基于表路由分片引擎的InfluxDB分布式集群方法与流程
本发明涉及应用于使用influxdb作为时序数据存储底座的各领域,如运营商业务支撑系统boss(business&operationsupportsystem)领域,物联网iot(internetofthings)和其具有海量指标的监控业务领域,具体来说,涉及基于表路由分片引擎的influxdb分布式集群方法。
背景技术:
随着云化、容器化、分布式微服务的技术和架构持续演进,物联网的持续进化;应用实例和各种被监控对象的数量都以指数级增长,现代应用系统的性能,可用性等kpi数据都具有两个明显的特征:
1、系统kpi(keyperformanceindicator)的数据具备时序型数据特征。
2、指标量都是海量级别。为了能够对当前的应用做更好的监控。监控平台首要的需求是能够存储海量的时序型数据,并具备高效的读写和水平扩展能力。
目前对于时序型数据库,业界比较知名的有influxdb、kdb+、prometheus、graphite、rrdtool、opentsdb。并且从2016年开始influxdb一直占据榜首的位置。
influxdb具备如下优势:安装便捷,无依赖;中等配置的机器支持每秒25万+数据写入[cpu:4-6核,内存:8-32g,iops(input/outputoperationspersecond,磁盘每秒操作数):500-1000];原生支持httpapi(超文本传输协议接口),更易对接和扩展,并提供各语言的sdk(softwaredevelopmentkit,软件开发工具包);类sql(structuredquerylanguage,结构化查询语言)查询语言,以时间为中心的函数,学习成本更低,更易学习掌握和实施;查询响应迅速(100ms以内);支持联系查询和不同的存储策略,能够快速的采样和分级存储能力。
虽然influxdb能够快速便捷的应对绝大部分的业务场景,但influxdb原生不支持多副本写入能力,在磁盘损坏的情况下,数据容易丢失。不支持分布式集群能力,导致influxdb在应对海量指标存储和高性能读写需求时,变得束手无策,无法支撑。
在落地案例中,对于常规的机械硬盘(7200转),接入3153主机,每30秒采集一次主机性能指标数据,30分钟数据量:8951551时,influxdb实例所在的主机磁盘繁忙程度达到了83%,无法再支撑更多的写入请求了。
针对相关技术中的问题,目前尚未提出有效的解决方案。
技术实现要素:
针对相关技术中的问题,本发明提出基于表路由分片引擎的influxdb分布式集群方法,以克服现有相关技术所存在的上述技术问题。
为此,本发明采用的具体技术方案如下:
基于表路由分片引擎的influxdb分布式集群方法,该方法包括以下步骤:
s1、通过influxdb中间件代理提供基于influxdb标准超文本传输协议的支持;
s2、将influxdb的服务与外部进行对接,并链接地址配置信息,且全部配置为influxdb中间件代理提供的代理服务地址和端口;
s3、基于元数据管理,对表和influxdb分组实例的关联关系进行配置;
s4、若外部请求发起写操作时,则influxdb中间件代理对influxdb的标准行协议数据进行接收;
s5、若外部发起非写操作时,influxdb中间件代理对非写操作命令进行接收,且通过influxdb中间件代理的结构化查询语言解析器,解析外部的操作命令,并按操作类型进行区分。
进一步的,所述s1、s2、s4及s5中的influxdb中间件代理为无状态可水平扩展的服务,若面对海量指标数据时,前端增加负载均衡器实现水平扩展能力。
进一步的,所述s4中发起写操作之前还包括以下步骤:
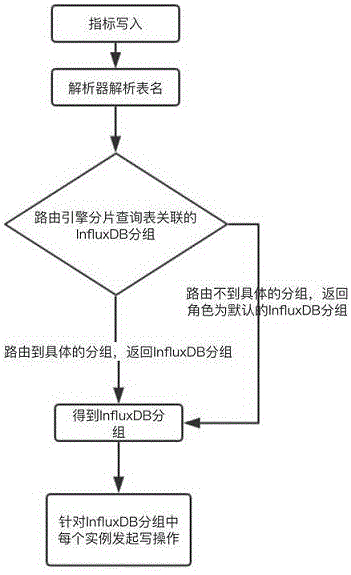
influxdb中间件代理的写解析器基于influxdb行协议的规则,并通过语法树,解析出influxdb的表信息;
路由引擎根据表信息,查询元数据配置的关联关系;
若查询到表与分组的配置关系,则返回此分组内所有influxdb实例。
进一步的,若未查询到表与分组的配置关系,则返回默认分组内的所有influxdb实例。
进一步的,所述s4中外部请求发起写操作时,influxdb分组内有若干influxdb实例,写入动作次数与influxdb实例数量相同。
进一步的,所述s5中按操作类型进行区分时,操作类型包括元数据的创建和删除、查看元数据的操作命令、查看包括所有表信息聚合操作命令及influxdb的数据查询操作。
进一步的,所述元数据的创建和删除还包括以下步骤:
influxdb中间件代理的路由分片引擎,返回所有influxdb实例,并发起操作,使得整个集群中数据库及存储策略保持一致;
当用户调整路由规则时进行无缝调整,并返回其中之一的执行结果。
进一步的,所述查看元数据的操作命令还包括以下步骤:
influxdb中间件代理的路由分片引擎,返回默认分组中的一个influxdb实例进行操作,并返回结果。
进一步的,所述查看包括所有表信息聚合操作命令还包括以下步骤:
influxdb中间件代理的路由分片引擎,返回每个分组中的一个influxdb实例;
influxdb中间件代理发起对每个实例的操作,且把结果进行聚合,并返回。
进一步的,所述influxdb的数据查询操作还包括以下步骤:
influxdb中间件代理的分片路由引擎,解析influql语法树,并解析出操作的表;
该路由分片引擎,查询到表与分组的关系,若存储则返回其分组中的一个influxdb实例;
若没有查询到表与分组的关系,则返回默认角色influxdb分组中的一个实例;
该路由分片引擎根据influxdb实例,进行查询操作,并返回结果数据。
本发明的有益效果为:
(1)本发明采用influxdb分布式集群方案,对外部完全透明,完备的支持influxdb各标准协议,外部原始的influxdb访问方式可以直接对接到influxdb分布式集群,实现分布式集群能力,而不需做任何改造。
(2)本发明采用influxdb分布式集群方案,提供了多实例服务的容灾能力,减少数据丢失的风险;同时提供分布式路由和分片能力,以多实例多分组influxdb集群的形式来提供指标数据库服务,大大提升了influxdb的指标承载能力,稳定性和性能。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1是根据本发明实施例的基于表路由分片引擎的influxdb分布式集群方法流程图之一;
图2是根据本发明实施例的基于表路由分片引擎的influxdb分布式集群方法的流程图之二;
图3是influxdb分布式集群的整体架构图。
具体实施方式
为进一步说明各实施例,本发明提供有附图,这些附图为本发明揭露内容的一部分,其主要用以说明实施例,并可配合说明书的相关描述来解释实施例的运作原理,配合参考这些内容,本领域普通技术人员应能理解其他可能的实施方式以及本发明的优点,图中的组件并未按比例绘制,而类似的组件符号通常用来表示类似的组件。
根据本发明的实施例,提供了基于表路由分片引擎的influxdb分布式集群方法,influxdb本身在时序领域一直处于领先地位,但influxdb开源版本仅支持单节点。本发明可有效应对当前以influxdb作为时序数据存储服务,所带来的存储性能和容灾的限制。本发明基于中间件代理的模式,以表为分片规则,支持查询,写入,元数据管理等各操作,协议保持与influxdb一致,面向业务完全透明,支持各开源产品的无缝对接。表分片的最大限制是单表数据量,经压测,单influxdb节点(8c+64g-ssd硬盘),可支持15000+主机的性能指标数据,能够满足99%以上的业务场景。
本发明的方案在于如何面向业务透明提供分布式解决方案。所述的面向业务透明,需要提供一种类似于中间件influxdb代理服务,服务的协议遵守influxdb的标准协议。所述的influxdb的中间件代理服务,需要支持标准的influxdb协议,通过支持influxdb的标准http协议代理,来满足代理转发服务。并需要支持通用的influxdb操作的路由分发。所述的支持通用的influxdb操作路由分发,就需要支持influxdb的元数据管理,数据查询,和数据写入能够被正确解析,分发和执行。所述的influxdb元数据管理,数据查询,和数据写入操作的服务解析执行,和路由转发。针对元数据管理,如存储策略增删改,建库需要在整个集群上进行执行;针对查询,核心是对sql的解析路由到指定服务;针对写入,核心是针对influxdb行协议的解析,分析出表名,进一步路由到集群分组中。从而完成对整个influxdb的操作支持按表的规则引擎分布式集群方案。
现结合附图和具体实施方式对本发明进一步说明,如图1-3所示,根据本发明实施例的基于表路由分片引擎的influxdb分布式集群方法,该方法包括以下步骤:
s1、influxdb中间件代理(influxdb中间件代理统称为:metrics)提供基于influxdb标准http协议的支持;
s2、外部对接influxdb的服务,链接地址配置信息,全部配置为metrics提供的代理服务地址和端口;metrics为无状态可水平扩展的服务,当面对海量指标数据时,前端可以增加负载均衡器如nginx(是一个高性能的http和反向代理服务器)来实现水平扩展能力;
s3、基于元数据管理,配置表和influxdb分组实例的关联关系,如kpi_xxx对应分组a,kpi_yyy对应分组b。同时influxdb的逻辑分组中有默认分组角色;
s4、当外部请求发起写操作时,metrics接收到influxdb的标准行协议数据,格式如:
<measurement>[,<tag_key>=<tag_value>[,<tag_key>=<tag_value>]]<field_key>=<field_value>[,<field_key>=<field_value>][<timestamp>]
数据举例:mymeasurement,tag1=value1,tag2=value2fieldkey="fieldvalue"1556813561098000000;
metrics的写解析器基于influxdb行协议的规则,通过语法树,解析出influxdb的表(measurement)信息。路由引擎,根据表信息,查询元数据配置的关联关系;如果查询表与分组的配置关系,返回此分组内所有influxdb实例,如果未查询到,将返回默认分组内的所有influxdb实例。发起写操作,实现指标数据的分布式存储能力,influxdb分组内可以有一个,或多个influxdb实例,几个实例发起几次写入动作,使指标数据可以具备多副本容灾的能力;
s5、当外部发起非写操作时,metrics接收到非写操作命令;metrics的sql解析器,解析外部的操作命令,按操作类型进行区分。
1、对于元数据的创建和删除,如创建库、创建存储策略,删除库、删除存储策略(createdatabase"db_name"),metrics的路由分片引擎会返回所有influxdb实例,发起操作,使得整个集群中数据库,存储策略保持一致,当用户调整路由规则时能够无缝调整;并返回其中之一的执行结果。
2、对于查看元数据的操作命令,如:showcontinuousqueries,showdatabases,metrics路由分片引擎仅返回默认分组中的一个influxdb实例进行操作并返回结果。
3、对于查看某个库下面所有表信息等聚合操作命令,metrics路由分片引擎,返回每个分组中的一个influxdb实例,metrics发起对每个实例的操作,并把结果进行聚合,然后返回。
4、对于influxdb的数据查询操作,metrics分片路由引擎,首先解析influql语法树,解析出操作的表。路由分片引擎,再进一步查询到表与分组的关系,如果存储返回其分组中的一个influxdb实例;如果没有查询到表与分组的关系,返回默认角色influxdb分组中的一个实例;路由引擎根据influxdb实例,进行查询操作,并返回结果数据。
综上,可以看出,因为做到的完全透明的实现方案,基于原始对接influxdb的场景可以快速的对接到influxdb分布式集群中,以高可用高性能实施方案举例,方法如下:
步骤一,系统整合nginx网关,nginx网管在xxx.xxx.80.26端口80,代理负载均衡分布式中间件服务metrics,metrics实例启动5个(根据实际的压力来部署实例数)。
upstreamzcm_metrics{
serverxxx.xxx.80.1:52503;
serverxxx.xxx.80.2:52504;
serverxxx.xxx.80.3:52505;
serverxxx.xxx.80.4:52506;
serverxxx.xxx.80.5:52507;
}
配置对外influxdb的标准服务:
#zcm-metrics
location^~/query{
proxy_passhttp://zcm_metrics/query;
}
location^~/write{
proxy_passhttp://zcm_metrics/write;
}
location^~/ping{
proxy_passhttp://zcm_metrics/ping;
}
步骤二,用户通过bs方式(web浏览器方式)访问元数据配置管理服务,配置influxdb实例信息,配置influxdb的逻辑分组,必须制定一个默认分组;
步骤三,用户通过bs方式,访问元数据配置管理服务,配置表与influxdb逻辑分组的映射关系;
步骤四,客户端程序或第三方的服务,原对接influxdb的地址服务修改为连接influxdb分布式集群提供的服务地址,原地址为:http://xxx.xxx.17.11:8586/修改为:http://xxx.xxx.80.26:80/;
发起基本的操作,对业务和外部操作全部透明,完成产品对接。
综上所述,本发明采用influxdb分布式集群方案,对外部完全透明,完备的支持influxdb各标准协议,外部原始的influxdb访问方式可以直接对接到influxdb分布式集群,实现分布式集群能力,而不需做任何改造。本发明采用influxdb分布式集群方案,提供了多实例服务的容灾能力,减少数据丢失的风险;同时提供分布式路由和分片能力,以多实例多分组influxdb集群的形式来提供指标数据库服务,大大提升了influxdb的指标承载能力,稳定性和性能。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!