这个词的左边右边的词换的越多,那么它就很有可能是一个单独的词。
[0048]
左右熵定义为(以左熵为例):
[0049][0050]
假设4g上网卡左右有这么几种搭配:[买4g上网卡,有4g上网卡,有 4g上网卡,丢4g上网卡],那么4g上网卡的左熵为:
[0051]-e
l
(4g上网卡)=p(买4g上网卡|)log2p(有4g上网卡)+p(有4g上网卡|)log2p(买4g上网卡) +p(丢4g上网卡|)log2p(丢4g上网卡)
[0052]
最后我们只需要对应的结果完善到相应情感词典进行整合就可以了。情感词典库格式如下表:
[0053]
性质词语权重正面词语11.75正面词语21.75正面词语31.2正面词语41.75负面词语52负面词语61.75负面词语75程度副词词语82程度副词词语91.7程度副词词语101否定词词语111否定词词语121.........
[0054]
步骤2:获取互联网舆情数据;
[0055]
以新浪微博为例,具体包括:
[0056]
步骤2.1:注册新浪微博公众开放平台api调用及开发者账号
[0057]
步骤2.2:申请消息接口,成为开发者,获取access_token
[0058]
步骤2.3:调用http://open.weibo.com/message_api_start接口进行获取互联网舆情数据,保存在存储设备中。
[0059]
步骤3:采用逆向最大匹配法(rmm)对互联网舆情数据进行分词;
[0060]
其原理是事先设置一个k值,然后从最后一个字开始向前截取k个字,先把这k个字和步骤一产生的分词字典进行匹配,看能否找到匹配的词语,若不能,则剔除这k个字最左边的字,然后再把这k-1个字与字典匹配... 一直到匹配成功,或者前k-1个字都没匹配成功,那就把第k个字当成一个独立的词,然后再向前移动分出来的词的长度,再截取k个
字......一直到全部文本分好词为止。
[0061]
例如:【热点】农村土地,城市气温创新低,邀约事件
[0062]
设置k为2,那么获取“【热点】农村土地,城市气温创新低,邀约事件”为:
[0063]
/【/热点/】/农村/土地/,/城市/气温/创/新低,/邀约/事件
[0064]
最后获取关键词为:热点、农村、土地、城市、气温、新低、邀约、事件。
[0065]
步骤4:将步骤3产生的分词在情感词典进行建模,输出综合情感指数评价;
[0066]
具体为:逐个遍历分词后的语句中的词语,如果词语命中分词词典或情感词典,则进行相应权重的处理,正面词权重为加法,负面词权重为减法,否定词权重取相反数,程度副词权重则和它修饰的词语权重相乘
[0067]
步骤五:产生预警并进行处置
[0068]
由于步骤4已经获取到语句情感的权重,将情感语句分为正面、负面、和中性三个维度
[0069]
其中权重》2为正面,2≥权重≥-2为中性,权重《-2为负面
[0070]
由此可得“【热点】农村土地,城市气温创新低,邀约事件”的性质,将产生舆情预警数据推送到消息中心并进行预警处置。
[0071]
作为本发明的第二实施例,提供一种智能互联网舆情预警与处置系统,所述系统包括词典构建模块、舆情获取模块、分词模块、综合评价模块以及预警模块。
[0072]
所述词典构建模块用于构建分词词典与情感词典;
[0073]
所述舆情获取模块用于获取互联网舆情数据;
[0074]
所述分词模块用于将获取到的互联网舆情数据的文本基于分词词典进行分词处理,获取分词词语,将分词词语作为情绪分类算法的输入数据;
[0075]
所述综合评价模块用于通过情绪分类算法对输入数据在情感词典中进行建模,获取综合情感指数评价;
[0076]
所述预警模块用于基于获取的综合情感指数评价,进行情感指数排名,基于情感指数排名,对对应互联网舆情数据产生舆情预警,并进行处置。
[0077]
以上所述仅为本发明的较佳实施例,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1