水上目标识别方法、装置、终端设备及存储介质与流程
1.本技术属于视觉检测技术领域,尤其涉及一种水上目标识别方法、装置、终端设备及存储介质。
背景技术:
2.传统的船只水面感知技术主要依靠船只上搭载的毫米波雷达、激光雷达和惯性测量单元、全球定位系统(global positioning system,gps)等传感器。近年来计算机视觉技术发展迅速,视频流包含更丰富的目标物体细节信息,故基于视觉的感知技术更易于对水面上的目标物体进行有效地识别。
3.现有技术在对视频流进行目标识别时,通常是将每帧的目标识别视为独立事件,容易造成漏检。
技术实现要素:
4.本技术实施例提供了一种水上目标识别方法、装置、终端设备及存储介质,以解决现有目标识别方法容易造成漏检的问题。
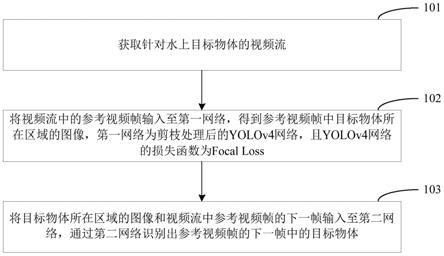
5.第一方面,本技术实施例提供了一种水上目标识别方法,所述水上目标识别方法包括:
6.获取针对水上目标物体的视频流;
7.将所述视频流中的参考视频帧输入至第一网络,得到所述参考视频帧中目标物体所在区域的图像,所述第一网络为剪枝处理后的yolov4网络,且所述yolov4网络的损失函数为focal loss;
8.将所述目标物体所在区域的图像和所述视频流中所述参考视频帧的下一帧输入至第二网络,通过所述第二网络识别出所述参考视频帧的下一帧中的所述目标物体。
9.第二方面,本技术实施例提供了一种水上目标识别装置,所述水上目标识别装置包括:
10.视频流获取模块,用于获取针对水上目标物体的视频流;
11.视频帧输入模块,用于将所述视频流中的参考视频帧输入至第一网络,得到所述参考视频帧中目标物体所在区域的图像,所述第一网络为剪枝处理后的yolov4网络,且所述yolov4网络的损失函数为focal loss;
12.目标识别模块,用于将所述目标物体所在区域的图像和所述视频流中所述参考视频帧的下一帧输入至第二网络,通过所述第二网络识别出所述参考视频帧的下一帧中的所述目标物体。
13.第三方面,本技术实施例提供了一种终端设备,包括存储器、处理器以及存储在所述存储器中并可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现如上述第一方面所述水上目标识别方法的步骤。
14.第四方面,本技术实施例提供了一种计算机可读存储介质,所述计算机可读存储
介质存储有计算机程序,所述计算机程序被处理器执行时实现如上述第一方面所述水上目标识别方法的步骤。
15.第五方面,本技术实施例提供了一种计算机程序产品,当所述计算机程序产品在终端设备上运行时,使得所述终端设备执行如上述第一方面所述水上目标识别方法的步骤。
16.由上可见,本技术在获取针对水上目标物体采集的视频流之后,可以先将视频流中的参考视频帧输入至第一网络,得到参考视频帧中目标物体所在区域的图像,再将目标物体所在区域的图像和视频流中参考视频帧的下一帧输入至第二网络,可以通过第二网络识别出参考视频帧的下一帧中的目标物体。本技术在基于第二网络识别参考视频帧的下一帧中的目标物体时,使用到目标物体在参考视频帧中的信息,即使用到目标物体的上下文动态信息,而不是将每帧的目标识别视为独立事件,可以改善目标物体的漏检问题。另外,本技术中的第一网络为剪枝处理后的yolov4网络,且该yolov4网络的损失函数为focal loss,通过该yolov4网络能够减少计算量,提高目标识别的运算速度,提升对部分较难识别的目标物体的识别能力。
附图说明
17.为了更清楚地说明本技术实施例中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本技术的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
18.图1是本技术实施例一提供的水上目标识别方法的实现流程示意图;
19.图2是本技术实施例二提供的水上目标识别方法的实现流程示意图;
20.图3a是参考视频帧的示例图;
21.图3b是图3a所示参考视频帧中的目标物体所在区域的图像;
22.图3c是图3b所示目标物体的掩模图像;
23.图3d是图3b所示目标物体所在区域的图像的h分层的示例图;
24.图3e是图3b所示目标物体所在区域的图像的s分层的示例图;
25.图3f是图3b所示目标物体所在区域的图像的v分层的示例图;
26.图3g是图3d所示h分层中目标物体在各颜色的像素点数量的示例图;
27.图3h是图3e所示s分层中目标物体在各颜色的像素点数量的示例图;
28.图3i是图3f所示v分层中目标物体在各颜色的像素点数量的示例图;
29.图4是本技术实施例三提供的水上目标识别装置的结构示意图;
30.图5a是在湖边码头的场景下进行目标识别测试的示例图;
31.图5b是在湖边码头的场景下进行目标识别测试的另一示例图;
32.图5c是在内河水域的场景下进行目标识别测试的示例图;
33.图5d是在内河水域的场景下进行目标识别测试的另一示例图;
34.图5e是在入海口的场景下进行目标识别测试的示例图;
35.图5f是在入海口的场景下进行目标识别测试的另一示例图;
36.图5g是在无人机航拍的场景下进行目标识别测试的示例图;
loss。
51.终端设备在将参考视频帧输入至第一网络之后,第一网络可以输出参考视频帧中目标物体的第一目标框位置。第一目标框中的图像即为参考视频帧中目标物体所在区域的图像。
52.其中,参考视频帧中需存在目标物体,以通过第一网络检测出参考视频帧中目标物体所在区域的图像,并将参考视频帧中的目标物体所在区域的图像作为目标物体的模板,通过第二网络进行后续视频帧中目标物体的识别,实现目标物体的精准跟踪。目标物体可以是视频帧中的任一物体,例如船只、航标、浮木等。
53.在一个实施例中,终端设备可以先将视频流中的首帧输入至第一网络,若通过第一网络检测到首帧中存在目标物体,则可以确定首帧为参考视频帧;若通过第一网络检测到首帧中不存在目标物体,则可以将首帧的下一帧输入至第一网络,通过第一网络检测首帧的下一帧中是否存在目标物体,直到检测到存在目标物体的视频帧,该视频帧即为参考视频帧。
54.以终端设备为边缘计算平台为例,第一网络和第二网络均可运行在边缘计算平台上。在第一网络和第二网络运行在边缘计算平台上之前,可以先在高性能计算机上对第一网络和第二网络进行训练,该训练可以基于稳定高效的pytorch深度学习框架完成。在训练完成后,可以将训练后的网络由pytorch深度学习模型转化为tensorrt深度学习模型,部署至边缘计算平台,实现船载的离线实时运行。
55.在对第一网络和第二网络进行训练时,需要先构建训练数据集。在构建训练数据集时,可以分为四个步骤。步骤一:获取面向水面上漂浮的树桩、浮木、水草、航标、漂流垃圾、人和船只等水上目标的原始数据;步骤二:对获取的原始数据进行第一预处理,以去除重复度较高、成像质量较差的数据;步骤三:对第一预处理后的数据进行标注;步骤四:对标注后的数据进行增广操作,以增加数据集中数据的数量。
56.原始数据可以通过如下至少一种方式获取:
57.(1)开源数据集获取。例如存在较多船舶和人员类的图像的ms coco数据集。可以根据网络训练的实际需求,对ms coco数据集进行筛选,保留满足海边人员这一特征的图像和形貌明显的船舶图像。
58.(2)生活取景。诸如树桩、浮木、水草等类别的目标物体在公开网络上极难获取,故可以通过对水边或水面的此类目标物体进行拍摄,并对拍摄获得的图像进行去重处理。
59.(3)船只实时传输。可以在某些海域进行大量的水面船只实验,在实验期间获取船只上的视频传感器采集图像。
60.(4)网络爬图。为了弥补某些类别(例如假人和渔网等类别)的不足,可以采用多线程爬图的方式,以百度、必应、谷歌、搜狗等各大搜索引擎为支点,爬取大量的网络图片。通过网络爬图获得的数据质量层次不齐,需要进一步进行数据的清洗、去重和筛选等处理。
61.对原始数据的第一预处理可以包括如下方式中的至少一种:
62.(1)抽帧。船只实时传输的通常为长段视频数据(即帧数较多的视频流),而在视频数据中通常存在场景和目标物体的位置均较为相似的视频帧,故可以对视频数据进行抽帧处理,以对视频数据中的视频帧进行去重处理。在对视频数据进行抽帧处理时,可以采用等距采样的方法,如每隔25帧采集一张图片。可选地,可根据实际数据的相似性和对数据量的
需求选择需间隔的帧数。
63.(2)去重。通过各种来源得到的数据集可能会产生重复图像,可以采用结构相似性(structural similarity,ssim)算法来做相似性分析。通过对亮度、对比度、结构三个角度的综合对比得到两幅图像的相似度数值。根据ssim算法得到的结构相似性,去除了相似度80%以上的图像。通过排除视频中获取的大量结构相似的图像,整体数据库的图像质量和有效性得到了提升。
64.(3)ps处理和筛选。对部分敏感数据,或附带水印以至于影响图像分辨的图像,可考虑进行photoshop处理。通过筛选可以剔除一些网络爬图获取的跟目标类别无关的图像;剔除一些像素过低、模糊不清的图像;剔除包含目标类别,但不符合水上目标识别场景的图片;剔除包含目标类别,但拍摄角度较差难以标注的图片。
65.在预处理后的数据进行标注,可以包括在图像中运用边界框(bounding box)将感兴趣的目标物体框出,并提取目标框的位置、类别等。
66.为了提高标注效率,本技术可以采用智能标注(human
‑
in
‑
the
‑
loop)方法,对第一预处理后的数据进行标注。智能标注方法的流程为:人工标注、训练网络、根据阶段性网络模型的预测结果由人工修改标注、人工审核、循环上述过程直到形成最终数据集。具体包括:
67.(1)人工标注。前期需要人工标注图片至3000张左右,作为初始数据集。
68.(2)根据初始数据集,训练深度学习网络算法,得到神经网络模型(即第一网络或者第二网络)。
69.(3)根据智能标注方法的流程中的(2)得到的神经网络模型预测下一批未标注的数据。
70.(4)人工对智能标注方法的流程中的(3)预测的数据标签进行修改、审核,得到扩展后的数据集。
71.(5)重复智能标注方法的流程中的(2)至(4)的过程,直到预处理后的数据全部标注完毕。
72.如表1所示是智能标注与传统标注的标注实例。传统标注是指数据集中的数据全部使用人工标注。
73.表1智能标注与传统标注的标注实例
[0074][0075]
在本次标注实例中,有八名人员参与数据标注工作,前期使用传统标注方法,标注速度较慢,且容易漏标,约50天时间有效标注了2913次。而后期使用智能标注方法进行标注,约20天时间标注了4127次,标注效率提升了3.5倍左右。
[0076]
上述增广操作可以是指对标注后的数据进行一定的形变转化。在对数据进行增广操作时,可以使用旋转、缩放、裁剪、添加噪声等手段;也可以使用mosaic数据增广方法,即
使用多张图像(典型值为4张)拼接成一张完整的图像,作为新的数据用于训练。可选地,在构建训练数据集时,还可以将空白标签的图像加入训练数据集,以改善部分误识别现象。针对在特殊天气采集的图像,可以进行直方图正规化图像增强。
[0077]
其中,上述剪枝处理可以是指在保持现有的yolov4网络的输入模块、特征处理器和预测层不变的情况下,减少现有的yolov4网络中特征提取层的规模,以提高网络算法的运算速度。例如,现有的yolov4网络的特征提取层包括73个卷积层,本技术通过对现有的yolov4网络进行剪枝处理,可以减少现有的yolov4网络的特征提取层的卷积层数量,使得剪枝处理后的yolov4网络的特征提取层包括60个卷积层,减少了卷积运算量。另外,本技术的yolov4网络中的损失函数为focal loss,可以提升对部分较难识别的目标物体的识别能力。
[0078]
本技术的yolov4网络的训练过程如下:
[0079]
步骤一:对训练数据集进行第二预处理。具体包括将输入的图像转换为三维矩阵,归一化其灰度值,针对平均灰度值低于灰度值阈值(例如120)的图像使用直方图正规化的方式进行图像增强。
[0080]
步骤二:初始化yolov4网络的计算图。具体包括对yolov4网络的各层结构和参数,载入预训练的原始网络权重。
[0081]
步骤三:将数据分批次输入网络,得到预测框。具体包括将输入图像的矩阵经过卷积层、池化层的层层处理,得到最终的特征图,再运用锚框方法在特征图中滑动获取大量目标框,随后运行非极大抑制方法去除相似的目标框,最终根据置信度选取可能性较大的目标框(即预测框)。
[0082]
步骤四:根据预测框和真值框计算损失值,再根据梯度信息反向优化网络参数。具体包括将预测框与提前标注的真值框进行交并比计算得到损失值,根据神经网络的反向传播算法计算梯度信息,根据梯度信息反向层层优化网络参数。
[0083]
步骤五:重复步骤三至步骤四,直到网络收敛。通常是在损失值长期保持稳定的情况下,网络充分收敛。
[0084]
步骤六:根据步骤五得到的最终模型,评估其在测试集上的平均准确率。例如,可以设置交并比阈值为0.5,将预测框与真值框重合度达到50%以上的视为正确预测,以此计算精准率(precision)和召回率(recall),根据精准率和召回率绘制p
‑
r曲线,计算p
‑
r曲线下围成的面积,该面积即为识别出的类别的准确率。综合所有类别的准确率,可以得到平均准确率。
[0085]
本技术通过将本技术的yolov4网络与现有的网络进行对比,可以确定本技术的yolov4网络的运算速度较快,且预测准确率较高。其中,运算速度是指每秒处理帧数(frames per second,fps)。上述现有的网络包括快速区域卷积神经网络(faster region
‑
convolution neural network,faster r
‑
cnn)、单步多框检测器(single shot multibox detector,ssd)、yolov3网络、现有的yolov4网络等。
[0086]
表2各网络在水上目标检测数据集上的测试性能对比
[0087][0088]
由表2中各网络的测试性能对比可知,本技术的yolov4网络可以取得69.13fps的运算速度和81.74%的预测准确率,其在目标识别时的运算速度和预测准确率均高于现有的网络。
[0089]
本技术的yolov4网络,能够通过视觉传感器获得的视频流,在船只的水上在0
‑
2级海况条件下,10米距离内,目标物体的识别准确率达到80%以上,充分满足船只实时运转要求。
[0090]
步骤103,将目标物体所在区域的图像和视频流中参考视频帧的下一帧输入至第二网络,通过第二网络识别出参考视频帧的下一帧中的目标物体。
[0091]
终端设备在将目标物体所在区域的图像和视频流中参考视频帧的下一帧输入至第二网络,第二网络可以使用参考视频帧中目标物体所在区域的图像,对参考视频帧的下一帧中的目标物体进行识别,该识别过程使用到了目标物体的上下文动态信息,可以改善目标物体的漏检问题,从而更好地为船只的智能避障功能提供服务。其中,上述第二网络可以是跟踪性能较好的孪生区域候选网络(siamese region proposal network,siamese
‑
rpn),其在兼顾实时性的情况下可以达到较高的准确率,且能够在长时间跟踪时保持稳定性。
[0092]
第二网络在识别出参考视频帧的下一帧中的目标物体后,可以输出参考视频帧的下一帧中目标物体的第二目标框位置。第二目标框中的图像即为参考视频帧的下一帧中目标物体所在区域的图像。
[0093]
在一个实施例中,在识别出参考视频帧的下一帧中的目标物体之后,还包括:
[0094]
输出目标物体的第一置信度和第二网络的已跟踪帧数;
[0095]
若目标物体的第一置信度小于第一置信度阈值,和/或第二网络的已跟踪帧数大于帧数阈值,则将参考视频帧的下一帧作为参考视频帧,并返回执行将参考视频帧输入至第一网络的步骤;
[0096]
若目标物体的第一置信度小于或者等于第一置信度阈值,且第二网络的已跟踪帧数小于或者等于帧数阈值,则将参考视频帧的下一帧作为参考视频帧,并返回执行将目标物体所在区域的图像和视频流中参考视频帧的下一帧输入至第二网络的步骤。
[0097]
其中,目标物体的第一置信度是指第二网络输出的目标物体的置信度。第二网络的已跟踪帧数可以是指视频流中已使用第二网络进行目标物体识别的帧数。
[0098]
若目标物体的第一置信度小于第一置信度阈值,则说明通过第二网络对参考视频帧的下一帧识别出的目标物体的置信度较低,为了较为准确地识别出参考视频帧的下一帧中的目标物体,可以将参考视频帧的下一帧输入至第一网络,通过第一网络对参考视频帧的下一帧进行目标识别。
[0099]
若第二网络的已跟踪帧数大于帧数阈值,则说明已通过第二网络跟踪较多的视频帧,为了提高目标物体的识别准确性,需要更新输入至第二网络的目标物体所在区域的图像。本技术通过将参考视频帧的下一帧输入至第一网络,可以将输入至第二网络的目标物体所在区域的图像更新为参考视频帧的下一帧中目标物体所在区域的图像。
[0100]
终端设备在检测到视频流中所有视频帧均进行目标识别后,可以结束对视频流的目标识别。
[0101]
在一个实施例中,在将视频流中的参考视频帧输入至第一网络之后,还包括:
[0102]
输出目标物体的第二置信度;
[0103]
将目标物体所在区域的图像和视频流中参考视频帧的下一帧输入至第二网络包括:
[0104]
在目标物体的第二置信度大于第二置信度阈值时,将目标物体所在区域的图像和视频流中参考视频帧的下一帧输入至第二网络。
[0105]
其中,目标物体的第二置信度是指第一网络输出的目标物体的置信度。
[0106]
在目标物体的第二置信度大于第二置信度阈值时,说明第一网络识别的目标物体较为准确,故可以将基于第一网络得到的目标物体所在区域的图像作为目标物体的模板输入至第二网络,通过第二网络实现目标物体的跟踪。
[0107]
在一个实施例中,在将视频流中的参考视频帧输入至第一网络之后,还包括:
[0108]
输出目标物体的类别;
[0109]
将目标物体所在区域的图像和视频流中参考视频帧的下一帧输入至第二网络包括:
[0110]
在目标物体的类别为目标类别时,将目标物体所在区域的图像和视频流中参考视频帧的下一帧输入至第二网络。
[0111]
终端设备在将参考视频帧输入至第一网络之后,第一网络可以对参考视频帧中的目标物体进行识别,并输出目标物体的类别。
[0112]
为了实现针对目标类别的目标物体的跟踪,可以在第一网络输出的目标物体的类别为目标类别时,才将目标物体所在区域的图像和参考视频帧的下一帧输入至第二网络;在第一网络输出的目标物体的类别不是目标类别时,则可以筛选掉参考视频帧,将参考视频帧的下一帧输入至第一网络,输出参考视频帧的下一帧中目标物体的类别,重复执行上述类别判断的步骤,直到第一网络输出的目标物体的类别为目标类别或者遍历完视频流。
[0113]
可选地,终端设备也可以同时获取目标物体的第二置信度和目标物体的类别,在目标物体的第二置信度大于第二置信度阈值,且目标物体的类别为目标类别时,将目标物体所在区域的图像和视频流中参考视频帧的下一帧输入至第二网络,以通过第二网络实现对目标类别的物体的准确识别。
[0114]
本技术实施例在基于第二网络识别参考视频帧的下一帧中的目标物体时,通过使用目标物体在参考视频帧中的信息,即使用到目标物体的上下文动态信息,而不是将每帧的目标识别视为独立事件,可以改善目标物体的漏检问题。且本技术中的第一网络为剪枝处理后的yolov4网络,该yolov4网络的损失函数为focal loss,通过该yolov4网络识别出参考视频帧中目标物体,能够提高目标识别的运算速度,提升对部分较难识别的目标物体的识别能力。另外,本技术实施例通过级联第一网络和第二网络,能够在船只的实时视频流
检测中取得更好的识别效果。
[0115]
参见图2,是本技术实施例二提供的水上目标识别方法的实现流程示意图,该水上目标识别方法应用于终端设备。如图2所示,该水上目标识别方法可以包括以下步骤:
[0116]
步骤201,获取针对水上目标物体的视频流。
[0117]
该步骤与步骤101相同,具体可参见步骤101的相关描述,在此不再赘述。
[0118]
步骤202,将视频流中的参考视频帧输入至第一网络,得到参考视频帧中目标物体所在区域的图像,第一网络为剪枝处理后的yolov4网络,且yolov4网络的损失函数为focal loss。
[0119]
该步骤与步骤102相同,具体可参见步骤102的相关描述,在此不再赘述。
[0120]
步骤203,将目标物体所在区域的图像和视频流中参考视频帧的下一帧输入至第二网络,通过第二网络识别出参考视频帧的下一帧中的目标物体。
[0121]
该步骤与步骤103相同,具体可参见步骤103的相关描述,在此不再赘述。
[0122]
步骤204,根据目标物体所在区域的图像,确定目标物体的掩模图像。
[0123]
在一个实施例中,终端设备可以使用lc显著性检测算法,对目标物体所在区域的图像进行前景和背景分离,得到目标物体的掩模图像。lc显著性检测算法能够在不影响终端设备的核心计算资源的情况下求出目标物体的掩模图像,从而快速地在hsv颜色空间判断出目标物体的颜色。
[0124]
其中,目标物体的掩模图像可以理解为目标物体所在区域的图像的前景掩模。终端设备在对目标物体所在区域的图像进行前景和背景分离之后,可以将目标物体所在区域的图像中背景区域的像素点的灰度值设置为0,将目标物体所在区域的图像中前景区域的像素点的灰度值设置为255,对目标物体所在区域的图像进行灰度值设置后得到的图像即为目标物体的掩模图像。
[0125]
如图3a所示是参考视频帧的示例图;图3b所示是图3a所示参考视频帧中的目标物体所在区域的图像;图3c所示是图3b所示目标物体的掩模图像。
[0126]
步骤205,对目标物体所在区域的图像进行hsv分离,得到目标物体所在区域的图像的h分层、s分层和v分层。
[0127]
其中,hsv是一种颜色空间,包括三个颜色参数,分别为色调(h)、饱和度(s)和明度(v)。
[0128]
如图3d所示是图3b所示目标物体所在区域的图像的h分层的示例图;图3e是图3b所示目标物体所在区域的图像的s分层的示例图;图3f是图3b所示目标物体所在区域的图像的v分层的示例图。
[0129]
步骤206,根据目标物体的掩模图像和h分层、s分层和v分层中的至少一种分层,确定目标物体的颜色。
[0130]
终端设备根据目标物体的掩模图像和v分层可以判断目标物体的颜色是否为黑色;根据目标物体的掩模图像和s分层可以判断目标物体的颜色是否为白色或者灰色;在目标物体的颜色不是黑色、白色或者灰色中的任一种颜色时,可以根据目标物体的掩模图像和h分层确定目标物体的颜色。
[0131]
终端设备在得到目标物体的颜色之后,可以在目标物体所在视频帧的第一预设位置显示目标物体的颜色。另外,还可以在目标物体所在视频帧的第二预设位置、第三预设位
置、第四预设位置分别显示目标物体的类别、置信度和目标物体的目标框(即第一目标框或者第二目标框)的位置信息。其中,第一预设位置、第二预设位置、第三预设位置和第四预设位置是预先设置的不同位置。例如,第一预设位置是目标物体的目标框的下方一位置,第四预设位置是目标物体的目标框的下方另一位置,第二预设位置是目标物体的目标框的上方一位置,第三预设位置是目标物体的目标框的上方另一位置。
[0132]
在一个实施例中,根据目标物体的掩模图像和h分层、s分层和v分层中的至少一种分层,确定目标物体的颜色;
[0133]
根据目标物体的掩模图像,确定s分层中目标物体在各颜色的像素点数量和v分层中目标物体在各颜色的像素点数量;
[0134]
根据s分层中目标物体在各颜色的像素点数量和v分层中目标物体在各颜色的像素点数量,判断目标物体的颜色是否为非彩色,非彩色为黑色、白色和灰色的任一种颜色;
[0135]
若目标物体的颜色不是非彩色,则确定h分层中目标物体的像素点数量最多的颜色为目标物体的颜色。
[0136]
终端设备根据目标物体的掩模图像,可以得到目标物体在v分层中的位置,检测目标物体在v分层中的位置处的像素点的颜色,并统计各个颜色的像素点数量,通过各个颜色的像素点数量可以判断目标物体的颜色是否为黑色。v分层中的颜色灰度小于46的为黑色,其他为非黑色,在黑色的像素点数量较多时,可以确定目标物体的颜色为黑色;在黑色的像素点数量较少时,可以确定目标物体的颜色不是黑色。
[0137]
终端设备根据目标物体的掩模图像,可以得到目标物体在s分层中的位置,检测目标物体在s分层中的位置处的像素点的颜色,并统计各个颜色的像素点数量,通过各个颜色的像素点数量可以判断目标物体的颜色是否为白色或灰色。s分层中的颜色灰度在(0
‑
43)范围内为白色或灰色,在(43
‑
255)范围内为其他颜色,在白色或灰色的像素点数量较多时,可以确定目标物体的颜色为白色或灰色;在白色或灰色的像素点数量较少时,可以确定目标物体的颜色不是白色和灰色。而在白色或灰色的判断中,则依据v分层的色彩状况,灰度值在(46
‑
220)范围内的为灰色,灰度值在(221
‑
255)范围内的为白色。
[0138]
终端设备在目标物体的颜色不是黑色、白色或灰色时,可以确定目标物体的颜色为彩色,此时可以根据目标物体的掩模图像,得到目标物体在h分层中的位置,检测目标物体在h分层中的位置处的像素点的颜色,并统计各个颜色的像素点数量,确定像素点数量最多的颜色即为目标物体的颜色。
[0139]
可选地,本技术可通过直方图统计各个颜色的像素点数量。
[0140]
如图3g是图3d所示h分层中目标物体在各颜色的像素点数量的示例图;
[0141]
图3h是图3e所示s分层中目标物体在各颜色的像素点数量的示例图;图3i是图3f所示v分层中目标物体在各颜色的像素点数量的示例图。由图3g、3h和3i可知,目标物体的颜色为青色。
[0142]
应理解,目标物体通常包括多种颜色,本技术中的目标物体颜色可以理解为目标物体的主体颜色(即像素点数量最多的颜色)。
[0143]
本技术实施例在实施例一的基础上增加根据目标物体的掩模图像和目标物体所在区域的h分层、s分层、v分层等确定目标物体的颜色,能够在不影响第一网络和第二网络的算力的情况下,同步检测出目标物体的颜色。
[0144]
对应于上文实施例所述的水上目标识别方法,图4示出了本技术实施例提供的水上目标识别装置的结构框图,为了便于说明,仅示出了与本技术实施例相关的部分。
[0145]
参照图4,该水上目标识别装置包括:
[0146]
视频流获取模块41,用于获取针对水上目标物体的视频流;
[0147]
视频帧输入模块42,用于将视频流中的参考视频帧输入至第一网络,得到参考视频帧中目标物体所在区域的图像,第一网络为剪枝处理后的yolov4网络,且yolov4网络的损失函数为focal loss;
[0148]
目标识别模块43,用于将目标物体所在区域的图像和视频流中参考视频帧的下一帧输入至第二网络,通过第二网络识别出参考视频帧的下一帧中的目标物体。
[0149]
可选地,上述目标识别模块43还用于:
[0150]
输出目标物体的第一置信度;
[0151]
上述水上目标识别装置还包括:
[0152]
帧数获取模块,用于获取第二网络的已跟踪帧数;
[0153]
第一处理模块,用于若目标物体的第一置信度小于第一置信度阈值,或者第二网络的已跟踪帧数大于帧数阈值,则将参考视频帧的下一帧作为参考视频帧,并返回执行视频帧输入模块42;
[0154]
第二处理模块,用于若目标物体的第一置信度小于或者等于第一置信度阈值,且第二网络的已跟踪帧数小于或者等于帧数阈值,则将参考视频帧的下一帧作为参考视频帧,并返回执行目标识别模块43。
[0155]
可选地,上述视频帧输入模块42还用于:
[0156]
输出目标物体的第二置信度;
[0157]
上述目标识别模块43具体用于:
[0158]
在目标物体的第二置信度大于第二置信度阈值时,将目标物体所在区域的图像和视频流中参考视频帧的下一帧输入至第二网络。
[0159]
可选地,上述视频帧输入模块42还用于:
[0160]
输出目标物体的类别;
[0161]
上述目标识别模块43具体用于:
[0162]
若目标物体的类别为目标类别,则将目标物体所在区域的图像和视频流中参考视频帧的下一帧输入至第二网络。
[0163]
可选地,上述视频帧输入模块42还用于:
[0164]
输出目标物体的第二置信度和目标物体的类别;
[0165]
上述目标识别模块43具体用于:
[0166]
若目标物体的第二置信度大于第二置信度阈值且目标物体的类别为目标类别,则将目标物体所在区域的图像和视频流中参考视频帧的下一帧输入至第二网络。
[0167]
可选地,上述水上目标识别装置还包括:
[0168]
掩模确定模块,用于根据目标物体所在区域的图像,确定目标物体的掩模图像;
[0169]
图像分离模块,用于对目标物体所在区域的图像进行hsv分离,得到目标物体所在区域的图像的h分层、s分层和v分层;
[0170]
颜色确定模块,用于根据目标物体的掩模图像和h分层、s分层和v分层中的至少一
种分层,确定目标物体的颜色。
[0171]
可选地,上述颜色确定模块具体用于:
[0172]
根据目标物体的掩模图像,确定s分层中目标物体在各颜色的像素点数量和v分层中目标物体在各颜色的像素点数量;
[0173]
根据s分层中目标物体在各颜色的像素点数量和v分层中目标物体在各颜色的像素点数量,判断目标物体的颜色是否为非彩色,非彩色为黑色、白色和灰色的任一种颜色;
[0174]
若目标物体的颜色不是非彩色,则确定h分层中目标物体的像素点数量最多的颜色为目标物体的颜色。
[0175]
需要说明的是,上述装置/单元之间的信息交互、执行过程等内容,由于与本技术方法实施例基于同一构思,其具体功能及带来的技术效果,具体可参见方法实施例部分,此处不再赘述。
[0176]
本技术实施例提供的水上目标识别装置可以应用在前述方法实施例一和实施例二中,详情参见上述方法实施例一和实施例二的描述,在此不再赘述。
[0177]
在实际应用中,本技术提供的水上目标识别方案可以部署至终端设备。在终端设备上运行之后,可以在多个场景下进行目标识别测试。如图5a和图5b所示是在湖边码头的场景下进行目标识别测试的示例图,在湖边码头的场景下能够识别出图中的人、船只等目标物体,并在图中标记出人、船只等目标物体的置信度;如图5c和图5d所示是在内河水域的场景下进行目标识别测试的示例图,在内河水域的场景下能够识别出图中的航标,并在图中标记出航标的置信度;如图5e和图5f所示是在入海口的场景下进行目标识别测试的示例图,在入海口的场景下能够识别出图中的航标,并在图中标记出航标的置信度;如图5g和图5h所示是在无人机航拍的场景下进行目标识别测试的示例图,在无人机航拍的场景下能够识别出图中的船只,并在图中标记出船只的置信度。
[0178]
由图5a、图5b、图5c、图5d、图5e、图5f、图5g和图5h可知,在这四个场景下,本技术提供的水上目标识别方案的检测效果较好,能够完成对各类水上目标物体的识别。其中,在湖边码头的场景下,能够准确地检测出岸边的人员和湖泊中游过的船只,整个识别过程运行良好。在内河水域和入海口的场景下,在目标物体的识别过程中,虽然船只前的支架从镜头前扫过,但本技术提供的水上目标识别方案仍能够表现出较好的稳定性,准确地识别出航标等目标物体。在无人机航拍的场景下,本技术中的视频流来自于无人机的航拍视频传输,本技术提供的水上目标识别方案能够较为准确地识别出该视频流中的目标物体。
[0179]
图6是本技术实施例四提供的终端设备的结构示意图。如图6所示,该实施例的终端设备6包括:一个或多个处理器60(图中仅示出一个)、存储器61以及存储在所述存储器61中并可在所述处理器60上运行的计算机程序62。所述处理器60执行所述计算机程序62时实现上述各个水上目标识别方法实施例中的步骤。
[0180]
所述终端设备6可包括,但不仅限于,处理器60、存储器61。本领域技术人员可以理解,图6仅仅是终端设备6的示例,并不构成对终端设备6的限定,可以包括比图示更多或更少的部件,或者组合某些部件,或者不同的部件,例如所述终端设备还可以包括输入输出设备、网络接入设备、总线等。
[0181]
所称处理器60可以是中央处理单元(central processing unit,cpu),还可以是其他通用处理器、数字信号处理器(digital signal processor,dsp)、专用集成电路
(application specific integrated circuit,asic)、现成可编程门阵列(field
‑
programmable gate array,fpga)或者其他可编程逻辑器件、分立门或者晶体管逻辑器件、分立硬件组件等。通用处理器可以是微处理器或者该处理器也可以是任何常规的处理器等。
[0182]
所述存储器61可以是所述终端设备6的内部存储单元,例如终端设备6的硬盘或内存。所述存储器61也可以是所述终端设备6的外部存储设备,例如所述终端设备6上配备的插接式硬盘,智能存储卡(smart media card,smc),安全数字(secure digital,sd)卡,闪存卡(flash card)等。进一步地,所述存储器61还可以既包括所述终端设备6的内部存储单元也包括外部存储设备。所述存储器61用于存储所述计算机程序以及所述终端设备所需的其他程序和数据。所述存储器61还可以用于暂时地存储已经输出或者将要输出的数据。
[0183]
所属领域的技术人员可以清楚地了解到,为了描述的方便和简洁,仅以上述各功能单元、模块的划分进行举例说明,实际应用中,可以根据需要而将上述功能分配由不同的功能单元、模块完成,即将所述装置的内部结构划分成不同的功能单元或模块,以完成以上描述的全部或者部分功能。实施例中的各功能单元、模块可以集成在一个处理单元中,也可以是各个单元单独物理存在,也可以两个或两个以上单元集成在一个单元中,上述集成的单元既可以采用硬件的形式实现,也可以采用软件功能单元的形式实现。另外,各功能单元、模块的具体名称也只是为了便于相互区分,并不用于限制本技术的保护范围。上述装置中单元、模块的具体工作过程,可以参考前述方法实施例中的对应过程,在此不再赘述。
[0184]
本技术实施例还提供了一种计算机可读存储介质,计算机可读存储介质存储有计算机程序,计算机程序被处理器执行时实现可实现上述各个方法实施例中的步骤。
[0185]
本技术实施例还提供了一种计算机程序产品,当计算机程序产品在终端设备上运行时,使得终端设备执行时实现可实现上述各个方法实施例中的步骤。
[0186]
在上述实施例中,对各个实施例的描述都各有侧重,某个实施例中没有详述或记载的部分,可以参见其它实施例的相关描述。
[0187]
本领域普通技术人员可以意识到,结合本文中所公开的实施例描述的各示例的单元及算法步骤,能够以电子硬件、或者计算机软件和电子硬件的结合来实现。这些功能究竟以硬件还是软件方式来执行,取决于技术方案的特定应用和设计约束条件。专业技术人员可以对每个特定的应用来使用不同方法来实现所描述的功能,但是这种实现不应认为超出本技术的范围。
[0188]
在本技术所提供的实施例中,应该理解到,所揭露的装置/终端设备和方法,可以通过其它的方式实现。例如,以上所描述的装置/终端设备实施例仅仅是示意性的,例如,所述模块或单元的划分,仅仅为一种逻辑功能划分,实际实现时可以有另外的划分方式,例如多个单元或组件可以结合或者可以集成到另一个系统,或一些特征可以忽略,或不执行。另一点,所显示或讨论的相互之间的耦合或直接耦合或通讯连接可以是通过一些接口,装置或单元的间接耦合或通讯连接,可以是电性,机械或其它的形式。
[0189]
所述作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或者全部单元来实现本实施例方案的目的。
[0190]
所述集成的模块/单元如果以软件功能单元的形式实现并作为独立的产品销售或使用时,可以存储在一个计算机可读取存储介质中。基于这样的理解,本技术实现上述实施例方法中的全部或部分流程,也可以通过计算机程序来指令相关的硬件来完成,所述的计算机程序可存储于一计算机可读存储介质中,该计算机程序在被处理器执行时,可实现上述各个方法实施例的步骤。其中,所述计算机程序包括计算机程序代码,所述计算机程序代码可以为源代码形式、对象代码形式、可执行文件或某些中间形式等。所述计算机可读介质可以包括:能够携带所述计算机程序代码的任何实体或装置、记录介质、u盘、移动硬盘、磁碟、光盘、计算机存储器、只读存储器(read
‑
only memory,rom)、随机存取存储器(random access memory,ram)、电载波信号、电信信号以及软件分发介质等。需要说明的是,所述计算机可读介质包含的内容可以根据司法管辖区内立法和专利实践的要求进行适当的增减,例如在某些司法管辖区,根据立法和专利实践,计算机可读介质不包括电载波信号和电信信号。
[0191]
以上所述实施例仅用以说明本技术的技术方案,而非对其限制;尽管参照前述实施例对本技术进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本技术各实施例技术方案的精神和范围,均应包含在本技术的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1